by Rain Chu 6 月 14, 2026 | Agent , AI , Hermes , OpenClaw , Prompt
當我們開始用 AI 寫網站、做 Landing Page、產生前端介面時,常常會遇到一個問題
畫面看起來很快就完成了,但總覺得「哪裡怪怪的」。
按鈕很像、卡片很多、漸層很浮誇、字級沒有層次、留白不夠精準,甚至每個 AI 產生的網站都像是同一套模板改出來的。這種「可以用,但不高級」的設計感,就是許多 AI 前端作品容易落入的平庸陷阱。
而 Impeccable 官方網站 想解決的,正是這個問題。
什麼是 Impeccable?
Impeccable 是一套專為 AI Coding Agent 設計的前端設計輔助工具,它不是單純幫你產生漂亮畫面的 AI 設計工具,而是提供一套「設計語彙」與「設計指令」,讓你可以更精準地指揮 AI 改善網站畫面。
簡單說,Impeccable 讓 AI 不只是會寫程式,也更懂設計。
它可以協助 AI 理解網站中的層級、對比、留白、色彩、字體、動畫、產品脈絡與品牌調性,讓 AI 產生的前端畫面不再只是堆滿卡片、套上漸層、加一點陰影,而是更接近真正設計師會思考的介面。
你可以把 Impeccable 想像成:
一套給 AI 前端工程師使用的設計總監指令集。
為什麼 AI 做出來的網站常常很平庸?
現在很多人會用 AI 幫忙做網站,例如請 Claude Code、Cursor、Codex CLI 或 Gemini CLI 產生頁面。AI 很擅長快速完成版型,但如果沒有足夠清楚的設計方向,它很容易產生幾種常見問題:
每個區塊都用卡片包起來,看起來很模板化
喜歡使用過度常見的紫色漸層、玻璃擬態、發光陰影
字體大小與層級不夠精準,主標、副標、內文沒有明確節奏
留白太平均,缺乏視覺重點
按鈕、表單、導覽列看起來功能正確,但沒有品牌感
Landing Page 和後台 Dashboard 使用同一種設計邏輯
作品看起來像 AI 產物,而不是成熟產品
Impeccable 的價值就在於,它不是只叫 AI「設計得漂亮一點」,而是提供更具體的設計方向,例如讓畫面更有層次、更安靜、更大膽、更精煉、更符合產品情境。
Impeccable 的核心特色
1. 提供 AI 可理解的設計語言
Impeccable 的官方介紹中提到,它補上了 AI Agent 缺少的設計語彙,這代表你可以用更接近設計師的方式指揮 AI,例如改善排版、調整顏色、強化視覺層次、降低過度設計、整理產品脈絡。
這對不熟設計術語的人很有幫助,因為你不需要長篇大論解釋「我要更高級、更有質感、更像品牌網站」,而是可以透過 Impeccable 的指令,把設計意圖轉成 AI 比較能執行的動作。
2. 支援多種 AI Coding 工具
Impeccable 可以搭配多種主流 AI Coding 工具使用,例如 Cursor、Claude Code、GitHub Copilot、Gemini CLI、Codex CLI 等。
這代表它不是只服務單一平台,而是比較像一套可以帶進不同開發流程的設計輔助層。對於已經習慣用 AI 寫前端的開發者來說,Impeccable 可以直接加入現有工作流程,不需要重新學一套完整設計軟體。
3. 透過指令改善網站設計
Impeccable 提供多個設計指令,讓你可以針對不同設計任務下達命令。例如:
/impeccable init
/impeccable shape
/impeccable critique
/impeccable audit
/impeccable polish
/impeccable bolder
/impeccable quieter
/impeccable distill
這些指令的好處是,你可以更像在跟設計師溝通,而不是一直對 AI 說:「再漂亮一點」、「再高級一點」、「不要這麼普通」。
4. 幫你減少 AI 生成網站的套路感
很多 AI 產生的網站會有明顯套路,例如紫色漸層、大量圓角卡片、發光邊框、過度一致的版面節奏。Impeccable 內建反套路的設計檢查,可以幫助你找出這些容易讓網站看起來廉價、模板化或過度 AI 感的元素。
這對品牌網站、形象頁、SaaS Landing Page、產品頁、作品集網站尤其重要。因為這些頁面的重點不只是功能完成,而是要讓使用者在第一眼感覺到專業、信任與差異化。
5. 保留你的設計系統,不是硬套新風格
Impeccable 的另一個優點是,它不是粗暴地把你的網站改成另一種風格,而是會盡量尊重既有的設計系統,例如顏色、字體、元件、間距、按鈕樣式與品牌規則。
這對已經有產品雛形或既有網站的人很重要。你不一定想要整個重做,而是希望 AI 幫你把現有介面整理得更成熟、更一致、更像一個真正的產品。
Impeccable 適合誰使用?
Impeccable 特別適合以下幾種人:
1. 用 AI 寫前端的開發者
如果你常用 Cursor、Claude Code、Codex CLI、GitHub Copilot 來產生 React、Next.js、Astro、Tailwind CSS 或其他前端頁面,Impeccable 可以幫你補上 AI 在設計判斷上的不足。
2. 想快速做出高質感 Landing Page 的創業者
很多創業者會用 AI 快速做 MVP,但 Landing Page 如果太普通,會影響使用者信任感,Impeccable 可以幫助你把「能用的頁面」推進到「比較有品牌感的頁面」。
3. 會寫程式但不擅長設計的人
你可能知道功能怎麼做,但不知道為什麼畫面不夠好看。Impeccable 可以用指令化的方式協助你檢查排版、層級、色彩與互動細節。
4. 想降低 AI 生成感的網站製作者
如果你的網站看起來太像 AI 產物,Impeccable 可以幫你找出常見的 AI 設計套路,讓畫面更有辨識度。
如何安裝 Impeccable?
你可以到 GitHub 下載與查看 Impeccable 專案:
Impeccable GitHub 下載頁
官方建議可以在專案根目錄執行:
npx impeccable skills install
接著在你的 AI Coding 工具中執行:
如果之後要更新,可以執行:
npx impeccable skills update
官方網站也提供更多說明與範例:
Impeccable 官方網站
使用 Impeccable 的工作流程建議
如果你正在做一個網站或前端產品,可以用以下流程開始:
第一步,先用 AI 產生基本頁面結構。
第二步,執行 /impeccable init。
第三步,用 /impeccable shape 先整理畫面架構。
第四步,用 /impeccable critique 檢查設計問題。
第五步,用 /impeccable polish 做上線前修飾。
第六步,必要時使用 /impeccable audit。
對 WordPress 網站製作者有什麼幫助?
雖然 Impeccable 本身比較偏向 AI Coding Agent 與前端開發流程,但對 WordPress 網站製作者也很有參考價值。
如果你使用 WordPress 搭配自訂佈景主題、區塊編輯器、Elementor、Bricks、Breakdance 或自製前端元件,你可以先在本機或開發環境中,用 AI 建立前端區塊,再透過 Impeccable 改善設計品質。
例如:
首頁 Hero 區塊不夠有記憶點
服務介紹區塊太像模板
價格表太普通
Call to Action 不夠明確
部落格列表頁缺乏層次
後台管理介面太陽春
品牌網站缺乏高級感
這些都可以透過 Impeccable 的設計指令進行調整,再整合回 WordPress 佈景主題或頁面模板中。
結論:Impeccable 讓 AI 網站設計從「能用」走向「有質感」
AI 讓網站製作變快,但速度不代表品質。真正影響使用者感受的,往往是那些細節:字體層級、留白、對比、色彩、互動節奏、品牌一致性,以及畫面是否有明確的設計意圖。
Impeccable 的重點不是取代設計師,而是讓 AI 更容易理解設計師的語言,也讓開發者可以用更精準的方式指揮 AI 做出不平庸的網站。
如果你正在用 AI 製作網站,卻覺得畫面總是差一點質感,那麼 Impeccable 很值得加入你的前端工作流程。
官方網站:https://impeccable.style/
GitHub 下載:https://github.com/pbakaus/impeccable
by Rain Chu 6 月 13, 2026 | Agent , AI , GGUF , Hermes , OpenClaw
原本我在 Nvidia 都搭配 vLLM 啟動,這條路理論上可以發揮 NVFP4 權重的優勢,但在 DGX Spark 的 GB10 平台上,實際遇到 CUDA Kernel 與 Marlin repack 相容性問題。
最後我改採:
Hcompany/Holo-3.1-35B-A3B-GGUF 搭配 llama.cpp CUDA Build,成功啟動模型並提供 API 服務。
這篇文章記錄完整流程,也保留幾個重要的踩坑經驗。
環境
本次環境如下:
硬體:NVIDIA DGX SparkGPU:NVIDIA GB10系統:Ubuntu Linux模型儲存位置:/mnt/ai-models推論框架:llama.cpp模型格式:GGUF量化版本:Q4_K_M DGX Spark 使用統一記憶體架構,因此 CPU、GPU 與系統服務會共用記憶體。這點對 vLLM 與 llama.cpp 都很重要。
為什麼放棄 NVFP4 + vLLM
一開始使用 vLLM 載入:
Hcompany/Holo-3.1-35B-A3B-NVFP4 後,權重其實已經完整載入:
Loading safetensors checkpoint shards: 100% Completed | 3/3Loading weights took 142.78 seconds 但載入完成後,仍然在 Marlin FP4 重新整理階段失敗:
NotImplementedError:Could not run '_C::gptq_marlin_repack'with arguments from the 'CUDA' backend 這代表模型檔案本身沒有問題,真正卡住的是 vLLM 的 CUDA Extension 在 DGX Spark GB10 上沒有完整提供所需的 Marlin CUDA Operator。
如果只是想先把 Holo 3.1 跑起來,不一定要繼續投入時間處理 NVFP4 相容性。改用 GGUF + llama.cpp 是更快、更穩定的選擇。
移除 NVFP4 模型快取
vLLM 下載的 Hugging Face 模型通常會放在:
/mnt/ai-models/huggingface/hub/ 先確認路徑:
find /mnt/ai-models/huggingface \ -maxdepth 3 \ -type d \ -name 'models--Hcompany--Holo-3.1-35B-A3B-NVFP4' \ -print 確認容量:
du -sh \ /mnt/ai-models/huggingface/hub/models--Hcompany--Holo-3.1-35B-A3B-NVFP4 確認無誤後刪除:
rm -rf \ /mnt/ai-models/huggingface/hub/models--Hcompany--Holo-3.1-35B-A3B-NVFP4 1. 安裝編譯工具
sudo apt update
sudo apt install -y \ git \ build-essential \ cmake \ ninja-build \ libcurl4-openssl-dev \ pkg-config 2. 確認 CUDA Toolkit
export CUDA_HOME=/usr/local/cudaexport PATH="${CUDA_HOME}/bin:${PATH}"
export LD_LIBRARY_PATH="${CUDA_HOME}/lib64:${LD_LIBRARY_PATH:-}"
nvcc --versionnvidia-smi nvcc --version 必須能正常回傳 CUDA 版本。
3. Clone llama.cpp
mkdir -p /mnt/ai-models/srccd /mnt/ai-models/srcgit
clone https://github.com/ggml-org/llama.cpp.gitcd
llama.cpp 如果之前已經下載過:
cd /mnt/ai-models/src/llama.cpp
git fetch origingit switch master
git pull --ff-only origin master 4. 編譯 CUDA 版本
cd /mnt/ai-models/src/llama.cpp
rm -rf buildcmake -B build \ -DGGML_CUDA=ON \ -DCMAKE_BUILD_TYPE=Releasecmake --build build \ --config Release \ -j 4 \ --target llama-server llama-cli 確認:
./build/bin/llama-server --version
./build/bin/llama-cli --version 下載 Holo 3.1 GGUF 模型
建立模型目錄:
mkdir -p \ /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF 下載主模型、視覺投影模型與 Chat Template:
hf download \ Hcompany/Holo-3.1-35B-A3B-GGUF \ q4_k_m.gguf \ mmproj.f16.gguf \ chat_template.jinja \ --local-dir \ /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF 確認:
ls -lh \ /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF 應該看到:
q4_k_m.ggufmmproj.f16.ggufchat_template.jinja 單模型模式啟動
先用最簡單的單模型方式確認服務能運作:
cd /mnt/ai-models/src/llama.cpp
./build/bin/llama-server \ -m /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF/q4_k_m.gguf \ --mmproj /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF/mmproj.f16.gguf \ --jinja \ --host 0.0.0.0 \ --port 8080 \ -c 8192 \ -np 1 \ -ngl 999 參數說明:
--mmproj 指定視覺投影模型
--jinja 使用模型附帶的 Chat Template
-c 8192 Context Length
-np 1 同時處理 1 個請求
-ngl 999 儘可能將模型層放到 GPU 官方建議參數
llama-server \
--hf Hcompany/Holo-3.1-35B-A3B-GGUF \
--n-gpu-layers 999 \
--ctx-size 65536 \
--batch-size 16384 \
--ubatch-size 2048 \
--flash-attn 1 \
--cache-type-k q8_0 \
--cache-type-v q8_0 \
--image-min-tokens 1024 \
--ctx-checkpoints 8 \
--cache-ram 32768 \
--kv-unified \
--threads 16 測試文字 API
curl -s http://192.168.0.240:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Holo-3.1-35B-A3B-GGUF", "messages": [ { "role": "user", "content": "請使用繁體中文介紹你的 UI 畫面分析能力。" } ], "max_tokens": 256, "temperature": 0.2 }' | python3 -m json.tool 在這台 DGX Spark 上,實測文字生成速度約為:
測試圖片分析 API
curl -s http://127.0.0.1:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "q4_k_m.gguf", "messages": [ { "role": "user", "content": [ { "type": "text", "text": "Describe this image in one concise English sentence." }, { "type": "image_url", "image_url": { "url": "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg" } } ] } ], "thinking_budget_tokens": 64, "max_tokens": 1024, "temperature": 0.1 }' | python3 -m json.tool 已知問題:中文多模態輸出偶爾觸發解析錯誤
圖片推論本身可以成功,但在某些中文輸出中,llama-server 可能回傳:
Failed to parse input at pos ... 例如:
自由女神像、火炬、基座、城市天際線、高樓、水面、島嶼、樹木、旗�、船。 其中 � 是 UTF-8 無效字元替代符號。
實務上的處理方式:
1. 降低 temperature,例如 0.12. 限制輸出為簡短句子3. 提高 max_tokens,避免輸出被截斷4. Client 端遇到 500 時自動 Retry 一次5. 優先更新至最新版 llama.cpp Router Mode:支援多模型切換
確認單模型模式正常後,可以啟用 Router Mode:
cd /mnt/ai-models/src/llama.cpp
./build/bin/llama-server \ --models-dir /mnt/ai-models/llama-models \ --models-max 1 \ --models-autoload \ --jinja \ --host 0.0.0.0 \ --port 8080 \ -c 8192 \ -np 1 \ -ngl 999 啟動後會看到:
Loaded 1 local model presets from /mnt/ai-models/llama-modelsAvailable models (1) Holo-3.1-35B-A3B-GGUFstarting router server, no model will be loaded in this processrouter server is listening on http://0.0.0.0:8080 Router 會在 Client 第一次呼叫時才載入模型。
查看模型清單:
curl -s \ 'http://127.0.0.1:8080/models?reload=1' | \ python3 -m json.tool 指定模型:
curl -s http://127.0.0.1:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Holo-3.1-35B-A3B-GGUF", "messages": [ { "role": "user", "content": "請使用繁體中文簡短介紹你的功能。" } ], "max_tokens": 512, "temperature": 0.2 }' | python3 -m json.tool Router Mode 的記憶體策略
我使用:
意思是:
可以讓 Client 選擇多個模型但同一時間只保留一個模型在記憶體中 這很適合 DGX Spark。因為 Holo 35B、KV Cache、圖片 Token 與系統服務都會共用統一記憶體。
如果要同時提供 Holo 與另一個 Tool Calling 模型,建議:
Holo 35B:Context 8192 或 16384用途:UI 截圖與視覺分析較小的文字 Tool Calling 模型:Context 65536用途:Hermes Agent 預設模型 不同模型需要不同 Context Length 時,可使用 models.ini:
version = 1
[*]
jinja = true
n-gpu-layers = 999
parallel = 1
[Holo-3.1-35B-A3B-GGUF]
model = /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF/q4_k_m.gguf
mmproj = /mnt/ai-models/llama-models/Holo-3.1-35B-A3B-GGUF/mmproj.f16.gguf
ctx-size = 8192
[qwen-coder]
model = /mnt/ai-models/llama-models/qwen-coder-14b-q4_k_m.gguf
ctx-size = 65536 啟動:
./build/bin/llama-server \ --models-preset /mnt/ai-models/llama-models/models.ini \ --models-max 1 \ --models-autoload \ --host 0.0.0.0 \ --port 8080 讓 llama.cpp 開機就執行
一、確認執行檔路徑
先執行:
ls -lh /mnt/ai-models/src/llama.cpp/build/bin/llama-server 再確認模型目錄:
ls -lah /mnt/ai-models/llama-models 測試版本:
/mnt/ai-models/src/llama.cpp/build/bin/llama-server --version 如果這三個指令正常,就可以建立服務。
二、建立 systemd 服務
建立服務檔:
sudo nano /etc/systemd/system/llama-router.service 貼上:
[Unit]
Description=llama.cpp Router Server
Documentation=https://github.com/ggml-org/llama.cpp
After=network-online.target local-fs.target
Wants=network-online.target
RequiresMountsFor=/mnt/ai-models
[Service]
Type=simple
User=gwoyju
Group=gwoyju
WorkingDirectory=/mnt/ai-models/src/llama.cpp
Environment="LD_LIBRARY_PATH=/usr/local/cuda/lib64"
Environment="CUDA_HOME=/usr/local/cuda"
ExecStartPre=/usr/bin/test -x /mnt/ai-models/src/llama.cpp/build/bin/llama-server
ExecStartPre=/usr/bin/test -d /mnt/ai-models/llama-models
ExecStart=/mnt/ai-models/src/llama.cpp/build/bin/llama-server \
--models-dir /mnt/ai-models/llama-models \
--models-max 1 \
--models-autoload \
--jinja \
--host 0.0.0.0 \
--port 8080 \
-c 8192 \
-np 1 \
-ngl 999
Restart=on-failure
RestartSec=10
TimeoutStopSec=30
KillSignal=SIGTERM
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target 儲存後離開:
WantedBy=multi-user.target 讓服務可以隨一般多使用者開機流程啟動;Restart=on-failure 會在程式異常退出時重新啟動服務。
為什麼需要 RequiresMountsFor
你的模型與程式都放在:
如果外接 SSD 尚未掛載完成,直接啟動 llama-server 會失敗。
這一行:
RequiresMountsFor=/mnt/ai-models 會要求 systemd 先準備好該掛載點,再啟動 Router。
三、啟用開機自動執行
重新讀取服務設定:
sudo systemctl daemon-reload 設定開機自動啟動,並立即啟動:
sudo systemctl enable --now llama-router 查看服務狀態:
systemctl status llama-router --no-pager 正常情況應該看到:
以及:
router server is listening on http://0.0.0.0:8080 四、查看即時日誌
查看最近 100 行日誌:
journalctl -u llama-router -n 100 --no-pager 持續追蹤日誌:
journalctl -u llama-router -f 離開即時日誌:
五、測試 Router API
確認 Router 已啟動:
curl -s http://127.0.0.1:8080/health 查看模型清單:
curl -s \ 'http://127.0.0.1:8080/models?reload=1' | \ python3 -m json.tool 測試 Holo 3.1:
curl -s http://127.0.0.1:8080/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Holo-3.1-35B-A3B-GGUF", "messages": [ { "role": "user", "content": "請使用繁體中文簡短介紹你的功能。" } ], "max_tokens": 256, "temperature": 0.2 }' | python3 -m json.tool 第一次呼叫時會需要等待模型載入。後續請求會比較快。
六、常用管理指令
啟動服務
sudo systemctl start llama-router 停止服務
sudo systemctl stop llama-router 重新啟動
sudo systemctl restart llama-router 查看狀態
systemctl status llama-router --no-pager 取消開機自動啟動
sudo systemctl disable --now llama-router 七、確認開機後是否真的自動啟動
重新開機:
重新 SSH 登入後執行:
systemctl status llama-router --no-pager 確認 Port:
測試模型清單:
curl -s http://127.0.0.1:8080/models | \ python3 -m json.tool 八、改用 models.ini
準備讓不同模型有不同 Context Length:
Holo 35B:8192Hermes 預設 Tool Calling 模型:65536 這種情況建議不要在服務中使用:
而是改用:
假設設定檔位於:
/mnt/ai-models/llama-models/models.ini 服務中的 ExecStart 改成:
ExecStart=/mnt/ai-models/src/llama.cpp/build/bin/llama-server \
--models-preset /mnt/ai-models/llama-models/models.ini \
--models-max 1 \
--models-autoload \
--host 0.0.0.0 \
--port 8080 改完後重新載入設定:
sudo systemctl daemon-reload
sudo systemctl restart llama-router 查看日誌:
journalctl -u llama-router -f 九、避免 Ollama 開機後搶占記憶體
你之前遇過記憶體不足。如果目前 DGX Spark 主要改用 llama.cpp,建議停用 Ollama 的開機自動啟動:
sudo systemctl disable --now ollama 確認:
systemctl status ollama --no-pager 未來需要恢復:
sudo systemctl enable --now ollama 十、限制只允許內網連線
目前使用:
代表區域網路內其他裝置可以存取 API。Router Mode 目前仍屬於實驗性功能;llama.cpp 啟動日誌也提醒,不建議直接暴露在不受信任的網路環境。
假設區域網路是:
可以設定 UFW:
sudo ufw allow from 192.168.0.0/24 \ to any port 8080 proto tcp 查看規則:
不要直接把 Port 8080 暴露到公網。
建議你現在直接執行的版本
建立 /etc/systemd/system/llama-router.service 後,執行:
sudo systemctl daemon-reload
sudo systemctl enable --now llama-router
systemctl status llama-router --no-pagerjournalctl -u llama-router -n 50 --no-pager 這樣 DGX Spark 每次重新開機後,llama.cpp Router Server 就會自動啟動,並等待 Hermes Agent 或其他 Client 指定要載入的模型。
參考資料
https://huggingface.co/collections/Hcompany/holo31
https://build.nvidia.com/spark/llama-cpp/instructions
by Rain Chu 4 月 7, 2026 | Agent , AI , OpenClaw
在 2026 年,AI 不再只是聊天工具,而是「會幫你做事的代理人(AI Agent)」。
而現在,你可以擁有一個——完全屬於你自己的 AI 智能體(OpenClaw)
不再依賴 SaaS、不再擔心資料外流私有化 + 24 小時在線 + 可自動執行任務
更關鍵的是:用 Hostinger,一鍵部署只要約 $7/月
🤖 什麼是 OpenClaw?
OpenClaw 是一款開源 AI Agent(AI 智能代理)平台 ,可以讓 AI 不只是聊天,而是「幫你做事情」。
它可以:
自動回覆訊息(Telegram / WhatsApp / Slack)
幫你整理資料、寫報告
控制瀏覽器執行任務
呼叫 API、自動化流程
長期記憶與上下文管理
👉 本質上,它是:
「你的私人 AI 員工」
而且是——
⚡ 為什麼 OpenClaw 爆紅?
OpenClaw 在 2026 年爆紅的原因只有一個:
👉 它讓 AI 從「聊天」進化成「做事」
傳統 AI(ChatGPT):
OpenClaw:
例如:
幫你每天抓股價 → 傳 Telegram
自動回覆客戶訊息
幫你爬資料 → 整理成報告
自動操作網站(RPA + AI)
👉 這就是「AI Agent 時代」
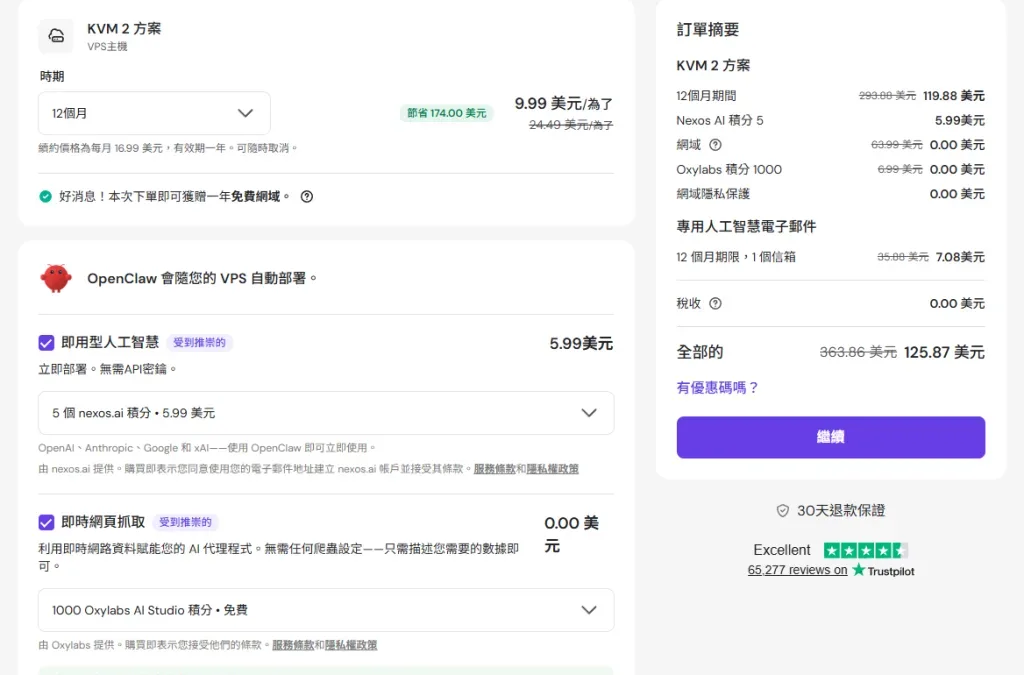
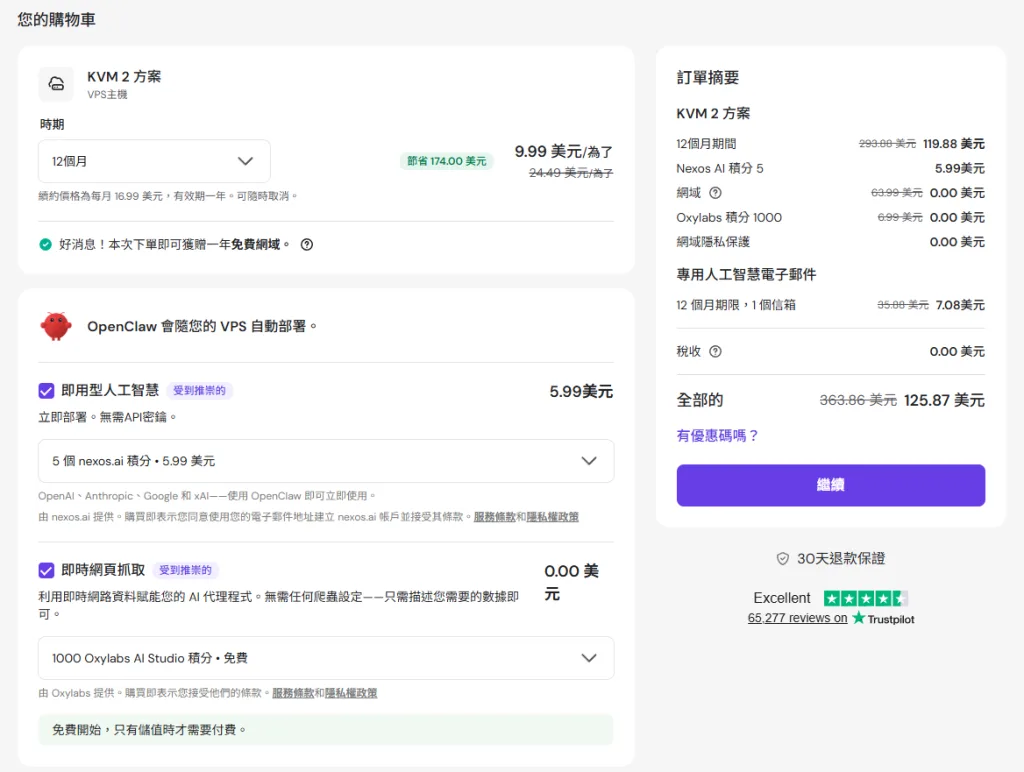
☁️ 為什麼用 Hostinger 部署 OpenClaw?
如果你自己部署 OpenClaw:
❌ 要裝 Docker
但用 Hostinger:
👉 全部幫你做好了
✅ Hostinger + OpenClaw 優勢
一鍵部署(不用 CLI)
預先配置 AI 環境
全球 VPS(穩定 24/7)
免費網域 + SSL
防火牆 + 備份
👉 官方直接提供 OpenClaw 模板
💰 成本有多低?
👉 最低只要約 $7/月
實際成本結構:
項目 價格 VPS 主機 約 $5~$10/月 AI API(選擇性) 視使用量 總成本 約 $7/月起
👉 比你請一個員工便宜 1000 倍 😅
甚至有資料指出:
👉 VPS 部署 OpenClaw 最低約 $5/月即可開始
🚀 60 秒部署流程(Hostinger)
超簡單流程:
Step 1️⃣
購買 VPS(選 KVM 2 即可)
Step 2️⃣
選擇 OpenClaw 模板
Step 3️⃣
點「Deploy」
Step 4️⃣
登入 Web UI
Step 5️⃣
接上 AI(OpenAI / Claude / Ollama)
👉 完成 🎉
🔐 私有 AI 的最大價值
為什麼大家開始瘋 OpenClaw?
1️⃣ 資料完全私有
不像 SaaS AI:
2️⃣ 完全控制
3️⃣ 可自動化一切
👉 這才是真正的「AI Agent」
⚠️ 但一定要注意
OpenClaw 很強,但也有風險:
AI 可以執行指令(高權限)
插件可能有安全問題
Token 洩漏 = 全部被控
👉 建議:
使用 VPS(不要跑在本機)
分離權限
使用防火牆 / Cloudflare
🧠 誰適合用?
非常適合你這類型:
DevOps / 架構師
WordPress / SaaS 維運
想做 AI Agent 商業化
想打造自動化系統
甚至可以做:
👉 「AI SaaS 創業」
🔮 未來趨勢(很重要)
未來會變成:
每個人都有一個 AI Agent
每家公司都有 AI 自動化流程
SaaS → AI Agent 化
👉 OpenClaw 就是這個入口
相關資訊
官方網站
https://www.hostinger.com/openclaw
by Rain Chu 4 月 1, 2026 | Agent , AI , OpenClaw
如果你想使用 OpenClaw 這類 AI Agent 工具,大多需要一台電腦或伺服器來執行。
但現在,你甚至可以用「一支舊 Android 手機」來打造一個 隨身遠端 AI 控制節點 !
👉 沒錯,舊手機不再只是備用機,而是可以變成:
這篇文章會帶你一步步完成:
📌 在 Android 手機上透過 Termux 安裝 OpenClaw,並實現遠端操控能力
🎯 為什麼要用「舊 Android 手機 + OpenClaw」?
📸 使用場景示意
4
✅ 核心優勢
1️⃣ 硬體要求低(舊手機就能跑)
不需要高效能 CPU / GPU
2GB~4GB RAM 就能運作
廢棄手機再利用
2️⃣ 可直接使用手機硬體能力
👉 不同於傳統 server,你可以用:
📷 相機(影像輸入)
🎤 麥克風(語音控制)
📶 行動網路(隨時在線)
3️⃣ 隨身攜帶的 AI 控制中心
SSH 控制 GCP / VM
呼叫 AI Agent workflow
當 DevOps 控制台
4️⃣ 比舊電腦更省電、更穩定
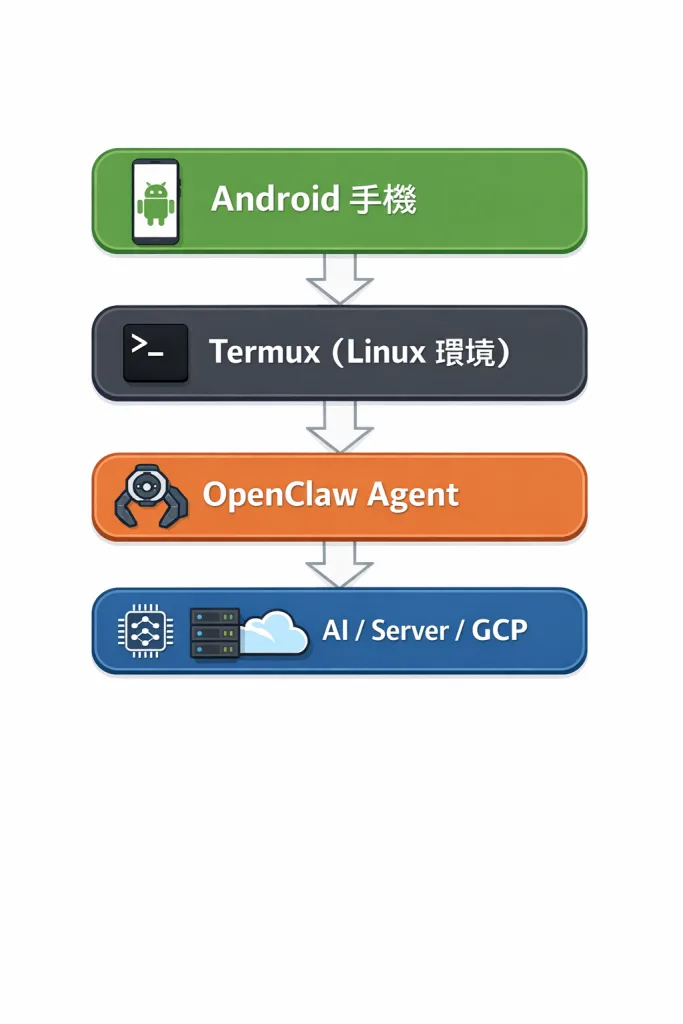
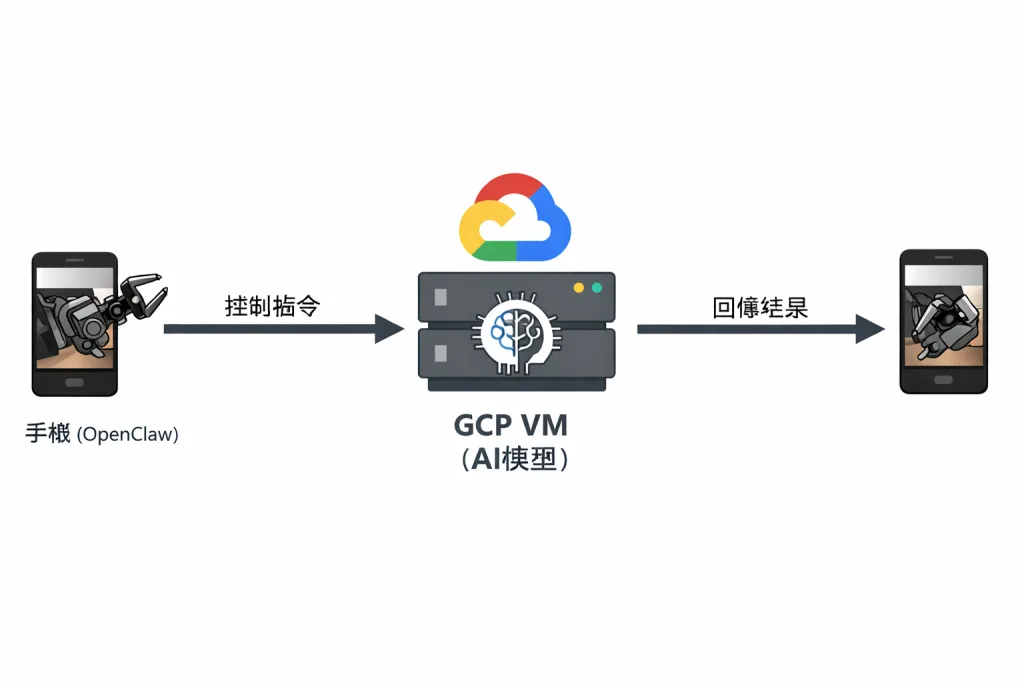
🧠 系統架構
Android 手機 -> Termux (Linux 環境) -> OpenClaw Agent -> Local AI / Server / GCP
👉 手機只是「控制層」,重運算仍在雲端
以下安裝方法 2 選 1 ,薪水推薦用 APK
🛠️ 安裝流程(APK)
🔗 官方下載
👉 來源:https://github.com/mithun50/openclaw-termux/releases/
📱 Step 1:下載 APK
在 Releases 頁面找:
👉 通常名稱會像:
openclaw-android.apk
下載到手機
🔐 Step 2:允許安裝未知來源
Android 需要開:
👉 設定 → 安全性
📲 Step 3:安裝 APK
直接點 APK:
👉 完成後會出現 App(OpenClaw)
⚙️ Step 4:準備 Backend(重點)
👉 APK 本身不會跑 AI
你需要一個 Gateway:
方法 A(最推薦)
👉 手機本機跑:
👉 流程:
APK → localhost:port
方法 B(更穩定)
👉 連 GCP:
APK → GCP VM(OpenClaw)
🔗 Step 5:連線 OpenClaw Gateway
打開 APK → 設定連線:
方式 1:自動配對
方式 2:手動輸入
Host: 你的IP
👉 官方說明支援:
manual host/port
token / TLS
🧪 Step 6:測試
成功後你可以:
🛠️ 安裝流程(完整實戰)
📱 Step 1:安裝 Termux
👉 使用:Termux
⚠️ 注意:
請從 F-Droid 安裝(不要用 Play 商店版本)
🔄 Step 2:更新環境
pkg update && pkg upgrade -y
📦 Step 3:安裝 OpenClaw
👉 官方 repo:openclaw-termux
git clone https://github.com/mithun50/openclaw-termux.git
⚙️ Step 4:啟動服務
bash start.sh
啟動後你會看到:
🌐 遠端操控方式
方法一:瀏覽器控制
👉 手機或電腦打開:
http://手機IP:PORT
方法二:API / AI Agent 控制
👉 你可以串:
LangChain
Local AI Agent
webhook
方法三:SSH 進手機
pkg install openssh
⚡ 進階玩法
🔥 架構升級
👉 也可以這樣玩:
手機(OpenClaw)-> 控制指令 -> GCP VM(AI模型)-> 回傳結果
🤖 實際應用
📊 自動抓資料 → 分析 → 回報
🧠 控制 Ollama AI 模型
🏠 智慧家居控制中心
📡 遠端監控節點
⚠️ 注意事項(實戰會踩雷)
❌ Android 限制
❌ Port 問題
👉 常見:
lsof -i :8080
❌ 效能限制
👉 不適合:
❌ 手機連不到內網
👉 用:
❌ 以為 APK = 完整系統
👉 錯
👉 APK 只是 UI
❌ Port 連不到
👉 要開:
ufw allow 3000
❌ Gateway 沒啟動
openclaw gateway
🧠 舊手機 vs 舊電腦
項目 舊手機 舊電腦 功耗 ⭐⭐⭐⭐ ⭐ 攜帶性 ⭐⭐⭐⭐ ⭐ 穩定性 ⭐⭐⭐ ⭐⭐ 擴充性 ⭐ ⭐⭐⭐⭐
👉 結論:
📌 手機適合「控制節點」,電腦適合「運算節點」
參考資訊
官方網站
https://github.com/mithun50/openclaw-termux
下載最新版本
https://github.com/mithun50/openclaw-termux/releases
VIDEO

近期留言