by Rain Chu | 4 月 18, 2026 | AI, Hermes
🧠 Hermes Agent 是什麼?
Hermes Agent 是由 Nous Research 推出的開源 AI Agent 框架,具備:
- 🔁 跨對話記憶(Memory)
- 🧠 技能(Skill)可持續累積
- 🌐 內建網頁瀏覽與工具調用
- ⏱️ 任務排程(Cron-like)
- 🔌 OpenAI 相容 API(可接各種 LLM)
👉 本質上,它不是單純聊天機器人,而是「可執行任務的 AI 系統」
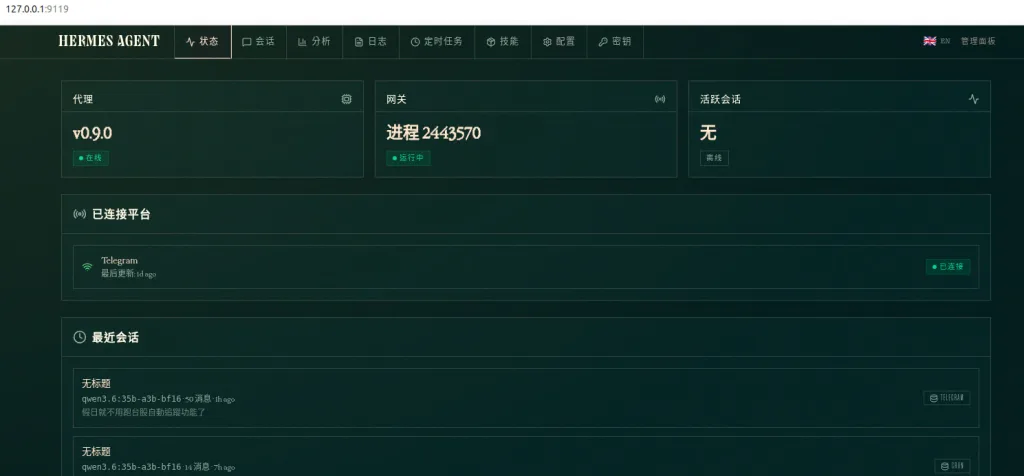
🖥️ Hermes WebUI(Dashboard)帶來什麼改變?
1️⃣ 從 CLI → GUI 的巨大轉變
過去:
- OpenClaw / Agent 系統 → CLI + config + prompt
現在:
- Hermes WebUI → 點擊操作 + 視覺化管理
👉 這是 AI Agent 商業化的關鍵一步
2️⃣ 多 Agent 管理(未來 SaaS 核心)
透過 WebUI,可以:
- 管理多個 Agent
- 設定不同任務流程
- 控制記憶與技能
👉 這意味著:
👉 你可以做「多人 AI 平台」
3️⃣ 技能(Skill)可視化
Hermes 最大亮點:
任務會被記錄成「技能」,並可重複使用
例如:
👉 這其實就是:
👉 AI workflow engine(未來企業標準)
Hermes 實作
先更新到最新版本
然後就可以直接啟用 hermes webui
之後就可以用瀏覽器使用,預設是 http://localhost:9119/
🔍 Hermes WebUI 深度觀察(關鍵洞察)
💡 與 Open WebUI 深度整合
在社群中有人指出:
Hermes 可以當成「有狀態的 LLM endpoint」
意思是:
- WebUI(前端)
- Hermes(Agent)
- LLM(模型)
👉 三層架構:
User → WebUI → Hermes Agent → LL
「Hermes 開箱就像調教一週的 OpenClaw」
官方資訊
https://docs.openwebui.com/getting-started/quick-start/connect-an-agent/hermes-agent
第三方套件
https://github.com/nesquena/hermes-webui
by rainchu | 12 月 18, 2025 | AI, 圖型處理, 影片製作
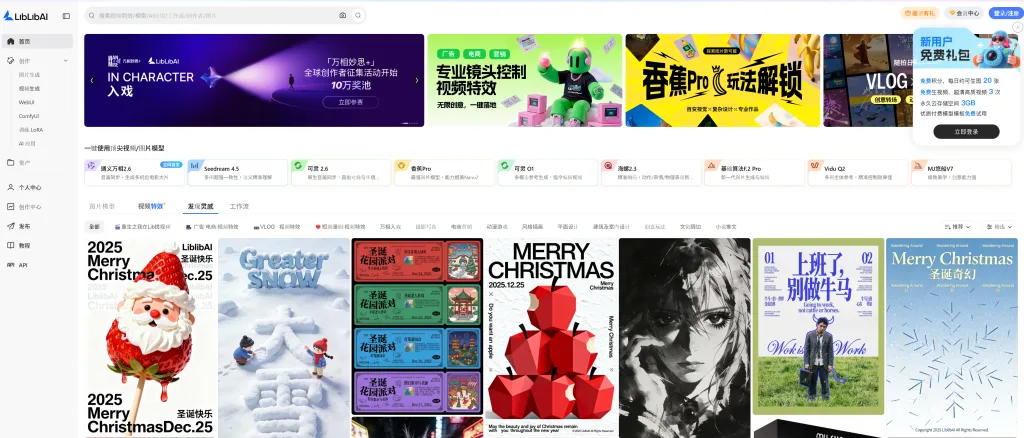
眾多 AI 創作平台之中,Liblib 憑藉其高度整合的功能、生態完整度以及對中文使用者的極致友善設計,迅速成為中國最領先的 AI 創作平台之一。
一站式 AI 影像與視頻創作平台
Liblib 不僅僅是一個圖片生成網站,而是一個超級齊全的 AI 創作平台,涵蓋:
- AI 圖片生成
- AI 視頻特效與動畫
- 模型管理與分享
- 視覺化工作流(Workflow)
- LoRA 訓練與應用
透過雲端化的設計,使用者無需自行架設環境,即可直接在瀏覽器中使用高階 AI 生成能力。
深度整合 WebUI 與 ComfyUI
對於熟悉 Stable Diffusion 生態的使用者而言,Liblib 最大的優勢之一,在於它同時支援:
- WebUI:操作直覺、上手快速,適合大多數創作者
- ComfyUI:節點式工作流,適合進階用戶進行複雜控制與自動化生成
這種雙軌並行的設計,讓初學者與專業用戶都能在同一平台中找到最適合自己的創作方式。
強大的 LoRA 訓練能力
Liblib 在 LoRA 訓練方面表現尤為突出,提供完整且視覺化的訓練流程:
- 上傳資料集即可開始訓練
- 支援多種風格與角色 LoRA
- 訓練完成後可直接套用於生成
- 社群分享與模型市集機制
這讓創作者能快速打造專屬風格模型,大幅降低 AI 模型訓練的門檻。
中文使用者極度友善
相較於許多國外 AI 平台對中文支援不足,Liblib 在以下方面明顯優於同類產品:
- 完整繁體與簡體中文介面
- 中文 Prompt 理解度高
- 中文模型與 LoRA 資源豐富
- 適合華語創作者的社群內容
對中文內容創作者來說,這是一個真正「為中文而生」的 AI 創作平台。
工作流與創作效率全面升級
Liblib 內建的 工作流系統(Workflow),讓使用者可以:
- 將複雜生成流程模組化
- 重複使用高品質生成邏輯
- 快速套用他人分享的創作流程
- 大幅提升商業與批量創作效率
這對於需要大量產出視覺內容的團隊與個人創作者而言,是極具價值的功能。
為什麼 Liblib 是中國最領先的 AI 創作平台?
綜合來看,Liblib 的核心優勢包括:
- ✅ 視頻特效 + 圖片模型完整整合
- ✅ WebUI 與 ComfyUI 同時支援
- ✅ 強大且易用的 LoRA 訓練
- ✅ 中文高度友善,資源豐富
- ✅ 從新手到專業用戶皆適用
這不僅是一個工具,更是一個完整的 AI 創作生態系。
官方網站
👉 Liblib 官方平台
https://www.liblib.art/

by Rain Chu | 6 月 27, 2024 | AI, 人臉辨識, 影片製作, 語音合成
Fusion Lab 又有新款力作,Hallo AI 可以讓用戶僅需提供一張照片和一段語音,就能讓照片中的人物進行說話、唱歌甚至進行動作,為數字內容創作帶來了革命性的突破。

主要功能介紹:
- 語音動畫同步:用戶只需上傳一張照片及一段WAV格式的英語語音,Hallo AI就能使照片中的人物按語音內容進行動作,包括說話和唱歌。
- 動作自然流暢:結合精確的面部識別和動作捕捉技術,保證人物動作的自然流暢,令人印象深刻。
技術框架:
- 音頻處理:使用Kim_Vocal_2 MDX-Net的vocal removal模型分離語音。
- 面部分析:透過insightface進行2D和3D的臉部分析。
- 面部標記:利用mediapipe的面部檢測和mesh模型進行精確標記。
- 動作模組:AnimateDiff的動作模組為動作生成提供支持。
- 影像生成:StableDiffusion V1.5和sd-vae-ft-mse模型協同工作,用於生成和調整圖像細節。
- 聲音向量化:Facebook的wav2vec模型將WAV音頻轉換為向量數據。
安裝方法
盡量採用 Linux 平台,我這邊測試成功的有 Ubuntu 20 WSL 版本,就可以簡單三個步驟,部過前提要記得先安裝好 WSL CUDA 支援
1.建立虛擬環境
conda create -n hallo python=3.10
conda activate hallo
2.安裝相關的依賴
pip install -r requirements.txt
pip install .
3.要有 ffmpeg 支援
4.測試與驗證
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav
最近更新:
- 在🤗Huggingface空間克隆了一個Gradio演示。
- 新增Windows版本、ComfyUI界面、WebUI和Docker模板。
參考資料
Hallo GitHub
Hallo Model
大神開發的Windows介面
Hallo 線上版本
Hallo Docker版
影片跳舞合成

by Rain Chu | 4 月 10, 2023 | AI, Stable Diffusion, 繪圖
Stable Diffusion Lora 超好用,已經不太需要說明,今天要來介紹一個可以讓 Lora 放開她的束縛,可以完全調整 Lora 在模型中的每一層的權重設定,為何要有分層設定,可以看看原作者的下面這張說明圖,分別在不同層插入 Lora 可以有不同的效果出現,也可以更精準的控制AI
LoRA 權重外掛
hako-mikan/sd-webui-lora-block-weight (github.com)
安裝方法,到擴充功能中,選擇從網址安裝,並且輸入 hako-mikan/sd-webui-lora-block-weight (github.com)
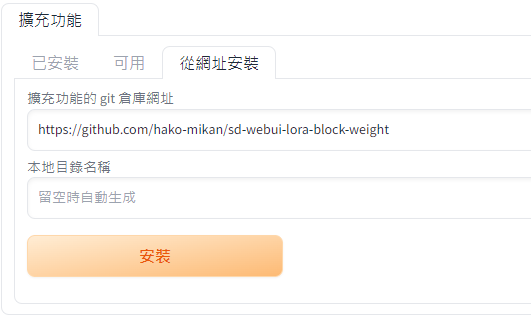
之後重啟系統即可看到多了 LoRA Block Weight 可以用
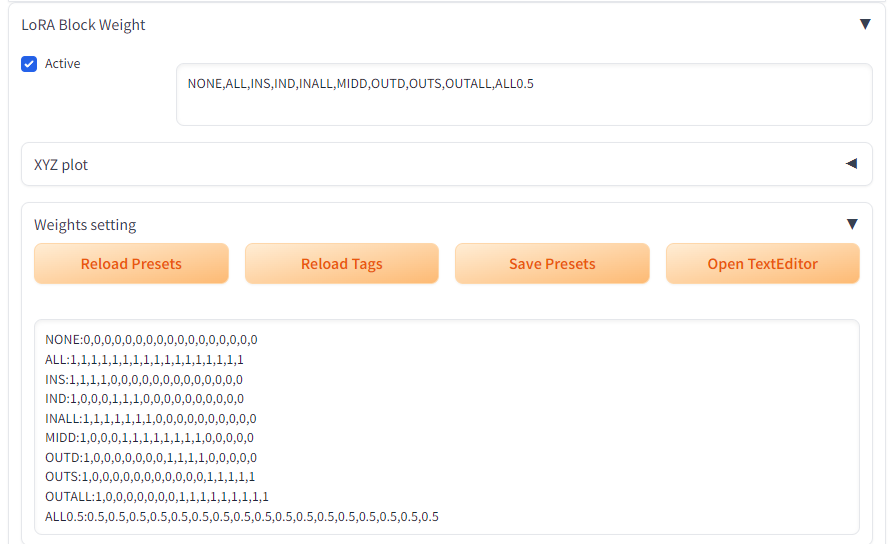
至於使用效果的話,我建議都試試看上面的設定,再去拿捏下手的感覺
LoRA 整合權重外掛的 UI
bbc-mc/sdweb-merge-block-weighted-gui: Merge models with separate rate for each 25 U-Net block (input, middle, output). Extension for Stable Diffusion UI by AUTOMATIC1111 (github.com)
LoRA擁有17個作用層

參考資料
by Rain Chu | 4 月 2, 2023 | AI, Stable Diffusion, 繪圖
隨著科技的快速發展,人工智能(AI)已經深入滲透到我們日常生活的方方面面。在這個世代,手機已經成為我們生活中不可或缺的一部分。而現在,我們可以利用AI技術在手機上進行繪畫,使創作變得更加輕鬆、有趣和高效。在這篇文章中,我們將探討如何在手機上使用AI進行繪圖,以及如何充分利用這些工具來提高您的藝術技巧,讓你可以離開鍵盤和滑鼠的限制,用手點一點也可以AI繪畫。
直接用現成的APP
機畫師-專業的AI繪畫APP-支持controlNet
有團隊把 Stable Diffusion 的 Webui 做成 APP 給大家使用,需要付費,如果不想用電腦的可以試試看
Pixai.Art
在 Android 上的 AI 繪圖軟體,底層也是採用 Stable Diffusion ,現在也支援 LORA 和 Control Net
Google Colab
用 Google Colab 雲端伺服器來幫忙運算,原則免費,但建議可以付點錢,享受更快更穩,不麻煩的服務
https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/main/stable/chillout_mix_webui_colab.ipynb
直接用上面的網址,然後都下一步,就可以建立起自己的 WebUi
Draw Things
https://drawthings.ai/
用 iPhone 上面的資(CPU、GPU),來做AI繪圖,可以離線使用,但手機會很燙,且很耗電
How to run Stable Diffusion on Termux on Android phone
https://ivonblog.com/en-us/posts/android-stable-diffusion/
神人教你如何在 Android 上面安裝自己的 Stable Diffusion Webui ,過程很難,且不是每一隻手機都可以,有興趣的在看看即可
參考資料
近期留言