終於有省錢的 GraphRAG – LightRAG是GRAG的燈塔
省錢增效又不失去太多的準確度,值得試試看的知識圖譜 RAG
如何使用可以看這一篇
瀏覽器看這篇-browser-use
https://github.com/gregpr07/browser-use
省錢增效又不失去太多的準確度,值得試試看的知識圖譜 RAG
https://github.com/gregpr07/browser-use
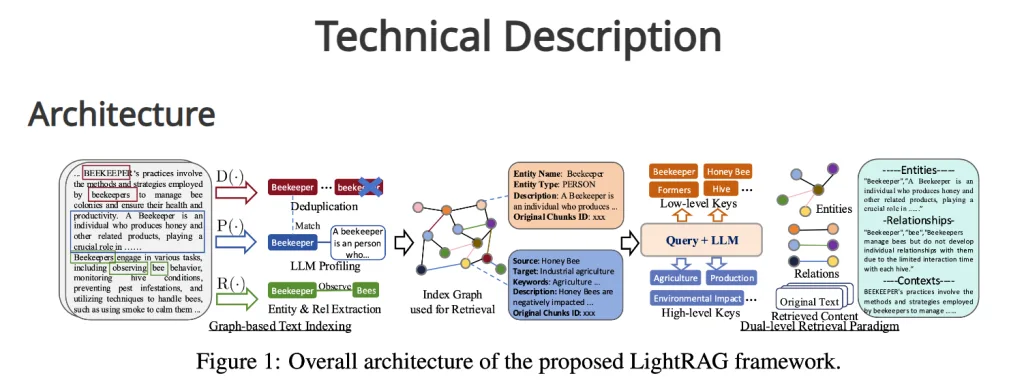
GraphRAG圖像檢索增強生成(Graph Retrieval-Augmented Generation,GraphRAG)超好用,但也超級貴,超級花錢,想要省錢的話,就要用本地端的服務如(Ollama),要用的話,可以按照下面的步驟處理,前提是你已經可以使用 OpenAI 版本的 GraphRAG 了,本篇是要把 OpenAI 改成 Ollama
要先設定好 GraphRAG
下載以及安裝好 Ollama
pip install ollama
把舊的 yaml 檔案改成 ollama 的設定檔,新的設定檔案如下
encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
# model: gpt-4o-mini
model_supports_json: true # recommended if this is available for your model.
# max_tokens: 4000
# request_timeout: 180.0
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# ollama api_base
api_base: http://localhost:11434/v1
model: llama3
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
# model: text-embedding-3-small
# ollama
model: nomic-embed-text
api_base: http://localhost:11434/api
# api_base: https://<instance>.openai.azure.com
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional
chunks:
size: 300
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 0
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# enabled: true
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 0
community_report:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: true # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: true # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: true
raw_entities: true
top_level_nodes: true
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# max_tokens: 12000
global_search:
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32
其中修改 llm 區塊
修改 model: llama3
加入 api_base: http://localhost:11434/v1
修改 embeddings 區塊
model: nomic-embed-text
api_base: http://localhost:11434/api
除了設定好 setting.yaml 以外,程式碼也要修改成可以支持 ollama 的程式碼,有兩處要改,可以用以下現成的程式碼
加入 ollama setting 區塊
# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""The EmbeddingsLLM class."""
from typing_extensions import Unpack
from graphrag.llm.base import BaseLLM
from graphrag.llm.types import (
EmbeddingInput,
EmbeddingOutput,
LLMInput,
)
import ollama
from .openai_configuration import OpenAIConfiguration
from .types import OpenAIClientTypes
class OpenAIEmbeddingsLLM(BaseLLM[EmbeddingInput, EmbeddingOutput]):
"""A text-embedding generator LLM."""
_client: OpenAIClientTypes
_configuration: OpenAIConfiguration
def __init__(self, client: OpenAIClientTypes, configuration: OpenAIConfiguration):
self.client = client
self.configuration = configuration
async def _execute_llm(
self, input: EmbeddingInput, **kwargs: Unpack[LLMInput]
) -> EmbeddingOutput | None:
args = {
"model": self.configuration.model,
**(kwargs.get("model_parameters") or {}),
}
# openai setting
# embedding = await self.client.embeddings.create(
# input=input,
# **args,
#)
#return [d.embedding for d in embedding.data]
# ollama setting
embedding_list=[]
for inp in input:
embedding = ollama.embeddings(model='qwen:7b', prompt=inp) #如果要改模型, 模型的名字要換掉
embedding_list.append(embedding['embedding'])
return embedding_list
加入 ollama setting 區塊,並且關閉 openai setting 區塊即可
# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""OpenAI Embedding model implementation."""
import asyncio
from collections.abc import Callable
from typing import Any
import numpy as np
import tiktoken
from tenacity import (
AsyncRetrying,
RetryError,
Retrying,
retry_if_exception_type,
stop_after_attempt,
wait_exponential_jitter,
)
from graphrag.query.llm.base import BaseTextEmbedding
from graphrag.query.llm.oai.base import OpenAILLMImpl
from graphrag.query.llm.oai.typing import (
OPENAI_RETRY_ERROR_TYPES,
OpenaiApiType,
)
from graphrag.query.llm.text_utils import chunk_text
from graphrag.query.progress import StatusReporter
import ollama
class OpenAIEmbedding(BaseTextEmbedding, OpenAILLMImpl):
"""Wrapper for OpenAI Embedding models."""
def __init__(
self,
api_key: str | None = None,
azure_ad_token_provider: Callable | None = None,
model: str = "text-embedding-3-small",
deployment_name: str | None = None,
api_base: str | None = None,
api_version: str | None = None,
api_type: OpenaiApiType = OpenaiApiType.OpenAI,
organization: str | None = None,
encoding_name: str = "cl100k_base",
max_tokens: int = 8191,
max_retries: int = 10,
request_timeout: float = 180.0,
retry_error_types: tuple[type[BaseException]] = OPENAI_RETRY_ERROR_TYPES, # type: ignore
reporter: StatusReporter | None = None,
):
OpenAILLMImpl.__init__(
self=self,
api_key=api_key,
azure_ad_token_provider=azure_ad_token_provider,
deployment_name=deployment_name,
api_base=api_base,
api_version=api_version,
api_type=api_type, # type: ignore
organization=organization,
max_retries=max_retries,
request_timeout=request_timeout,
reporter=reporter,
)
self.model = model
self.encoding_name = encoding_name
self.max_tokens = max_tokens
self.token_encoder = tiktoken.get_encoding(self.encoding_name)
self.retry_error_types = retry_error_types
def embed(self, text: str, **kwargs: Any) -> list[float]:
"""
Embed text using OpenAI Embedding's sync function.
For text longer than max_tokens, chunk texts into max_tokens, embed each chunk, then combine using weighted average.
Please refer to: https://github.com/openai/openai-cookbook/blob/main/examples/Embedding_long_inputs.ipynb
"""
token_chunks = chunk_text(
text=text, token_encoder=self.token_encoder, max_tokens=self.max_tokens
)
chunk_embeddings = []
chunk_lens = []
for chunk in token_chunks:
try:
# openai setting
#embedding, chunk_len = self._embed_with_retry(chunk, **kwargs)
#chunk_embeddings.append(embedding)
#chunk_lens.append(chunk_len)
# ollama setting
embedding = ollama.embeddings(model="nomic-embed-text", prompt=chunk)['embedding'] #如果要替換嵌入模型, 請修改此處的模型名稱
chunk_lens.append(chunk)
chunk_embeddings.append(embedding)
chunk_lens.append(chunk_lens)
# TODO: catch a more specific exception
except Exception as e: # noqa BLE001
self._reporter.error(
message="Error embedding chunk",
details={self.__class__.__name__: str(e)},
)
continue
#chunk_embeddings = np.average(chunk_embeddings, axis=0, weights=chunk_lens)
#chunk_embeddings = chunk_embeddings / np.linalg.norm(chunk_embeddings)
return chunk_embeddings.tolist()
async def aembed(self, text: str, **kwargs: Any) -> list[float]:
"""
Embed text using OpenAI Embedding's async function.
For text longer than max_tokens, chunk texts into max_tokens, embed each chunk, then combine using weighted average.
"""
token_chunks = chunk_text(
text=text, token_encoder=self.token_encoder, max_tokens=self.max_tokens
)
chunk_embeddings = []
chunk_lens = []
embedding_results = await asyncio.gather(*[
self._aembed_with_retry(chunk, **kwargs) for chunk in token_chunks
])
embedding_results = [result for result in embedding_results if result[0]]
chunk_embeddings = [result[0] for result in embedding_results]
chunk_lens = [result[1] for result in embedding_results]
chunk_embeddings = np.average(chunk_embeddings, axis=0, weights=chunk_lens) # type: ignore
chunk_embeddings = chunk_embeddings / np.linalg.norm(chunk_embeddings)
return chunk_embeddings.tolist()
def _embed_with_retry(
self, text: str | tuple, **kwargs: Any
) -> tuple[list[float], int]:
try:
retryer = Retrying(
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential_jitter(max=10),
reraise=True,
retry=retry_if_exception_type(self.retry_error_types),
)
for attempt in retryer:
with attempt:
embedding = (
self.sync_client.embeddings.create( # type: ignore
input=text,
model=self.model,
**kwargs, # type: ignore
)
.data[0]
.embedding
or []
)
return (embedding, len(text))
except RetryError as e:
self._reporter.error(
message="Error at embed_with_retry()",
details={self.__class__.__name__: str(e)},
)
return ([], 0)
else:
# TODO: why not just throw in this case?
return ([], 0)
async def _aembed_with_retry(
self, text: str | tuple, **kwargs: Any
) -> tuple[list[float], int]:
try:
retryer = AsyncRetrying(
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential_jitter(max=10),
reraise=True,
retry=retry_if_exception_type(self.retry_error_types),
)
async for attempt in retryer:
with attempt:
embedding = (
await self.async_client.embeddings.create( # type: ignore
input=text,
model=self.model,
**kwargs, # type: ignore
)
).data[0].embedding or []
return (embedding, len(text))
except RetryError as e:
self._reporter.error(
message="Error at embed_with_retry()",
details={self.__class__.__name__: str(e)},
)
return ([], 0)
else:
# TODO: why not just throw in this case?
return ([], 0)
2024/07 相信 AI 界最火的是 Microsoft 推出的 GraphRAG 了,看起來很簡單,但坑也不少,網路上教學很多,我這邊專門做一集推坑以及救贖的文章
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
model: gpt-4o-mini
model_supports_json: true # recommended if this is available for your model.要用 ollama 的話,要先安裝 ollama 的庫
pip install ollama
並且用別人已經改好的程式碼
git clone https://github.com/TheAiSingularity/graphrag-local-ollama.git
執行細節可以看
請下載 Gephi
打開 settings.yaml 並且找到 snapshots 將 graphml 打開,這樣子在 index 的時候就會幫你生成 .graphml 的檔案,之後就可以用 Gephi 去編輯他
snapshots: graphml: true raw_entities: true top_level_nodes: true
近期留言