by Rain Chu 8 月 30, 2025 | AI , 圖型處理 , 數據分析
LaneSOD 是一套基於 InSPyReNet (逆向顯著性金字塔重建網路)而延伸出的開源模型,專門針對車道線分割(Lane Segmentation),應用於駕駛場景的 AI 視覺處理中。透過強大的顯著性檢測技術,LaneSOD 能精準辨識道路上的車道線,具備高準確度與可用性。
一、什麼是 LaneSOD?
核心技術 :LaneSOD 架構於 InSPyReNet,後者是一種高解析度顯著性物件偵測模型,於 ACCV 2022 上提出,專門處理高解析度圖片的顯著性檢測,使用金字塔結構融合多階層特徵提高精度。執行場景 :LaneSOD 適用於駕駛視角的車道識別,尤其在多車道或複雜光線下仍能穩定運作,是自駕輔助或智慧交通系統的理想工具。
二、快速上手:使用 LaneSOD 的流程概覽
以下以 Python + PyTorch 環境為基礎,簡述流程步驟:
安裝依賴與下載模型:
git clone https://github.com/plemeri/LaneSOD.git
cd LaneSOD
pip install -r requirements.txt 資料準備與推論:
from lanesod import LaneSODModel
model = LaneSODModel(pretrained=True)
# 載入測試影像
img = load_image("road_scene.jpg")
mask = model.predict(img)
save_image_mask("road_scene_mask.png", mask) mask 是二值化輸出,車道線處為前景。
可進行後處理(edge filtering)提升視覺辨識效果。
三、LaneSOD 的特色亮點
高解析度精準分割 :繼承 InSPyReNet 的頂尖顯著性分析能力,即使複雜場景仍保持高精度。簡易套件整合 :支援 CLI 和 Python API,開發者可快速整合至專案。應用靈活性高 :適用於單張圖片、影片逐幀處理或即時影像分析。MIT 開源授權 :自由使用並可擴展至商業應用。
四、實戰建議
強調後處理 :可搭配 OpenCV 做 morphological operations(如 dilation, erosion)強化車道線連貫性。影片整合 :巡迴處理影片每幀、並套用 temporal smoothing,可提升邊界一致性與視覺效果。多元測試場景 :建議在白天、夜晚、陰影等多樣環境下測試模型穩定性。
原始資料
https://github.com/plemeri/LaneSOD
by Rain Chu 8 月 29, 2025 | AI , 圖型處理 , 影片製作
如何輕鬆地運用 AI 技術,讓影片或直播畫面擁有透明背景 ,無需繁鎖編輯與圖層操作!今天分享的工具是使用 InSPyReNet 提供的開源套件
工具簡介:什麼是 transparent-background[webcam]?
核心技術 :基於 InSPyReNet(ACCV 2022)所提出的 AI 去背演算法,支援圖片、影片甚至 webcam 的背景移除功能 。Python 套件 :名稱為 transparent-background,採 MIT 授權,可自由商業使用。強大特色 :
支援多種輸出模式:如 RGBA(透明背景)、saliency map、綠幕、背景模糊、overlay 等。
支援 webcam 輸入,但 Linux 上需安裝 v4l2loopback 才能建立虛擬攝影機
安裝與依賴設定(含 webcam 支援)
安裝套件 :
pip install transparent-background[webcam] 若使用 Linux,請安裝 webcam relay :
git clone https://github.com/umlaeute/v4l2loopback.git && cd v4l2loopback
make && sudo make install
sudo depmod -a
sudo modprobe v4l2loopback devices=1
CLI 快速範例
transparent-background --source 0 --dest output_folder --type rgba 參數說明:
--source 0 表示 webcam 輸入(一般第一支 webcam 為 0)。--type rgba 代表輸出為帶 alpha 通道的透明背景影像。map、green、blur、overlay 或指定背景圖
用於單一影片檔案
Python API 範例:
讀取 webcam 並顯示去背畫面
import cv2
from transparent_background import Remover
remover = Remover()
cap = cv2.VideoCapture(0) # 開啟預設 webcam
while True:
ret, frame = cap.read()
if not ret:
break
# 處理去背結果(RGBA)
out = remover.process(frame, type="rgba")
cv2.imshow("Transparent Webcam", out)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
📖 transparent-background 參數說明
--source [SOURCE](必填)指定輸入的資料來源,可以是:
單張圖片 :例如 image.png圖片資料夾 :例如 path/to/img/folder單個影片檔 :例如 video.mp4影片資料夾 :例如 path/to/vid/folder整數 :用於指定 webcam 地址,例如 0(對應 /dev/video0 的攝影機)
--dest [DEST](可選)輸出結果存放的資料夾,若未指定,則預設為當前工作目錄 。
--threshold [THRESHOLD](可選)設定硬性去背的閾值,範圍為 0.0 ~ 1.0 。
不建議與 soft prediction 同時使用 ,若未設定,系統會使用「軟性預測」來生成更自然的透明效果。
--type [TYPE](可選)選擇輸出的背景類型,預設為 rgba:
rgba :輸出帶透明通道的影像(alpha map),若未設定 threshold,會自動透過 pymatting 進行前景提取。⚠️ 此模式不適用於影片或 webcam 。map :輸出純粹的 saliency map(灰階遮罩)。green :將背景換成綠幕。white :將背景換成純白色(由 [carpedm20] 貢獻)。‘[255, 0, 0]’ :使用指定的 RGB 顏色作為背景(需加單引號)。blur :將背景模糊處理。overlay :以半透明綠色覆蓋前景並突顯邊緣。另一張圖片 :可指定圖片路徑(例如 samples/background.png),前景會直接疊加在該背景上。
--ckpt [CKPT](可選)使用其他模型檔(checkpoint)。
--mode [MODE](可選)指定運行模式:
base :標準模式。base-nightly :使用 nightly release 版本的 checkpoint。fast :快速模式,速度快但可能在細節上略有損失。
其他選項
--resize [RESIZE]
static(預設):輸出尺寸固定。dynamic:生成更清晰的邊緣,但可能不穩定。
--format [FORMAT]--reverse前景移除 、保留背景(官方玩笑稱為「transparent-foreground」模式 😆)。--jit
範例
單張圖片去背 (輸出透明 PNG):
transparent-background --source input.png --dest output --type rgba 處理整個資料夾的圖片,並輸出模糊背景效果 :
transparent-background --source ./images --dest ./results --type blur 即時 webcam 去背 (Linux 需安裝 v4l2loopback):
transparent-background --source 0 --dest ./webcam_output --type green 更換背景為自訂圖片 :
transparent-background --source video.mp4 --dest ./output --type 'backgrounds/bg.png' GUI 模式
安裝 GUI 支援
pip install --extra-index-url https://download.pytorch.org/whl/cu118 transparent-background[gui] # with gui dependency (flet) 開啟 GUI
transparent-background-gui 官方教學
VIDEO
官方網頁
https://github.com/plemeri/transparent-background
採用的演算法
https://github.com/plemeri/InSPyReNet
開源的後製影片軟體
https://kdenlive.org
參考資料
by Rain Chu 8 月 8, 2025 | Agent , AI , Javascript , Python , RPA , 瀏覽器 , 程式開發
想用 AI 控制網頁自動化,但程式碼又要精準可靠,同時享受自然語言,高效又方便?那你絕不能錯過由 Browserbase 團隊推出的 Stagehand —— 這款專為 AI 時代設計的瀏覽器自動化框架,不僅支援 TypeScript 與 Python、可本地或雲端部署,還比 Browser‑Use 更快、更耐變動!
Stagehand 兼具控制力與智慧的 AI 瀏覽器自動化框架
Stagehand 是以 Playwright 為核心構建的 AI-native 自動化工具,它加入了 LLM 判斷能力,結合程式精準控制與自然語言指令,令自動化腳本更穩定、更智慧也更高效
自然語言 + 程式碼混合操作 :你可以用程式寫明確動作,也能用「act(‘點擊第一個 Stagehand 元件’)」這樣類人語法完成UI操作 。接口完整,支援察看、執行與資料萃取 :核心三大命令 act、observe、extract,讓操作更透明、更可控 容錯與自恢復能力 :UI 略有變動也不怕,Stagehand 的 observe + 快取策略讓腳本更具彈性完美整合 Playwright :所有 Playwright 腳本都能無縫升級 Stagehand,省心又高效
核心玩法!TypeScript/JavaScript 快速上手範例
// Use Playwright functions on the page object
const page = stagehand.page;
await page.goto("https://github.com/browserbase");
// Use act() to execute individual actions
await page.act("click on the stagehand repo");
// Use Computer Use agents for larger actions
const agent = stagehand.agent({
provider: "openai",
model: "computer-use-preview",
});
await agent.execute("Get to the latest PR");
// Use extract() to read data from the page
const { author, title } = await page.extract({
instruction: "extract the author and title of the PR",
schema: z.object({
author: z.string().describe("The username of the PR author"),
title: z.string().describe("The title of the PR"),
}),
}); 這段程式完整示範了初始化、導航、AI 驅動操作到資料萃取的流程,不僅省事,也大幅提升開發效率。
Stagehand 與 Browser-Use 比較
功能面 Stagehand(此文主角) Browser-Use 控制精準度 Token 級動作掌控 + 自然語言指令混合 攻擊角度偏自然語言,程式控制較弱 容錯能力 observe + 快取策略,對 DOM 變化更耐受缺少自恢復機制 雲端支援 原生整合 Browserbase,輕鬆雲端部署 需額外集成,無預設雲平台支援 語言支援 TypeScript / Python 主要依賴 Python AI 整合 天生結合 LLM,支援複雜任務拆解 依賴外部 LLM,不那麼一體化
只要先學四個指令,快速上手
指定去那一個網頁
goto():
# 初始化
page = stagehand.page
# 指定去那一個頁面
await page.goto("https://rain.tips/") 使用自然語言操作
act():
await page.act("點選確定按鈕"); 抓取數據資料
extract():
post = await page.extract("取得標題") 預覽功能
observe():
links = await page.observe("找到頁面中的所有連結") 實戰快速導覽
安裝
# 用 pip
pip install stagehand python-dotenv
# 安裝playwright
python -m playwright install
# 裝 chromium 瀏覽器
python -m playwright install chromium 建立 .env
export BROWSERBASE_API_KEY="your_browserbase_api_key"
export BROWSERBASE_PROJECT_ID="your_browserbase_project_id"
export MODEL_API_KEY="your_model_api_key" # OpenAI, Anthropic, etc. 建立程式碼 main.py
import asyncio
import os
from stagehand import Stagehand, StagehandConfig
from dotenv import load_dotenv
load_dotenv()
async def main():
config = StagehandConfig(
env="BROWSERBASE",
api_key=os.getenv("BROWSERBASE_API_KEY"),
project_id=os.getenv("BROWSERBASE_PROJECT_ID"),
model_name="gpt-4o",
model_api_key=os.getenv("MODEL_API_KEY")
)
stagehand = Stagehand(config)
try:
await stagehand.init()
page = stagehand.page
await page.goto("https://docs.stagehand.dev/")
await page.act("click the quickstart link")
result = await page.extract("extract the main heading of the page")
print(f"Extracted: {result}")
finally:
await stagehand.close()
if __name__ == "__main__":
asyncio.run(main()) 驗證與測試
若要用本地端的瀏覽器的話,可以改成下面的程式碼
import asyncio
import os
from dotenv import load_dotenv
from stagehand import StagehandConfig, Stagehand
load_dotenv()
async def main():
# 检查API密钥是否设置
api_key = os.getenv("OPENAI_API_KEY")
config = StagehandConfig(
env="LOCAL", # 本地运行
# AI模型配置 - 使用环境变量
model_name="gpt-4o-mini", # 使用更便宜的模型
model_api_key=api_key, # 从环境变量读取
# 本地运行配置
headless=False, # 显示浏览器窗口
verbose=3, # 详细日志
debug_dom=True, # DOM调试
)
# 使用配置创建Stagehand实例
stagehand = Stagehand(config)
# 初始化Stagehand(启动浏览器会话)
await stagehand.init()
# 获取页面对象,用于后续的页面操作
page = stagehand.page
await page.goto("https://rain.tips/")
# # 使用observe()取得文章的連結
blog_links = await page.observe("取得文章中的所有連結)
print(f"✅ Page link: {blog_links}")
await page.act(blog_links[0])
data_post_1 = await page.extract("取得文章的標題和內文")
print(f"✅ 文章資訊如下: {data_post_1}")
if __name__ == "__main__":
asyncio.run(main())
總結:為什麼 Stagehand 是下一代自動化框架?
語言直覺更自然,人類可理解 對 UI 變化具彈性、不易失效 結合 LLM,自動拆解任務,效率提升數倍 支援本地與雲端,開發與生產環境都得心應手
Stagehand 正重新定義瀏覽器自動化,不再只是死板指令,而是一場「程式控+AI 智能」的完美結合,無論對開發者或 AI 自動化愛好者,都是一大利器。快一起駕馭它,打造更強、更智慧的自動化流程!
參考資料
BrowserBase
GitHub Stagehand
Demo
開發說明文件
https://www.aivi.fyi/aiagents/introduce-stagehand
by Rain Chu 8 月 7, 2025 | 未分類
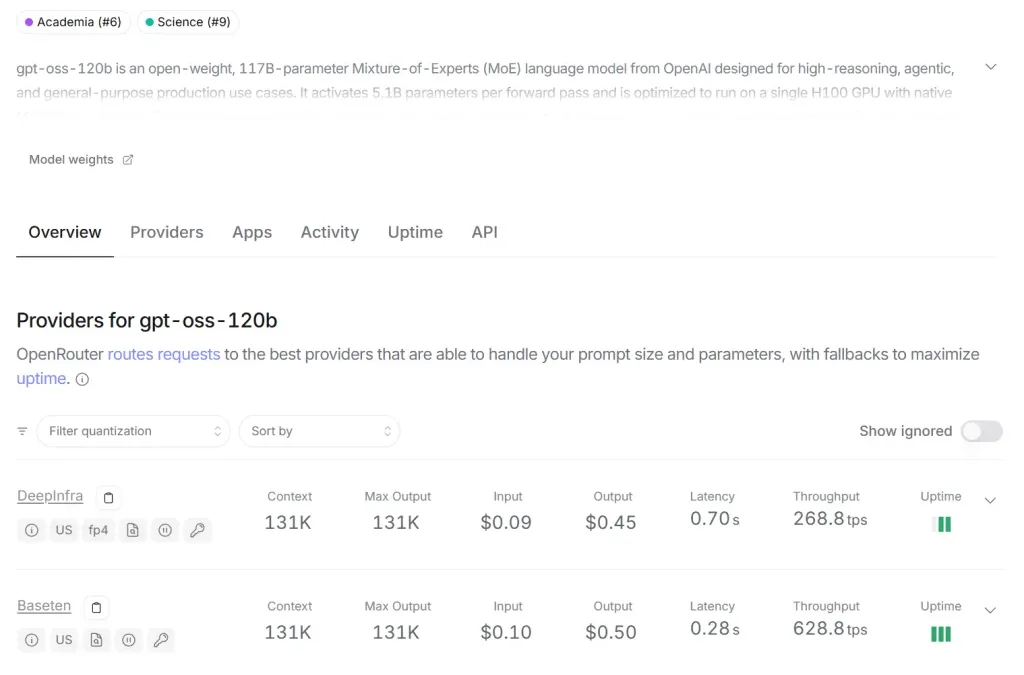
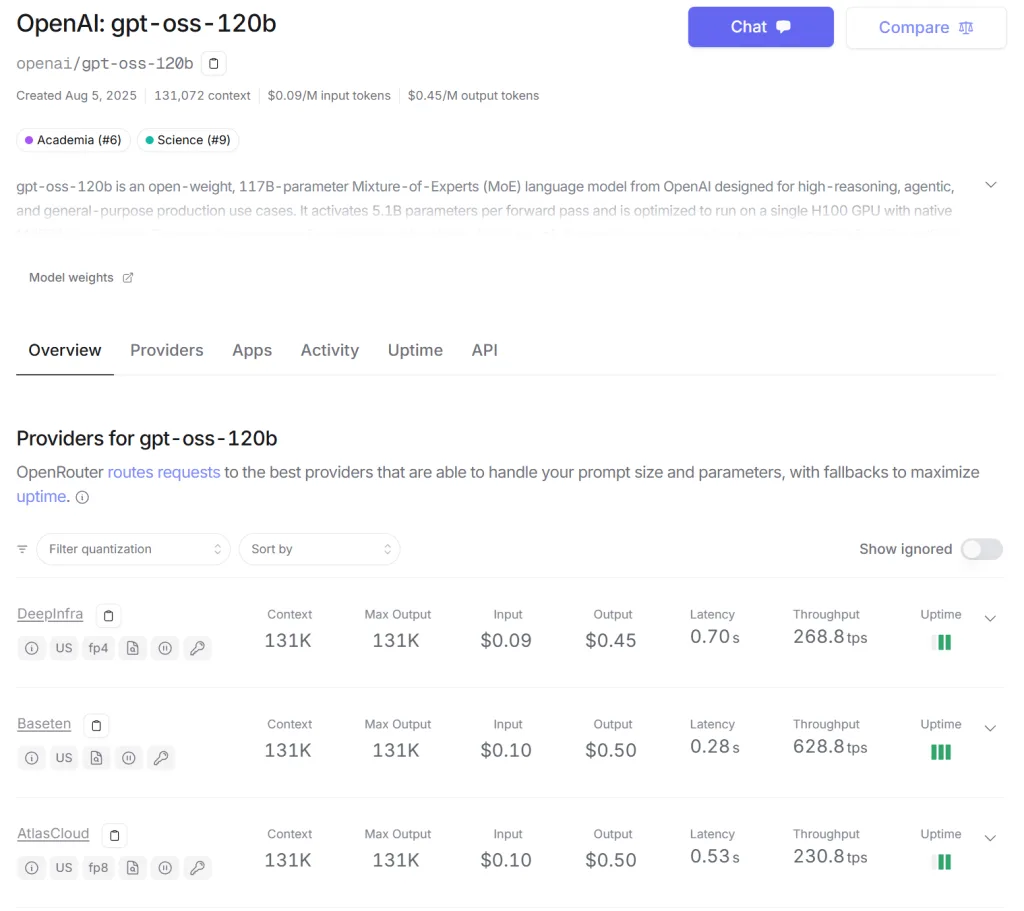
gpt‑oss 教學,可以在 16 GB 筆電上免費使用 OpenAI 的開源 gpt‑oss‑20B / 120B GPT 模型,2025/8/5 OpenAI 終於推出的 gpt‑oss (包括 gpt‑oss‑20B 與 gpt‑oss‑120B)簡直是福音!這些開源模型支持在具備足夠資源的電腦上離線運行,完全不需要存取 OpenAI 伺服器,既保護資料隱私,又零使用量限制。
GPT‑OSS 模型概覽
gpt‑oss‑120B gpt‑oss‑20B
兩者皆採用 Mixture-of-Experts 架構(MoE),對每個 token 只啟用一部分參數,有效節省記憶體與運算資源。
為什麼它值得推薦?
真·免費 & 無使用限制 :完全無需訂閱、不計費,也無 API 次數限制。離線運行,資料更安全 :不連網執行,所有運算都在本地完成,隱私無虞。高效能與實用性並重 :gpt‑oss‑20B 適合筆電、家庭工作站;gpt‑oss‑120B 則適用於高性能 GPU 主機。
如何開始在本地使用 GPT‑OSS?
以下以 Ollama 為例,快速上手流程:
安裝 Ollama (適用於 Windows / macOS / Linux)。使用指令下載模型:ollama pull gpt‑oss:20b
啟動模型聊天介面:ollama run gpt‑oss:20b
要完全離線,也可在 Ollama 設定中啟用「飛航模式」。
ollama pull gpt‑oss:20b # 適合 16 GB 裝置
ollama pull gpt‑oss:120b # 適用於 GPU ≥ 60 GB 設備
對部分硬體較低端的使用者,也可透過像 llama.cpp 加上 GGUF 精簡版模型運行,建議至少 14 GB 記憶體以獲得流暢回應。
歸納總結
模型版本 適用裝置 模型特性 gpt‑oss‑20B 筆電 / Mac 開發者 約 210 億參數、效能近 o3‑mini gpt‑oss‑120B 高階工作站 / GPU 主機 約 1170 億參數、推理接近 o4‑mini
兩者皆具備開源特性,可離線運行、免費使用、無使用量限制,非常適合自主部署與隱私需求高的專案。此外,也可透過 Hugging Face、Azure、AWS 等多平台取得模型。
同場加映
可以用於 mac mini 建議用 oss-120B 放在 MAC 128G 共同記憶體以上的機器,可以有每秒 40 token
不想買機器的,可以先用 openrouter 或是 Groq
內建有 BrowserUse,Python,MCP
可以控制推理強度
MoE混合推理模型
支援企業級應用 vLLM ,SGLang
可以用於 Agent,微調
原生支援MXFP4,ollama等無須轉換
參考資料
https://github.com/openai/gpt-oss
VIDEO
VIDEO
VIDEO
近期留言