by Rain Chu 7 月 24, 2026 | 未分類
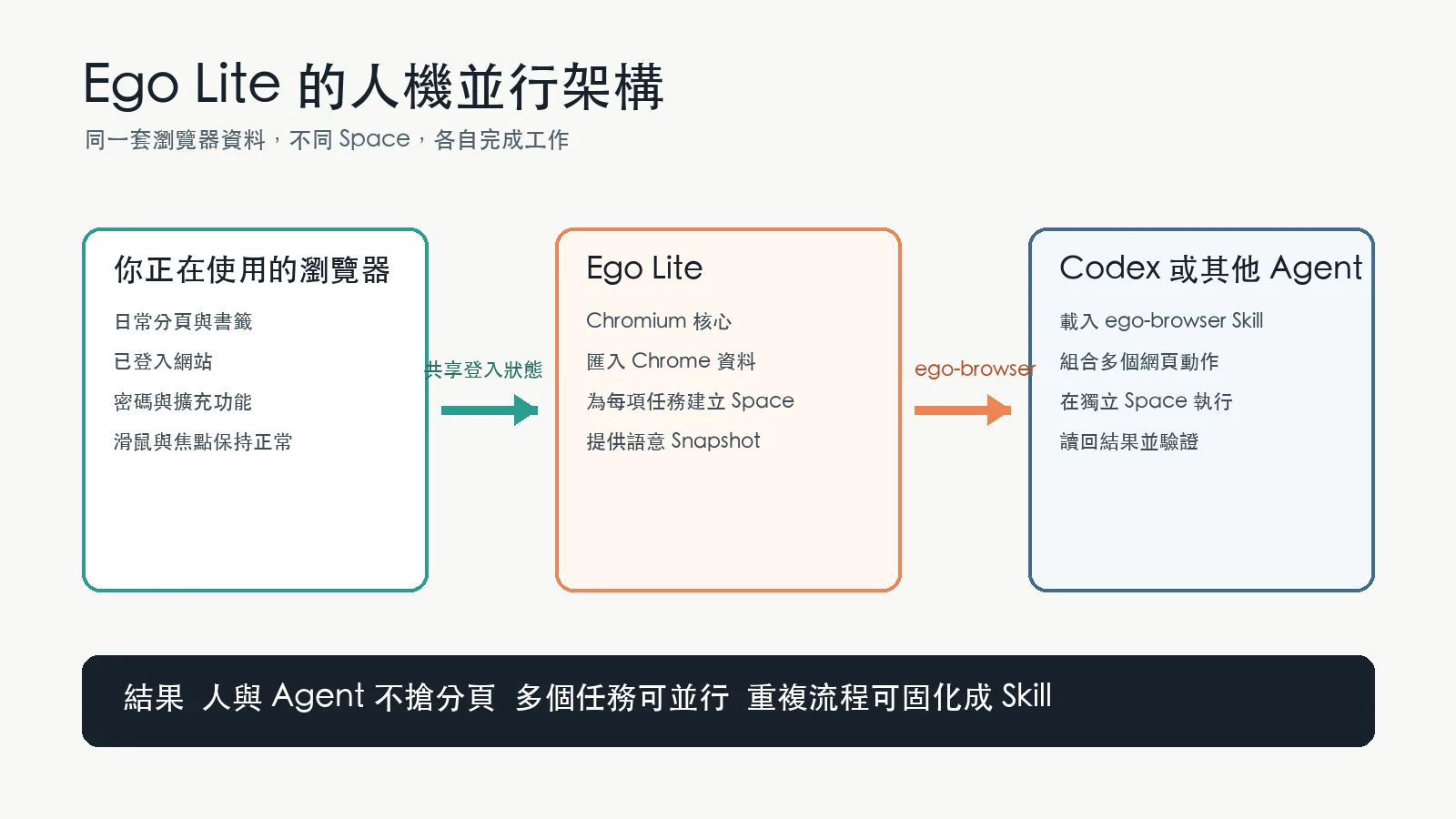
Ego Lite 是可以讓 Codex、Claude Code 或其他 Agent 能在保留登入狀態的瀏覽器裡工作,同時不搶走你的分頁、滑鼠與注意力。它把 Chromium 瀏覽器、獨立工作空間 Space,以及 ego-browser Skill 組合在一起,讓人與 Agent 可以在同一套瀏覽器資料上並行處理不同任務。
如果你曾經用過 Playwright CLI 讓 Codex 操作瀏覽器 ,Ego Lite 可以視為另一條更偏向日常使用的路線。Playwright 擅長測試與可重現的自動化,Ego Lite 則把重點放在沿用真實登入狀態、讓多個 Agent 任務分開執行,以及把成功流程逐步固化成可重複使用的 Skill。
Ego Lite 是什麼
Ego Lite 是一款以 Chromium 為核心的 Agent Browser。它可以匯入 Chrome 的分頁、書籤、密碼、Cookie、登入工作階段、擴充功能與瀏覽器 Profile,外觀與一般 Chrome 接近,但多了一層專門給 Agent 使用的 Space。
每個 Space 都是獨立工作空間。你可以繼續處理自己的分頁,Codex 在另一個 Space 填表單、整理資料或下載檔案,另一個 Agent 還能同時開第三個 Space 執行其他任務。這些工作不需要共用同一個前景分頁,也不會輪流搶滑鼠焦點 。
Ego Lite 以同一套瀏覽器資料連接使用者與 Agent,再用 Space 隔離不同任務 真正的差異是登入狀態與工作空間
瀏覽器自動化最麻煩的地方,常常不是按鈕怎麼點,而是登入、雙因素驗證、SSO、Cookie、擴充功能與多個 Profile 怎麼延續。傳統自動化工具通常另外啟動一個乾淨的瀏覽器環境,這很適合測試,卻不一定適合處理每天都要登入的後台、社群平台或內部系統。
Ego Lite 把自己定位成你每天可以直接使用的瀏覽器。完成初次匯入後,Agent 可以在自己的 Space 沿用既有登入狀態。這也是它比單純命令列包裝更有意思的地方,因為 Agent 操作的是一個有真實使用脈絡的瀏覽器,而不是臨時建立的空白執行環境。
比較項目 Ego Lite Playwright 或 Puppeteer 一般 Agent Browser CLI 產品形態 可日常使用的 Chromium 瀏覽器加 Skill 程式庫與測試框架 操作瀏覽器的命令列工具 登入狀態 可匯入 Chrome 資料並在 Space 使用 通常自行建立或管理 Profile 多半操作另一個瀏覽器環境 人與 Agent 並行 不同 Space 同時工作 需要自行設計多 Context 或多實例 依工具實作而定 適合情境 登入後台、資料整理、日常重複工作 自動測試、精確流程、持續整合 快速交給 Agent 操作網頁
這不是誰取代誰的問題。需要穩定測試、嚴謹選擇器與 CI 流程時,Playwright 仍然很合理。需要 Agent 直接處理既有登入網站,而且你還要繼續使用瀏覽器時,Ego Lite 的設計更貼近日常工作。另一篇 用 Chrome 與 OpenCLI 控制瀏覽器 ,也能幫你比較不同整合方式。
Ego Browser Skill 如何減少 Token 與反覆試錯
很多瀏覽器 Agent 採用一個動作一次工具呼叫的節奏。先讀頁面,再點一下,重新讀頁面,再填一個欄位。每次來回都要把狀態交給模型判斷,步驟一多,時間與 Token 就跟著增加。
ego-browser 讓 Agent 直接組合一段 JavaScript,把可預測的觀察、點擊、輸入、等待與驗證放在同一次執行裡。它提供接近 Playwright 的 page、locator 與 browser 介面,也加入 taskSpaces、語意 Snapshot 和瀏覽器內請求能力。Agent 不必在每個小動作後停下來重新思考,複雜流程因此有機會用更少回合完成。
官網目前宣稱,特定複雜自動化測試相較 agent-browser 最多可快 3.45 倍,GitHub README 則仍保留最多 2.5 倍的描述。這兩個數字可能來自不同版本或測試組合,適合視為官方基準測試,不應直接套用到所有網站。真正值得觀察的是你自己的任務完成率、重試次數、總 Token 與人工接手次數。
Ego Lite 完整安裝方式
Ego Lite 目前以 macOS 為主要支援平台,Windows 與 Linux 仍在規劃中。最簡單的方法是到官網下載 Mac 版 ,開啟應用程式後完成初次設定。你也可以先把 Skill 加入 Codex 或其他 Agent。
請幫我設定 Ego Lite
專案網址是 https://github.com/citrolabs/ego-lite
請閱讀 skills/ego-browser/references/install.md
依照步驟安裝應用程式與 ego-browser Skill
需要我手動完成匯入或授權時先停下來告訴我初次啟動時,Ego Lite 會詢問是否匯入 Chrome 資料。匯入登入工作階段很方便,也代表 Agent 可能接觸已登入網站。建議只匯入工作所需的 Profile,不要把個人金融、公司管理後台與一般瀏覽資料全部混在同一個高權限環境。
完成應用程式內的 onboarding 後,可以確認命令是否已加入環境。
若找不到命令,常見原因是 ~/.local/bin 尚未加入 PATH。
export PATH="$HOME/.local/bin:$PATH"
command -v ego-browser 最後用最小測試確認執行環境。
printf "console.log('ego-browser ready')\n" | ego-browser nodejs 如何在 Codex 正確下 Prompt
一個好指令至少要包含網站、目標、資料範圍、輸出格式、驗證條件與需要停下來確認的高風險動作。不要只寫「幫我整理這個網站」,因為 Agent 不知道要看幾頁、保留哪些欄位,也不知道什麼情況才算完成。
/ego-browser
開啟我已登入的商品後台
依最新時間排序評論
收集前 100 筆評論的日期、評分、內容與商品規格
移除重複資料後輸出 CSV
完成前檢查總筆數與欄位是否齊全
不要送出表單、修改商品或發布任何內容需要多個來源時,可以明確要求使用不同 Space 並行執行,再把結果合併。例如規劃旅程時,一個 Space 查交通,一個 Space 查天氣,另一個 Space 整理景點與營業時間。最後再要求 Agent 檢查日期是否一致,避免不同網站的資料互相衝突。
/ego-browser
建立三個 Space 並行規劃台北到台南的三日行程
Space 1 查可訂購的高鐵班次與價格
Space 2 查三天逐時天氣
Space 3 查景點營業時間與休館日
最後合併成每日行程表
每個交通與景點資訊都保留來源網址
遇到付款、訂位或登入驗證時停下來交給我三種實際適合的工作
把商品評論整理成 CSV
Agent 可以進入已登入的電商頁面,開啟完整評論、調整排序、向下捲動或翻頁,再把指定欄位輸出成 CSV,第一次完成後,還可以把穩定步驟改成接收商品網址的腳本。之後直接執行腳本,就不必每次都讓模型重新理解同一套操作。
跨網站規劃行程
交通、天氣、地圖與旅遊攻略可以放到不同 Space 同時處理。這類工作真正困難的是登入狀態、日期對齊與多來源整合,剛好能發揮 Space 與既有 Cookie 的優勢。
結合地圖與求職網站篩選職缺
如果目標是找離住家最近的職缺,Agent 可以先從多個求職網站整理職稱、公司與地址,再交給地圖服務估算距離,最後輸出成 CSV,這比只用關鍵字搜尋更接近真正的決策流程,但地址、通勤時間與職缺是否仍有效,都要在結果中保留可追查來源。
從一次成功操作變成可重複 Skill
Ego Lite 最有價值的用法,不是每次都叫 Agent 從頭探索頁面,而是先讓它完成一次,再把成功路徑整理成 Skill 或腳本。探索階段需要模型判斷頁面與處理例外,穩定階段則把固定動作改成程式,僅在網站改版或驗證失敗時再回到 Agent。
先用自然語言描述結果與安全邊界
讓 Agent 完成一次並驗證輸出
整理穩定的頁面定位、等待條件與輸出欄位
將流程固化成 Skill 或可接收參數的腳本
為登入失效、欄位缺漏與網站改版保留明確錯誤訊息
當固定腳本能直接完成任務時,重複執行確實可以把模型 Token 壓到很低,甚至讓執行階段不再呼叫模型。不過這不是所有任務都能達成的零成本承諾。頁面變動、需要理解文字、遇到驗證碼或必須做判斷時,仍然需要 Agent 或人工介入。這個思路也適合延伸到 用 OfficeCLI 把文件工作交給 AI Agent ,把重複的辦公流程逐步變成可驗證的工具。
登入狀態越方便,權限管理越重要
Ego Lite 官方表示瀏覽紀錄、Cookie、密碼與頁面資料都保留在本機,設定時只記錄是否選擇 Chrome 匯入。即使資料不會主動上傳,Agent 仍然可能在你的授權下讀到頁面內容或執行操作,所以安全重點仍是最小權限與明確停止條件。
工作與私人帳號使用不同 Profile
發布、付款、刪除與權限變更必須人工確認
Prompt 清楚列出禁止操作
先用少量資料測試,再放大範圍
輸出要包含來源、筆數與驗證結果
結論
Ego Lite 的核心價值,是把真實瀏覽器狀態、Agent 專用 Space 與可重複 Skill 接在一起。它很適合需要登入、多網站整合、長流程與重複執行的工作,也能讓 Codex 在背景處理任務時,你仍然保有自己的瀏覽器與滑鼠。
最好的導入方式,是先挑一個低風險、每週都會重複的工作。讓 Agent 完成一次,確認輸出可靠,再把流程固化。真正節省的不是某一次點擊,而是把日後的重複思考與試錯一起移除。
常見問題
Ego Lite 可以讓 Codex 操作已登入網站嗎
可以。完成瀏覽器資料匯入與 onboarding 後,Codex 可透過 ego-browser Skill 在獨立 Space 使用既有登入狀態。高風險操作仍建議保留人工確認。
Ego Lite 與 Playwright 有什麼不同
Playwright 是瀏覽器自動化與測試框架,Ego Lite 是可以日常使用的 Chromium 瀏覽器,再透過 Skill 讓外部 Agent 操作。兩者可依測試或日常工作需求選擇。
Ego Lite 是否免費
官方目前標示 Ego Lite 免費且不需要訂閱。Agent 使用的模型是否產生費用,仍取決於 Codex、Claude Code 或其他模型服務的方案。
目前支援哪些作業系統
官方目前提供 macOS 版本,Windows 與 Linux 仍在 roadmap。下載前應以官網最新狀態為準。
瀏覽資料會上傳到 Ego Lite 嗎
官方表示書籤、瀏覽紀錄、Cookie、密碼與頁面資料保留在本機。不過 Agent 取得操作權限後仍可能接觸頁面內容,應以獨立 Profile 和最小權限降低風險。
官方資源
by Rain Chu 7 月 23, 2026 | AI , 語音分離 , 語音合成 , 語音辨識
Voicebox 最吸引我的地方,是它不是只做 TTS,也不是只做 Whisper 聽寫,而是把語音輸入、語音輸出、聲音克隆、故事編輯器、REST API 和 MCP server 放在同一個本地優先的工具裡。這讓 AI Agent 不只會回文字,也能用你指定的音色說話。
如果說過去的語音工具常常分成兩邊,ElevenLabs 偏輸出,WisprFlow 偏輸入,那 Voicebox 想做的是完整 voice I/O stack。更重要的是,它預設把模型、聲音資料和錄音留在本機,這對語音克隆和工作資料來說很關鍵。
先講結論
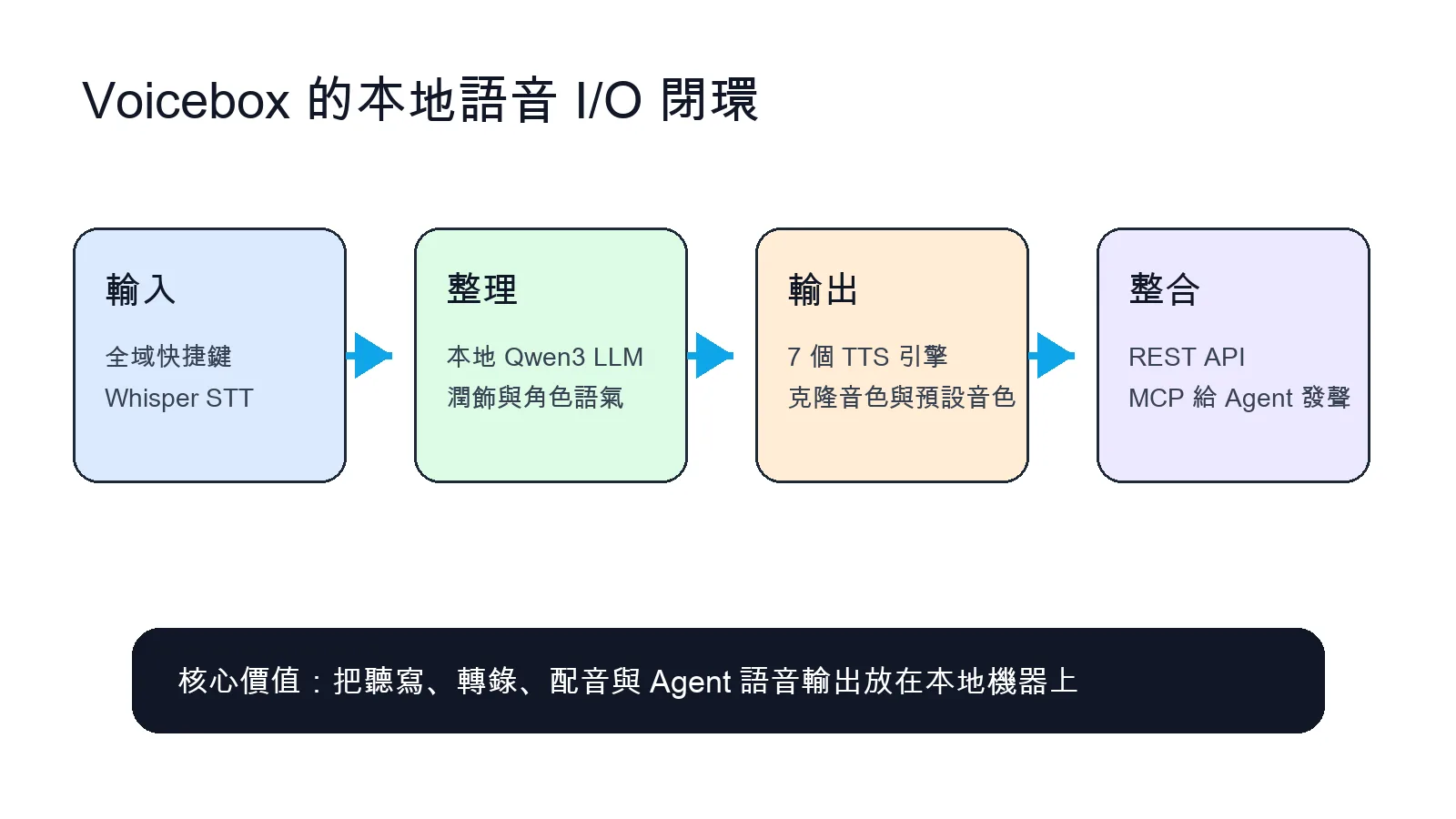
Voicebox 是 Jamie Pine 開源的 AI voice studio,官方定位是 local-first。它可以做文字轉語音、聲音克隆、全域快捷鍵聽寫、Whisper 轉錄、故事多軌編輯,還能透過 REST API 和 MCP server 讓 Claude Code、Cursor、Cline 這類 MCP-aware agent 發聲。
我會把它放在「本地語音 AI 底座」這一類,之前整理過 audio.cpp 本地語音 AI WebUI 和 Hugging Face speech-to-speech 本地語音 Agent ,Voicebox 則更偏向桌面應用和創作者工具,並且把 Agent 整合做得很直接。
Voicebox 把聽寫、轉錄、配音和 Agent 語音輸出放在同一個本地工具裡。 Voicebox 在補語音 AI 的哪一塊
很多語音工具只有單點能力。TTS 工具能把文字變聲音,但不一定能做聽寫。STT 工具能轉錄,但不一定能配音。聲音克隆工具效果強,但常常依賴雲端 API。Voicebox 的取向比較完整:輸入端用 Whisper,輸出端有多個 TTS 引擎,中間還有本地 Qwen3 LLM 做潤飾、角色語氣和 persona。
這種整合方式很適合兩種人:
第一種是內容創作者,想做旁白、podcast、故事對話、角色音色。
第二種是 AI Agent 使用者,想讓 Claude Code、Cursor 或自己的工具在完成任務後,用指定聲音提醒你,而不是只丟一段文字。
7 個 TTS 引擎和 23 種語言
官方 README 列出 7 個 TTS 引擎:Qwen3-TTS、Qwen CustomVoice、LuxTTS、Chatterbox Multilingual、Chatterbox Turbo、HumeAI TADA 和 Kokoro。它們的定位不同,有的適合多語言克隆,有的適合 CPU 快速推理,有的適合加入情緒標籤和語氣控制。
能力 Voicebox 的做法 適合用途 高品質 TTS Qwen3-TTS、Chatterbox、HumeAI TADA 等引擎 旁白、教學、產品介紹 聲音克隆 用參考音訊做 zero-shot cloning 個人聲音、角色聲音、品牌聲線 快速預設音色 Kokoro 和 Qwen CustomVoice 提供 50+ 音色 快速試稿、多角色對話 語音輸入 全域快捷鍵加 Whisper STT 聽寫、轉錄、工作筆記
如果你對開源 TTS 的音色設計有興趣,可以搭配看 Qwen3-TTS 的音色設計整理 和 dots.tts 聲音復刻架構 。Voicebox 比較像把這些能力打包成桌面工作台,而不是單一模型 demo。
聲音克隆和預設音色的差別
聲音克隆適合你有一段參考音訊,想生成相似聲線。預設音色適合你只是要快速找一個可用聲音,不想準備樣本。Voicebox 同時支援兩種路線,這點很實用。創作者可以先用預設音色打草稿,確定文本節奏後,再換成克隆音色做正式版本。
但聲音克隆也有界線。它很適合克隆你自己擁有權利的聲音,或明確授權的角色聲音。不要拿來模仿名人、同事或客戶聲音做未授權內容。語音模型越容易使用,倫理和授權越要先想清楚。
Whisper 聽寫補上輸入端
Voicebox 的另一半是輸入。它用 OpenAI Whisper 做 speech-to-text,支援全域 dictation hotkey、push-to-talk 和 toggle mode。macOS 上可以把轉錄結果直接貼到目前焦點文字欄位,這會讓它接近一個本地版語音輸入法。
Whisper 對長音訊和技術內容一直很適合。如果你常做訪談、會議紀錄、口述筆記,Voicebox 把 captures、replay、re-transcribe、refine 放在同一個介面裡,會比單純命令列轉錄更順。這裡也可以延伸看之前整理的 Whisper 開源語音轉文字 。
MCP 讓 Agent 真的開口說話
Voicebox 最有意思的一點,是內建 MCP server,官方 README 寫到它提供 `voicebox.speak`、`voicebox.transcribe`、`voicebox.list_captures`、`voicebox.list_profiles` 四個工具,這代表 MCP-aware agent 可以呼叫 Voicebox,把文字變成指定音色播放出來,也可以讀取 captures 和 voice profiles。
這不只是好玩。Agent 的語音輸出可以拿來做任務完成提醒、錯誤警告、長任務回報、pair programming 對話。你甚至可以把不同 agent 綁定不同聲音,例如 Claude Code 用一個音色,Cursor 用另一個音色,聽聲音就知道是哪個工具在回報。
{
"tool": "voicebox.speak",
"arguments": {
"text": "任務完成,測試已通過",
"profile": "Morgan"
}
} 如果你已經在玩 Playwright CLI 讓 Codex 操作瀏覽器 ,Voicebox 可以補上另一個感官通道。Agent 不只可以操作網頁,也能在完成後直接用語音提醒你。
Stories editor 適合做多角色內容
Voicebox 也有 Stories editor,可以做 conversation、podcast、narrative 這類多段落、多角色內容。這對部落格轉 podcast、教學腳本、角色對話、短劇旁白都很有用。比起一次產生一整段音訊,多軌 timeline 更適合慢慢調整角色、節奏和轉場。
如果你平常會把文章轉成短影片或語音內容,Voicebox 可以放在內容工作流後段。先由 Agent 整理稿件,再用 Voicebox 做角色分配和配音,最後再進剪輯工具。
安裝與使用入口
Voicebox 官方網站是 voicebox.sh ,GitHub repo 是 jamiepine/voicebox 。官方 README 提供 macOS Apple Silicon、macOS Intel 和 Windows 下載入口,也有開發者本地建置方式。
我會怎麼用
我不會只把 Voicebox 當成免費配音工具:
更有價值的用法,是把它接進 AI Agent 工作流,平常寫文章、整理筆記、跑 Codex、跑 Claude Code,最後都可以由 Voicebox 轉成語音摘要。長任務完成時不用一直盯螢幕,讓 Agent 開口提醒就好。
第二個用法是做內容實驗,先用預設音色快速產出版本,再用克隆音色做正式版。
第三個用法是本地聽寫,把口述想法直接丟進任何 app,再交給 Agent 整理。這會比只靠鍵盤更接近自然工作流。
我的判斷
Voicebox 不是單一模型展示,而是把語音 AI 變成桌面工作台。它的亮點不是某個 TTS 引擎本身,而是整合:本地隱私、TTS、STT、故事編輯、聲音 profile、REST API、MCP server。
如果你只需要偶爾產一段聲音,線上 TTS 服務可能更快。但如果你想要長期建立自己的聲音素材庫、做本地聽寫、讓 Agent 用聲音回報任務,Voicebox 會是值得試的工具。
延伸資源
FAQ
Voicebox 是什麼?
Voicebox 是開源的本地優先 AI 語音工作室,可以做 TTS、聲音克隆、Whisper 聽寫轉錄、故事編輯和 MCP Agent 語音輸出。
Voicebox 可以離線使用嗎?
官方定位是 local-first,模型、聲音資料和 captures 會留在本機。實際能否完全離線,取決於你是否已下載需要的模型和使用的引擎。
Voicebox 支援哪些 TTS 引擎?
官方列出 Qwen3-TTS、Qwen CustomVoice、LuxTTS、Chatterbox Multilingual、Chatterbox Turbo、HumeAI TADA 和 Kokoro。
Voicebox 可以接 Claude Code 或 Cursor 嗎?
可以。Voicebox 內建 MCP server,MCP-aware agent 可以使用 `voicebox.speak`、`voicebox.transcribe`、`voicebox.list_captures` 和 `voicebox.list_profiles`。
by Rain Chu 7 月 20, 2026 | Agent , AI , API , Tool
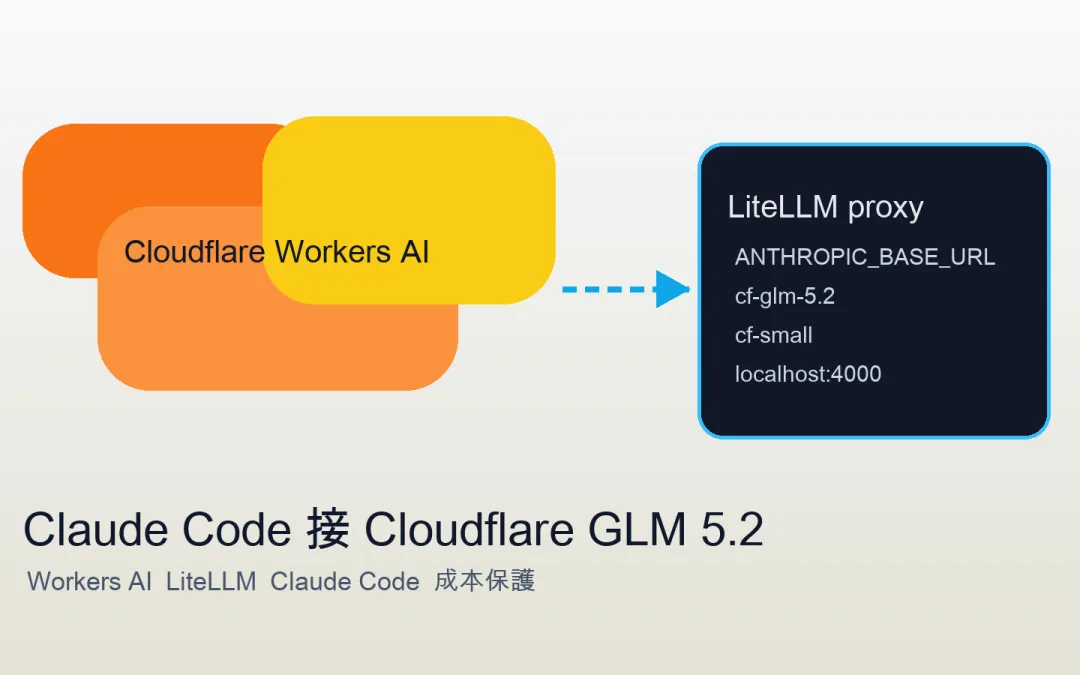
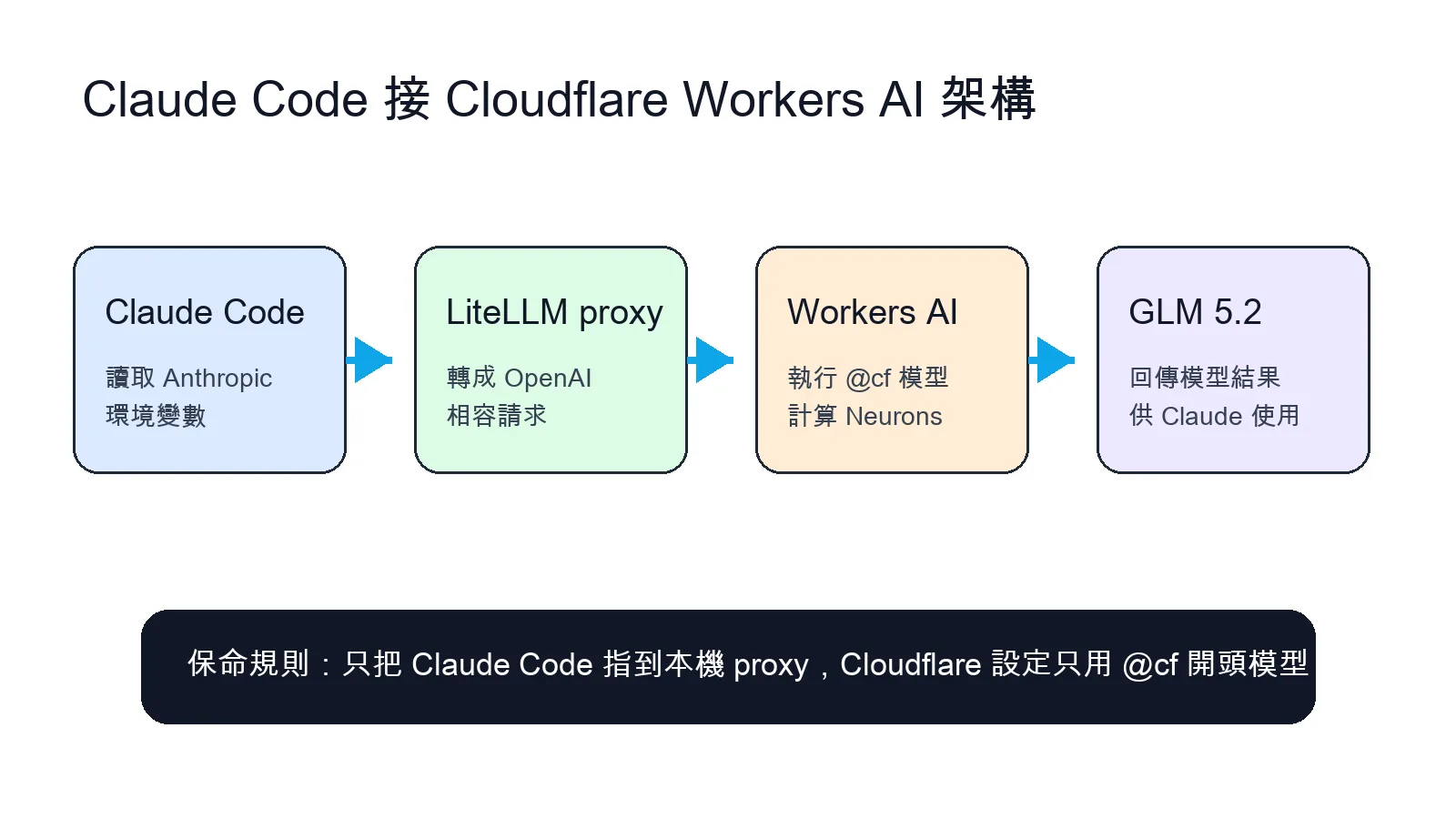
Cloudflare Workers AI 拿來接 Claude Code 的做法很簡單:Cloudflare 跑模型,LiteLLM 在本機當轉接橋,Claude Code 只需要改 Anthropic 相關環境變數,就能把請求送到本機 proxy。
這篇整理的是一個比較務實的路線。它不是要你把所有模型成本都消失,而是讓你知道免費額度在哪裡、帳單風險在哪裡、命令怎麼下、哪些設定一定要看清楚。
先講結論
Cloudflare Workers AI 有免費額度,官方價格頁寫明 Free plan 每天有 10,000 Neurons,GLM 5.2 目前也在 Cloudflare Workers AI 模型列表裡,可以透過 Cloudflare API 呼叫。這代表你可以把 Claude Code 的模型入口改成本機 LiteLLM proxy,再由 LiteLLM 轉送到 Cloudflare 的 @cf/zai-org/glm-5.2。
但「免費」不是「無限」,Cloudflare 的計費單位是 Neurons,免費額度用完後會受到方案限制,更重要的是,Cloudflare AI Gateway 也能接外部模型,如果你把 OpenAI 或 Anthropic 這類外部模型接進去,那就不再是 Cloudflare Workers AI 的免費模型邏輯,帳單會回到外部供應商那邊。
Claude Code 只改成本機 Anthropic 入口,真正的模型請求由 LiteLLM 轉到 Cloudflare Workers AI。 這個架構在解什麼問題
Claude Code 很好用,但長時間寫程式、重構、跑測試、修錯時,模型成本會變得很有感。若只是一些低風險任務,例如產生腳手架、改小工具、做簡單 demo、先跑一輪想法,Cloudflare Workers AI 的免費額度可以拿來當低成本緩衝層。
這和 用 Claude Code 搭配 LM Studio 與 Ollama 的思路很像,只是這次不是跑本地模型,而是把免費雲端額度接進本機開發流程。若你的工作流已經在用 Claude Code、Codex 和 skill 組合工作流 ,這種 proxy 入口會很有彈性。
完整操作命令
下面命令以 macOS 或 Linux 為主。你需要先有 Cloudflare 帳號,並在 Cloudflare dashboard 取得 Account ID 和 API Token。API Token 建議只給 Workers AI 需要的最小權限,不要用過度寬鬆的全域 token。
0. 安裝 Claude Code
npm install -g @anthropic-ai/claude-code 1. 用 curl 單測 GLM 5.2
先確認 Cloudflare 端可以呼叫模型。把 `你的ACCOUNT_ID` 和 `你的API_TOKEN` 換成自己的值。
curl https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/run/@cf/zai-org/glm-5.2 \
-H "Authorization: Bearer 你的API_TOKEN" \
-d '{"messages":[{"role":"user","content":"用一句話介紹你自己"}]}' 2. 安裝 uv
LiteLLM proxy 用 uvx 跑,可以固定 Python 3.12,避開較新 Python 版本造成的編譯問題。
curl -LsSf https://astral.sh/uv/install.sh | sh 3. 驗證 LiteLLM 能跑
uvx --python 3.12 --from 'litellm[proxy]' litellm --version 4. 建立 cf-config.yaml
建立 `cf-config.yaml`。`你的ACCOUNT_ID` 有兩處要換。`cf-glm-5.2` 給 Claude Code 主要模型用,`cf-small` 給較輕量任務用。
model_list:
- model_name: cf-glm-5.2
litellm_params:
model: openai/@cf/zai-org/glm-5.2
api_base: https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/v1
api_key: os.environ/CLOUDFLARE_API_TOKEN
- model_name: cf-small
litellm_params:
model: openai/@cf/meta/llama-3.1-8b-instruct-fp8
api_base: https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/v1
api_key: os.environ/CLOUDFLARE_API_TOKEN
litellm_settings:
use_chat_completions_url_for_anthropic_messages: true 5. 啟動 LiteLLM 翻譯橋
這個終端視窗要保持開啟。Claude Code 之後會連到 `localhost:4000`。
export CLOUDFLARE_API_TOKEN=你的token
uvx --python 3.12 --from 'litellm[proxy]' litellm --config cf-config.yaml --port 4000 6. 新開視窗測 proxy
curl http://localhost:4000/v1/models -H 'Authorization: Bearer sk-1234' 7. 把 Claude Code 指到本機 proxy
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-1234
export ANTHROPIC_MODEL=cf-glm-5.2
export ANTHROPIC_DEFAULT_HAIKU_MODEL=cf-small 接著啟動 Claude Code,若跳出自訂 API 設定就選是。進入後用 `/status` 確認 Base URL 指向 `localhost:4000`。
8. 把設定寫進 shell profile
如果你確定要長期使用,可以把上面四行 `ANTHROPIC_` export 加到 `~/.zshrc` 或 `~/.bashrc`。我會建議先手動跑幾次確認沒有問題,再寫進 profile。
Windows PowerShell 寫法
PowerShell 不用 `export`,改用 `$env:`。
$env:ANTHROPIC_BASE_URL="http://localhost:4000"
$env:ANTHROPIC_AUTH_TOKEN="sk-1234"
$env:ANTHROPIC_MODEL="cf-glm-5.2"
$env:ANTHROPIC_DEFAULT_HAIKU_MODEL="cf-small" 若要永久保存,放進 PowerShell 的 `$PROFILE`。Windows 跑 AI Agent 時,環境隔離也很重要,可以延伸看 Windows 跑 AI Agent 為什麼要用 WSL 。
保命提醒:不要把外部模型當免費額度
最容易出事的地方,是把 Cloudflare Workers AI、Cloudflare AI Gateway、OpenAI、Anthropic 混在一起。這篇的低成本前提,是 Cloudflare config 裡的模型走 `@cf/` 開頭,例如 `@cf/zai-org/glm-5.2`。這類模型用的是 Cloudflare Workers AI 額度。
如果你把 Gateway 接到 GPT 或 Claude,那些請求可能會回到 OpenAI 或 Anthropic 的帳單。Cloudflare 只是通道,不代表外部模型突然免費。真正要保命,就是把模型名稱、api_base、API key 來源逐一檢查,並在 Cloudflare 後台看用量。
官方價格頁目前寫得很明確:Free plan 每天 10,000 Neurons,Paid plan 也有每天 10,000 Neurons 免費額度,超出後依 Neurons 計費。免費方案超出額度通常是操作失敗,不是自動無限跑。這點比「無限免費」四個字重要太多。
省額度的三個做法
第一,任務分層。小任務用 `cf-small`,複雜推理再用 `cf-glm-5.2`。第二,讓 Agent 先輸出計畫再執行,避免一次丟太長上下文。第三,把重複流程寫成腳本或 skill,減少模型反覆讀同一批資料。
這也是我一直看好的方向:不要只追求模型本身,而是把模型接到穩定工具鏈。像 Playwright CLI 讓 Codex 操作瀏覽器 ,或 讓 Agent 自己搜尋和使用 skills ,本質上都是把昂貴推理留給真正需要判斷的地方。
我會怎麼用
我不會把這套當成主力模型的完全替代品,而是當成低成本實驗層。適合拿來跑 demo、試 prompt、生成小工具、做簡單 code review、補文件、處理一次性腳本。真正重要的架構決策、複雜除錯、長上下文專案,還是要保留更強模型或本地大模型選項。
如果你已經在用 Codex 和 ChatGPT Work 這類 AI 代理工作流 ,這套 Cloudflare Workers AI + LiteLLM 的做法可以當成另一個模型入口。它的價值不是讓你省到零,而是讓你有更多成本可控的實驗空間。
延伸資源
FAQ
Cloudflare Workers AI 接 Claude Code 真的免費嗎?
不是無限免費。Cloudflare Workers AI 有每日免費 Neurons 額度,超出後會依方案限制或計費。要把它當成低成本額度,不要當成沒有上限的模型。
為什麼需要 LiteLLM?
LiteLLM 在本機當 proxy,把 Claude Code 發出的 Anthropic 入口請求轉成 Cloudflare Workers AI 可接受的 OpenAI 相容請求。
最容易踩到哪個帳單風險?
最容易把 Cloudflare AI Gateway 接到外部 GPT 或 Claude,卻以為仍在用 Cloudflare 免費 @cf 模型。設定時要確認模型名稱是 `@cf/` 開頭,並檢查 API key 來源。
這套適合取代主力 Claude 嗎?
不建議直接取代。它比較適合低成本實驗、簡單任務、小工具和批次工作。複雜架構、長上下文和高風險任務,仍應保留更強模型。
by Rain Chu 7 月 20, 2026 | AI , skills , Tool
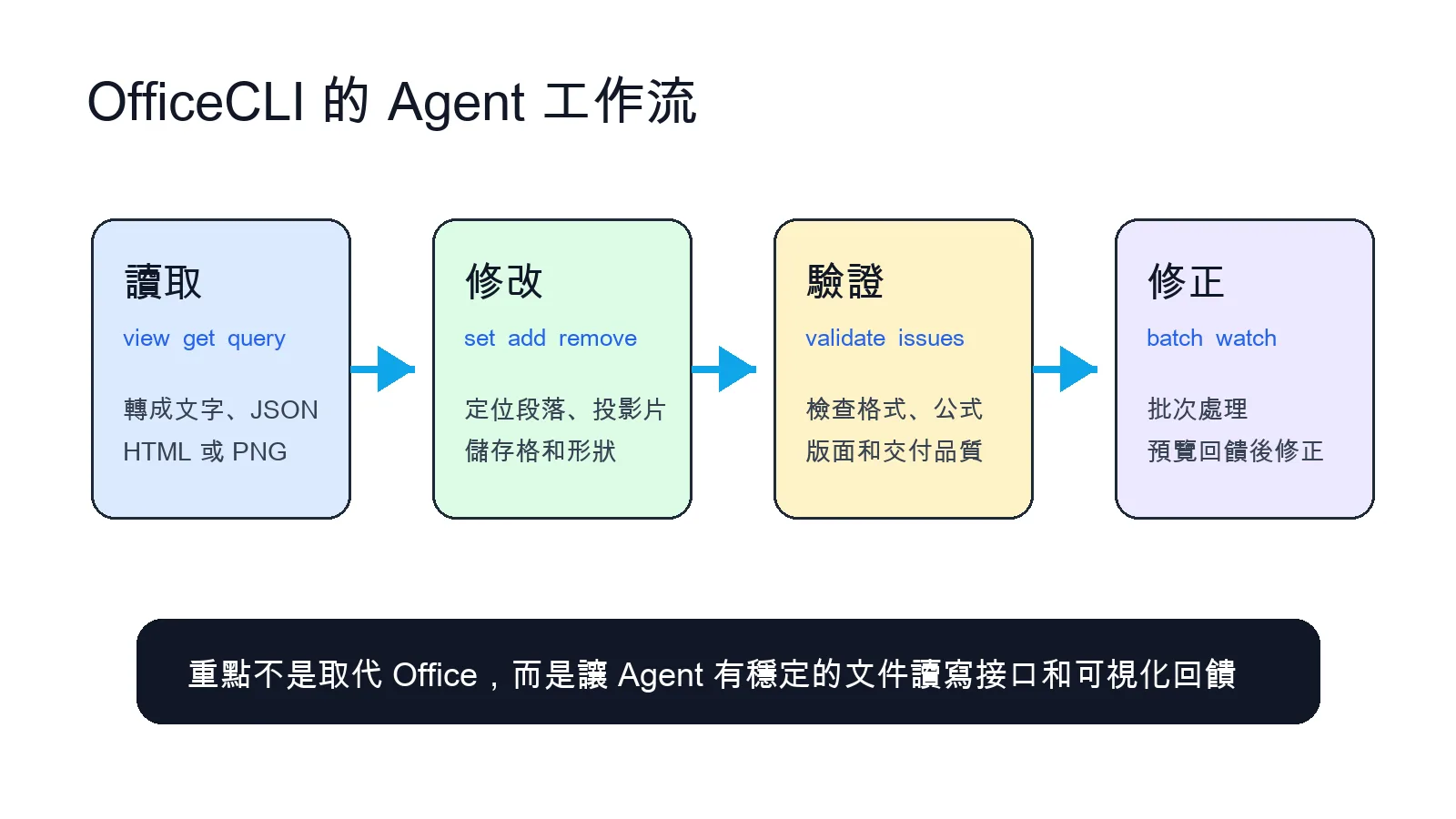
OfficeCLI 把 Word、Excel、PowerPoint 這三種常見文件,變成 AI Agent 可以穩定讀取、修改、驗證和預覽的工程接口。
以前要讓 AI 幫你處理 Office 文件,常見做法是丟給 Python 套件,例如 python-docx、openpyxl、python-pptx。這些工具很有用,但每種格式各自一套 API,版面問題也很難用純文字確認。OfficeCLI 的方向則比較像給 Agent 一支專門的文件手臂,用 CLI 和 JSON 把文件操作標準化。
先講結論
OfficeCLI 是 iOfficeAI 開源的 Office 文件命令列工具,主打給 AI Agent 使用。它可以建立、讀取、修改和驗證 docx、xlsx、pptx,不需要安裝 Microsoft Office,也不需要額外 runtime,官方定位是 single binary。
我會把它放在 Playwright CLI 同一類思路裡,Playwright CLI 是讓 Agent 操作瀏覽器,OfficeCLI 則是讓 Agent 操作文件,兩者共同點都是把原本依賴 GUI 或複雜 library 的任務,改成可重複、可檢查、可寫進 skill 的 CLI 工作流。
OfficeCLI 的價值在於讓 Agent 形成讀取、修改、驗證、修正的文件處理閉環。 為什麼 Agent 需要 OfficeCLI
文件不是只有文字,Word 有段落、樣式、頁首頁尾、註腳、目錄和追蹤修訂。
Excel 有公式、表格、樞紐分析、條件格式和資料驗證。P
owerPoint 有投影片、形狀、圖表、圖片、動畫和轉場。這些東西如果只轉成純文字,Agent 很容易看漏版面和結構。
OfficeCLI 的關鍵設計,是把文件轉成 Agent 能理解的結構化輸出,也能渲染成 HTML 或 PNG,這讓 Agent 不只知道文件裡有什麼文字,也能檢查排版結果。對需要交付正式報告、簡報、表格的人來說,這個 render → look → fix 的迴圈非常重要。
一行指令取代很多樣板程式碼
傳統 Python 套件通常要先 import library、建立物件、找到段落或投影片、設定屬性,最後再存檔,OfficeCLI 把這些操作變成像 shell command 一樣的命令。例如建立簡報、加入投影片、設定文字、讀取 outline、輸出 JSON,都可以用命令完成。
officecli create deck.pptx
officecli add deck.pptx / --type slide --prop title="Q4 Report"
officecli view deck.pptx outline
officecli get deck.pptx /slide[1] --json 這種形式對 Codex、Claude Code、Cursor、GitHub Copilot 這類 coding agent 很友善。Agent 不需要在不同文件格式之間背很多 Python API,只要知道 OfficeCLI 的命令和路徑規則,就能用一致方式操作三種 Office 文件。
OfficeCLI 能做哪些事
OfficeCLI 的命令不只 create 和 view。官方文件列出的核心能力包含 get、query、set、add、remove、move、swap、validate、batch、dump、merge、watch、mcp、raw 和 raw-set。這代表它不只是產生文件,也能讀取現有文件、定位元素、修改內容、驗證問題、批次處理和啟動 MCP server。
格式 可做的事 適合場景 Word 段落、樣式、表格、圖片、註腳、目錄、追蹤修訂 報告、自動合約、專案文件、審稿流程 Excel 儲存格、公式、表格、排序、條件格式、圖表、樞紐分析 月報、資料清理、預算表、營運儀表板 PowerPoint 投影片、形狀、圖片、表格、圖表、動畫、轉場 簡報初稿、銷售 deck、課程投影片、專案提案
如果你的工作已經在用 MarkItDown 把 Office 文件轉成 AI 可讀 Markdown ,OfficeCLI 可以補上另一半。MarkItDown 偏向讀取和轉換,OfficeCLI 更偏向讀寫修改和驗證。
最重要的是可視化回饋
Agent 產生文件最常見的問題,是內容看起來對,但交付檔打開後版面歪掉。OfficeCLI 的 built-in rendering engine 可以把 docx、xlsx、pptx 渲染成 HTML 或 PNG,再讓 Agent 檢查畫面。這對簡報和報告特別有用,因為很多錯誤不是純文字能看出來的。
例如 Agent 做完簡報後,可以先用 `officecli view deck.pptx html` 或 `officecli watch deck.pptx` 看預覽,再用 `officecli view deck.pptx issues –json` 找問題。這會讓文件生成變成工程流程,而不是一次性產出後靠人工開檔檢查。
安裝方式
OfficeCLI 官方提供多種安裝路線。AI Agent 可以先讀 skill file,讓 Agent 自己理解如何安裝和使用。一般開發者也可以直接跑安裝腳本,或透過 npm 安裝。
curl -fsSL https://officecli.ai/SKILL.md
curl -fsSL https://raw.githubusercontent.com/iOfficeAI/OfficeCLI/main/install.sh | bash
npm install -g @officecli/officecli Windows 則可以用 PowerShell 安裝。它的核心好處是 single binary,文件處理不必依賴本機有沒有安裝 Office。這對伺服器、CI、Docker 或 Agent 執行環境很重要。
跟 Python 套件和 LibreOffice 怎麼選
python-docx、openpyxl、python-pptx 還是很實用,尤其是你已經有固定資料結構和成熟程式碼時,LibreOffice headless 也適合某些批次轉檔需求,OfficeCLI 的優勢,是它把三種 Office 文件收斂成同一套 CLI、JSON 和路徑模型,對 Agent 來說比較容易自我修正。
我會這樣選。如果只是固定模板套資料,Python 套件仍然簡單。如果要讓 Agent 自己讀一份未知文件、理解結構、修改局部、檢查品質,再回頭修正,OfficeCLI 會更接近 AI-native 的工作方式。如果團隊正在做 Codex 與 AI 代理工作流 ,這種工具就很值得放進標準工具箱。
可以怎麼接到 Codex
最務實的做法,是先把 OfficeCLI 當成專案工具使用。讓 Codex 讀文件、產生命令、執行修改,再用 validate 和 issues 做回饋。等流程穩定後,再寫成 skill。這和 讓 Agent 自己發現和使用 skills 的方向很一致。
舉例來說,可以做一個「每週報告 skill」。輸入資料來源後,Agent 先產生 Excel 摘要,再把重點轉成 PowerPoint,最後輸出 Word 報告。OfficeCLI 負責文件讀寫與驗證,Codex 負責資料整理、判斷和修正。若還需要把團隊知識一起查進來,也可以搭配 OpenWiki 這類 Agent 共用知識庫 。
我的判斷
OfficeCLI 的真正價值,是把 Office 文件從「人打開 GUI 慢慢改」變成「Agent 可以讀、改、看、驗證、再修正」的循環。它不一定取代所有 Python library,但很適合補上 AI Agent 在文件處理裡最缺的一塊:穩定操作接口加可視化回饋。
如果你的工作常常要做報表、合約、簡報、月報、批次文件修改,這類工具會越來越重要。未來的文件自動化不只是產生文字,而是讓 Agent 能理解文件結構,知道自己改了哪裡,也能在交付前先檢查成果。
延伸資源
FAQ
OfficeCLI 是什麼?
OfficeCLI 是給 AI Agent 和開發者使用的 Office 文件 CLI,可以建立、讀取、修改和驗證 Word、Excel、PowerPoint 文件。
OfficeCLI 需要安裝 Microsoft Office 嗎?
不需要。官方主打 single binary,不依賴本機 Office 安裝,適合伺服器、CI 和 Agent 執行環境。
OfficeCLI 和 python-docx、openpyxl 差在哪裡?
Python 套件適合固定程式流程。OfficeCLI 更適合 AI Agent,因為它提供一致的 CLI、JSON 輸出、路徑式元素定位、文件驗證和 HTML 或 PNG 預覽。
Codex 可以用 OfficeCLI 嗎?
可以。Codex 可以透過終端執行 OfficeCLI 命令。若把常用流程寫成 skill,就能讓 Codex 更穩定地處理報告、簡報和表格。
by Rain Chu 7 月 20, 2026 | AI , Tool
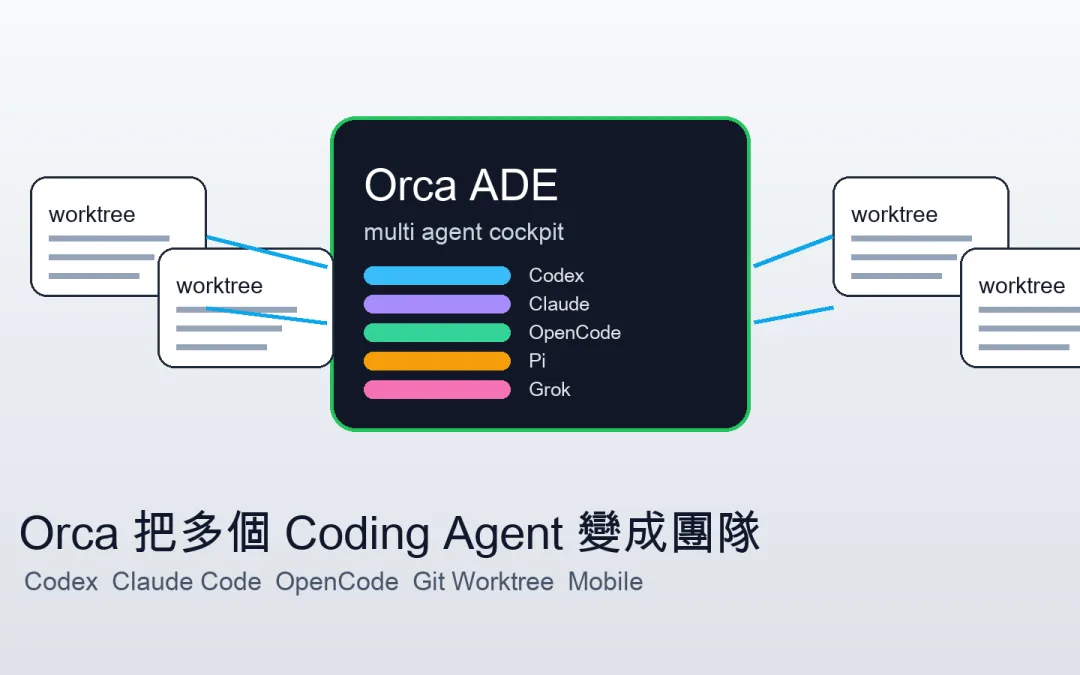
Orca 是 AI coding agent 的控制台,它把 Codex、Claude Code、OpenCode、Pi 這些 CLI agent 放進同一個開發環境,並且用 Git worktree 把每個任務隔離開來。這對已經開始同時使用多個 AI 編程工具的人很關鍵。
單一 Agent 的時代,問題通常是模型會不會寫,多 Agent 的時代,問題變成誰負責哪個分支、誰改了哪些檔案、怎麼比較成果、怎麼把最好的解法合回主線,Orca 想解的是後面這一段。
先講結論
Orca 是 stablyai 開源的 AI Development Environment,官方用法是把 Codex、Claude Code、OpenCode、Oh My Pi(OMP) 或其他 CLI agent 並排跑起來,每個 Agent 都在自己的 Git worktree 裡工作,最後由使用者比較差異、審查結果,再決定要合併哪一版。
我會把 Orca 看成 OpenWork 這類 OpenCode 工作台 的更完整版本,OpenWork 偏向把本地 Agent 工作桌面化,Orca 則更強調多 Agent orchestration、worktree 隔離、手機 companion、任務恢復和差異審查。
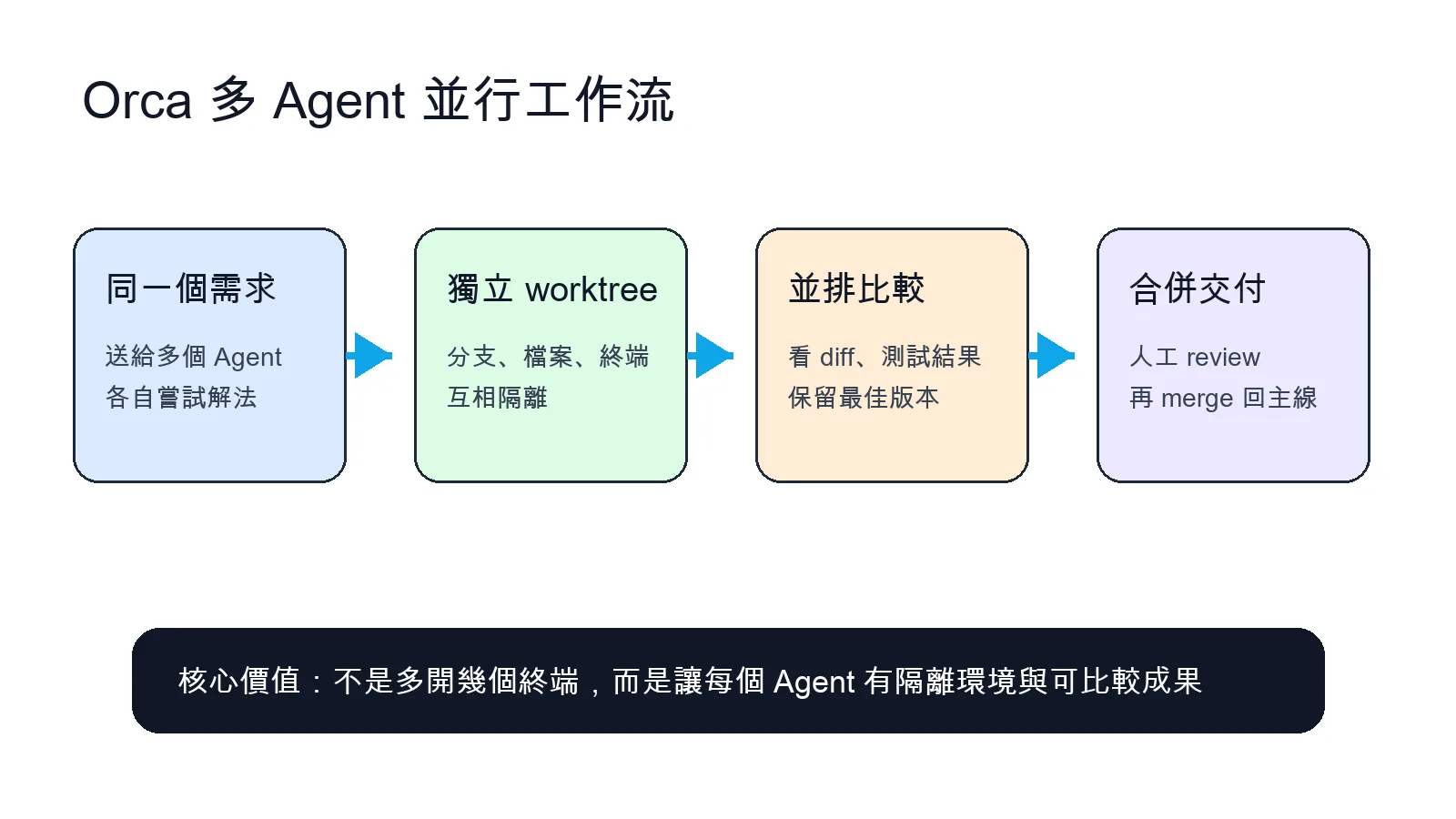
Orca 的核心不是多開終端,而是讓每個 Agent 有隔離環境,最後可以比較成果再合併。 Orca 解決的是多 Agent 失控問題
只跑一個 Codex 或 Claude Code 時,管理成本還可以接受,但當你同時讓三個 Agent 嘗試三種解法,麻煩就來了,檔案會互相覆蓋,終端輸出會混在一起,分支會弄亂,最後還要靠人回頭找哪一版比較好。
Orca 的做法是把每個 Agent 放進獨立 worktree。你可以把同一個 prompt 丟給多個 Agent,讓它們各自改一份程式碼,互不干擾。這很適合用在 bug 修復、重構、UI 改版、測試補齊和規格探索。
這和 用 Superpowers 建立 AI 開發紀律 的方向很接近。差別是 Superpowers 偏向規範和方法,Orca 偏向把這些工作流做進工具介面。
支援哪些 Agent
官方 README 的說法很直接:只要是能在 terminal 裡跑的 CLI agent,就可以放進 Orca。目前官方列出的包含 Claude Code、Codex、GitHub Copilot CLI、OpenCode、OpenClaude、OMP、Hermes Agent 等。這表示 Orca 不是綁定單一模型,而是把現有工具收進同一個 cockpit。
Agent Orca 裡的角色 適合任務 Codex 通用 coding agent 改程式、跑測試、整理專案 Claude Code 強推理與長任務 重構、架構判斷、需求拆解 OpenCode 本地或自訂模型入口 低成本實驗、本地 agent 工作流 OMP、Hermes 等 其他 CLI agent 特定工具或特定模型路線
如果你已經在用 Codex 與 ChatGPT Work 的 AI 代理工作流 ,Orca 的價值會更明顯。它不是要取代 Codex,而是讓 Codex 可以和其他 Agent 同場協作。
Parallel Worktrees 是核心
Orca 最重要的功能是 Parallel Worktrees。你可以把同一個需求發給多個 Agent,讓它們各自在不同 Git worktree 裡完成任務。完成後再比較 diff、測試結果和實作品質。這比在同一個 working tree 裡輪流叫不同 Agent 改檔安全很多。
我會把它想成「平行探索」。不是每個 Agent 都要成功,而是讓不同模型或不同 prompt 策略同時試錯。最後人做判斷,挑一個最好的版本進主線。這比盲信單一 Agent 更符合真實工程工作。
Terminal Splits 和任務恢復
Orca 也把多面板和多終端做進介面。Terminal Splits 讓你可以把多個 Agent、測試、伺服器和 logs 並排放著看。對前端專案、後端 API、資料庫 migration 這類需要同時觀察多個輸出的任務,這會比一直切 tab 順很多。
任務恢復也很重要。AI coding agent 常常不是一次跑完,尤其遇到長時間編譯、測試失敗、rate limit 或你臨時離開電腦。Orca 把任務狀態集中管理,讓你能回到原本的 Agent session,而不是重新猜它剛剛做到哪裡。
手機遠端和語音輸入不是噱頭
Mobile Companion 乍看像附加功能,但對長時間 Agent 任務其實很實用,你可以在手機上看 Agent 是否完成,收到通知後補一句 follow-up,或遠端啟動下一個任務。這讓 AI coding 從坐在電腦前等待,變成可以非同步監看。
語音輸入也類似,很多時候我們不是缺鍵盤,而是缺一個快速把想法丟給 Agent 的入口,若搭配清楚的任務模板,語音輸入可以用來快速交代需求、補充限制或要求重跑測試。
GitHub Issue 和定時審查
Orca 官方也強調 GitHub 和 Linear 的原生整合。你可以在 app 裡看 issue、PR、project board,並從任務直接開 worktree。這讓「看任務 → 啟動 Agent → 產生改動 → review diff」變成一條線,而不是在瀏覽器、終端、IDE、Git UI 之間來回切。
定時審查 repository 是另一個有意思的方向,它適合拿來做每日或每週檢查,例如 dependency 更新、測試覆蓋率、錯誤 logs、未完成 issue、重複程式碼。這類任務不一定需要最強模型,但需要穩定排程和可追蹤結果。
和 Playwright CLI、OpenWork 怎麼搭
Orca 管的是多 Agent 和 worktree。Playwright CLI 管的是瀏覽器自動化。OpenWork 管的是 OpenCode 和本地 Agent 桌面工作台。這些工具其實不是互斥,而是分別解決 AI 開發流程中的不同層級。
我的理想組合會是:Orca 負責多 Agent 任務隔離,Codex 或 Claude Code 負責實作,Playwright CLI 負責跑 UI 驗證,Graphify 或 OpenWiki 負責專案知識。這樣 Agent 就不是聊天框,而是完整開發系統的一部分。
安裝與使用入口
Orca 官方下載入口在 onOrca.dev,支援 macOS、Windows、Linux。Windows 使用者官方 README 也提醒可以抓較新的 RC 版本,因為有 Windows fixes。手機 companion 則提供 iOS App Store、TestFlight 和 Android APK。
桌面版:到 onOrca.dev/download 下載
原始碼:stablyai/orca GitHub
手機 companion:官方 README 提供 iOS、TestFlight 和 Android APK 連結
支援 Agent:Codex、Claude Code、OpenCode、GitHub Copilot CLI、Pi、Hermes Agent 和其他 CLI agent
我的判斷
Orca 的價值,不是讓你同時叫五個 Agent 然後期待奇蹟發生。真正有用的是隔離、比較、恢復、審查和合併,多 Agent 不是數量遊戲,而是工程流程問題。
如果你只是偶爾用 Codex 改一兩個檔案,Orca 可能有點重,但如果你已經常常同時開 Claude Code、Codex、OpenCode,或想把 issue 修復、UI 測試、code review 分配給不同 Agent,Orca 就值得試,它比較像從單兵作戰進入小隊協作。
延伸資源
FAQ
Orca ADE 是什麼?
Orca 是 AI Development Environment,可以把 Codex、Claude Code、OpenCode、Pi 等 CLI agent 放在同一個介面裡並行工作。
Orca 為什麼要用 Git worktree?
Git worktree 可以讓每個 Agent 在獨立工作區修改程式碼,避免互相覆蓋檔案,也方便最後比較 diff 和測試結果。
Orca 適合所有開發者嗎?
如果只是偶爾用一個 Agent 改小檔案,Orca 可能太重。若你常用多個 Agent、需要任務隔離、差異比較、手機遠端和任務恢復,Orca 就很適合。



近期留言