by Rain Chu 2 月 23, 2025 | Agent , AI , Chat , Prompt
硅基流動 (SiliconFlow)是一家致力於加速通用人工智慧(AGI)普惠化的公司,主要可以讓生成式人工智慧惠及開發者和終端使用者使用,最近,硅基流動與華為雲合作,推出了基於昇騰雲的 DeepSeek R1 和 V3 推理服務 ,為使用者提供高效、穩定的 AI 模型推理體驗。
DeepSeek R1 與硅基流動的合作 DeepSeek R1 是一款由強化學習驅動的推理模型,旨在解決模型生成內容的重複性和可讀性問題。在強化學習之前,DeepSeek R1 引入了冷啟動數據,進一步優化推理效能。然而,近期由於 DeepSeek 官方伺服器頻繁出現繁忙狀態 ,許多使用者在使用時受到限制。
為了解決這一問題,硅基流動與華為雲合作,將 DeepSeek R1 部署在基於昇騰的計算平台上 ,提供更 穩定、高速 的 DeepSeek R1 API 服務 ,讓使用者可以在更低的成本下獲得優質的 AI 推理服務。
如何使用 DeepSeek R1 API 使用者可以透過 註冊硅基流動平台 ,取得 API 金鑰,並將 DeepSeek R1 模型整合到各種應用之中。硅基流動提供了詳細的 技術文件與教學 ,幫助開發者快速上手,充分發揮 DeepSeek R1 的強大功能。
硅基流動透過與華為雲的合作,成功解決了 DeepSeek R1 在使用過程中的伺服器繁忙問題 ,為開發者和終端使用者提供了一個 高效、穩定的 AI 模型推理平台 。這不僅展現了 硅基流動的技術優勢 ,也體現了其在推動 AGI 普惠化 方面的努力。
API使用
by Rain Chu 2 月 23, 2025 | AI , Chat , 模型 , 程式開發
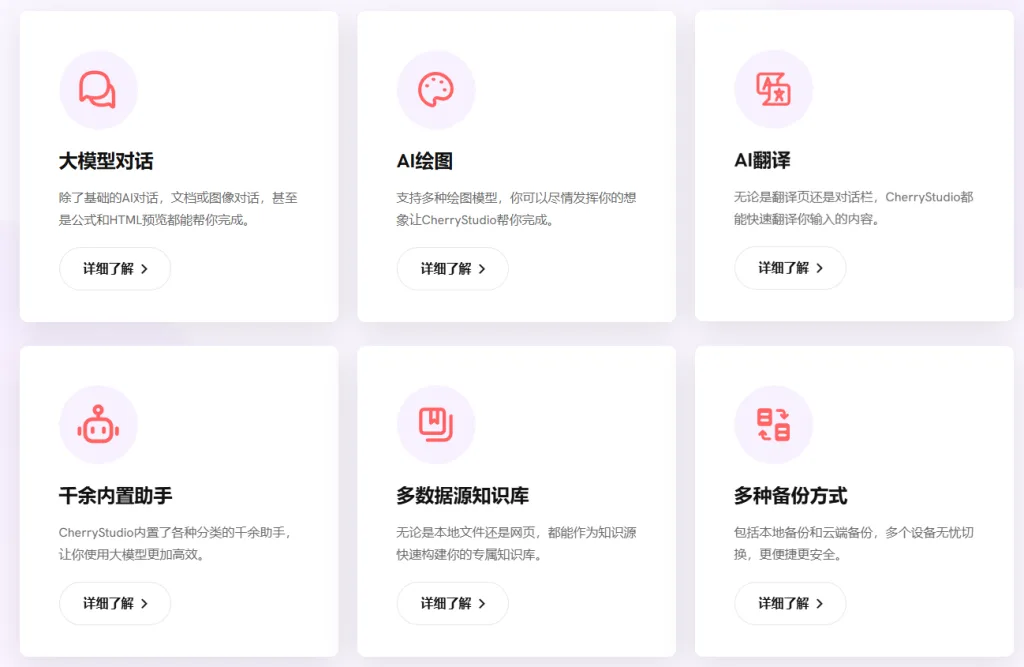
Cherry Studio 是一款功能強大的桌面客戶端,可以為使用者提供多模型對話、知識庫管理、AI 繪圖、翻譯等全方位的 AI 助手服務,其高度自訂的設計、強大的擴充能力和友善的使用者體驗,使其成為專業使用者和 AI 愛好者的理想選擇。
核心功能與特色
多模型對話支援 :Cherry Studio 集成了多種大型語言模型(LLM)服務商,如 OpenAI、Gemini、Anthropic、Azure 等,使用者可以在同一平台上調用不同模型,滿足多樣化需求。豐富的 AI 助手與對話功能 :
預配置助手 :內建超過 300 個行業專用助手,涵蓋翻譯、程式設計、寫作等領域,使用者也可自訂助手。多模型同時對話 :支援同一問題通過多個模型同時生成回覆,方便使用者比較不同模型的表現。對話管理 :自動分組管理對話記錄,支援對話匯出為多種格式(如 Markdown、PDF 等),便於儲存與分享。
文件與資料處理 :
多格式支援 :支援匯入 PDF、DOCX、PPTX、XLSX、TXT、MD 等多種檔案格式,方便使用者建構和查詢專屬知識庫。資料來源多樣性 :支援本機檔案、網址、網站地圖甚至手動輸入內容作為知識庫來源。知識庫匯出 :處理後的知識庫可匯出並分享給他人使用。
實用工具整合 :
AI 繪圖 :提供專用繪圖面板,使用者可通過自然語言描述生成高品質圖像。翻譯功能 :支援專用翻譯面板、對話翻譯、提示詞翻譯等多種翻譯場景。全域搜尋 :快速定位歷史記錄和知識庫內容,提升工作效率。
使用者體驗提升 :
跨平台支援 :相容 Windows、macOS 和 Linux 系統,滿足不同使用者的需求。即裝即用 :無需複雜的環境配置,下載後即可使用。介面自訂 :支援自訂 CSS、對話佈局、頭像和側邊欄選單,打造個性化的使用體驗。
適用場景
知識管理與查詢 :通過本機知識庫功能,快速建構和查詢專屬知識庫,適用於研究、教育等領域。多模型對話與創作 :支援多模型同時對話,幫助使用者快速獲取資訊或生成內容。翻譯與辦公自動化 :內建翻譯助手和檔案處理功能,適合需要跨語言交流或文件處理的使用者。AI 繪圖與設計 :通過自然語言描述生成圖像,滿足創意設計需求。
公開原始碼
by Rain Chu 2 月 23, 2025 | AI , 程式開發
OpenRouter 是一個統一的大型語言模型(LLM)API 服務平台,可以讓使用者透過單一介面訪問多種大型語言模型。
主要特點:
多模型支援: OpenRouter 集成了多種預訓練模型,如 GPT-4、Gemini、Claude、DALL-E 等,按需求選擇適合的模型。易於集成: 提供統一的 API 介面,方便與現有系統整合,無需自行部署和維護模型。成本效益: 透過 API 調用,使用者無需購買昂貴的 GPU 伺服器,降低了硬體成本。
使用方法:
註冊帳號: 使用 Google 帳號即可快速註冊 OpenRouter。選擇模型: 在平台上瀏覽並選擇適合的模型,部分模型提供免費使用。調用 API: 使用統一的 API 介面,將選定的模型整合到您的應用中。
Cline 整合
OpenRouter 與 Cline 的整合為開發者提供了強大的 AI 編程體驗,Cline 是一款集成於 VSCode 的 AI 編程助手,支援多種大型語言模型(LLM),如 OpenAI、Anthropic、Mistral 等,透過 OpenRouter,Cline 能夠統一調用這些模型,簡化了不同模型之間的切換和管理,使用者只需在 Cline 的設定中選擇 OpenRouter 作為 API 提供者,並輸入相應的 API 金鑰,即可開始使用多種模型進行開發。這種整合不僅提升了開發效率,還降低了使用多模型的技術門檻。
DeepSeek R1
OpenRouter 現在也支援 DeepSeek R1 模型,DeepSeek R1 是一款高性能的開源 AI 推理模型,具有強大的數學、編程和自然語言推理能力。透過 OpenRouter,開發者可以在 Cline 中輕鬆調用 DeepSeek R1 模型,享受其強大的推理能力。這進一步豐富了開發者的工具選擇,讓他們能夠根據項目需求選擇最適合的模型。
by Rain Chu 2 月 3, 2025 | AI , Stable Diffusion , 繪圖
AMD於2024年7月推出了Amuse 2.0 Beta版本,這是一款專為AMD平台設計的AI創作工具,替 AMD CPU、GPU的用戶提供更簡便的AI圖像生成體驗。
主要特色:
AMD XDNA超分辨率技術 :該技術可在圖像生成結束時,將輸出尺寸提高兩倍。例如,將512×512像素的圖像放大至1024×1024像素,提升圖像細節和清晰度。多樣化的AI功能 :Amuse 2.0提供了繪畫和草圖圖像轉換、可自定義AI濾鏡,以及基於ONNX的多階段管線等功能,滿足不同創作需求。 「容易模式」(Ez Mode) :即使用戶沒有專業的AI知識,也能透過此模式輕鬆上手,享受AI創作的樂趣。
硬體支援: Amuse 2.0 的推薦配置包括:
配備24GB或以上記憶體的Ryzen AI 300系列處理器。
配備32GB記憶體的Ryzen 8040系列處理器(需更新至最新的OEM MCDM和NPU驅動)。
Radeon RX 7000系列顯示卡。
目前只有Ryzen AI 300系列和更新驅動後的Ryzen 8000系列處理器支援AMD XDNA超分辨率技術。
安裝與使用: 到官網去下載 Amuse 2.0為單一可執行(EXE)檔案,無需額外的相依性,安裝過程簡單。首次啟動時,系統會自動偵測硬體配置,並自動設定最佳化參數。建議初次使用者選擇「平衡」設定,以在性能和品質之間取得良好平衡。
by Rain Chu 1 月 1, 2025 | AI , 影片製作
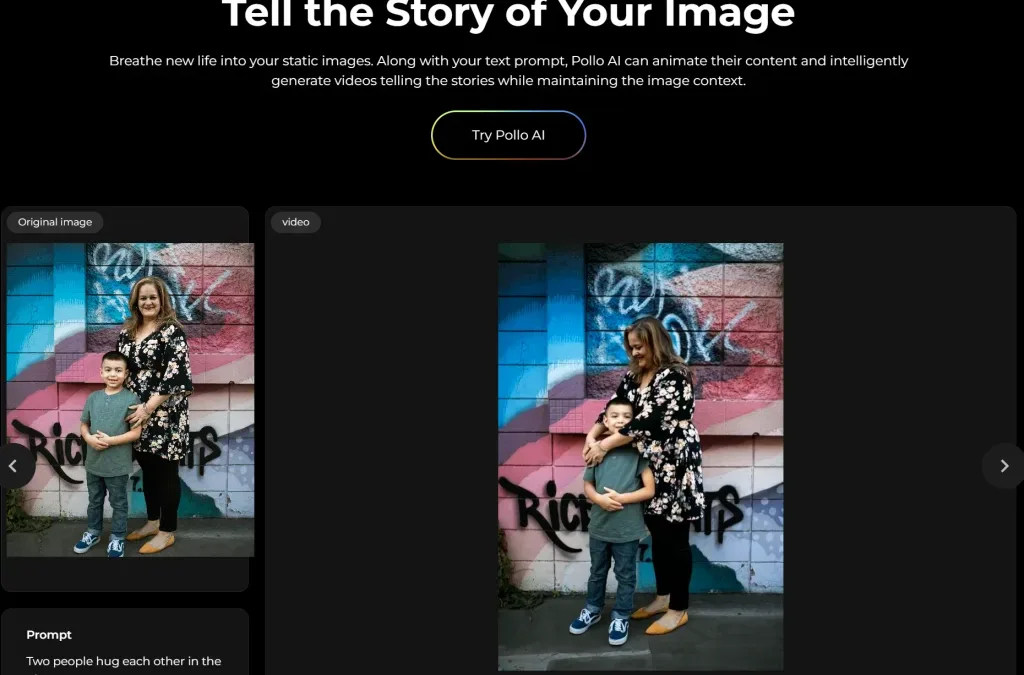
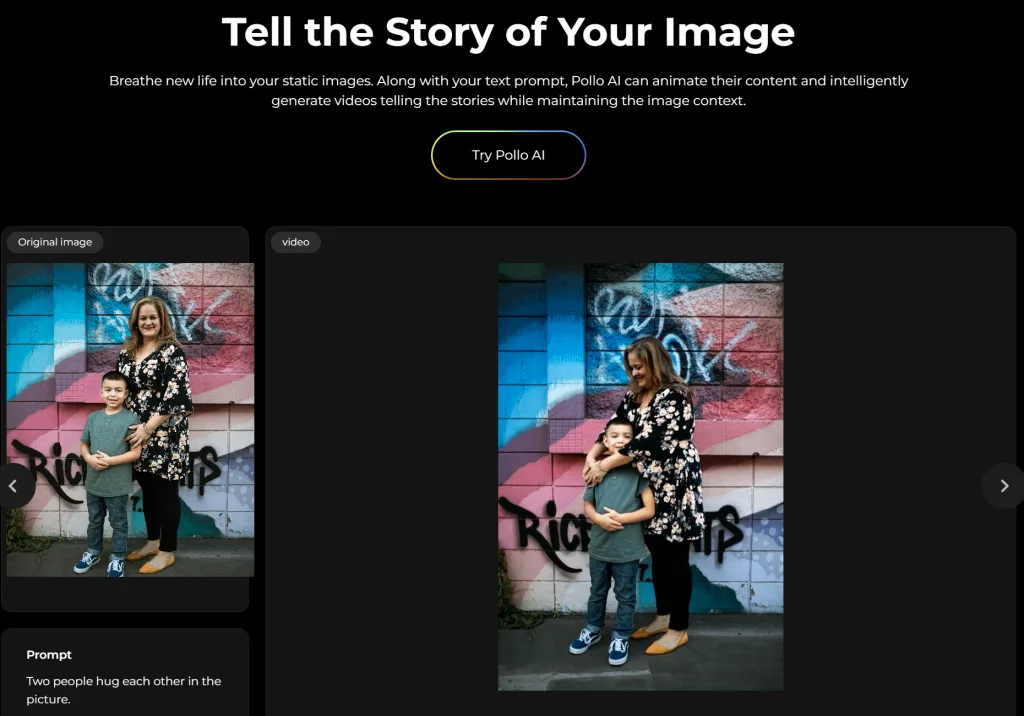
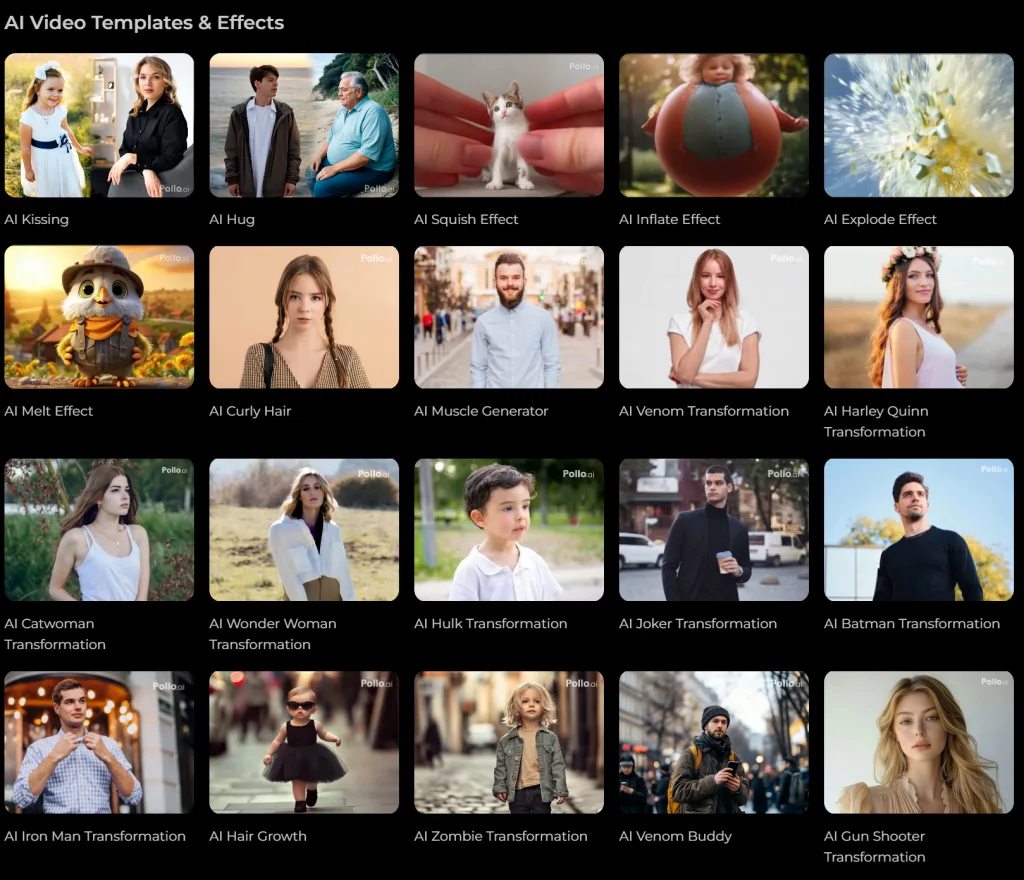
Pollo AI 可以讓用戶從文字提示、圖片或現有影片中創建超高品質的影片,支援多種影片風格,從真實的電影場景到富有想像力的動畫,滿足不同的創作需求。其快速的影片生成演算法,讓用戶能在短短幾分鐘內獲得高清、專業級的影片輸出,此外,Pollo AI還提供多樣的模板,如AI擁抱影片生成器,方便用戶輕鬆創作溫馨感人的影片
Pollo AI homepage,文字生圖 支援 40多種 AI 影片特效,使得任何事物或人物都能在影片中“活”起來,例如
擠壓特效 :讓照片中的主體如同麵團或橡皮泥般被擠壓變形,呈現出趣味十足的動態效果,適合在社交媒體上分享。
膨脹特效 :使物體、人物或動物如氣球般膨脹,隨後飄走或爆裂,創作出搞笑短片,流暢自然的動畫效果有望成為病毒式影片。
爆炸特效 :讓畫面中的主體以誇張且滑稽的方式“炸裂”,天馬行空的創意為觀眾帶來歡樂。
融化特效 :將靜態圖像轉化為動態影片,讓畫面中的主體如巧克力般慢慢融化,效果逼真,只需簡單的三步操作即可完成。
Pollo AI 特效以及影片樣版庫
VIDEO
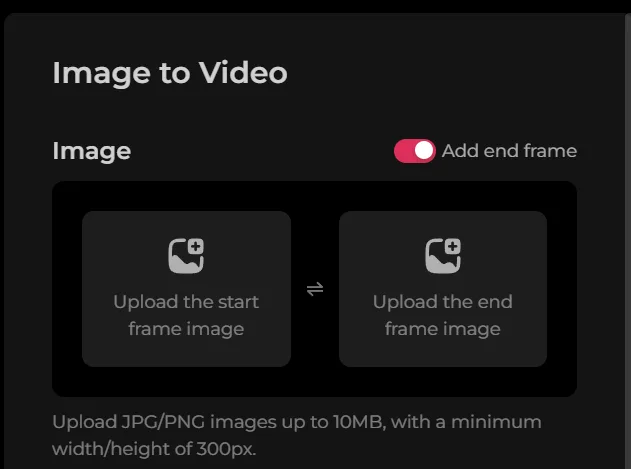
首尾偵功能
Pollo AI還引入了首尾偵功能
Pollo AI Image to Video 功能,首尾禎產影片功能 三張圖片合成功能
Pollo AI的三張圖片合成功能
參考資訊
by rainchu 12 月 27, 2024 | AI , 人臉辨識 , 圖型處理 , 繪圖
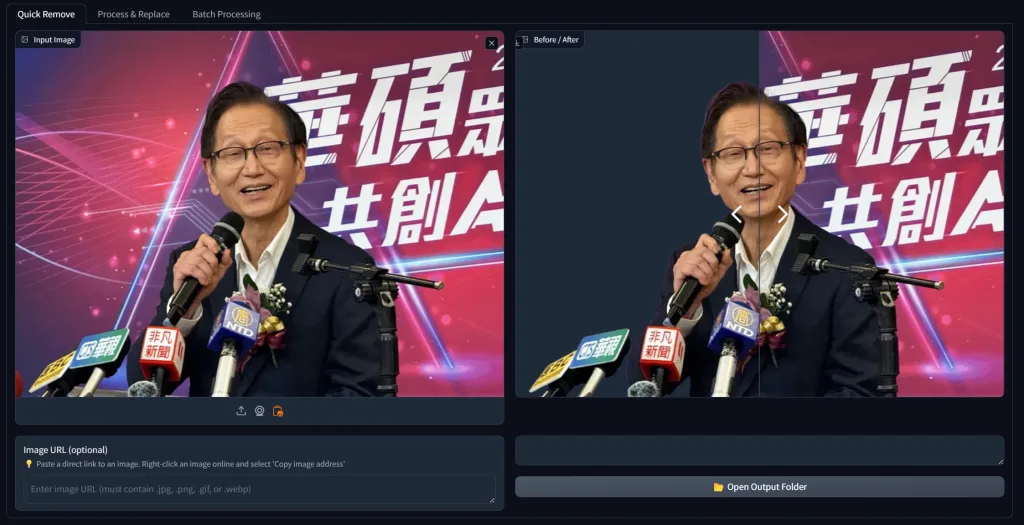
MBG-2-Studio 是一款基於 BRIA-RMBG-2.0 模型開發的開源應用程式,專門用於高效地移除和替換圖像背景,提供了背景移除、圖像合成、顏色分級和批次處理,可以用於電子商務、廣告製作、遊戲開發等多種場景。
主要功能:
背景移除 :利用先進的 AI 技術,精確分離前景與背景,達到高精度的背景去除效果。拖放圖庫 :用戶可以直接從圖庫中拖放處理後的圖像,進行背景替換和顏色調整。圖像合成 :將處理後的圖像放置在新的背景上,並進行位置和大小的調整,以實現自然的合成效果。顏色分級 :調整圖像的亮度、對比度、飽和度、色溫和色調,提升圖像質量。批次處理 :一次性處理多張圖像,提高工作效率,適合需要大量處理的用戶。URL 支援 :直接從 URL 加載圖像進行處理,方便處理線上圖片。
使用指南: 使用 node js 安裝
安裝 :從 GitHub 頁面下載最新版本的安裝包,解壓後運行 install.js 進行安裝。啟動 :安裝完成後,運行 start.js 啟動應用程式。背景移除 :在「背景移除」標籤下,將需要處理的圖像拖放到指定區域,應用程式會自動進行背景移除。圖像合成 :在「合成工作區」標籤下,從圖庫中拖放處理後的圖像到合成區域,調整位置和大小,選擇新的背景,並使用顏色分級工具進行調整。
使用 pip 安裝
安裝: 到 app 目錄下,執行 pip install -r requirements.txt啟動: 執行 app\app.py
相關資源: GitHub 頁面


近期留言