by Rain Chu 7 月 12, 2026 | 未分類
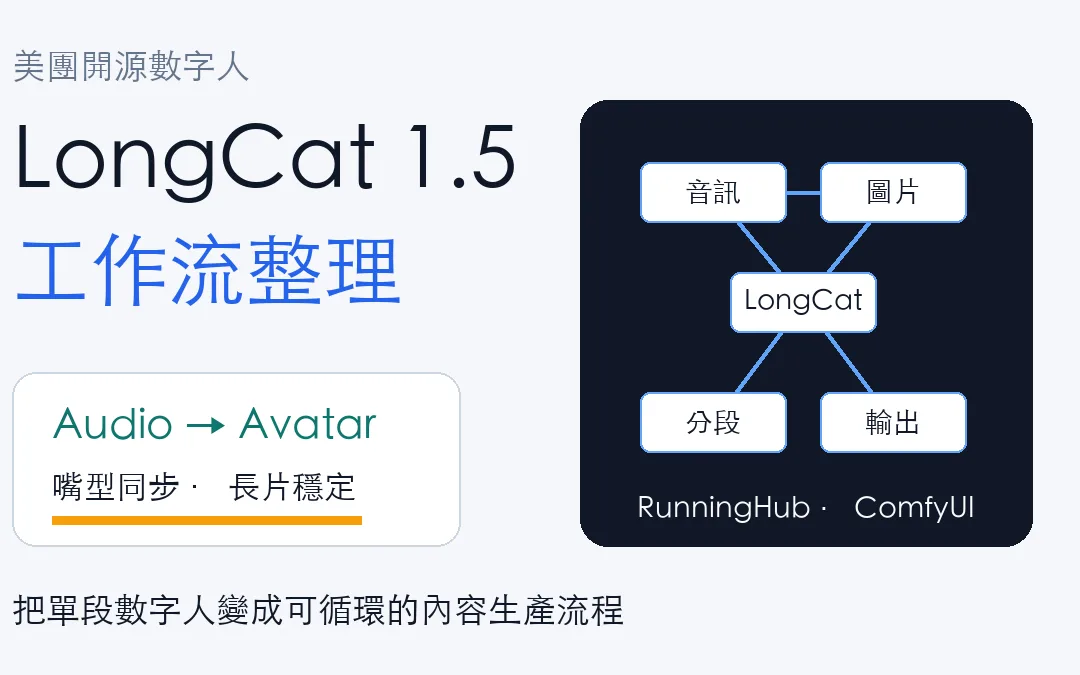
LongCat 1.5 最值得注意的地方是它把音訊驅動、人物一致性、長影片穩定性和 ComfyUI 工作流串在一起,讓數字人從單段 Demo 更接近可重複生產的內容流程。
美團開源的 LongCat-Video-Avatar 1.5 建立在 LongCat-Video 基礎模型之上,官方定位是 audio-driven human video generation,也就是用音訊、文字、圖片或既有影片去驅動人物生成。對內容創作者來說,關鍵不只是嘴型同步,而是能不能穩定做出比較長的數字人片段。
LongCat 1.5 解決的是什麼問題
過去很多數字人工具看起來很驚艷,但實際用在長片段時會遇到幾個老問題:嘴型不穩、人物身份漂移、動作重複、背景抖動、分段接不上,LongCat 1.5 的官方 model card 強調幾個方向:用 Whisper-Large 取代 Wav2Vec2 作為音訊編碼器,改善嘴型與語音動態,並強化長影片生成時的身份一致性和時間穩定性。
它支援的任務也不只一種,AT2V 是 Audio-Text-to-Video,適合用音訊和文字描述生成片段,ATI2V 是 Audio-Text-Image-to-Video,可以用參考圖片維持角色形象,Video Continuation 則比較接近延續既有影片,讓後續動作和語音繼續往下生成。
為什麼 RunningHub 工作流有用
LongCat 1.5 本身是模型,真正要變成創作者可用的工具,還需要工作流。這也是 RunningHub 和 ComfyUI 的價值所在。RunningHub 可以把複雜節點封裝成比較容易執行的流程,讓使用者不一定要在本機把所有依賴、模型、節點和顯卡環境都裝好。
如果你還不熟 RunningHub,可以先看我之前整理的 RunningHub 是什麼?把 ComfyUI 工作流變成 AI 內容生產平台 ,這次 LongCat 1.5 的重點就是把「單段生成」改成「循環工作流」,讓多段音訊和多段片段可以自動往下跑,不必每 4 秒就手動複製節點、改連線、重新拼接。
循環工作流的核心概念
實作數字人長片段時,最麻煩的往往不是單次生成,而是分段,假設每段產生 4 秒,20 秒就需要 5 段,30 秒就需要更多段。如果每一段都手動複製節點和連線,工作流會變得又長又難維護。
比較合理的做法是讓工作流自動按時間切段,再把每段送進 LongCat 1.5 生成。這裡有幾個重要參數:
音訊起始時間:決定從第幾秒開始讀音訊。
生成時長:決定每段處理幾秒,實務上可以略大一點,避免音訊尾端被切掉。
幀率:要和模型採樣規則配合。
尺寸:工作流裡常見長邊 1024,也可以提高,但成本會上升。
參考圖和 prompt:決定人物外觀、場景、動作與一致性。
其中「4n+1」這個規則很重要。如果秒數乘上幀率後不是符合模型要求的幀數,採樣器可能直接報錯,好的工作流會用數學節點自動修正幀數,避免使用者每次手算。
設備需求怎麼看
很多人第一個問題會是:本機能不能跑?答案要拆開看,官方安裝方式需要 Python 3.10、CUDA 版 PyTorch、FlashAttention、ffmpeg、librosa 和模型權重。這代表如果要本地完整跑起來,最好有 NVIDIA GPU 和足夠顯存,不然體驗會很痛苦。
RunningHub 的思路則是把算力放到雲端,說明欄提到可以在 RTX 4090 上運行,這對一般創作者比較友好,因為你不用先處理 CUDA、依賴衝突和顯存不足。缺點是需要依平台計費,還要注意素材隱私和商用內容的授權風險。
如果你對本地 AI 影片工作流有興趣,可以對照 OpenMontage 本地部署實測 。如果你的重點是語音和角色互動,也可以延伸看 Hugging Face speech-to-speech 本地即時語音 Agent ,思路都會回到同一件事:模型、音訊、工作流和算力要一起設計。
提示詞要寫得比想像中更細
LongCat 1.5 官方也提醒,長而具體的 prompt 通常比短句更穩。不要只寫「一位女生在說話」。更好的寫法是把人物外觀、動作、服裝、表情、場景都寫清楚,例如:一位長黑髮女性,穿白色襯衫,坐在明亮咖啡館裡,微笑並自然說話。
如果要做商用級數字人,我會把 prompt 拆成四層:
角色:年齡、髮型、服裝、表情、姿態。
場景:室內或戶外、光線、背景、鏡頭距離。
動作:說話、微笑、點頭、手勢、是否走路。
限制:不要誇張表情、不要手部變形、不要背景閃爍、不要換臉。
如果你還需要語音來源,可以搭配 Qwen3-TTS 這類音色設計工具 ,先把聲音品質穩住,再進入數字人生成。音訊不好,嘴型同步再強也很難救。
LongCat 1.5 適合誰
使用者 適合程度 原因 短影音創作者 高 可以把固定角色、音訊和場景變成批量內容。 電商和品牌團隊 高 可做商品介紹、導購、活動宣傳和多語版本。 本機 AI 玩家 中 模型開源,但完整環境和顯卡需求不低。 只想快速試效果的人 高 用 RunningHub 工作流比本地安裝更快。 企業敏感資料場景 中 要評估素材隱私、雲端上傳和合規問題。
如果只是做一張照片講話,過去已經有很多工具可以完成,例如我之前整理過的 Hallo AI 數字人 ,LongCat 1.5 更值得看的地方,是它開始處理更長、更穩、更可工作流化的數字人生成。
注意事項
第一,雲端工作流很方便,但素材上傳前要確認隱私。客戶聲音、真人肖像、商業腳本,都不應該隨便丟到不熟的平台裡。
第二,數字人看起來自然,不代表可直接商用。要確認聲音、人物肖像、參考圖、背景素材和平台條款,尤其是用真人形象時更要小心。
第三,循環工作流能提高效率,但也會放大錯誤。如果第一段人物已經歪掉,後面自動跑再多段也只是把錯誤放大。比較穩的做法是先做 4 到 8 秒測試,確認嘴型、動作和人物一致性,再放大到長片段。
最後
LongCat 1.5 代表數字人工作流正在從單點工具走向內容生產線。模型本身強調嘴型、長影片穩定和身份一致性,RunningHub 工作流則把操作門檻往下壓。對創作者來說,現在最重要的能力不是只會按生成,而是懂得設計音訊、角色、分段、幀率和工作流。
如果你想快速驗證,先用 RunningHub 工作流跑一段短音訊。如果要做可控的長片或商用內容,再回頭研究 ComfyUI 節點、官方 Hugging Face 權重和本地部署成本。這樣比較不會一開始就被環境和顯卡需求卡住。
FAQ
LongCat 1.5 是什麼?
LongCat 1.5 是美團開源的音訊驅動數字人模型,支援用音訊、文字、圖片或既有影片生成數字人片段。
LongCat 1.5 可以本地部署嗎?
可以,但官方安裝需要 CUDA 版 PyTorch、FlashAttention、ffmpeg、librosa 和模型權重,建議有 NVIDIA GPU 再嘗試。
為什麼幀率要注意 4n+1?
部分採樣流程要求輸入幀數符合特定規則,如果秒數乘幀率後不符合,採樣器可能報錯。工作流通常會用數學節點自動修正。
by Rain Chu 7 月 12, 2026 | AI , 圖型處理
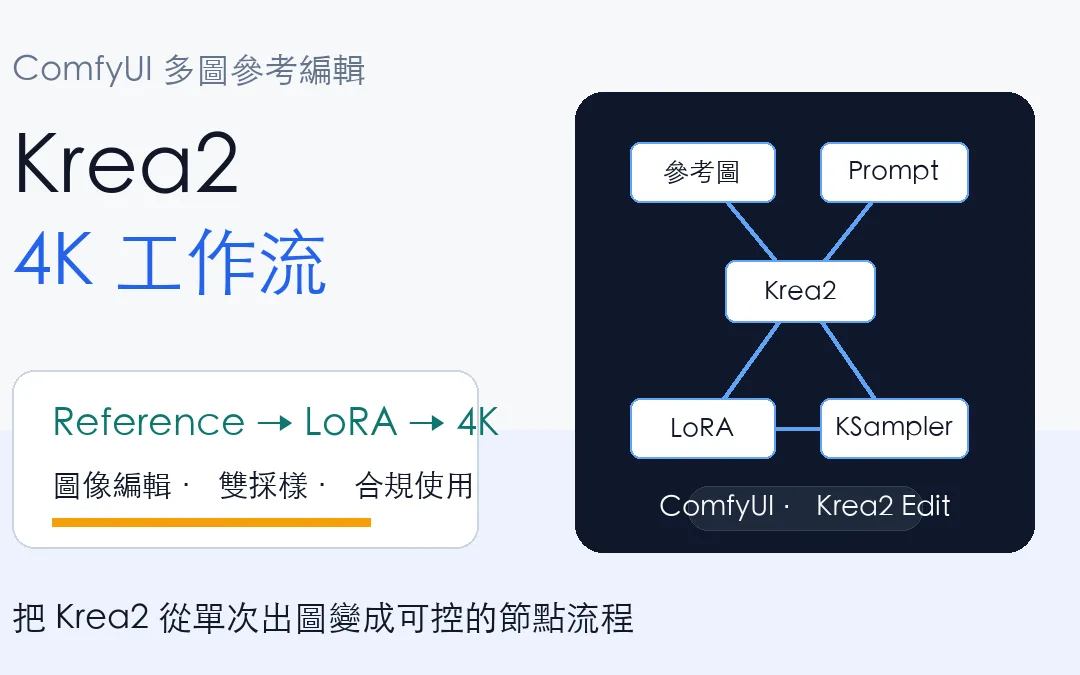
Krea2 開始變得有趣,不只是因為它能做漂亮的圖,而是因為它正在被接進 ComfyUI 的節點工作流。當圖像編輯、多圖參考、LoRA、KSampler 和 4K 出圖放在同一張節點圖裡,Krea2 就不只是單次生成工具,而是可以被拆解、調參、複用的內容生產流程。
我會把這次重點整理成三件事。
第一,Krea2 edit LoRA 的 ComfyUI 節點怎麼理解。
第二,私模與社群模型要怎麼分開看。
第三,4K 工作流不是單純放大,而是先控制訓練尺寸,再用 latent 放大與第二次採樣補細節。
Krea2 圖像編輯的真正重點
Krea2 圖像編輯最吸引人的地方,是它把「參考圖」和「提示詞」放到同一個生成條件裡 ,這比單純丟一張圖做 img2img 更細,因為參考圖可以被視覺編碼器理解,再和 prompt 一起影響模型輸出。
ComfyUI-Krea2-Ostris-Edit 這個節點包就是關鍵之一,它的 README 說明,這套節點是為了執行用 AI Toolkit 訓練的 Krea 2 edit LoRA,安裝方式是放到 ComfyUI 的 `custom_nodes` 目錄,重新啟動後節點會出現在 `ostris/krea2` 類別。
它不是模型本體,而是讓 ComfyUI 能正確吃進 Krea2 edit LoRA 的橋,這點很重要,因為很多人看到節點就以為模型已經包含在裡面,實際上模型、LoRA、節點和工作流是四個不同層次。
多圖參考不是把圖片塞進去就好
Krea2 Ostris Edit 的文字編碼節點可以接受 prompt,也可以接受 `image1` 到 `image3` 這類參考圖。GitHub 說明裡提到,參考圖會透過 Krea2 的 Qwen3-VL text encoder 編碼,並用 Krea 的 conditioning template 加入 `Picture N:` 這類視覺 placeholder。
換句話說,多圖參考的重點不是「圖片有沒有接上節點」,而是參考圖有沒有被正確轉成 conditioning。若接了 VAE,參考圖也會被 VAE 編碼成 reference latents,再交給 model patch 節點使用。這也是為什麼工作流裡會看到 Text Encode、Model Patch、VAE、KSampler 連在一起。
Text Encode Krea 2 Ostris Edit 負責把 prompt 與參考圖一起編碼
Krea 2 Ostris Edit Model Patch 讓模型真的消化 reference latents
如果文字編碼 checkpoint 沒有 Qwen3-VL vision weights,參考圖就無法被正確編碼
如果 conditioning 沒有 reference latents,patch 後的模型會像原本的 Krea2 一樣運作
這也是我會把它歸類為進階 ComfyUI 工作流,而不是單純的模型推薦,若你對節點式 AI 生產平台還不熟,可以先看我整理過的 RunningHub 與 ComfyUI 工作流平台 ,會比較容易理解為什麼同一個模型放進工作流後,價值會完全不一樣。
私模、社群模型與合規使用要分清楚
這次素材裡有一個很值得注意的提醒:老白訓練的 Krea2 亞洲女性私模不是開源模型,它是投入大量訓練步數與算力成本做出來的商業模型,這類模型能不能商用、能不能轉售、能不能放到平台上提供他人使用,都要看授權條款。
所以我會把工作流和模型分成兩條線來看。工作流可以學,節點可以研究,參數邏輯也值得整理,但私模本身不是「看到連結就能自由拿來用」的資源。若只是想理解 Krea2 工作流,可以先從社群模型、公開節點和 RunningHub 上的示範流程開始。
另外,Krea2 的圖像編輯能力很容易碰到肖像、換裝、仿真與身份一致性問題。越是接近真人或商業素材,越需要確認素材來源、肖像權、授權和平台規範。技術可以做到,不代表每個場景都適合做。
4K 工作流的核心不是暴力放大
這套 4K 思路有一個實用點:先用接近訓練尺寸的長邊出圖,再在 latent 空間放大,最後用第二次採樣補細節。以這次整理的參數來看,長邊 1536 是一個被反覆提到的基準,因為後面還要做倍率放大。
第一個 KSampler 會用比較高的 denoise,例如 `denoise 1`,步數可以抓 8 到 10 步。這一步不是最後成品,而是建立整體構圖與質感。接著在 latent 空間放大,例如 2.5 倍,再進入第二個 KSampler。第二次採樣通常要更保守,避免把第一輪已經穩定的畫面重新打亂。
階段 用途 重點 第一輪採樣 建立構圖與主要質感 可用較高 denoise,步數約 8 到 10 latent 放大 把畫面放到更高解析度 倍率要配合原始長邊與顯存 第二輪採樣 補細節與穩定質感 採樣器與 denoise 要保守,避免重新洗圖
這個思路和傳統 Stable Diffusion 的高解析修復很像,但放到 Krea2 和 LoRA 組合後,更需要注意模型本身的訓練尺寸與美學方向。你如果常玩本機模型部署,也可以對照我之前寫的 ComfyUI 本機部署 AI 繪圖模型 ,兩者都在處理「模型能力」和「工作流控制」之間的平衡。
LoRA 權重不是越高越好
這次工作流裡多次出現 LoRA 疊加。單獨使用某個風格 LoRA 時,權重可以先從 0.8 附近測。若兩個 LoRA 一起用,總權重抓在 0.9 到 1.0 比較容易控制,例如一個 0.5,另一個 0.4。
這不是死規則,而是避免模型過度偏移的起點。Krea2 本身的細節與光影已經很強,LoRA 的目的應該是加強風格或概念,而不是把底模原本的結構感整個蓋掉。若出現臉部變形、姿勢不穩、材質變髒,第一個要檢查的通常不是 prompt,而是 LoRA 權重和第二輪採樣是否太激進。
Krea2 工作流適合誰
我覺得 Krea2 這類流程比較適合三種人。第一種是已經熟悉 ComfyUI,想要把參考圖、LoRA、放大與後處理串成固定模板的人。第二種是需要穩定產出社群圖像、封面、人像素材或商品視覺的人。第三種是想研究圖像編輯模型訓練方向的人,因為 Krea2 edit LoRA 的節點設計能看出參考圖 conditioning 的實作脈絡。
如果只是偶爾修圖,可能用線上工具會比較快。如果要長期做工作流、批量產圖、測 LoRA 權重,ComfyUI 仍然比較有彈性。也可以用 AIX Studio 這類 AI 繪圖平台 做比較,看看自己需要的是封裝好的產品,還是可拆解的節點流程。
實作前可以先檢查這幾件事
確認 Krea2 模型與 LoRA 來源,尤其是授權和商用限制
安裝 ComfyUI-Krea2-Ostris-Edit 節點後再重啟 ComfyUI
確認 text encoder checkpoint 含有 Qwen3-VL vision weights
多圖參考要檢查 VAE reference latent 是否真的接進 conditioning
第一輪採樣先穩構圖,第二輪採樣再補細節
LoRA 疊加時總權重不要一開始就拉太高
真人、換裝、仿真、商業圖像要先確認合規與授權
若你想直接在線上試工作流,可以看 RunningHub 的 Krea2 Realism Engineer v2 工作流頁面。若人在海外,RunningHub 也有海外站。這類平台的好處是不用先處理本地顯卡和節點衝突,但缺點是工作流可控性和資料隱私要自己評估。
結論
Krea2 圖像編輯真正值得看的,不只是單張效果圖,而是它如何被拆成 ComfyUI 裡的節點、conditioning、model patch、LoRA 權重和雙採樣流程。這讓它從「好看的模型」變成「可調整的生產系統」。
我的建議是先從公開節點和可取得的工作流開始,把參考圖進 conditioning 的路徑搞懂,再去看私模或商業模型是否值得投入。尤其是人像與商業素材,合規使用要放在技術嘗試前面。能生成不是終點,能穩定、可控、可授權地生成,才是 Krea2 工作流真正能落地的地方。
延伸資源
by Rain Chu 7 月 12, 2026 | AI , 影片製作
Seedream 5.0 Pro 這次最值得注意的地方,不是「又一個更會畫圖的模型」而已。真正的主線,是它把圖像生成、圖像編輯、素材可信任度和後續圖生影片流程接在一起。換句話說,它是在替 Seedance 2.0 這類影像生成流程準備更乾淨、更可控的前置素材。
如果只把它拿來和 GPT Image 或其他圖像模型比美感,會漏掉一半重點,Seedream 5.0 Pro 的定位更像是「可控素材製作工具」,它適合處理商品圖、人物一致性、材質替換、局部修改與多圖參考,也適合被接進 RunningHub 這類 ComfyUI 工作流平台 裡,變成可重複使用的內容流程。
三個核心方向
Seedream 5.0 Pro 的核心方向可以拆成三個
第一是讓圖像編輯更可控,而不是只靠模型自由發揮。
第二是用更模組化的方式提供相對低成本的生成與編輯能力。
第三是讓圖片到影片的路徑更順,特別是和 Seedance 後續版本的銜接。
這三點合起來看,會發現它不是單點功能升級,而是完整內容管線的鋪路,先用 Seedream 5.0 Pro 生成或修好圖片,再把圖片丟進圖生影片模型,理論上可以減少人臉、素材可信任度和審核卡關的問題。這也是為什麼它比一般文生圖模型更值得追。
可控編輯比自由生成更重要
這次最明顯的提升,是局部編輯的可控性。舉例來說,把圖片中的某個玩偶換成另一個物件,或用簡單標記指定要改的區域,Seedream 5.0 Pro 能比較自然地把新物件融入原場景。光影、材質、邊緣融合和背景一致性,是它比較有競爭力的地方。
這對電商圖片很重要,商品圖最怕的是物件看起來像後貼上去,或材質和場景不一致,Seedream 5.0 Pro 比較像是在理解「這個材質應該如何存在於場景裡」,而不是只是把 prompt 文字翻成圖片。
但它也不是萬能,越抽象的概念、越複雜的排版設計、越需要策略性構圖的封面設計,它和 GPT Image 這類模型還是有差距,我的判斷是,Seedream 5.0 Pro 更像 Nano Banana 類型的競爭者,強在可控編輯與素材處理,GPT Image 則更強在理解任務、設計整體版面和處理抽象需求。
材質還原是電商場景的亮點
Seedream 5.0 Pro 對材質的理解很值得注意。測試裡包含服裝布料、球衣、禮服、玩偶、沙發和花材替換,整體看起來比較能保持原本場景的光線與質感。尤其是給定材質參考圖和顏色參考圖時,它能把要求融合到新圖片裡。
這代表它不只是能「換一個東西」,而是能更接近「照著品牌材質和色彩規範換一個東西」。對商品主圖、社群宣傳圖、服裝搭配、場景圖來說,這會比單純漂亮更實用。
用途 Seedream 5.0 Pro 的優勢 還要注意 商品圖修圖 材質融合與局部替換自然 需要確認商品真實性與授權 人物一致性 臉、服裝和場景一致性提高 肖像權與真人仿真風險要先處理 多圖參考 可以吸收材質、顏色與風格參考 參考圖太多時仍可能混亂 設計排版 基礎美感變好 抽象概念和版面設計仍不是最強項
為什麼它其實是在幫 Seedance 2.0 鋪路
最有意思的是圖生影片這條線。過去很多 AI 影片工作流的問題,不是影片模型完全不行,而是前置圖片太容易出現臉不穩、素材不被信任、提示詞被擋、或圖片本身和影片模型不匹配。Seedream 5.0 Pro 若能產生更容易被後續流程接受的素材,整個圖生影片鏈條就會順很多。
這也是為什麼我會把它和 AI 動畫分鏡工具 、OpenMontage 這類本地 AI 影片工作流 放在同一條線上看。未來的內容生產不是單一模型決勝負,而是「圖像模型負責前置素材」「影片模型負責運動」「工作流平台負責串接」。
Seedance 2.0 或後續版本真正要跑得順,前面就需要一個能把人物、商品、材質和場景先整理好的工具。Seedream 5.0 Pro 在這裡扮演的角色,比單純文生圖更關鍵。
目前限制也很明顯
Seedream 5.0 Pro 已經有幾個強項,但限制也不能忽略。抽象概念測試仍不穩,例如要求產出大量不同姿勢或不同表情的頭像格,有時會出現重複動作、理解偏差或排列不如預期。這代表它在「規則化輸出」和「多元素差異控制」上還沒有完全成熟。
設計排版也仍然不是它最強的地方。如果要做品牌封面、資訊圖、海報版面,GPT Image 類模型可能仍然更聰明。Seedream 5.0 Pro 比較適合先做圖像素材,再交給其他設計流程處理版面。
另外還有兩個功能值得觀望。第一是 4K 原生版本。第二是分層能力。分層對設計工作很關鍵,因為它會影響後續能不能像 Photoshop 一樣調整物件、文字、背景與光影。若分層真的穩定開放,Seedream 5.0 Pro 的定位會從圖像模型更靠近設計工具。
RunningHub 工作流怎麼用
說明欄提供了幾個 RunningHub 工作流,包含 Seedream 5.0 Pro 文生圖、Seedream 5.0 Pro 圖像編輯,以及全能圖片 G2 圖像編輯。對不想先處理本地部署的人來說,這種方式最快。你可以先用線上工作流測它是否符合自己的內容需求,再決定要不要進一步研究本地化或自動化。
如果你偏向本地工具鏈,也可以把這次的思路和 ComfyUI 本機部署 AI 繪圖模型 對照。線上工作流省部署,本機部署則更可控。兩者沒有誰一定比較好,差別在你要速度、隱私、成本,還是可調參能力。
我的使用判斷
Seedream 5.0 Pro 值得試,尤其是你有商品圖、人物素材、服裝材質、社群圖片和圖生影片需求。它不是最會做排版的模型,也不是最會理解抽象創意的模型,但它在「把現有素材改得更可用」這件事上很有價值。
我會把它放在 AI 內容生產流程的前段。先用它把人物、商品、材質、色彩和構圖穩住,再接到影片模型或設計工具。這種位置比單純追求一張漂亮圖更實際,也更接近未來 AI 工作流的方向。
至於要不要立刻大量投入,我會等兩件事。第一,4K 原生版本穩不穩。第二,分層功能是不是真的能用在設計流程裡。如果這兩個功能落地,它就不只是又一個圖像模型,而會更像一個能接進商業工作流的圖像基礎工具。
by Rain Chu 7 月 11, 2026 | AI , 圖型處理 , 影片製作
RunningHub 最值得看的地方,不是它又做了一個線上 AI 繪圖平台,而是它把 ComfyUI 工作流、AI 應用、模型 API、工作流 API 和內容模板包成一個可營運的創作平台。對內容團隊來說,這比較像是把原本散在本機、模型網站、工作流社群和 API 文件裡的能力,整理成同一個生產入口。
如果你之前已經在玩 本機 ComfyUI 與開源繪圖模型 ,RunningHub 可以看成另一條路。它不是要求每個人都先理解節點、環境、顯卡和模型路徑,而是把工作流託管在雲端,讓創作、分享、調用和商業化更接近一般工具的使用方式。
RunningHub 是什麼
RunningHub 官方把自己定位成原生 AI 智能體驅動的全能內容創作平台,支援 ComfyUI 工作流、無限畫布、AI 應用和模型 API 調用。這句話拆開看,其實代表三層產品。
第一層是創作入口,包含快捷創作、無限畫布、rhTV、RHSTORY、VibeX 和各種模板。
第二層是工作流市場,讓創作者基於 ComfyUI 做出可複用的流程,並提供給其他人直接使用。
第三層是 API 與開發者工具,把模型、AI 應用和工作流變成可以被產品或內部系統調用的服務。
這三層合在一起,RunningHub 的野心就比較清楚了,它不是只想做一個 ComfyUI 雲端版,而是想做 AI 內容生產的基礎平台。創作者可以在上面做模板,團隊可以用模板產出素材,開發者可以透過 API 把同一套能力接到自己的產品裡。
和本機 ComfyUI 最大差別
本機 ComfyUI 的好處是自由度高,模型和節點都能自己控制,缺點也很明顯,安裝、模型管理、節點衝突、顯卡限制和工作流維護都會吃掉大量時間。RunningHub 則把這些麻煩轉成雲端服務與平台規則。
面向 本機 ComfyUI RunningHub 環境管理 自己安裝 Python、節點、模型和驅動 平台託管工作流與模型能力 硬體成本 需要自己的 GPU 或雲端機器 按平台資源與調用方式使用 分享方式 通常分享 JSON、模型清單與安裝說明 可直接變成模板、AI 應用或 API 適合對象 技術玩家、研究者、重度創作者 內容團隊、電商、短劇、行銷、開發者 商業化路徑 需要自己包服務或教學 平台內有模板、應用與創作者激勵
這和 Liblib 這類中國 AI 創作平台 很像,都是把模型能力、創作者生態與素材生產流程放進平台。差別在於 RunningHub 特別強調 ComfyUI 工作流、AI 應用和 API 的連動,對想把流程產品化的人更有吸引力。
工作流才是核心資產
RunningHub 的 ComfyUI 頁面不是只展示模型,而是展示大量工作流。像商品圖、角色設計、短劇分鏡、動作模仿、去水印、高清修復、影片超分、圖生影片等,都不是單一模型能解決的問題,而是由多個節點和步驟組成的流程。
這一點很重要。AI 內容創作正在從 prompt 時代走向 workflow 時代。單次生成可以靠運氣,多次穩定產出就需要流程。誰能把流程沉澱成模板、應用和 API,誰就更接近可複製的生產力。
這也能和 OpenMontage 本地影片工作流 放在一起看。一邊是本地自架、可控性更高,另一邊是平台化、上手更快。真正要選哪一邊,不是看哪個比較酷,而是看團隊需要的是控制權,還是交付速度。
API 讓 RunningHub 不只是一個網站
RunningHub 的 API 頁面有一個關鍵說法,單一接口可以直連 400 多個主流大模型。它也把能力拆成模型 API、AI 應用 API 和工作流 API。這代表開發者不一定要讓使用者進 RunningHub 網站操作,也可以把平台能力接進自己的產品。
官方列出的生產環境重點包括全模態聚合、工作流託管、彈性按需計費與企業級安全。這幾個詞不是行銷話術而已。對公司來說,真正麻煩的往往不是模型能不能跑,而是能不能穩定調用、能不能控權限、能不能算成本、能不能把工作流變成內部服務。
RunningHub 也提供 RH_CLI、RH_Skills、ComfyUI 插件與 AI Developer Kit。這些工具的意義是降低接入門檻。創作者可以從平台模板開始,工程團隊則可以把流程變成自動化服務。這和 AI 代理走向工作平台 是同一個方向,重點不只是模型,而是把模型放進可用的工作系統。
哪些人最適合用 RunningHub
我會把 RunningHub 的使用者分成四類。
電商與品牌團隊,需要大量商品圖、短影片、模特圖、場景圖和廣告素材。
短劇與內容團隊,需要分鏡、角色、場景、動作模仿和影像增強。
ComfyUI 創作者,想把自己的工作流變成模板、應用或可被調用的服務。
開發者與企業團隊,想用 API 把模型和工作流接進既有系統。
如果只是偶爾玩圖,本機工具或單一模型網站就夠了。如果是每天要產內容、測素材、上架商品、做短劇或替客戶交付,RunningHub 這種平台化工具才會開始有價值。因為它解決的不是單張圖,而是內容生產流程。
我會怎麼開始測
第一步不要先研究所有功能,而是挑一個真實任務。例如電商商品圖、短劇分鏡、社群廣告短片或角色一致性測試。用官方模板跑出第一版,記錄效果、成本和可修改程度。
第二步才是比較工作流。看同一個任務能不能換模型、改節點、調提示詞、保留角色一致性,或直接變成 AI 應用。這一步能判斷 RunningHub 是臨時工具,還是能進入你的固定流程。
第三步看 API。如果你要把內容生產接到網站、內部後台、自動化任務或客戶服務流程,工作流 API 才是長期價值。這時候就要評估調用成本、回傳格式、權限控管和失敗重試。
我的結論
RunningHub 的定位很清楚,它想把 ComfyUI 從高手工具變成內容生產平台,這件事不只是降低門檻,也是在改變 AI 創作的價值重心。過去大家比的是誰會寫 prompt,現在會慢慢變成誰能設計穩定工作流,誰能把工作流包成應用,誰能把應用接成 API。
如果你只想偶爾生成圖片,RunningHub 可能會顯得太大。如果你在做短劇、電商、廣告素材、品牌內容或 AI 工具產品,它就很值得看。因為它賣的不是單次生成,而是從創作、模板、工作流到 API 的整套生產鏈。
延伸資源
FAQ
RunningHub 是什麼?
RunningHub 是一個 AI 內容創作平台,整合 ComfyUI 工作流、AI 應用、無限畫布、模型 API 和工作流 API,適合把圖像、影片和內容流程平台化。
RunningHub 和本機 ComfyUI 有什麼差別?
本機 ComfyUI 自由度高,但需要自己管理環境、模型和顯卡。RunningHub 把工作流和模型能力雲端化,適合需要快速創作、分享模板、建立 AI 應用或調用 API 的團隊。
RunningHub 適合哪些場景?
它適合電商商品圖、短劇分鏡、品牌素材、影片生成、角色一致性、高清修復,以及把 ComfyUI 工作流變成可重複調用的內部工具或 API 服務。
by Rain Chu 7 月 9, 2026 | AI , TTS
Qwen3-TTS 這次真正補上的,不只是「又一個開源 TTS 模型」,而是把 AI 語音從單純文字轉語音,往「可以設計聲音」推了一步。對創作者來說,這個差異很大:以前多半是找一段參考音頻去克隆,現在可以先用文字描述你想要的音色,再生成符合角色感的聲音。
我會把 Qwen3-TTS 放在本地 TTS 工具鏈的一個重要位置:它不是完全取代 Index TTS2,也不是只適合做 demo,而是補上了「音色捏臉」這個創作端很需要的能力。尤其當它被包進 ComfyUI 節點後,對做短片、角色對白、旁白、多角色音頻工作流的人會更順手。
如果你之前已經看過 VoxelCPM 本地 TTS 或 本地即時語音 Agent ,Qwen3-TTS 可以理解成另一條更偏「創作型語音生成」的路線。
先講結論:Qwen3-TTS 最值得看的是音色設計
Qwen3-TTS 的幾個核心能力可以拆成三塊:音色設計、音色克隆、自訂聲音與情緒控制,音色克隆大家比較熟,給一段參考音頻,再讓模型生成相似聲音;真正新鮮的是音色設計,你可以用提示詞描述聲音,例如年齡、性別、顆粒感、情緒、語氣、角色氣質。
這件事對內容創作很實用。做科幻短片時,你可以要一個「低沉、沙啞、有壓迫感的中年男聲」;做兒童故事時,可以要「明亮、溫柔、帶笑意的年輕女聲」;做遊戲角色時,可以先把聲音當成角色設定的一部分,而不是等拿到參考音頻後才開始克隆。
這也是 Qwen3-TTS 和 Index TTS2 的關鍵差異,Index TTS2 在參考音頻和情緒控制上仍然很靈活,但 Qwen3-TTS 把「從文字描述生成音色」這件事做成主能力,兩者不是誰完全取代誰,而是切入點不同。
Qwen3-TTS 的三種用法
從 ComfyUI 節點 README 來看,HAIGC 的 Comfyui-HAIGC-QwenTTS 把 Qwen3-TTS 包成幾個常用節點,最核心的是模型載入、聲音設計、聲音克隆、自訂聲音、角色預設保存與多角色對話合成。
用法 需要的模型 適合場景 限制 聲音設計 VoiceDesign 用文字描述角色聲線,先捏出音色 需要會寫清楚聲音提示詞 聲音克隆 Base 用參考音頻生成相似聲音 需要參考音頻與對應文本 自訂聲音 CustomVoice 使用預設說話人或提示詞控制聲音 情緒與音色控制受模型能力限制 多角色對話 搭配角色預設 短劇、廣播劇、遊戲 NPC 對話 要管理角色名與預設檔
這裡有一個實作上很重要的細節:模型要放在 `ComfyUI/models/qwen-tts/` 下面,節點不會幫你自動下載模型。也就是說,這不是裝好節點就直接能跑,還要自己把 Qwen3-TTS 的對應模型資料夾放到正確位置。
ComfyUI 節點讓它更像創作工作流
如果只看 TTS CLI,Qwen3-TTS 會比較像模型測試。但進到 ComfyUI 節點後,它就開始有工作流價值。你可以把文案、角色聲音、參考音頻、角色預設、多角色對話接成流程,最後輸出可用音頻。
這對影片創作者尤其實用。前面整理 OpenMontage 本地 AI 影片工作流 時也提過,影片生成不是只有畫面,旁白、角色語音、字幕和音效都是完整作品的一部分。Qwen3-TTS 這類工具的價值,就是把聲音也放進可控流程裡。
站上之前也整理過 ComfyUI 本機部署工作流 。圖像生成和 TTS 看起來是不同領域,但 ComfyUI 的優勢都是一樣的:把模型變成節點,讓創作者能用流程管理。
音色設計:最像「聲音捏臉」的功能
音色設計最適合用在你還沒有參考音頻,但已經知道角色感的情境。比方說,你想要一個「沙啞、低沉、帶警告意味的戰士聲音」,傳統聲音克隆會問你:參考音頻在哪裡?Qwen3-TTS 的 VoiceDesign 則是讓你先用文字描述聲音。
這對角色型內容很關鍵。短劇、遊戲、動畫、解說頻道,都常常不是缺一個真實人聲,而是缺一個「符合角色設定」的聲音。音色設計讓 TTS 從工具變成創作材料,這是我覺得 Qwen3-TTS 最值得測的地方。
但提示詞也會變成新門檻。你不能只寫「好聽的聲音」,最好描述清楚年齡、性別、音域、情緒、語速、質感、場景。例如:
A deep, raspy middle-aged male voice, slow pace, serious and threatening tone, cinematic fantasy character.
中文也可以寫,但英文描述通常比較容易控制細節。之後如果要大量產角色聲音,我會建議把常用聲音提示詞整理成自己的 prompt library。
聲音克隆:自然度不錯,但仍要看參考音頻品質
Qwen3-TTS 的聲音克隆需要參考音頻,也最好提供參考音頻對應的文本,這點和很多 zero-shot voice cloning 工具一樣:參考音頻越乾淨,語速和情緒越穩,克隆結果越容易自然。
這裡我會提醒兩件事。第一,不要拿太吵、太短、音量忽大忽小的音頻當參考;第二,克隆聲音牽涉聲紋與授權問題,不要拿真人聲音去做未經同意的商業使用,工具越方便,這條線越要自己守住。
如果你主要目標是語音克隆,可以把 Qwen3-TTS 和 VoxCPM 語音克隆 一起測,不要只看單句 demo,要測長句、情緒、停頓、重複生成穩定性。
情緒控制:Qwen3-TTS 和 Index TTS2 的取捨
Qwen3-TTS 可以透過自訂聲音與預設說話人做某種程度的情緒與語氣控制,但這裡要小心期待值,它的自訂情緒方式更偏「用預設或提示詞控制」,而 Index TTS2 在某些情境下則可以直接用參考音頻帶出情緒,操作上會更直覺。
所以我不會說 Qwen3-TTS 全面打掉 Index TTS2。更準確的說法是:
你想從文字描述直接設計聲音,Qwen3-TTS 更值得測。
你有很好的參考音頻,想保留聲音和情緒,Index TTS2 仍然有優勢。
你要做 ComfyUI 影音工作流,Qwen3-TTS 節點會更容易串進流程。
你要穩定量產,兩者都要測長文本、批次生成和錯誤率。
安裝與使用時先注意這幾點
模型要自己下載: 節點預設讀 `ComfyUI/models/qwen-tts/`,資料夾命名要和模型後綴一致。先確認模型類型: VoiceDesign、Base、CustomVoice 對應的功能不同,載錯模型就會覺得節點怪怪的。FP16 / FP32 和 CUDA 要看環境: GPU 跑得快,但顯存、驅動、torch 版本都會影響穩定性。角色預設要管理好: 如果要做多角色對話,角色名、.pt 預設檔和對白格式最好固定。節點早期可能有 bug: 遇到預設節點跑不起來,先看 GitHub issue 和最新 commit,不要急著判定模型不可用。
如果你只是想快速試用,也可以先用 ModelScope 的 Qwen3-TTS demo 或 RunningHub 工作流 感受效果。真正要放進自己的內容生產流程,再回頭做本地 ComfyUI 部署。
適合誰?
我覺得 Qwen3-TTS 特別適合四種人。
短片創作者。 需要快速做旁白、角色音、警告音、廣播音,不想每次找真人錄音。遊戲與互動敘事作者。 多角色對話、NPC 聲音、角色預設會很有用。ComfyUI 工作流玩家。 想把聲音生成接進圖像、影片、字幕和後製流程。本地 AI 研究者。 想比較 Qwen3-TTS、Index TTS2、VoxCPM、ChatTTS 等不同開源 TTS 路線。
如果你只需要最簡單的文字轉語音,反而不一定要上這套。Qwen3-TTS 的價值在於音色設計、角色聲音與工作流整合,而不是單純把一段文字念出來。
資源整理
Qwen3-TTS 補上的是創作者最想要的控制感
Qwen3-TTS 最讓我在意的,不是它又多會念文字,而是它讓聲音開始可以被設計。對內容創作來說,聲音不是最後補上的配件,而是角色、情緒和敘事的一部分。
它目前還不是無腦安裝、無腦量產的工具。模型要自己放、節點要確認版本、不同功能要對應不同模型,ComfyUI 工作流也需要一點整理。但方向很明確:TTS 正在從「文字轉語音」進化成「聲音設計工具」。
一句話總結:Index TTS2 仍然香,但 Qwen3-TTS 把音色捏臉這塊補起來了。之後做角色語音、短劇旁白、多角色對話,我會把它列入優先測試清單。

近期留言