by Rain Chu | 6 月 6, 2026 | AI, 圖型處理
2026 年最受矚目的 AI 繪圖模型之一,莫過於 Ideogram 團隊正式釋出的:
Ideogram 4
這是 Ideogram 首次公開模型權重(Open Weight),也是目前開源陣營中,在:
- 文字生成(Text Rendering)
- 海報設計
- 品牌廣告
- 排版控制
- JSON 結構化提示詞
官方資料顯示,Ideogram 4 採用 9.3B 參數的單流 Diffusion Transformer(DiT)架構,並支援原生 2K 圖像生成。
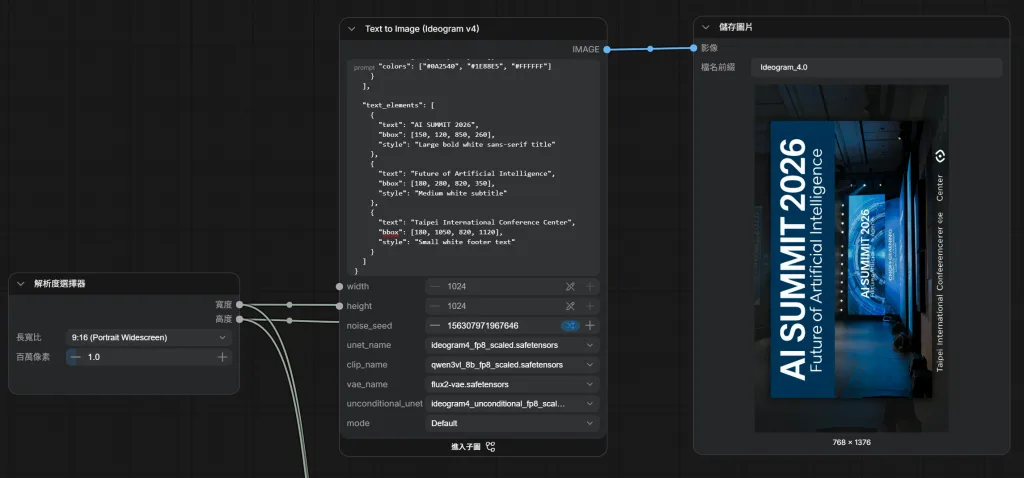
本篇將帶你使用 ComfyUI,在本機部署 Ideogram 4。
系統需求
官方模型共有兩個版本:
| 版本 | 量化 |
|---|
| Ideogram 4 FP8 | 品質最佳 |
| Ideogram 4 NF4 | VRAM需求較低 |
目前 ComfyUI 官方整合版本主要使用:
其中 FP8 畫質最佳。
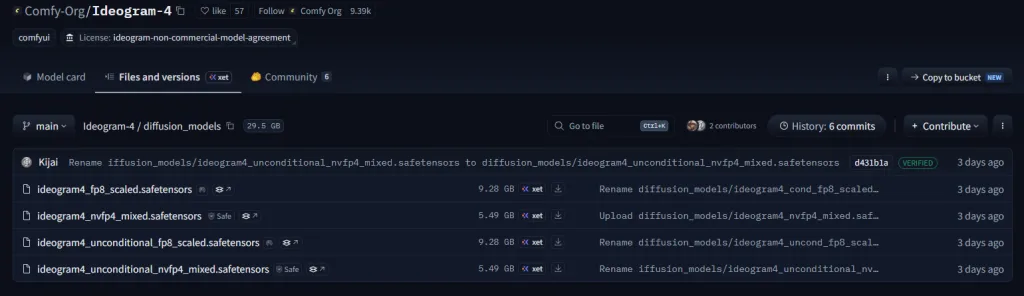
第一步:下載模型
ComfyUI 專用模型
官方:
Comfy-Org Ideogram-4
原始模型:
Ideogram 4 FP8 官方模型
第二步:放置模型檔案
依照官方說明建立目錄。
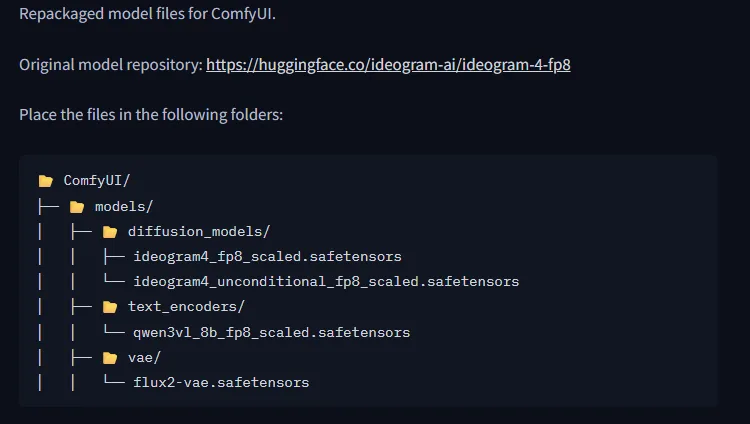
ComfyUI
│
├─ models
│ ├─ diffusion_models
│ │ ├─ ideogram4_fp8_scaled.safetensors
│ │ └─ ideogram4_unconditional_fp8_scaled.safetensors
│ │
│ ├─ text_encoders
│ │ └─ qwen3vl_8b_fp8_scaled.safetensors
│ │
│ └─ vae
│ └─ flux2-vae.safetensors
第三步:了解每個模型用途
ideogram4_fp8_scaled
主模型
負責:
ideogram4_unconditional_fp8_scaled
CFG 引導模型
負責:
- 提升細節
- 強化 Prompt Follow
- 改善品質
官方建議兩個模型一起使用。若只載入主模型雖可運作,但畫質會下降。
qwen3vl_8b_fp8_scaled
文字編碼器
負責:
- Prompt 理解
- JSON 理解
- 空間推理
- 海報版面配置
flux2-vae
VAE 解碼器
負責將 Latent 轉換成圖片。
第四步:更新 ComfyUI
Ideogram 4 需要最新版本的 ComfyUI。
更新方式:
或:
官方於 Day-0 即已原生支援 Ideogram 4。
第五步:載入官方 Workflow
ComfyUI 官方已提供範例工作流。
建議直接從:
Comfy Blog
下載 Workflow。
基礎工作流架構
Prompt
↓
Qwen3-VL Encoder
↓
Ideogram 4
↓
Sampler
↓
Flux VAE Decode
↓
Save Image
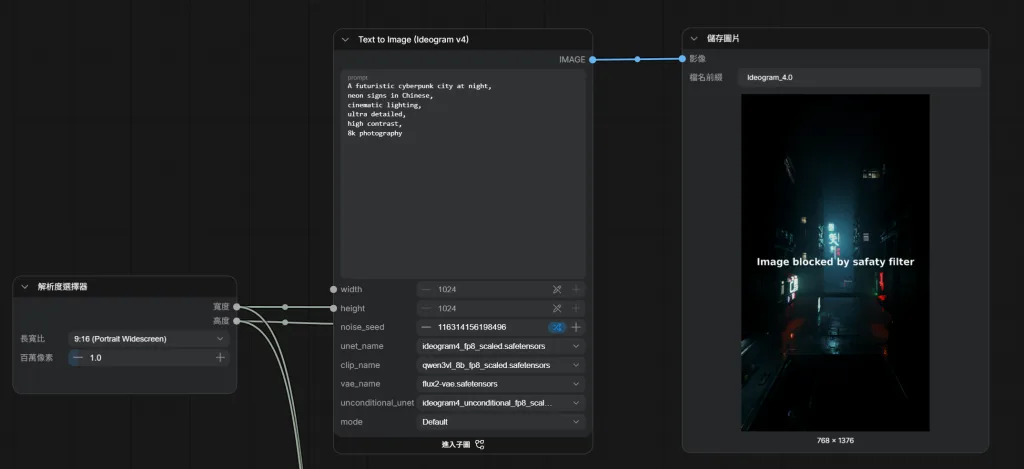
第六步:第一張圖片
測試 Prompt:
A futuristic cyberpunk city at night,
neon signs in Chinese,
cinematic lighting,
ultra detailed,
high contrast,
8k photography
生成尺寸:
推理模式:
第七步:體驗 JSON Prompt
Ideogram 4 最大特色就是:
Structured JSON Prompt
官方模型訓練時即使用 JSON Caption。
範例:海報設計
{
"scene_summary": "Professional technology conference poster",
"background": {
"description": "Modern convention center stage with blue ambient lighting, large LED screen, clean professional environment"
},
"style": {
"description": "Corporate marketing design, professional conference poster, clean typography, premium branding, modern layout"
},
"objects": [
{
"description": "Conference stage",
"bbox": [100, 150, 900, 850],
"colors": ["#0A2540", "#1E88E5", "#FFFFFF"]
}
],
"text_elements": [
{
"text": "AI SUMMIT 2026",
"bbox": [150, 120, 850, 260],
"style": "Large bold white sans-serif title"
},
{
"text": "Future of Artificial Intelligence",
"bbox": [180, 280, 820, 350],
"style": "Medium white subtitle"
},
{
"text": "Taipei International Conference Center",
"bbox": [180, 1050, 820, 1120],
"style": "Small white footer text"
}
]
}
Bounding Box 控制
可直接指定位置。
{
"text_elements":[
{
"text":"SALE 50%",
"bbox":[100,100,500,300]
}
]
}座標範圍:
原點:
這是目前 FLUX 與 Stable Diffusion 所不具備的能力。
色彩盤控制
品牌設計超級好用。
{
"color_palette":[
"#FF6600",
"#FFFFFF",
"#000000"
]
}官方支援:
與 FLUX 比較
FLUX 強項
Ideogram 4 強項
- Logo
- 海報
- Banner
- 電商素材
- 排版設計
- 中文文字生成
若你是:
Ideogram 4 很可能比 FLUX 更適合。
結論
Ideogram 4 不只是另一個 AI 繪圖模型。
它最大的創新在於:
把 Prompt 從自然語言升級為結構化設計規格。
透過:
- Qwen3-VL
- Diffusion Transformer
- JSON Prompt
- Bounding Box
- Color Palette
使用者終於可以像操作 Figma 一樣控制 AI 生成內容。
對於需要:
- 海報設計
- 品牌素材
- Banner 製作
- AI Agent 自動產圖
的開發者來說,Ideogram 4 是目前最值得研究與部署的開源模型之一。
by Rain Chu | 6 月 6, 2026 | AI, 繪圖
AI 圖像生成正式進入「設計級控制」時代
近兩年 AI 繪圖領域競爭激烈,從 Midjourney、Stable Diffusion、FLUX,到 Google Imagen,各家模型都在追求更好的畫質與更精準的提示詞理解能力。
真正困擾設計師與企業用戶的問題其實不是畫質,而是以下的問題:
- 文字總是生成錯誤
- 排版無法控制
- Logo 與標題位置不準確
- 無法符合品牌色彩規範
- 每次生成結果都像在「抽卡」
2026 年 6 月,Ideogram 正式推出最新開源模型:
Ideogram 4.0
這不僅是 Ideogram 首次公開權重(Open Weight)模型,更被許多開發者視為目前最接近商業設計工作流程的 AI 圖像生成系統。
什麼是 Ideogram 4.0?
Ideogram 4.0 是一款從零開始訓練的 AI 圖像生成模型,採用最新的:
Diffusion Transformer(DiT)架構
與傳統 Stable Diffusion 不同,Ideogram 4.0 使用:
- 34 層 Transformer
- 93 億參數(9.3B)
- 單流(Single Stream)設計
- 文字 Token 與影像 Token 共用同一套注意力機制
官方稱其為:
Single-Stream Diffusion Transformer(DiT)
這種架構讓模型能更深入理解文字與影像之間的關聯,提高提示詞遵循能力(Prompt Adherence)與版面控制能力。
核心架構解析
1. 文字編碼器(Text Encoder)
Ideogram 4.0 並未使用傳統的 CLIP 或 T5 「文字編碼器(Text Encoder)」。
而是採用了:
Qwen3-VL-8B-Instruct
作為文字理解引擎。
其特色包括:
- 視覺語言模型(Vision Language Model)
- 僅使用文字模式
- 提取 13 個中間層隱藏狀態
- 將多層特徵串接後輸入 DiT
這種設計能同時保留:
讓模型對複雜提示詞有更深層的理解能力。
2. DiT 主幹網路
Ideogram 4.0 採用:
- 34 Layers
- Embedding Dimension:4608
- 18 Attention Heads
- SwiGLU Feed Forward
總參數量達:
9.3 Billion Parameters
目前已是開源 AI 繪圖模型中最頂尖的規模之一。
3. VAE 解碼器
使用凍結(Frozen)的:
KL VAE
特性:
- 8× 空間壓縮
- 128 Latent Channels
負責將潛在空間(Latent Space)轉換為最終圖像。
4. Flow Matching 取樣器
不同於傳統 DDPM。
Ideogram 4.0 採用:
Euler Flow Matching
搭配:
Asymmetric CFG
特色:
- 提升生成效率
- 改善細節品質
- 更穩定的提示詞遵循能力
官方提供三種推理模式:
| 模式 | Steps |
|---|
| V4_TURBO | 12 |
| V4_DEFAULT | 20 |
| V4_QUALITY | 48 |
品質模式會在最後階段降低引導強度,進一步提升真實感。
最大突破:JSON 結構化提示詞
這是 Ideogram 4.0 最具革命性的地方。
過去 AI 繪圖都依賴自然語言:
A beautiful girl standing beside a lake...
Ideogram 4.0 則改為:
{ "background": "...", "objects": [...], "texts": [...], "style": {...}}模型訓練時完全使用 JSON 描述,因此天生理解結構化資訊。
Bounding Box 精準版面控制
支援 Bounding Box:
{ "bbox": [100,100,400,400]}採用:
可直接指定:
這是過去 Midjourney、Stable Diffusion 很難做到的功能。
色彩盤控制(Color Palette)
可直接指定品牌色:
{ "colour_palette": [ "#FF6600", "#FFFFFF", "#000000" ]}限制:
非常適合:
多語言文字生成能力大幅提升
Ideogram 一直以來最強的能力就是:
Text Rendering
也就是圖片內文字生成。
例如:
以往 AI 經常出現亂碼。
但 Ideogram 4.0 已能大幅提升:
等多語系文字品質。
原生支援 2K 輸出
解析度支援:
- 最小:256 × 256
- 最大:2048 × 2048
且:
例如:
- YouTube Banner
- 網站橫幅
- 電商主圖
- 手機桌布
皆可直接生成。
設計工作流功能全面升級
除了模型本身之外,Ideogram 平台也同步推出多項設計工具:
Prompt Edit
直接修改既有圖片中的特定區域。
Magic Fill
局部重繪。
Remix
基於現有圖片重新生成。
Extend / Reframe
擴展畫布與調整比例。
Upscale
提高解析度。
Transparent Background
直接輸出透明背景 PNG。
MCP 整合
可接入 AI Agent 工作流程。
Editable Text Layers
未來將支援真正可編輯的文字圖層功能。
Ideogram 4.0 與 Google Imagen 誰更強?
若比較:
- Google Imagen
- FLUX
- Stable Diffusion
- Ideogram 4.0
目前 Ideogram 最大優勢在於:
✅ 文字生成能力
✅ 排版控制能力
✅ JSON 結構化設計流程
✅ 開源權重
✅ 可自行部署
而 Google Imagen 仍在:
方面維持優勢。
若是企業設計工作流,Ideogram 4.0 已經是極具競爭力的選擇。
官方資源
官方網站
Ideogram 官方網站
模型介紹
Ideogram 4.0 Model Page
技術部落格
Ideogram 4.0 Technical Details
API 文件
Ideogram Developer API
GitHub
Ideogram 4 GitHub Repository
Hugging Face
Ideogram 4 Hugging Face Collection
Ideogram 4.0 不只是另一個 AI 繪圖模型。
它最大的突破在於:
把 AI 繪圖從「描述圖片」提升到「設計圖片」。
透過:
- Diffusion Transformer(DiT)
- Qwen3-VL 編碼器
- JSON Prompt
- Bounding Box 控制
- 色彩盤控制
- 可編輯文字圖層
Ideogram 4.0 正逐步接近 Photoshop、Illustrator 與 Figma 所代表的專業設計工作流程。
對於品牌設計、電商素材、廣告製作與 AI Agent 自動化內容生成來說,Ideogram 4.0 很可能會成為 2026 年最值得關注的開源 AI 圖像生成模型之一
by rainchu | 12 月 18, 2025 | AI, 圖型處理, 影片製作
眾多 AI 創作平台之中,Liblib 憑藉其高度整合的功能、生態完整度以及對中文使用者的極致友善設計,迅速成為中國最領先的 AI 創作平台之一。
一站式 AI 影像與視頻創作平台
Liblib 不僅僅是一個圖片生成網站,而是一個超級齊全的 AI 創作平台,涵蓋:
- AI 圖片生成
- AI 視頻特效與動畫
- 模型管理與分享
- 視覺化工作流(Workflow)
- LoRA 訓練與應用
透過雲端化的設計,使用者無需自行架設環境,即可直接在瀏覽器中使用高階 AI 生成能力。
深度整合 WebUI 與 ComfyUI
對於熟悉 Stable Diffusion 生態的使用者而言,Liblib 最大的優勢之一,在於它同時支援:
- WebUI:操作直覺、上手快速,適合大多數創作者
- ComfyUI:節點式工作流,適合進階用戶進行複雜控制與自動化生成
這種雙軌並行的設計,讓初學者與專業用戶都能在同一平台中找到最適合自己的創作方式。
強大的 LoRA 訓練能力
Liblib 在 LoRA 訓練方面表現尤為突出,提供完整且視覺化的訓練流程:
- 上傳資料集即可開始訓練
- 支援多種風格與角色 LoRA
- 訓練完成後可直接套用於生成
- 社群分享與模型市集機制
這讓創作者能快速打造專屬風格模型,大幅降低 AI 模型訓練的門檻。
中文使用者極度友善
相較於許多國外 AI 平台對中文支援不足,Liblib 在以下方面明顯優於同類產品:
- 完整繁體與簡體中文介面
- 中文 Prompt 理解度高
- 中文模型與 LoRA 資源豐富
- 適合華語創作者的社群內容
對中文內容創作者來說,這是一個真正「為中文而生」的 AI 創作平台。
工作流與創作效率全面升級
Liblib 內建的 工作流系統(Workflow),讓使用者可以:
- 將複雜生成流程模組化
- 重複使用高品質生成邏輯
- 快速套用他人分享的創作流程
- 大幅提升商業與批量創作效率
這對於需要大量產出視覺內容的團隊與個人創作者而言,是極具價值的功能。
為什麼 Liblib 是中國最領先的 AI 創作平台?
綜合來看,Liblib 的核心優勢包括:
- ✅ 視頻特效 + 圖片模型完整整合
- ✅ WebUI 與 ComfyUI 同時支援
- ✅ 強大且易用的 LoRA 訓練
- ✅ 中文高度友善,資源豐富
- ✅ 從新手到專業用戶皆適用
這不僅是一個工具,更是一個完整的 AI 創作生態系。
官方網站
👉 Liblib 官方平台
https://www.liblib.art/

by rainchu | 12 月 3, 2024 | AI, 圖型處理
TryOffDiff:開創虛擬脫衣的新方向
在電子商務與生成式模型的發展中,虛擬試穿(Virtual Try-On, VTON)技術早已佔據重要一席之地,讓用戶能在數位環境中模擬穿戴效果,但一項新興的任務——虛擬脫衣(Virtual Try-Off, VTOFF)正在改變我們對電子商務中的服裝數位化處理的理解。
什麼是 VTOFF?
虛擬脫衣(VTOFF)是可以從穿著者的單張照片中提取標準化的服裝影像,而不是僅僅模擬服裝穿著的效果,最大的好處是幫助你快速分離模特兒身上的衣服,VTOFF 的挑戰在於,如何準確捕捉服裝的形狀、材質與細節紋理,同時去除穿著者的影響,生成一個純粹且高還原度的服裝影像。
這項任務的核心價值在於:
- 提供標準化的服裝圖像,有助於電子商務中的產品展示。
- 評估生成式模型的重建能力,成為模型研究與改進的重要工具。
試用 VTOFF
TryOffDiff:專為 VTOFF 打造的生成模型
針對 VTOFF 的挑戰,TryOffDiff 模型應運而生。這是一種基於 Stable Diffusion 的生成架構,結合了 SigLIP 視覺條件技術,確保高還原度與細節保留。與傳統的虛擬試穿和姿態轉移技術相比,TryOffDiff 擁有以下優勢:
- 重建品質卓越:TryOffDiff 在處理服裝紋理、複雜細節以及準確的形狀表現上表現突出。
- 簡化處理流程:不需要繁瑣的前處理與後處理步驟,顯著提高效率。
- 改進的評估方法:傳統影像生成指標難以準確衡量重建品質,TryOffDiff 使用 DISTS(Deep Image Structure and Texture Similarity) 作為評估標準,提供更可靠的結果分析。
實驗成果與應用前景
TryOffDiff 的實驗基於改進版的 VITON-HD 資料集進行,結果顯示其重建表現超越現有基準方法。特別是在以下領域:
- 電子商務:幫助商家輕鬆生成標準化產品影像,提升顧客的購物體驗。
- 生成式模型評估:作為生成模型評估的重要參考,推動更高還原度的技術研究。
- 未來發展:激發針對高品質影像重建的新技術創新。
參考資料
by rainchu | 9 月 3, 2024 | AI, Stable Diffusion, 繪圖
Tensor.art 是一個 AI 的免費線上圖像生成平台,用穩定擴散模型(SD, Stable Diffusion)來生成圖片,用戶可以透過選擇不同的檢查點(模型)和細節調整元素(LURAs)來生成圖像,這些工具允許用戶調整生成圖像的細節和風格,Tensor.art 每天都提供用戶一定數量的免費信用額,一般使用者已經很夠用
技術方面
Tensor.art 提供多種圖像生成選項,包括基於文本的圖像生成和圖像到圖像的轉換。用戶可以通過上傳參考圖像和相應的文本提示來精確控制生成的圖像類型和風格。此外,平台還支持使用控制網格(Control Net)進一步細調圖像的外觀,以及高解析度修正工具來解決非標準長寬比圖像生成時可能出現的問題。
Tensor.art 的界面友善,適合各種經驗水平的用戶。新手可以利用預設的模型和設置快速開始,而經驗豐富的創作者則可以探索更多高級功能,如自定義種子、詳細程度調整和不同的取樣方法,這些功能提供了豐富的視覺特性和個性化選項。
參考資料
近期留言