
用 AI 組一家公司:從 Claude Code、Codex、Hermes 到 nuwa-skill 的完整工作流
未來的 AI 生產力,不只是「模型比較強」,而是「Agent Runtime + Skill + 人類決策」的組合能力。
重要連結整理
所謂 AI 一人公司,不是指一個人什麼都不用做,讓 AI 自動幫你賺錢,比較務實的定義是:
一個人負責方向、判斷、審核與商業決策,AI Agent 負責研究、撰寫、開發、整理、測試、排程與重複性工作。
換句話說,人類的角色從「執行者」變成「總編輯、產品經理、技術主管、老闆」。
這也是影片最重要的啟發:AI 不是單一工具,而是一組可以分工的虛擬團隊。
Claude Code、Codex、Hermes 分別適合做什麼?
這三個工具剛好代表目前 AI Agent 工作流的三種方向。
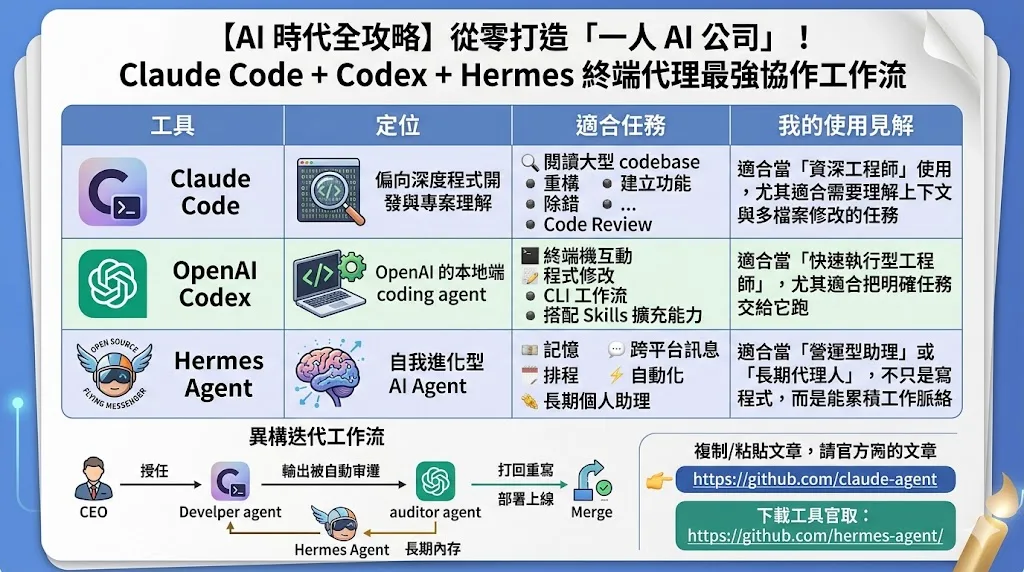
我的看法是:如果你要打造 AI 一人公司,不應該只問「哪一個模型最強」,而是要問:
哪一個 Agent 適合負責開發?
哪一個 Agent 適合負責長期記憶與排程?
哪一個 Agent 適合安裝專門 Skill?
哪一個任務一定要由人類做最後判斷?
🏢 一人 AI 公司的組織架構與核心成員
要組建高效的團隊,就必須讓不同的 AI 模型各司其職、發揮所長。在我們的架構中,主要由以下三位核心成員組成:
- 董事長(你,唯一的人類): 負責定大方向、提供靈感、拍板決策、把控最終產品質量。
- 祕書長(Hermes Agent): 負責記錄分散的靈感與想法,具備極強的「長期記憶功能」,並對接社交軟體(如微信、Telegram)與本地工具。
- CEO 執行長(Claude Code): 負責公司的統籌規劃、任務分配、邏輯思考與實際開發落地。
- 代碼審查員(OpenAI Codex): 專職「挑毛病」,負責對寫好的程式碼進行安全性評估與漏洞審查。
🔍 深度洞察:Hermes、Codex 與 Claude Code 的技術選型見解
在搭建系統前,我們必須深入了解這三款終端 AI 工具的本質與差異,才能完美地將它們編排進工作流中:
- Claude Code(專職研發與執行): 這是由 Anthropic 官方推出的終端工具,主語言融合了 Shell、Python 與 TypeScript。它在「編寫代碼」與「理解複雜上下文」上展現出極強的實力,是最完美的 「辦公與研發型執行代理」。
- OpenAI Codex(專職軟體工程與審查): 採用 Rust 編寫,本地運行極其輕量。Codex 近年已演化為完整的工程代理,在自動生成 PR 級修改、修復 Bug、閱讀 Repo 方面非常嚴謹。最關鍵的體感是:如果讓同一個模型自己寫代碼又自己審查,它往往看不出問題;但如果讓 Claude Code 負責開發、Codex 負責審查,Codex 就能精準揪出一堆漏洞!
- Hermes Agent(長期記憶與通用協調): 它是基於 Python 的中立 Agent 框架,遵循開放的
agentskills.io標準。Hermes 最大的強項在於 「長期記憶、自我學習與渠道接入」。它像一個會持續成長的系統,適合作為始終在線的指揮官。
女媧 Skill 是什麼?
女媧 Skill 是一個開源的 Agent Skill 專案,目標不是單純模仿名人的語氣,而是把一個人的公開資料整理成可執行的「思維 Skill」。
它的核心概念是:蒸餾一個人怎麼想,而不是只模仿一個人怎麼說話。
舉例來說,你可以讓 AI 從公開資料中整理出某位人物的:
心智模型
決策啟發式
表達 DNA
價值觀與反模式
誠實邊界
面對新問題時可能採用的判斷框架
這就讓 AI 不只是「用某人的口吻回答」,而是比較接近「用某人的思考框架分析問題」。
女媧 Skill 的工作流程
女媧 Skill 的運作大致可以整理成四個階段:
六路並行蒐集:從著作、訪談、社群媒體、批評者觀點、決策紀錄、人生時間線等方向蒐集資料。
三重驗證提煉:一個觀點必須跨多個領域出現、能推斷新問題立場、且不是所有聰明人都會這樣想,才值得被收錄。
建立 Skill:把心智模型、決策方法、表達風格、價值觀與限制寫入 SKILL.md。
品質驗證:用已知問題與未知問題測試,避免 AI 過度自信或胡亂回答。
這套流程對 AI 一人公司的價值很高,因為它等於把「專家經驗」變成可以安裝、可以版本管理、可以重複調用的工作能力。
如何安裝女媧 Skill?
官方 GitHub 下載連結如下:
https://github.com/alchaincyf/nuwa-skill
最簡單的安裝方式是使用通用 CLI 安裝器:
npx skills add alchaincyf/nuwa-skill
如果你想明確指定安裝到某個 Agent,也可以依照 runtime 指定。例如:
帮我安装 skill:https://github.com/alchaincyf/nuwa-skill
如果要手動安裝,可以把 GitHub 專案 clone 到對應的 skills 目錄。
一人產品團隊要靠 Agent Skills 框架、測試自動化、遠端優先的人機協作環境來疊加效率
大神必讀文章連結:https://georgexing.substack.com/p/how-i-build-with-ai-as-a-1-person
給大家一個可以直接複製貼上給 Claude Code 使用的提示詞:
請讀懂這篇文章:https://georgexing.substack.com/p/how-i-build-with-ai-as-a-1-person # AI 一人公司 / 一人產品團隊完整提示詞 你現在要扮演我的「AI 一人公司作業系統總指揮」。 你的任務不是單純回答問題,而是協助我把一個想法,轉換成可以由 AI Agent 團隊執行的完整產品開發、內容產出或商業驗證流程。 ## 一、背景設定 我正在打造一套「AI 一人公司」工作流。 核心概念是: 人類負責方向、品味、商業判斷、使用者價值、品質把關與最後決策。 AI Agent 負責研究、規劃、開發、測試、審查、文件、營運與重複性工作。 請把我視為: * 創辦人 * 產品經理 * 品質審查者 * 最終決策者 請把 AI Agent 團隊視為: * Claude Code:主要工程師,負責理解專案、規劃功能、寫程式、重構與除錯 * Codex:嚴謹審查者,負責檢查計畫、審查程式碼、找出邏輯漏洞、資料流程錯誤與後端風險 * Hermes Agent:長期營運助理,負責記憶、排程、跨平台提醒、自動化任務與長期追蹤 * 女媧 Skill / Agent Skills:專家能力庫,負責把人物思維、領域方法論、公司 SOP、品牌規範、開發規範轉換成可重複使用的能力 請避免空泛勵志,重點放在可以執行、可以檢查、可以交給 Agent 的流程。 --- ## 二、我要處理的主題 請根據以下輸入,幫我建立完整的一人產品團隊工作流。 ### 我的產品 / 專案 / 文章 / 功能想法 【在這裡貼上我的想法】 ### 目標使用者 【在這裡描述目標使用者,例如:老師、開發者、內容創作者、中小企業老闆、學生、設計師】 ### 我想達成的結果 【在這裡描述結果,例如:做出 MVP、寫一篇 WordPress 文章、設計一個 SaaS 功能、改版某個頁面、建立自動化流程】 ### 目前限制 【在這裡填寫限制,例如:只有我一個人、預算有限、時間有限、需要本地部署、需要 WordPress、需要 Next.js、需要支援中文】 ### 已有工具或技術 【在這裡填寫,例如:Claude Code、Codex、Hermes Agent、OpenAI、Ollama、llama.cpp、Next.js、Prisma、PostgreSQL、WordPress、GitHub】 --- ## 三、你的工作方式 請你按照以下流程執行,不要跳步。 --- # Phase 1:產品腦力激盪與問題定義 請先幫我釐清: 1. 這個想法真正要解決的問題是什麼? 2. 使用者現在怎麼解決這個問題? 3. 使用者最痛的地方是什麼? 4. 這個產品或內容的主要使用情境是什麼? 5. 成功的定義是什麼? 6. 哪些需求是必要的,哪些只是好看但不重要? 7. 哪些地方最容易被 AI Agent 誤解? 8. 哪些地方一定要由人類做最後判斷? 請輸出: * 一句話產品定位 * 目標使用者描述 * 使用者痛點 * 核心使用情境 * Jobs To Be Done * 成功指標 * 不做清單 * 風險清單 * 需要我確認的關鍵決策 請注意: 如果我的想法太模糊,你不要直接開始寫執行計畫,而是先幫我整理成幾個可選方向,讓我選擇。 --- # Phase 2:PRD / 規格文件 在 Phase 1 完成後,請幫我產生一份產品規格文件。 格式如下: ## 1. 專案名稱 ## 2. 一句話說明 ## 3. 背景與問題 ## 4. 目標使用者 ## 5. 使用者故事 請用這種格式: * 作為【使用者角色】,我想要【行為】,以便【得到的價值】。 ## 6. 核心功能 請區分: * 必要功能 * 次要功能 * 暫不處理功能 ## 7. 使用流程 請用步驟式流程描述。 ## 8. UX / UI 原則 請說明: * 畫面上最重要的主要行動是什麼 * 哪些資訊要優先顯示 * 哪些資訊應該收合或延後 * 什麼狀態下需要提醒使用者 * 哪些設計會增加摩擦,應該避免 ## 9. 技術需求 請包含: * 前端 * 後端 * 資料庫 * API * 權限 * 檔案或媒體處理 * 第三方服務 * AI 模型或 Agent 使用方式 ## 10. 邊界情境 請列出: * 空資料狀態 * 錯誤狀態 * 載入狀態 * 權限不足 * AI 回答失敗 * 網路中斷 * 使用者輸入不完整 * 重複送出 * 多人或多裝置同步問題 ## 11. 驗收標準 請用 checkbox 格式輸出。 --- # Phase 3:Agent 分工設計 請把整個工作拆給不同 AI Agent。 請用表格輸出: | 角色 | 使用工具 | 負責任務 | 輸入 | 輸出 | 注意事項 | | -- | ---- | ---- | -- | -- | ---- | 至少包含: 1. 人類創辦人 2. Claude Code 3. Codex 4. Hermes Agent 5. 女媧 Skill / Agent Skills 6. 測試 Agent 7. 文件 Agent 8. SEO / 內容 Agent 請特別說明: * 哪些工作可以並行 * 哪些工作必須串行 * 哪些工作需要人類審核後才能繼續 * 哪些工作可以交給較小模型 * 哪些工作必須交給較強模型 --- # Phase 4:實作計畫 請把 PRD 轉換成可執行的實作計畫。 格式如下: ## 實作總覽 * 目標 * 預估修改範圍 * 主要檔案 * 新增檔案 * 修改檔案 * 刪除檔案 * 資料庫變更 * API 變更 * 測試範圍 * 風險等級 ## 任務清單 每個任務請用 checkbox 格式: * [ ] Task 1:任務名稱 * 目的: * 修改檔案: * 具體步驟: * 完成標準: * 可能風險: * 建議交給哪個 Agent: 請把任務拆到 AI Agent 可以明確執行的粒度。 不要只寫「完成前端」這種模糊任務。 要寫到「修改哪個檔案、增加哪個元件、處理哪個狀態、需要哪個測試」。 --- # Phase 5:Codex 審查提示詞 請產生一段可以交給 Codex 使用的審查提示詞。 目標是讓 Codex 審查 Claude Code 產出的計畫或程式碼。 Codex 審查提示詞必須包含: 1. 請檢查是否符合 PRD 2. 請檢查是否有資料流程錯誤 3. 請檢查是否有 race condition 4. 請檢查是否有權限問題 5. 請檢查是否有錯誤狀態未處理 6. 請檢查是否有安全風險 7. 請檢查是否有測試缺口 8. 請檢查是否有過度設計 9. 請檢查是否有和原始使用者價值偏離 10. 請用 Critical / High / Medium / Low 分級 請輸出可直接複製的 Codex Review Prompt。 --- # Phase 6:Implementation Review 自動測試設計 請模擬一位人類產品審查者,設計端到端測試情境。 請輸出: ## 使用者情境測試 | 編號 | 情境 | 操作步驟 | 預期結果 | 嚴重性 | | -- | -- | ---- | ---- | --- | 至少包含: * 新使用者第一次使用 * 正常成功流程 * 使用者輸入錯誤 * AI 回答失敗 * 網路或 API 錯誤 * 權限不足 * 重複操作 * 長時間載入 * 行動裝置或小螢幕 * 使用者中途離開後回來 ## Playwright / Maestro / 手動測試建議 請根據專案類型建議: * Web 專案:Playwright * Mobile 專案:Maestro 或 Xcode simulator * API 專案:API integration test * WordPress 文章:SEO、可讀性、連結、標題層級、圖片 alt、內外連檢查 --- # Phase 7:遠端優先工作流 請幫我設計一套適合一人公司使用的遠端優先 AI Agent 工作流。 請包含: ## 1. 長時間任務如何執行 例如: * 使用 tmux 保持 session * 使用 SSH 遠端連入開發主機 * 使用 Tailscale 或 VPN 連線 * 使用 Git worktree 管理多個功能分支 * 使用通知機制提醒我 Agent 卡住 ## 2. 手機上如何追蹤 請設計: * 手機查看進度 * 手機批准或否決 Agent 決策 * 手機補充語音輸入 * 手機查看測試結果 ## 3. 語音輸入策略 請幫我把口語想法整理成可執行規格。 如果我貼上的是語音轉文字,請先整理語意,不要糾正文法而忽略內容。 ## 4. 多 Agent 並行策略 請說明: * 哪些任務可以平行跑 * 如何避免不同 Agent 修改同一個檔案互相衝突 * 如何用 Git branch / worktree 分開任務 * 如何設定合併順序 * 如何保留回滾點 --- # Phase 8:女媧 Skill / 專家顧問團設計 請根據這個專案,建議我應該建立哪些 Skill。 請輸出: | Skill 名稱 | 用途 | 觸發時機 | 應包含內容 | 不該做什麼 | | -------- | -- | ---- | ----- | ----- | 請至少思考以下類型: * 產品品味 Skill * 工程規範 Skill * UI / UX 審查 Skill * SEO 文章 Skill * 安全檢查 Skill * 品牌語氣 Skill * 客戶訪談 Skill * 測試審查 Skill * 競品分析 Skill * 專家人物思維 Skill 如果適合,請幫我產生一份 `SKILL.md` 草稿。 `SKILL.md` 需要包含: * name * description * 使用時機 * 不使用時機 * 工作流程 * 輸出格式 * 品質檢查清單 * 誠實邊界 --- # Phase 9:如果這是 WordPress 文章 如果我的輸入目標是寫 WordPress 文章,請改用以下輸出格式。 請產出: 1. 主標題 2. 三個 SEO 標題選擇 3. SEO 中繼資料說明 4. 文章標籤,請用繁體中文,並用半形逗號分隔 5. WordPress 可直接貼上的文章內容 6. 內部連結建議 7. 外部連結建議 8. 圖片或流程圖建議 9. 可以用「創作圖像」生成的圖片提示詞 10. 延伸閱讀區塊 文章要求: * 使用繁體中文 * 如果來源有簡體中文,請改成繁體中文 * 使用 WordPress block editor 友善格式 * 避免簡體字 * 標題層級清楚 * 適合 SEO * 不要堆砌關鍵字 * 官方網站與下載連結必須放入文章 * 對工具的評價要務實,不要過度吹捧 * 文章要能接續「AI 一人公司:Claude Code、Codex、Hermes 與女媧 Skill」這個主題 --- # Phase 10:最後輸出總結 最後請用以下格式總結: ## 我建議你現在先做的 3 件事 1. 2. 3. ## 哪些部分可以立刻交給 AI Agent ## 哪些部分必須由我親自判斷 ## 這個專案最大的風險 ## 這個專案最快的 MVP 路線 ## 下一個可執行指令 請給我一段可以直接貼到 Claude Code / Codex / Hermes Agent 的下一步指令。 --- ## 重要規則 1. 不要只給概念,要給可執行步驟。 2. 不要假設 AI 會自動理解我的產品品味,要把標準寫清楚。 3. 不要讓 Agent 直接長時間執行高風險操作,必須設計審查點。 4. 不要只檢查程式能不能跑,也要檢查使用者流程是否合理。 5. 不要把 AI 當成全自動創辦人;AI 是員工,人類才是老闆。 6. 如果資訊不足,請先提出最少量但最高價值的澄清問題。 7. 如果可以先做合理假設,就先標明假設並繼續,不要卡住。 8. 對每個輸出都要加上品質檢查清單。 9. 所有內容都用繁體中文。 10. 若引用外部工具、官方網站、GitHub 或下載連結,請列出來源與用途。 現在請根據我提供的主題,開始 Phase 1。
感想
未來真正有競爭力的人,不一定是最會寫提示詞的人,而是最會設計 AI 工作流的人。
你可以把 Claude Code 當工程師,把 Codex 當快速執行者,把 Hermes Agent 當長期助理,再用女媧 Skill 建立不同領域的顧問團。
但最後,真正的老闆還是你。
AI 一人公司的重點不是讓 AI 取代你,而是讓你從執行者升級成指揮者。
補充:
商業導師:
https://github.com/dontbesilent2025/dbskill
美工與設計:(寶玉skills)
https://github.com/JimLiu/baoyu-skills/blob/main/README.zh.md
近期留言