by Rain Chu 7 月 20, 2026 | Agent , AI , API , Tool
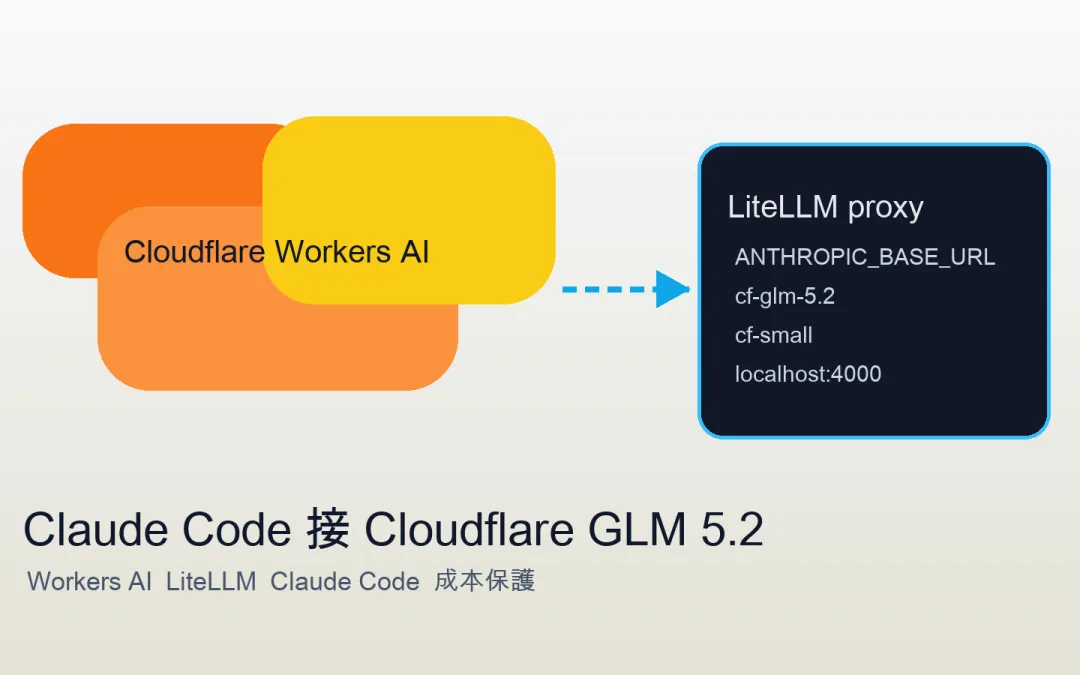
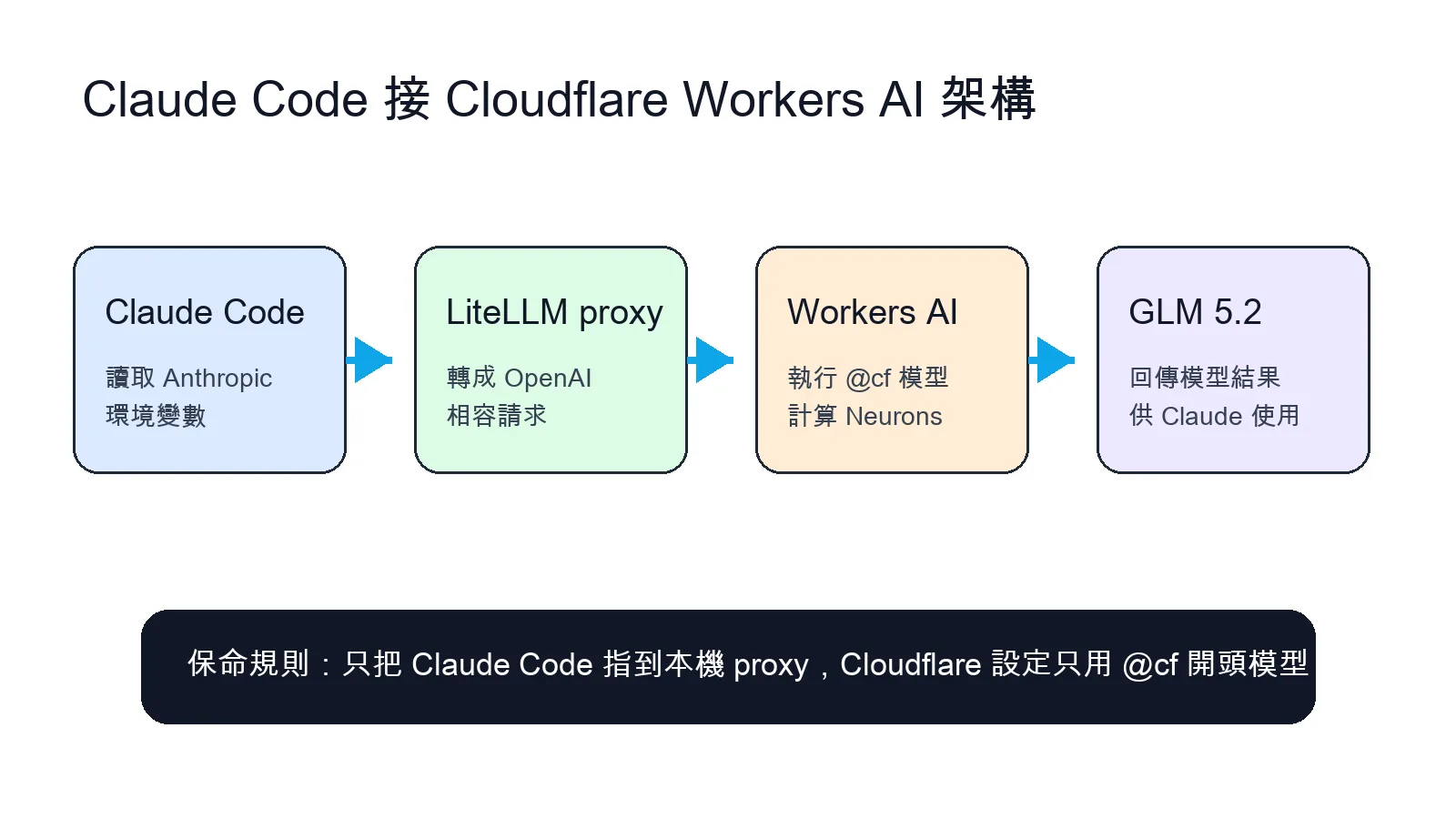
Cloudflare Workers AI 拿來接 Claude Code 的做法很簡單:Cloudflare 跑模型,LiteLLM 在本機當轉接橋,Claude Code 只需要改 Anthropic 相關環境變數,就能把請求送到本機 proxy。
這篇整理的是一個比較務實的路線。它不是要你把所有模型成本都消失,而是讓你知道免費額度在哪裡、帳單風險在哪裡、命令怎麼下、哪些設定一定要看清楚。
先講結論
Cloudflare Workers AI 有免費額度,官方價格頁寫明 Free plan 每天有 10,000 Neurons,GLM 5.2 目前也在 Cloudflare Workers AI 模型列表裡,可以透過 Cloudflare API 呼叫。這代表你可以把 Claude Code 的模型入口改成本機 LiteLLM proxy,再由 LiteLLM 轉送到 Cloudflare 的 @cf/zai-org/glm-5.2。
但「免費」不是「無限」,Cloudflare 的計費單位是 Neurons,免費額度用完後會受到方案限制,更重要的是,Cloudflare AI Gateway 也能接外部模型,如果你把 OpenAI 或 Anthropic 這類外部模型接進去,那就不再是 Cloudflare Workers AI 的免費模型邏輯,帳單會回到外部供應商那邊。
Claude Code 只改成本機 Anthropic 入口,真正的模型請求由 LiteLLM 轉到 Cloudflare Workers AI。 這個架構在解什麼問題
Claude Code 很好用,但長時間寫程式、重構、跑測試、修錯時,模型成本會變得很有感。若只是一些低風險任務,例如產生腳手架、改小工具、做簡單 demo、先跑一輪想法,Cloudflare Workers AI 的免費額度可以拿來當低成本緩衝層。
這和 用 Claude Code 搭配 LM Studio 與 Ollama 的思路很像,只是這次不是跑本地模型,而是把免費雲端額度接進本機開發流程。若你的工作流已經在用 Claude Code、Codex 和 skill 組合工作流 ,這種 proxy 入口會很有彈性。
完整操作命令
下面命令以 macOS 或 Linux 為主。你需要先有 Cloudflare 帳號,並在 Cloudflare dashboard 取得 Account ID 和 API Token。API Token 建議只給 Workers AI 需要的最小權限,不要用過度寬鬆的全域 token。
0. 安裝 Claude Code
npm install -g @anthropic-ai/claude-code 1. 用 curl 單測 GLM 5.2
先確認 Cloudflare 端可以呼叫模型。把 `你的ACCOUNT_ID` 和 `你的API_TOKEN` 換成自己的值。
curl https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/run/@cf/zai-org/glm-5.2 \
-H "Authorization: Bearer 你的API_TOKEN" \
-d '{"messages":[{"role":"user","content":"用一句話介紹你自己"}]}' 2. 安裝 uv
LiteLLM proxy 用 uvx 跑,可以固定 Python 3.12,避開較新 Python 版本造成的編譯問題。
curl -LsSf https://astral.sh/uv/install.sh | sh 3. 驗證 LiteLLM 能跑
uvx --python 3.12 --from 'litellm[proxy]' litellm --version 4. 建立 cf-config.yaml
建立 `cf-config.yaml`。`你的ACCOUNT_ID` 有兩處要換。`cf-glm-5.2` 給 Claude Code 主要模型用,`cf-small` 給較輕量任務用。
model_list:
- model_name: cf-glm-5.2
litellm_params:
model: openai/@cf/zai-org/glm-5.2
api_base: https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/v1
api_key: os.environ/CLOUDFLARE_API_TOKEN
- model_name: cf-small
litellm_params:
model: openai/@cf/meta/llama-3.1-8b-instruct-fp8
api_base: https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/v1
api_key: os.environ/CLOUDFLARE_API_TOKEN
litellm_settings:
use_chat_completions_url_for_anthropic_messages: true 5. 啟動 LiteLLM 翻譯橋
這個終端視窗要保持開啟。Claude Code 之後會連到 `localhost:4000`。
export CLOUDFLARE_API_TOKEN=你的token
uvx --python 3.12 --from 'litellm[proxy]' litellm --config cf-config.yaml --port 4000 6. 新開視窗測 proxy
curl http://localhost:4000/v1/models -H 'Authorization: Bearer sk-1234' 7. 把 Claude Code 指到本機 proxy
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-1234
export ANTHROPIC_MODEL=cf-glm-5.2
export ANTHROPIC_DEFAULT_HAIKU_MODEL=cf-small 接著啟動 Claude Code,若跳出自訂 API 設定就選是。進入後用 `/status` 確認 Base URL 指向 `localhost:4000`。
8. 把設定寫進 shell profile
如果你確定要長期使用,可以把上面四行 `ANTHROPIC_` export 加到 `~/.zshrc` 或 `~/.bashrc`。我會建議先手動跑幾次確認沒有問題,再寫進 profile。
Windows PowerShell 寫法
PowerShell 不用 `export`,改用 `$env:`。
$env:ANTHROPIC_BASE_URL="http://localhost:4000"
$env:ANTHROPIC_AUTH_TOKEN="sk-1234"
$env:ANTHROPIC_MODEL="cf-glm-5.2"
$env:ANTHROPIC_DEFAULT_HAIKU_MODEL="cf-small" 若要永久保存,放進 PowerShell 的 `$PROFILE`。Windows 跑 AI Agent 時,環境隔離也很重要,可以延伸看 Windows 跑 AI Agent 為什麼要用 WSL 。
保命提醒:不要把外部模型當免費額度
最容易出事的地方,是把 Cloudflare Workers AI、Cloudflare AI Gateway、OpenAI、Anthropic 混在一起。這篇的低成本前提,是 Cloudflare config 裡的模型走 `@cf/` 開頭,例如 `@cf/zai-org/glm-5.2`。這類模型用的是 Cloudflare Workers AI 額度。
如果你把 Gateway 接到 GPT 或 Claude,那些請求可能會回到 OpenAI 或 Anthropic 的帳單。Cloudflare 只是通道,不代表外部模型突然免費。真正要保命,就是把模型名稱、api_base、API key 來源逐一檢查,並在 Cloudflare 後台看用量。
官方價格頁目前寫得很明確:Free plan 每天 10,000 Neurons,Paid plan 也有每天 10,000 Neurons 免費額度,超出後依 Neurons 計費。免費方案超出額度通常是操作失敗,不是自動無限跑。這點比「無限免費」四個字重要太多。
省額度的三個做法
第一,任務分層。小任務用 `cf-small`,複雜推理再用 `cf-glm-5.2`。第二,讓 Agent 先輸出計畫再執行,避免一次丟太長上下文。第三,把重複流程寫成腳本或 skill,減少模型反覆讀同一批資料。
這也是我一直看好的方向:不要只追求模型本身,而是把模型接到穩定工具鏈。像 Playwright CLI 讓 Codex 操作瀏覽器 ,或 讓 Agent 自己搜尋和使用 skills ,本質上都是把昂貴推理留給真正需要判斷的地方。
我會怎麼用
我不會把這套當成主力模型的完全替代品,而是當成低成本實驗層。適合拿來跑 demo、試 prompt、生成小工具、做簡單 code review、補文件、處理一次性腳本。真正重要的架構決策、複雜除錯、長上下文專案,還是要保留更強模型或本地大模型選項。
如果你已經在用 Codex 和 ChatGPT Work 這類 AI 代理工作流 ,這套 Cloudflare Workers AI + LiteLLM 的做法可以當成另一個模型入口。它的價值不是讓你省到零,而是讓你有更多成本可控的實驗空間。
延伸資源
FAQ
Cloudflare Workers AI 接 Claude Code 真的免費嗎?
不是無限免費。Cloudflare Workers AI 有每日免費 Neurons 額度,超出後會依方案限制或計費。要把它當成低成本額度,不要當成沒有上限的模型。
為什麼需要 LiteLLM?
LiteLLM 在本機當 proxy,把 Claude Code 發出的 Anthropic 入口請求轉成 Cloudflare Workers AI 可接受的 OpenAI 相容請求。
最容易踩到哪個帳單風險?
最容易把 Cloudflare AI Gateway 接到外部 GPT 或 Claude,卻以為仍在用 Cloudflare 免費 @cf 模型。設定時要確認模型名稱是 `@cf/` 開頭,並檢查 API key 來源。
這套適合取代主力 Claude 嗎?
不建議直接取代。它比較適合低成本實驗、簡單任務、小工具和批次工作。複雜架構、長上下文和高風險任務,仍應保留更強模型。
by Rain Chu 7 月 15, 2026 | Agent , AI
Windows 跑 AI Agent,真正的關鍵不是把所有工具硬裝進 PowerShell,而是把 Windows 當成桌面和硬體入口,把 Linux 工具鏈交給 WSL 2,這樣做的好處很直接:Python、Node、Docker、Git、CUDA、各種開源 Agent 工具,都會更接近它們原本被設計和測試的環境。
我的判斷是,如果你在 Windows 上做 Codex、Claude Code、Cursor、OpenCode、本地模型或自動化 Agent,WSL 2 幾乎是標準底座,不是因為 Windows 不行,而是 AI Agent 這一波工具鏈大多先從 Linux 生態長出來。
先講結論
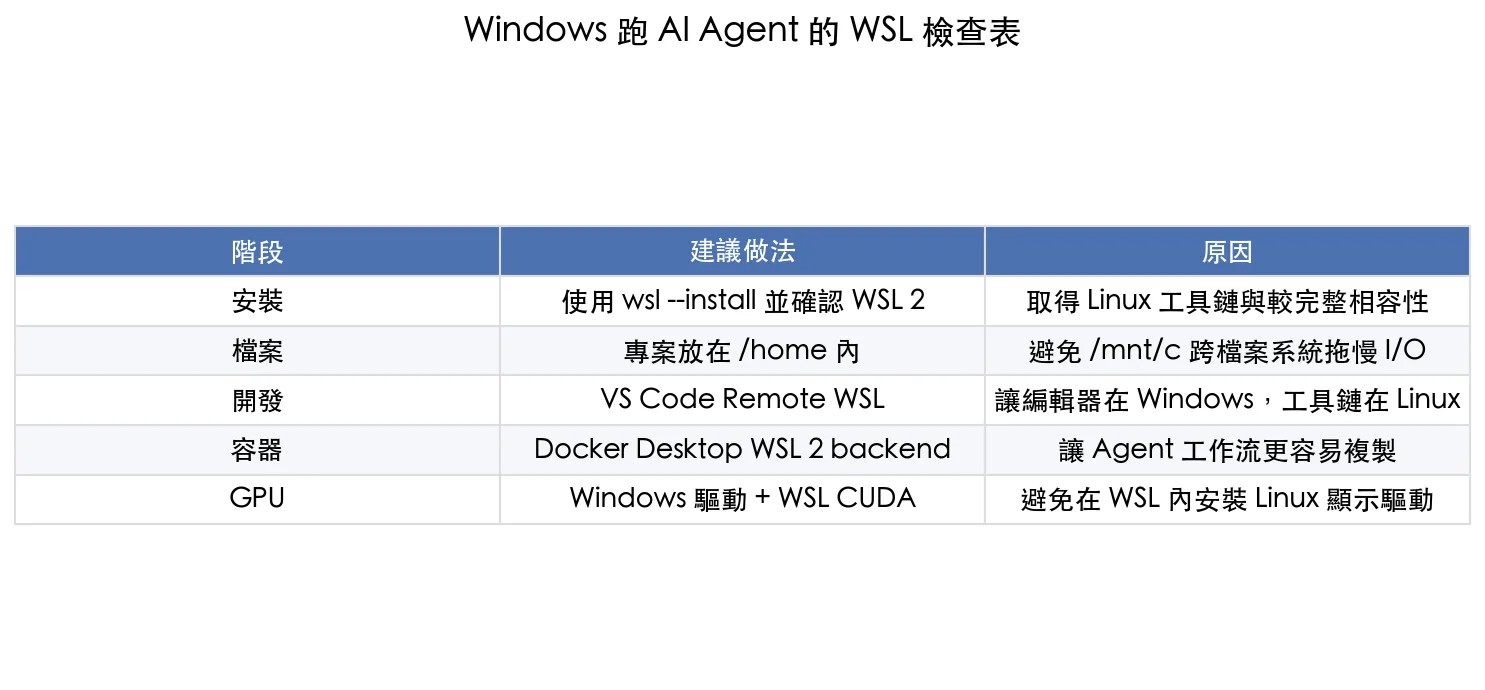
Windows 11 或新版 Windows 10 可以用 `wsl –install` 安裝 WSL,預設會走 WSL 2。
AI Agent 專案建議放在 WSL 的 `/home` 目錄,不要長期放在 `/mnt/c`。
VS Code 建議用 Remote WSL,讓編輯器在 Windows,工具鏈在 Linux。
Docker Desktop 可以啟用 WSL 2 backend,適合需要容器化 Agent 服務的人。
NVIDIA GPU 可以在 WSL 2 裡用 CUDA,但重點是安裝 Windows 端驅動,不要在 WSL 裡裝 Linux 顯示驅動。
為什麼 Windows 跑 AI Agent 需要 WSL
Microsoft 對 WSL 的定位很清楚:讓開發者可以在 Windows 上直接使用 Linux distribution、Linux 應用、工具和 Bash 命令列,而且不需要傳統虛擬機或雙系統。對 AI Agent 來說,這剛好補上 Windows 和開源工具鏈之間的落差。
很多 Agent 專案會同時碰到 Python、Node、Playwright、ffmpeg、SQLite、Docker、Git hooks、shell scripts。這些東西在 Linux 裡比較自然,在 Windows 原生環境則容易遇到路徑、權限、編碼、套件編譯和命令差異。
如果你正在使用 Codex 與 ChatGPT Work ,或想把 OpenWork 和 OpenCode 桌面工作台 跑穩,WSL 可以讓 Windows 變成比較舒服的 Agent 開發機,而不是一直在修環境。
第一步:安裝與確認 WSL 2
Microsoft 官方文件建議,在符合版本的 Windows 上,可以用系統管理員 PowerShell 執行:
安裝後可以用下面指令查看 distribution 和 WSL 版本:
如果你有多個 Linux distribution,可以用 `wsl.exe –set-default` 設定預設環境。對大多數 AI Agent 使用者,我會建議先用 Ubuntu,原因不是它最酷,而是教學、套件、問題排查和相容性資料最多。
第二步:專案不要放在 /mnt/c
這是最常見的坑。Microsoft 文件明確建議,如果你主要在 Linux 命令列裡工作,專案檔案應該放在 WSL 檔案系統內,例如 `/home/你的帳號/projects`。不要把主要專案放在 `/mnt/c/Users/…` 下面長期開發。
原因是跨 Windows 和 Linux 檔案系統會影響效能,也可能讓檔案權限、大小寫、watcher、node_modules、Python venv 出現奇怪問題。AI Agent 工作流常常有大量小檔案、快取、套件安裝和檔案監看,這種差異會被放大。
簡單說:Linux 工具鏈處理的專案,就放 Linux 檔案系統,需要從 Windows 檔案總管打開時,可以在 WSL 目錄下執行:
explorer.exe .第三步:VS Code 用 Remote WSL
不要把 VS Code 直接開在 Windows 路徑裡,再讓終端機切來切去。比較乾淨的方式是安裝 VS Code 的 WSL 支援,從 WSL 裡開專案:
code .這樣 UI 還是在 Windows,但 extension host、terminal、語言服務和套件環境會跑在 WSL。對 Python、Node、Rust、Go、Docker compose、Playwright 這類 Agent 常用工具,這種模式會少很多不必要的摩擦。
第四步:Docker 交給 WSL 2 backend
很多 AI Agent 工具會需要資料庫、瀏覽器服務、向量資料庫、Redis、sandbox 或 API mock。這時候 Docker 是很自然的選擇。Docker Desktop 支援 WSL 2 backend,可以讓 Windows 上的容器工作流更接近 Linux。
我會把它看成「可複製環境」的保險。今天你在 Windows WSL 跑得起來,明天移到 Linux server 或雲端 VM,踩坑會少很多。這和我之前整理 Docker 跟 command line 一樣使用 的方向一致,容器不是炫技,而是讓環境可重現。
第五步:GPU 和 CUDA 要小心裝
如果你要跑本地模型、推理框架或 CUDA 工具,WSL 2 可以吃到 NVIDIA GPU,NVIDIA 官方文件的關鍵提醒是:安裝 Windows 端 NVIDIA 驅動後,CUDA 驅動會映射進 WSL,不要在 WSL 裡安裝 Linux 顯示驅動。
這點很重要。很多人一進 Ubuntu 就照 Linux 教學裝完整 NVIDIA driver,反而把環境弄壞,WSL 裡需要的是相容的 CUDA toolkit 和使用者空間工具,不是另一套 Linux 顯示驅動。
如果你在 Windows 上遠端連自己的 AI server,可以參考我之前寫的 Windows PowerShell 連接 Ollama AI Server 。如果是要本機推理,則更需要把 WSL、GPU driver、CUDA 和模型框架的版本關係先整理好。
Windows 跑 AI Agent 的 WSL 檢查表
階段 建議做法 原因 安裝 使用 wsl –install 並確認 WSL 2 取得 Linux 工具鏈與較完整相容性 檔案 專案放在 /home 內 避免 /mnt/c 跨檔案系統拖慢 I/O 開發 VS Code Remote WSL 讓編輯器在 Windows,工具鏈在 Linux 容器 Docker Desktop WSL 2 backend 讓 Agent 工作流更容易複製 GPU Windows 驅動 + WSL CUDA 避免在 WSL 內安裝 Linux 顯示驅動
WSL 跑 AI Agent 的重點不是只把 Ubuntu 裝起來,而是把檔案、編輯器、容器和 GPU 全部放在正確位置。 我會怎麼配置一台 Windows AI Agent 機
如果是我自己整理一台 Windows AI Agent 工作機,我會照這個順序來:
Windows Terminal 裝好,PowerShell 和 Ubuntu 分開使用。
WSL 2 裝 Ubuntu,專案目錄固定放在 `/home`。
VS Code 用 Remote WSL 開專案。
Python 用 uv 或 venv 管,Node 用 nvm 或 corepack 管。
需要服務就用 Docker compose,不把資料庫亂裝在 Windows 裡。
需要本地模型時,先確認 NVIDIA Windows driver、WSL kernel、CUDA toolkit 和推理框架版本。
如果你的目標是 本地大模型推理框架 ,WSL 可以讓 vLLM、SGLang、llama.cpp、Ollama 周邊工具更接近 Linux 使用方式。如果你的目標是 Agent 開發,WSL 則可以讓 shell、瀏覽器自動化、檔案操作和套件安裝更穩。
我的判斷
Windows 不需要變成 Mac,也不需要硬裝成 Linux。最好的方式是讓 Windows 做它擅長的事:桌面、驅動、硬體管理、遊戲和日常軟體。讓 WSL 做它擅長的事:Linux 工具鏈、開源套件、容器、AI Agent 環境。
真正穩的 Windows AI Agent 工作流,不是把所有東西混在同一個地方,而是把邊界分清楚。Windows 管外層,WSL 管開發環境,Docker 管可重現服務,GPU driver 留在 Windows,專案檔案留在 Linux 檔案系統。這樣才比較不會每次換工具就重修一次環境。
延伸資源
FAQ
Windows 跑 AI Agent 一定要用 WSL 嗎?
不一定,但如果工具鏈偏 Linux、需要 Python、Node、Docker、CUDA 或多個開源套件,WSL 2 通常比純 Windows 環境穩定。
WSL 專案檔案應該放哪裡?
如果主要在 Linux 命令列工作,專案最好放在 WSL 的 `/home` 目錄,不要放在 `/mnt/c`,這樣 I/O 效能和權限行為通常比較穩。
VS Code 可以直接編輯 WSL 專案嗎?
可以。建議使用 VS Code Remote WSL,讓編輯器留在 Windows,語言工具鏈、終端機和套件環境跑在 WSL 裡。
WSL 可以用 NVIDIA GPU 嗎?
可以,但要用支援 WSL 的 Windows NVIDIA 驅動。重點是不要在 WSL 裡安裝 Linux 顯示驅動,CUDA 驅動會從 Windows 端映射進 WSL。
Docker Desktop 和 WSL 2 有什麼關係?
Docker Desktop 可以使用 WSL 2 backend,讓 Windows 上的容器工作流更接近 Linux 開發環境,適合需要複製 AI Agent 服務環境的人。
by Rain Chu 7 月 11, 2026 | Agent , AI , 程式開發
如果把 Lovable 只看成「用 AI 幫你寫程式」的工具,會低估它真正有趣的地方。它更像是一種產品代理人,把想法、介面、資料庫、登入、部署和迭代放到同一個工作流裡,讓原本要跨過工程門檻的人,可以直接從需求開始往產品推進。
我會把 Lovable 放在跟 Manus AI 與 OpenManus 這類 AI 代理工具 相近的位置來看。差別在於,Manus 更像是可以被交辦任務的通用代理人,Lovable 則更專注在把一個產品想法變成可以看、可以試、可以部署的 web app。
Lovable 真正賣的是產品速度
Lovable 官方文件把自己定義為 full-stack AI development platform,它不是只產生前端畫面,而是用自然語言建立、迭代、部署 web app,並且可以把前端、後端、資料庫、驗證與整合放進同一個工作流裡,對非工程背景的人來說,這件事的意義很直接。你不用先學完整開發流程,才有資格驗證一個產品想法。
這也是為什麼 Lovable 這類工具會和一般 no-code 平台不同,no-code 過去常常卡在模板與元件限制,AI app builder 則把入口改成對話,使用者先描述要做什麼,再透過一次次回饋修出接近產品的樣子,這個方向也和 Vibe Coding 工具正在重新定義開發流程 的趨勢一致,只是 Lovable 把目標族群拉得更寬,從開發者延伸到創辦人、產品經理、設計師、行銷和小團隊。
從最小可行產品,走向最小讓人喜愛的產品
我最喜歡的不是「AI 可以幫你做 app」這句話,而是創辦人談到的產品觀。不要只停在 minimum viable product,也就是最小可行產品,而是往 minimum lovable product MLP 靠近,這個差異很關鍵。
MVP 的精神是用最少成本驗證假設,它很有效,但也很容易被誤用成「只要勉強能用就好」,MLP 則多問了一層問題,這個東西有沒有小到可以快速交付,同時又好到讓第一批使用者真的願意留下來、推薦它、甚至開始依賴它。
AI 工具讓做出 MVP 的成本下降,反而讓「可行」變得不夠稀缺,以前做出能跑的產品就值得驚訝,現在使用者可能一天看過十個 AI 做出來的 demo,真正有差異的,是誰能更快找到讓人喜歡的細節,例如流程順不順、介面是否一眼懂、錯誤狀態是否貼心、資料是否真的能解決工作裡的麻煩。
Lovable 跟 Manus AI 像在哪裡
Lovable 和 Manus AI 都不是單純聊天機器人。它們的共同點是把「理解需求」和「執行任務」接起來。差別只是在任務邊界不同。
面向 Lovable Manus AI 類工具 主要任務 把產品想法變成 web app 把複雜任務拆解並執行 輸出型態 網站、SaaS、內部工具、可部署應用 報告、研究、網頁、資料分析、流程結果 使用入口 用自然語言描述產品需求並迭代 交辦目標,讓代理人規劃步驟 適合場景 創業驗證、產品原型、內部工具 研究、營運、分析、自動化任務 核心價值 縮短從 idea 到可用產品的距離 縮短從任務到成果的距離
從這個角度看,Lovable 不是要取代所有工程師,而是把產品探索的前段變得非常快。當需求還不穩、方向還在找、使用者還沒給出明確反饋時,用完整團隊慢慢打磨可能太重。Lovable 的價值是在這段模糊期中,讓更多人有能力把想法變成可以被使用者碰到的東西。
為什麼 MLP 比 MVP 更適合 AI 時代
AI 時代最大的變化,不只是生產速度變快,而是原型數量暴增。當每個人都能很快做出一個看起來像產品的東西,市場會更快對粗糙作品失去耐心。這時候,產品判斷會從「能不能做出來」移到「能不能讓人想用第二次」。
MLP 的思考可以拆成三個問題。
它是否小到可以快速完成,不會卡在過度設計。
它是否完整到足以處理一個真實情境,不只是展示用 demo。
它是否有一個讓人喜歡的瞬間,讓使用者願意繼續互動。
這三件事剛好也是 AI app builder 的強項。它能快速生成,也能快速修改。創辦人或產品負責人可以把時間從「如何把東西做出來」轉到「這個東西為什麼值得被喜歡」。這一點比單純追求開發效率更重要。
給創辦人的使用方式
如果要用 Lovable 驗證產品,我不會建議一開始就把它當成完整 SaaS 工廠,而是當成產品假設測試器。你可以先把需求寫得非常具體,例如目標使用者是誰、他現在用什麼替代方案、最痛的流程是哪一步、成功狀態長什麼樣子。
接著用 Lovable 做出第一個可互動版本,找少數真正有痛點的人試用。重點不是問他們「你覺得如何」,而是觀察他們是否願意把自己的資料放進去、是否願意第二天再打開、是否願意為了這個工具改變原本流程。這比一句稱讚更有價值。
如果要再往工程落地走,還是需要開發紀律,像 用 Superpowers 建立 AI 開發紀律 這類方法提醒的是,AI 生成速度越快,越需要規格、測試、版本控制和驗收,Lovable 官方也強調可同步 GitHub,這代表它不是只能停在玩具原型,也可以接回工程流程。
這類產品會把 AI 代理帶到更實際的位置
AI 代理最怕的是太抽象。大家都說代理人可以幫你完成任務,但真正有價值的產品,通常會先鎖定一個高頻、具體、有付費意願的任務。Lovable 鎖定的是 app builder。這讓它比泛用代理人更容易被理解,也更容易產生可見成果。
這也能連到最近 Codex 與 ChatGPT Work 走向 AI 代理 的方向。未來的競爭不一定是誰的模型最會聊天,而是誰能把模型、工具、權限、部署、記憶和工作流包成一個讓人放心交付任務的產品。Lovable 在產品開發這個垂直場景裡,已經把這條路講得很清楚。
我的結論
Lovable 最值得看的,不是它能不能用一句 prompt 變出網站,而是它把產品開發的問題重新排序了。以前先問能不能做,現在更該問能不能讓人喜歡。以前 MVP 是驗證市場的低成本方法,現在 MLP 會變成 AI 時代更重要的產品標準。
因為能做出來的東西會越來越多,真正稀缺的會是判斷力。知道該做多小,知道哪裡不能省,知道哪個細節會讓使用者留下來。Lovable 這類工具的價值,不是讓每個人都變成工程師,而是讓更多人有機會更早面對真正的產品問題。
延伸資源
FAQ
Lovable 是什麼?
Lovable 是一個 AI app builder,可以用自然語言建立、迭代和部署 web app。它的重點不是只產生程式碼,而是把產品想法推進到可互動、可測試、可部署的狀態。
Lovable 跟 Manus AI 有什麼不同?
兩者都接近 AI 代理產品。Manus AI 偏向通用任務執行,Lovable 則聚焦在 web app 和產品開發,把想法、介面、資料庫、部署與迭代串在一起。
為什麼最小讓人喜愛的產品比 MVP 更重要?
AI 讓做出可行原型的成本下降,市場上會出現更多相似 demo。這時候只是能用不夠,產品還要有讓使用者願意留下來的體驗和價值。
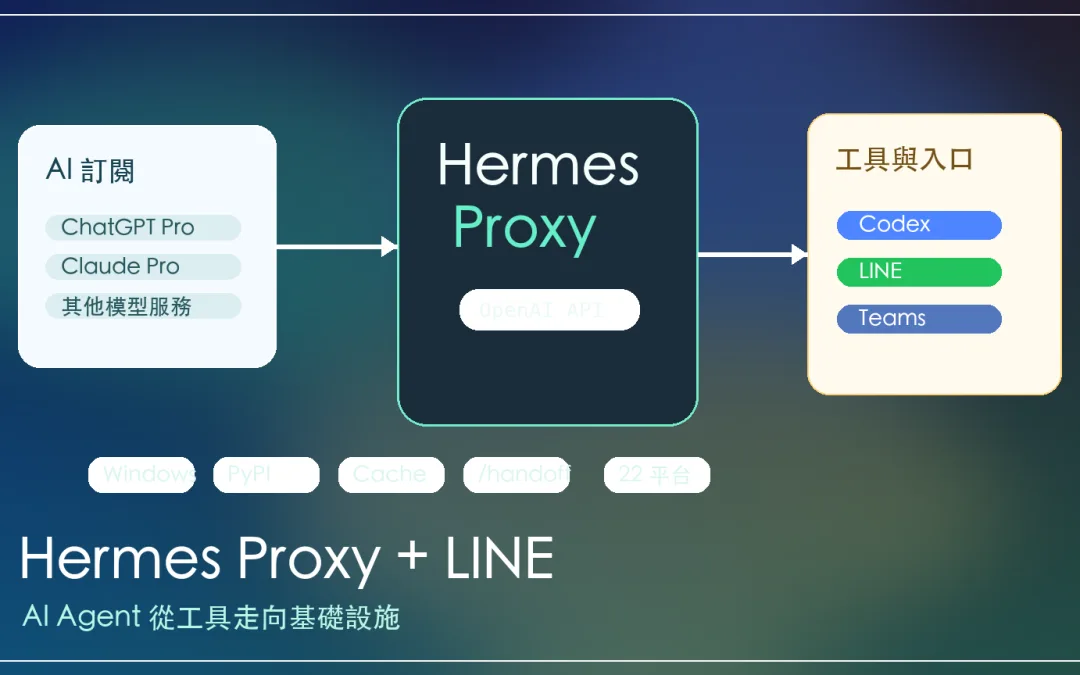
by Rain Chu 7 月 10, 2026 | Agent , AI , Hermes
Hermes Agent v2026.5.16 這次最值得看的,不是功能清單變長,而是它開始從「開源 AI Agent 玩具」往「可以被日常使用、跨工具接入、跨平台部署的基礎設施」移動。
我會把這次更新的重點放在兩件事:第一是 Hermes Proxy ,它把你手上的 AI 訂閱轉成 OpenAI 相容端點,讓 Codex、Aider、各種只吃 API 的工具有機會共用同一套訂閱資源,第二是 支援 LINE ,這代表 Agent 不再只是終端機裡的工具,而可以進到大家每天真的會打開的通訊入口。
如果你之前看過站上的 Hermes Agent 完整實測 ,那篇比較像認識 Hermes 的核心能力,這篇則聚焦在 v2026.5.16 之後,它怎麼變得更適合放進真實工作流。
先講結論:Hermes 正在補「基礎設施」這塊
很多 AI Agent 專案一開始都很炫,但卡在幾個現實問題:Windows 使用者不好裝、安裝流程太工程師、啟動太慢、外部工具接不進來、通訊平台支援不完整、安全性也不一定能被團隊接受。
Hermes Agent v2026.5.16 的 Foundation Release,剛好就是在處理這些比較不性感、但非常關鍵的底層問題。它包含 Windows 原生支援、PyPI 安裝、冷啟動加速、CDP 呼叫加速、Hermes Proxy、跨 session 快取、`/handoff`、LINE / Teams 等 22 個通訊平台、供應鏈安全掃描,以及新的 vision / X 搜尋工具。
這類更新不一定每個都會讓人眼睛一亮,但它們合在一起,代表 Hermes 不是只想做 demo,而是想成為可以被部署、被整合、被長期使用的 Agent 系統。
Hermes Proxy:把 AI 訂閱變成工具能吃的 API 入口
Hermes Proxy 是這次我最想拉出來講的功能。
現在很多人手上其實已經有 ChatGPT Pro、Claude Pro 或其他 AI 服務訂閱,但問題是開發工具通常只認 OpenAI 相容 API,你在聊天介面裡可以用的能力,不一定能直接接到 Codex、Aider、OpenCode、CI pipeline 或自己的自動化腳本裡。
Hermes Proxy 的想法,是在本機跑一個 OpenAI 相容端點,讓上層工具以為自己正在呼叫一般 API,但後面實際連到的是你已經訂閱的 AI 服務,用比較白話的方式說,它像是一個「訂閱轉接器」:工具只要會講 OpenAI API 格式,就有機會透過 Hermes Proxy 使用不同 AI 服務。
這跟站上之前整理的 AISA 一個 API Key 連上多種資源 有一點相似:核心都不是單一模型,而是「資源層」。差別是 AISA 偏向外部 API 與技能資源整合,Hermes Proxy 則更像本機開發工具和 AI 訂閱之間的橋。
為什麼 Hermes Proxy 對 Codex 使用者有感?
如果你的主要工作介面是 Codex,Hermes Proxy 的吸引力在於:它可能把「聊天訂閱」和「開發工具 API」之間的牆變薄。
很多工具都有一個共同限制:它們可以接 OpenAI 相容 API,但不能直接使用你在瀏覽器登入的 Pro 訂閱。這會造成一種很尷尬的狀況:你明明已經付了訂閱費,實際做 automation 或 coding agent 時卻還要另外付 API 費。
Hermes Proxy 不是魔法,也不代表所有服務都能無限制、無成本地被轉接。真正部署前還是要確認各家服務條款、登入方式、速率限制和穩定性。但方向很清楚:把模型資源抽象成統一端點,讓工具選擇不再被單一 API 形態綁死。
這也和 OpenWork / OpenCode 桌面工作台 這類工具的需求接在一起,當本地 Agent 工作台越來越多,誰能穩定提供模型、工具、通訊平台與權限管理,誰就更接近真正可用的工作環境。
支援 LINE:Agent 從終端機走進日常入口
另一個我覺得很重要的更新,是 LINE Messaging API 變成 Hermes 的一等平台,同一波也提到 SimpleX Chat、Teams pipeline、Webhook adapter,整體支援平台數來到 22 個。
LINE 支援的價值不只是在「多一個聊天入口」,對台灣、日本和許多亞洲使用者來說,LINE 就是日常工作和生活的入口。Agent 如果只能待在終端機或瀏覽器,其實離一般使用場景還有一段距離,但如果它能進 LINE,就有機會變成隨手派任務、收通知、接收摘要的個人助理。
想像一下:你在路上用 LINE 傳一句「幫我整理今天重要郵件」、「把這個連結存成研究筆記」、「提醒我晚上回覆某個客戶」,後面由 Hermes 去接 Teams、Email、Webhook、模型和工具。這才是 Agent 真正進入生活流程的樣子。
站上以前也寫過 WooCommerce 透過 LINE 通知訊息 ,那是把系統事件推到 LINE,Hermes 這類 Agent 平台則更進一步,不只是通知,而是讓 LINE 變成可以對 Agent 下指令的入口。
Windows 原生與 PyPI:降低安裝門檻才有機會普及
這次還有兩個很務實的更新:Windows 原生支援,以及 `pip install hermes-agent`。
Windows 原生支援的意義很大。以前很多開源 AI 工具對 Windows 使用者都不太友善,不是要求 WSL,就是建議 Docker。這對工程師或許還可以接受,但對想試用 Agent 的一般使用者、產品經理、營運、內容工作者來說,門檻就高了很多。
現在 Hermes 可以在 CMD.exe 和 PowerShell 原生執行,對「公司電腦多半是 Windows」的場景尤其重要。再加上 PyPI 標準化安裝,管理版本、依賴和升級都比較符合 Python 生態的習慣。
我也查了 PyPI,`hermes-agent` 套件目前確實存在,套件摘要寫的是 self-improving AI agent,並標示 Python 版本需求為 3.11 以上、低於 3.14。這點對部署很重要,因為你不能只看安裝指令,還要確認 Python 版本。
pip install hermes-agent
hermes 效能更新:Agent 不能每次都讓人等
Hermes 這次也強調冷啟動約少 19 秒、`hermes tools all-platforms` 從十幾秒降到約 1.5 秒內,以及瀏覽器 CDP 呼叫透過持久 WebSocket 連線提升到 180 倍。
這些數字看起來像效能細節,但對 Agent 產品很關鍵。Agent 的工作流常常是「開一下、問一下、跑一下工具、再切回來」,如果每一步都慢,使用者很快就會放棄。速度不是錦上添花,而是能不能被日常使用的門檻。
這也呼應我最近整理的 Grill Me 需求訪談工作流 :Agent 要好用,不能只靠模型聰明,前面要把需求問清楚,中間要能快速呼叫工具,後面還要能保存上下文和交接狀態。
快取與 /handoff:模型不該是一次選死
跨 session 快取和 `/handoff` 也是這次值得看的設計。
跨 session 快取可以讓重複工作更快恢復,尤其是長任務、多輪對話、固定專案背景。
`/handoff` 則是把目前對話、工具呼叫、上下文轉移到另一個模型、角色或設定檔。這代表模型不再是一開始就選死,而是可以隨著任務階段切換。
例如架構設計階段用一個模型,實作階段換另一個模型,摘要或低成本批次處理再換成本更低的模型,這種彈性如果搭配 Hermes Proxy,就會變得更有意思:模型資源、訂閱資源、工具入口都被抽象出來,Agent 才有機會變成可調度的系統。
供應鏈安全:從開源專案走向團隊部署必補的一課
Hermes 這次也把供應鏈安全放進更新裡,包括安裝時掃描依賴套件、比對安全通報、Lazy Libs 延遲載入,以及在某些 wheel 不適用時做 fallback。
這類內容對個人玩家可能比較無感,但對公司或團隊很重要。AI Agent 如果要進入企業環境,不能只回答「好不好玩」,還要回答「能不能被安裝」、「依賴是否安全」、「出問題能不能追」、「部署會不會卡在平台相容性」。
所以我才會說這次 Foundation Release 的重點,不只是多了功能,而是 Hermes 開始補齊作為基礎設施需要具備的條件。
新工具與技能:從文字走向多模態與社群搜尋
新版也提到 `vision_analyze` 和 `x_search`,前者可以把畫面交給具備視覺能力的模型分析,適合錯誤畫面、UI 問題、截圖診斷,後者則把 X / Twitter 搜尋變成 Hermes 的一等工具。
再加上 9 個新技能,Hermes 的方向越來越明確:它不只是聊天,也不是單純工具集合,而是要把工具、通訊、模型、記憶、技能生成整合成一個能持續進化的 Agent 系統。
如果你關心本地 Agent 和模型搭配,可以接著看 Ornith 35B 配 Hermes 工作流 ,那篇更偏本地模型和 agentic coding,這篇則偏 Hermes 平台本身的基礎設施更新。
我會怎麼看這次更新?
我覺得 Hermes Agent v2026.5.16 的關鍵,不是「它現在支援很多平台」這句話,而是它開始回答一個更大的問題:AI Agent 要如何真正活在我們每天使用的工具裡?
Hermes Proxy 回答的是模型與訂閱資源如何被工具使用
LINE 支援回答的是 Agent 如何進入日常通訊入口
Windows 與 PyPI 回答的是一般使用者怎麼開始
快取、handoff、效能與安全則回答的是長期使用能不能穩
如果你已經在玩 Hermes,這次最值得優先測的就是 Hermes Proxy 和 LINE,前者關係到你能不能把 AI 訂閱接進更多開發工具,後者關係到 Agent 能不能從「我打開電腦才會用」變成「我在手機上也能派任務」。
FAQ
Hermes Proxy 是什麼?
Hermes Proxy 是 Hermes Agent 內建的本地代理層,目標是提供 OpenAI 相容端點,讓支援 OpenAI API 格式的工具可以接到不同 AI 服務或訂閱資源。
Hermes 支援 LINE 代表什麼?
LINE Messaging API 成為 Hermes 的一等平台後,使用者可以把 LINE 當成和 Agent 對話、派任務、收通知的入口,讓 Agent 更接近日常使用場景。
Hermes Agent 怎麼安裝?
目前可以透過 PyPI 安裝:`pip install hermes-agent`,再執行 `hermes` 啟動。PyPI 資訊顯示它需要 Python 3.11 以上、低於 3.14。
這次 Foundation Release 最重要的是什麼?
最重要的是 Hermes 開始補齊基礎設施能力,包括 Windows 原生、PyPI 安裝、Hermes Proxy、LINE/Teams 等通訊平台、效能優化、快取/handoff 和供應鏈安全。
by Rain Chu 7 月 8, 2026 | Agent , AI , 語音合成 , 語音辨識
Hugging Face 的 speech-to-speech 真正有趣的地方,不只是「本地 AI 語音聊天」這句話,而是它把即時語音 Agent 拆成一條清楚的工程管線:VAD 偵測你什麼時候開始和結束說話,STT 把語音轉成文字,LLM 產生回應,TTS 再把文字變回聲音。
這條路線的價值很直覺:如果你不想把麥克風聲音、私人對話、公司資料一路送到雲端,那就把語音 Agent 搬回自己的機器。代價也很明顯:你要處理 Python、FFmpeg、CUDA、模型下載、本地 LLM server、TTS 後端、瀏覽器端 WebSocket。這不是「安裝一個 App 就結束」的工具。
如果你之前看過 VoxelCPM 本地 TTS ,這篇可以當成下一步:TTS 只是讓 AI 開口,speech-to-speech 則是把「聽、想、說」接成一個即時循環。
先講結論:它不是語音模型,而是一條可替換的語音 Agent 管線
huggingface/speech-to-speech 的 README 把架構講得很清楚:這是一條低延遲、模組化的 voice-agent pipeline,順序是 VAD → STT → LLM → TTS,並且透過 OpenAI Realtime-compatible WebSocket API 對外提供服務。
也就是說,你可以把支援 OpenAI Realtime 協議的 client 指到本機 server。
這個設計比單純做一個 demo 更有意思,因為每一段都能換。
STT 可以用 Parakeet、Whisper、Faster Whisper、MLX Whisper 或 Paraformer;LLM 可以接 OpenAI-compatible provider,也可以接 vLLM、llama.cpp、llama-server;TTS 可以用 Qwen3-TTS、Kokoro、Pocket TTS、ChatTTS 或 MMS TTS。
換句話說,它的重點不是某個模型最強,而是把語音 Agent 做成可插拔架構。
這和 OpenWork / OpenCode 工作台 的方向有點像:真正可長期使用的 AI 工具,不應該只綁死在單一供應商或單一模型。
Speech-to-speech 和傳統語音翻譯有什麼差別?
Hugging Face Audio Course 裡對 speech-to-speech translation 的說明很適合拿來釐清概念。
傳統機器翻譯是文字到文字,speech-to-speech 則是語音到語音。最常見的做法是串接:先把語音轉成文字,再做翻譯或生成,最後合成語音。
它也提醒一個很重要的問題:管線越長,錯誤越會累積,延遲也越高。
ASR 認錯一個字,後面的 LLM 可能照著錯字理解;LLM 回答太長,TTS 就要等更久;TTS 聲音不自然,最後體驗還是會掉下來。
所以本地即時語音 Agent 的關鍵不是只看「能不能講話」,而是看四件事:
語音辨識是不是準,尤其是中文、口音、背景噪音。
LLM 回應是不是夠快,不要讓人等到出戲。
TTS 聲音是不是自然,長時間聽會不會疲勞。
整條管線的延遲是不是穩定,而不是偶爾順、偶爾卡。
官方預設路線:先跑起 realtime server
官方 quickstart 很短:
pip install speech-to-speech
export OPENAI_API_KEY=...
speech-to-speech ws://localhost:8765/v1/realtime
預設路線會用本地 STT、本地 TTS,再把 LLM 接到 OpenAI-compatible API。你如果想讓 LLM 也留在本機,可以用 llama.cpp 啟動本地模型 server,再把 `responses_api_base_url` 指到本機。
speech-to-speech \
--model_name "ggml-org/gemma-4-E4B-it-GGUF" \
--responses_api_base_url "http://127.0.0.1:8080/v1" \
--responses_api_api_key "" Ollama 遠端連線 和本地 OpenAI-compatible server 的設定很重要:語音只是入口,真正回答問題的是後面的 LLM。Windows 實作路線:不是難,是零件很多
核心流程可以簡化成這樣:
裝 Python 3.11、Git、FFmpeg。
建立 `C:\s2s` 之類的資料夾,開 venv。
安裝 `speech-to-speech`。
用 llama.cpp 跑本地 Qwen 模型,開在 `http://127.0.0.1:8080/v1`。
啟動 speech-to-speech,把 STT 指到 Whisper、LLM 指到本地 server、TTS 指到 Qwen3-TTS。
開網頁 client,WebSocket 指到 `localhost:8765`。
這裡最容易踩坑的是 FFmpeg 和 winget。留言裡有人遇到 `winget` 找不到,這通常代表 Windows App Installer / winget 沒裝好,或 PowerShell 環境找不到它。這時候不要卡在同一條命令,可以改成手動下載 FFmpeg,或先修好 winget,再重新開 PowerShell。
架構表:每一段都可以替換,但每一段也都會出事
階段 作用 常見選擇 容易卡住的地方 VAD 判斷使用者何時開始/停止說話 Silero VAD 背景噪音、切句太早或太晚 STT 語音轉文字 Parakeet、Whisper、Faster Whisper 中文辨識、口音、GPU/CPU 速度 LLM 理解問題並產生回應 OpenAI-compatible API、llama.cpp、vLLM、Ollama 類服務 延遲、上下文長度、模型能力 TTS 文字轉語音 Qwen3-TTS、Kokoro、Pocket TTS、ChatTTS 聲音自然度、CUDA wheel、中文品質 Client 麥克風輸入與播放 Realtime WebSocket client、網頁呼吸球介面 瀏覽器權限、WebSocket 位置、服務啟動順序
這張表就是我對本地語音 Agent 的看法:模組化很香,但你不能只看成功 demo 任一段延遲太高、模型太大、依賴裝錯、WebSocket 指錯,都會讓整體體驗掉下來。
4GB 顯存、4090、CPU:期待值要分開看
如果你只是想體驗,本地小模型加 CPU/GPU 混跑可以試;如果你想每天使用,就要認真看顯卡、VRAM、記憶體、模型大小與量化格式。這部分可以搭配 AI 工作站顯卡選購 那篇看,因為語音 Agent 不是只吃一個模型,而是一整條 pipeline。
本地部署值不值得?
安裝太複雜、Python 依賴一直重裝、免費雲端語音也能用、中文場景不一定比微信等現成工具舒服。
我會這樣判斷:
如果你只想偶爾語音聊天 ,雲端 App 更省事。如果你在意隱私、離線、可控模型 ,本地 speech-to-speech 才有意義。如果你要接自己的 Agent 或自動化流程 ,OpenAI Realtime 相容 API 很有價值。如果你不想處理依賴 ,等整合包或 Docker / 一鍵腳本會比較舒服。
有留言建議做整合包,把 Python、虛擬環境、依賴、模型檔都打包好。這個方向很務實。語音 Agent 要走向一般使用者,最重要的可能不是模型再強一點,而是安裝流程少掉一半。
接進 Hermes、OpenWork 或自己的 Agent:語音只是入口
有人問如果部署在 Hermes 裡,是不是就不用打字了。方向是對的,但要分清楚:speech-to-speech 解決的是語音輸入與語音輸出,Agent 真正能不能工作,還要看後面的工具調用、上下文、記憶、權限與任務執行。
也就是說,語音不是 Agent 的全部,只是更自然的控制入口。你可以想像之後用語音叫本地 Agent 幫你查資料、改檔案、跑腳本、操作工作流,但這需要像 OpenWork 或 Hermes Agent 這類工作台或 runtime 來承接任務。
真正有用的組合會是:speech-to-speech 負責「聽和說」,Agent runtime 負責「做事」,本地 LLM / 工具 / MCP 負責「連到你的資料和系統」。語音只是讓人更容易下指令,不能替代完整的任務架構。
資源整理
本地即時語音 Agent 很香,但現在還偏工程師玩具
speech-to-speech 讓本地語音 Agent 的架構變得很清楚:你可以把 VAD、STT、LLM、TTS 串起來,對外提供 OpenAI Realtime 相容 API,再用網頁或其他 client 連進來。這條路很有想像空間,尤其適合隱私敏感、離線使用、機器人、客服、語言練習、自建 AI 助手。
但我不會把它包裝成人人都該裝。現階段它還需要處理太多環境問題,Windows 下尤其明顯。真正適合的人,是願意花時間把本地模型、音訊依賴、GPU、WebSocket 和 Agent runtime 串起來的人。
一句話總結:本地即時語音不是為了取代手機上的語音助手,而是為了把「能聽、能想、能說」這個入口,接到你自己的模型、資料和工作流上。這件事如果跑順,會比單純聊天更有價值。
FAQ
speech-to-speech 是什麼?
speech-to-speech 是 Hugging Face 的開源語音 Agent 管線,透過 VAD、STT、LLM、TTS 四個階段,把使用者語音轉成模型回應,再合成語音輸出。
它可以完全本地運行嗎?
可以,但需要把 STT、LLM、TTS 都換成本地後端,例如 Whisper、llama.cpp 或其他 OpenAI-compatible 本地 LLM server,以及 Qwen3-TTS 等本地語音合成模型。
為什麼不用雲端語音助手就好?
如果只是日常聊天,雲端語音助手更省事。本地方案的價值在於隱私、離線、可控模型、可接自有資料與 Agent 工作流。
by Rain Chu 7 月 8, 2026 | Agent , AI
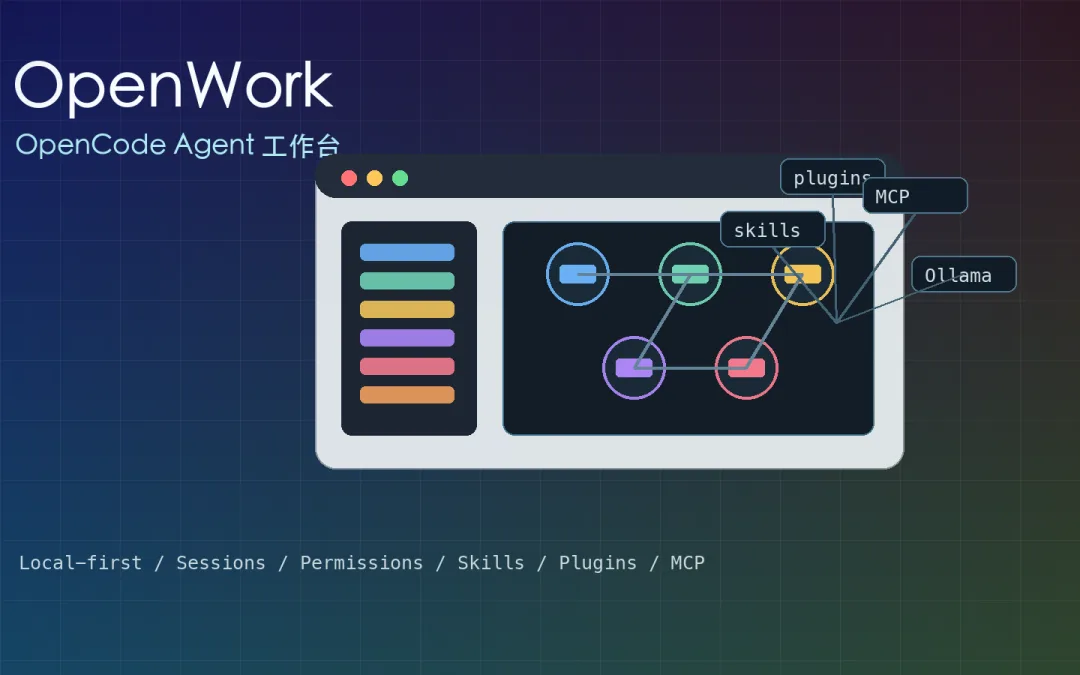
OpenCode 和 OpenWork 這組工具,真正值得看的地方不是「又一個 Claude Code 替代品」而已,而是它把 AI Agent 從純命令列往桌面工作台推了一步, OpenCode 負責 agentic coding 的核心能力,OpenWork 則把工作目錄、Session、Skill、Plugin、MCP、權限確認和遠端 worker 包成比較容易操作的圖形介面。
這條路線剛好踩在很多人的痛點上:Claude Code 好用,但成本、封閉性和模型選擇會卡住;Codex 很適合開發工作,但一般辦公流程、跨工具流程、團隊共享設定,還需要另一層產品化介面, OpenWork 的企圖就是把 opencode 這套底層能力包成「可以給團隊重複使用的 Agent 工作流」。
如果你之前已經在看 OpenCode 如何使用本地端模型 ,這篇可以當成下一步:不只讓模型接進來,而是把 skills、plugins、MCP 和權限流程一起整理成可操作的工作台。
OpenWork 是 opencode 的桌面層,不是另一個單純聊天 App
OpenWork 官方把自己定位成 Claude Cowork 和 Codex 的開源替代方案,它是一個 local-first 的桌面 app,背後 powered by opencode 你可以在本機跑 host mode,也可以用 client mode 連到既有 OpenCode server, 之後透過 UI 管理 session、看 streaming event、處理 permission request、管理 templates、安裝 skills 和 plugins。
這個定位很重要。OpenWork 不是要取代 OpenCode,而是把 OpenCode 原本比較偏開發者的 CLI 體驗,變成更像工作台的產品。OpenCode 擅長讀檔、改檔、跑工具、處理任務;OpenWork 則負責讓這些能力變得可視化、可審核、可分享。
這也是我覺得它和 用 AI 組一家公司 那篇可以放在一起看:真正有價值的不是單一模型多會回答,而是能不能把一套工作流程產品化,讓人、Agent、工具和權限一起運作。
OpenCode 和 OpenWork 的分工
這兩者的分工:
項目 OpenCode OpenWork 核心角色 AI coding agent 與 CLI/Server 核心 桌面工作台與協作介面 使用者體驗 偏工程師、命令列、設定檔 偏圖形介面、session、權限與模板 擴充方式 plugins、agents、SDK、生態資源 skills manager、plugins、MCP、templates 適合場景 開發、專案自動化、終端機工作流 把 Agent 流程包成團隊可重複使用的工作台
OpenWork README 裡有一句很關鍵:它是 ejectable 意思是就算 UI 還沒包到某個能力,只要底層 OpenCode 能做,理論上還是可以回到底層去做。這是開源工具很重要的特性,因為你不會被單一 UI 的產品進度完全卡死。
安裝與模式:先分清楚桌面 App、Host mode、Client mode
OpenWork 有幾種使用方式。最直覺的是下載桌面 app;如果你想自己 build,就要準備 Node.js、pnpm、Bun、Rust/Tauri、OpenCode CLI 官方 source build 流程大致是:
git clone https://github.com/different-ai/openwork
cd openwork
git checkout dev
pnpm install --frozen-lockfile
pnpm dev 如果只想跑 CLI host,也可以用 OpenWork Orchestrator:
npm install -g openwork-orchestrator
openwork start --workspace /path/to/workspace --approval auto
這裡要注意一件事:OpenWork 的 Host mode 會在本機跑 host stack,預設綁在 127.0.0.1 Client mode 則是連到既有的 OpenCode server,如果你看到 ready 是灰色、New task 不能按,第一個方向不是懷疑模型,而是檢查工作目錄、host stack、OpenCode server、provider key 或本地模型連線是否真的準備好。
Skills、Plugins、MCP:OpenWork 真正有用的地方
OpenWork 的 Skills manager 可以列出 `.opencode/skills`,也能把本地 skill folder 匯入到 `.opencode/skills/<skill-name>` 這個方向很像 Claude Code / Codex 的 skills 概念:把常用工作流程寫成可重複使用的操作說明,讓 Agent 每次做事不用從零開始猜。
如果你站上看過 用 skill-creator 建立 Skill ,OpenWork 這裡的邏輯也很接近:與其每次都寫一長串 prompt,不如把工作流程變成可安裝、可分享、可版本化的能力。
Plugin 則是 OpenCode 的原生擴充方式。OpenWork 會讀寫 `opencode.json`,Project scope 在工作目錄的 `opencode.json`,Global scope 通常在 `~/.config/opencode/opencode.json`。
awesome-opencode 這個 repo 則像是生態目錄,整理了 plugins、themes、agents、projects 和 resources 它不是核心工具,但很適合用來觀察 opencode 生態正在長出哪些周邊能力。
Build Mode 和 Plan Mode:不要一開始就讓 Agent 放手改
OpenCode 這類 agentic tool 最容易出問題的地方,是使用者還沒搞清楚任務邊界,就直接讓 Agent 進入執行狀態。比較穩的做法是先用 Plan Mode 讓它讀資料、拆任務、確認工具與風險,再進 Build Mode 讓它動手。
我會把它想成兩層:
Plan Mode :先觀察、讀檔、列步驟、找不確定性、提出執行順序。Build Mode :開始改檔、跑命令、安裝依賴、呼叫工具、產出結果。
這和 Claude Code Workflow 裡的做法一致:先讓 Agent 把路線講清楚,再授權它動手。
AI Agent 的效率不是靠更衝,而是靠每一步都能回頭檢查。
本地模型與 Ollama:重點在 provider 設定,不是只裝好模型
很多人以為「Ollama 已經能跑模型」就等於 OpenWork 會自動看到它,但中間還差 provider 設定、base URL、模型名稱,以及 OpenCode / OpenWork 讀取設定檔的位置。
原則上,你要確認三件事:
Ollama server 已經在跑,常見位置是 `http://localhost:11434`,遠端機器則要確定防火牆與 bind address。
OpenCode 的 provider 設定有指到 Ollama 或 OpenAI-compatible endpoint。
OpenWork 使用的 workspace / dev-mode / global config,和你實際編輯的設定檔是同一份。
這部分可以搭配 Ollama 遠端連線教學 和 LM Studio 與 Ollama 的零 API 成本環境 一起看 OpenWork 不是魔法入口,它還是要靠底層 provider 設定把模型接起來。
Token 成本:免費模型不等於無限使用
免費通常代表某段時間、某個額度、某個服務條款下不用付費,不代表可以無限燒,也不代表 latency、rate limit、上下文長度和品質都沒有代價。
OpenCode / OpenWork 這種工具特別容易消耗 token,因為 Agent 會讀檔、反覆規劃、呼叫工具、看輸出、再修正你讓它處理一個大型 workspace,成本不是只有最後回答那幾百字,而是整個工作循環。
所以比較實際的策略是:
簡單查詢與短任務用便宜或本地模型。
高風險修改、跨檔案重構、複雜判斷再用強模型。
能寫成 skill / template 的流程就固化,減少每次重新解釋。
先 Plan 後 Build,避免 Agent 一路試錯燒成本。
Windows 使用者要先注意的幾個坑
Windows 問題不少,這也很符合這類 Tauri / Node / CLI 混合工具的現況。
OpenWork README 也有提到,Windows access 有一部分是透過 paid support plan;source build 則會牽涉 Node、pnpm、Bun、Rust、Tauri 和 OpenCode CLI。這不是一般雙擊安裝就結束的輕工具。
Ready 灰色 :先檢查 host stack 是否啟動、workspace 是否選對、provider 是否可用。New task 灰色 :通常表示前置狀態未完成,例如沒有有效 session、工作目錄或 worker 尚未 ready。nul 檔案問題 :Windows 下 `nul` 是特殊裝置名,如果工具誤產生同名檔,刪除會很麻煩。這種問題要優先回報 issue,並避免在重要目錄直接測不穩定版本。`.config` 目錄看起來不對 :要確認你看的到底是 OpenCode global config、workspace config,還是 dev-mode 隔離狀態。
這裡我會建議用比較保守的方式測:先開一個乾淨測試資料夾,不要直接指到重要專案;先確認 session、provider、permission、簡單讀寫任務都正常,再把 OpenWork 放進真正的工作流程。
OpenWork 適合誰?
OpenWork 現階段比較適合三種人。
第一種是想把 OpenCode 圖形化的人。 你已經接受 agentic coding,但希望有 session、permission、skills、plugins 的視覺工作台。第二種是想把 Agent 工作流交給團隊的人。 Templates、skills、remote sharing 這些能力,重點都是讓流程可以重複與分享。第三種是正在比較 Claude Code、Codex、OpenCode 生態的人。 OpenWork 讓 opencode 不只停留在 CLI,而是開始往產品化入口走。
但如果你現在只想要一個穩定、少設定、打開就能工作的辦公 AI,OpenWork 可能還會讓你覺得太工程化。它的價值在於可控與可擴充,不在於完全隱藏複雜度。
資源整理
截至我整理資料時,OpenWork GitHub repo 約 1.6 萬 stars,awesome-opencode 約 8 千多 stars 這代表生態正在被快速關注,但也代表文件、Windows 體驗、plugin 相容性和錯誤處理還會持續變動。用它之前要有「早期開源工具」的心理預期。
OpenWork 把 OpenCode 從工具變成工作台
OpenCode 已經回答了「AI Agent 能不能在 terminal 裡幫我做事」;OpenWork 想回答的是下一題:「這套能力能不能被包成一個可視化、可分享、可審核的工作台?」
現階段最好的用法,是先用 OpenCode 跑穩本地模型、provider、skills 和 plugins,再用 OpenWork 管理 session、權限、template 與團隊共享流程。
OpenWork 的重點不是多一個聊天視窗,而是讓 opencode 的 Agent 能力開始變成「可交付的工作流程」。這會是 2026 年 AI 工具很重要的一條線。
FAQ
OpenWork 是什麼?
OpenWork 是 powered by opencode 的開源桌面工作台,讓使用者在本機或遠端 server 上管理 AI Agent session、skills、plugins、MCP、templates 與權限確認。
OpenWork 和 OpenCode 有什麼差別?
OpenCode 是底層 AI coding agent 與 CLI/Server 核心;OpenWork 是圖形化桌面層,負責把 session、權限、skills、plugins、templates 與工作目錄變得更容易操作。


近期留言