
by rainchu | 12 月 15, 2025 | AI, 影片製作
只要一張產品圖,AI 就能直接拍片帶貨!
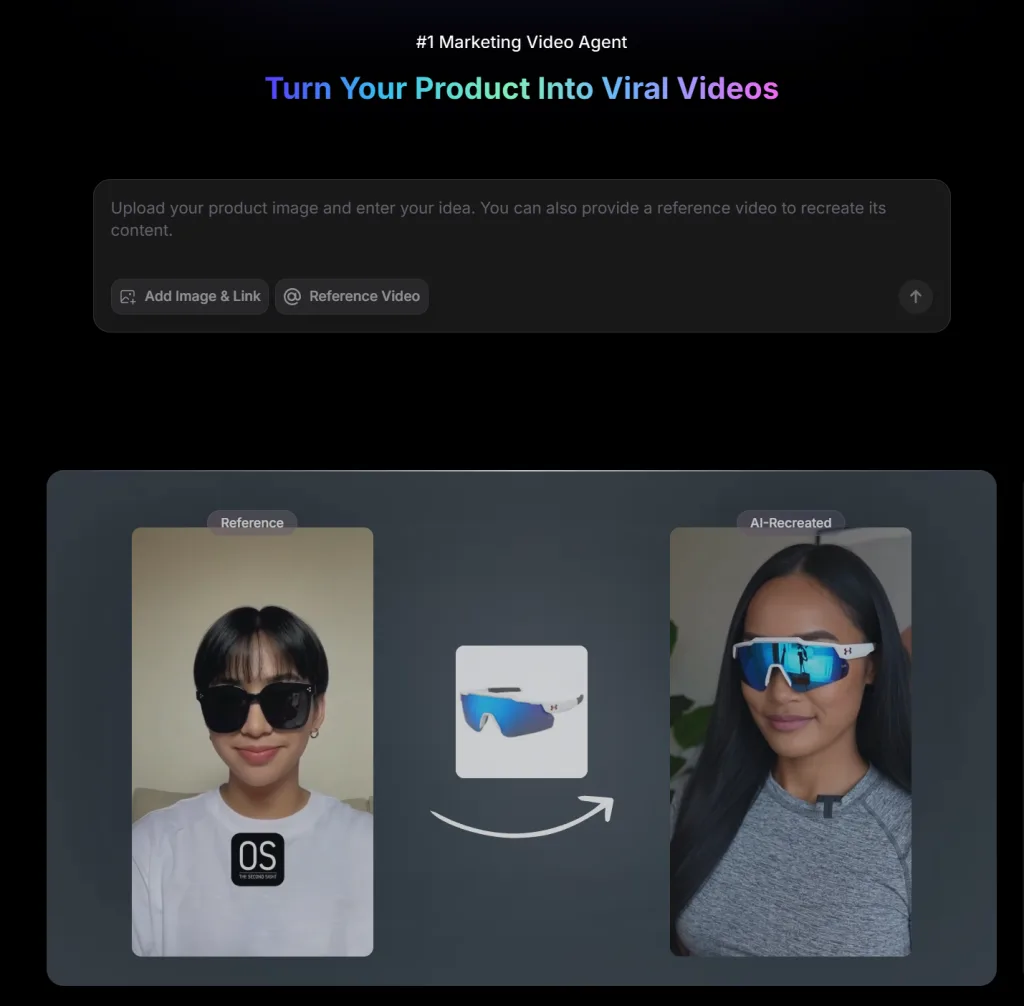
你還在為了拍產品影片煩惱嗎?
要找模特、租場地、剪影片,成本高又耗時?現在,只要一張產品圖,AI 就能直接幫你拍好完整的帶貨影片!
這次要介紹的,就是近期在電商圈與自媒體圈爆紅的 Topview AI,全新升級的 Topview Avatar 2 與 Avatar 4,已經把「AI 虛擬人帶貨」推進到全新等級。
不用真人出鏡、不用攝影棚、不用學剪輯,AI 直接生成 會說中文、唇形同步、動作自然的虛擬帶貨主播,真的非常誇張。
Topview AI 是什麼?為什麼這麼多人在用?
Topview AI 是一款專為行銷與電商打造的 AI 行銷影片生成工具,最大特色就是:
- 只需要 產品圖片 + 文字腳本
- AI 就能自動生成完整的 產品介紹、開箱、廣告影片
- 適用於 電商賣家、接業配、自媒體、品牌行銷、個人 IP
現在很多賣家,已經直接用 Topview 來 批量產出短影音、廣告素材、Reels、Shorts、TikTok 帶貨影片。
🔥 Topview Avatar 2 / Avatar 4 核心特色整理
✅ 能控制角色的手勢、動作(重點)
你不再只能站樁式講話,而是可以用文字指令控制虛擬人:
- 指向產品
- 拿起商品展示
- 換姿勢、換站位
- 走動、比手勢、互動式介紹
讓影片看起來 更像真人業配,而不是呆板 AI。
✅ 支援穿戴展示,大小型商品都 OK
不論你是賣:
- 衣服、褲子、鞋子、包包
- 配件、飾品
- 3C、保養品、小家電
Topview 都可以讓角色 直接穿上你的商品,或是 手持展示大型或小型商品,不再只是把圖片貼在旁邊。
✅ AI 直接生成虛擬帶貨主播(還會說中文)
Topview 的虛擬主播:
- 支援 中文語音
- 唇形高度同步
- 語氣自然,適合業配、銷售、介紹影片
- 可選寫實風、卡通風、寵物風、創意風
甚至你可以讓 卡通角色、虛擬人、寵物角色 幫你帶貨,內容更有記憶點。
✅ 任何產品 × 任何場景,自由搭配
現在你可以做到:
- 把產品放進 任何背景場景
- 讓角色穿上你指定的衣服
- 拿著產品介紹特色
- 搭配創意背景,拍出超有梗的廣告
不用再受限於現實拍攝條件,想像力就是你的攝影棚。
🚀 Topview Avatar 4:直接把 AI 虛擬人拉到下一個等級
最新的 Topview Avatar 4,真的可以說是進化版中的進化版:
- 上傳照片,生成你的 專屬虛擬分身
- 可換身體、換服裝、換動作
- 支援更長的影片(最長可到 2 分鐘)
- 多種模板風格自由選擇
- 更自然的口型同步與肢體動作
不論你是要經營 品牌虛擬人、個人 IP、或長期帶貨角色,這一版真的非常值得研究。
誰最適合用 Topview AI?
如果你是以下族群,Topview 幾乎是必備工具:
- 電商賣家(蝦皮、Shopify、官網)
- 接業配的自媒體創作者
- 想經營虛擬人、個人 IP 的創作者
- 行銷公司、品牌方
- 不想出鏡,但又想拍影片的人
很多用戶已經靠 Topview 穩定產出內容+持續帶貨變現。
💰 Topview 收費與方案說明
👉 Topview AI 註冊連結
https://www.topview.ai/?via=ecomplus
Topview 提供免費與付費會員方案:
免費會員
付費會員(建議)
- 每月 29 美元
- 每月 80 積分
- 可製作高畫質 Avatar 2 / Avatar 4 影片
- 平均每支影片成本不到台幣 50 元
- 年繳方案價格更優惠
與傳統真人拍攝相比,Topview 能用 極低成本批量產出高品質行銷影片,對需要大量素材的賣家來說,CP 值非常高。
實際價格與方案請以 Topview 官網最新公告為主
官方網站

by rainchu | 12 月 15, 2025 | AI, 圖型處理, 模型, 繪圖
Nano Banana Pro 剛出,就馬上成為「圖像生成與視覺應用」領域的新標準,它不只是畫圖工具,而是一個高度可控、支援中文、能維持一致性的 AI 視覺引擎。
以下整理 Google Nano Banana Pro 的 15 種超強應用場景,無論你是設計師、行銷企劃、教育工作者或產品經理,都能立即上手。

1️⃣ 簡報/企劃海報快速生成
只要輸入企劃主題與風格,Nano Banana 就能產出投影片主視覺、封面海報、提案插圖,大幅減少找素材與修圖時間。
2️⃣ 草圖秒變產品實景圖
手繪線稿、低擬真草圖,可直接轉為擬真產品照,特別適合工業設計、UI / UX、新創產品驗證。
3️⃣ 設計材質紋理
可精準生成木頭、金屬、皮革、布料、玻璃等高解析材質貼圖,支援不同光源與粗糙度設定。
4️⃣ 角色一致性
透過角色描述與參考設定,即使多次生成,也能維持臉型、服裝、風格高度一致,非常適合漫畫、品牌代言角色。
5️⃣ 品牌指南手冊
一次生成品牌色彩、字體風格、視覺範例,快速完成 Brand Book 視覺示意。
6️⃣ 生成各種尺寸
同一視覺可自動輸出 社群貼文、橫幅廣告、直式限動、網站 Banner 等多尺寸版本。
7️⃣ 食譜圖超清晰
針對食物細節表現極佳,油光、層次、質地自然,特別適合餐飲菜單、食譜部落格、外送平台。
8️⃣ 多國語言菜單 Menu
結合 Gemini 的語言能力,可直接生成多國語言版本菜單圖片,且排版自然、不違和。
9️⃣ 景點/教材圖卡
可用於旅遊介紹、歷史教材、地理圖卡、兒童學習素材,風格可愛或寫實皆可。
🔟 風格轉換更精細
支援攝影風、插畫風、3D 風、日系、美式、復古等,且保留原圖構圖與細節。
1️⃣1️⃣ 教學假桌面生成
快速生成「假作業系統畫面」、「教學用後台介面」,適合製作教學簡報與線上課程。
1️⃣2️⃣ 腳本 → 連續劇照
輸入分鏡或劇本段落,即可生成連續一致的劇照畫面,對影視提案與動畫前期極有幫助。
1️⃣3️⃣ 中文超強
對繁體中文理解精準,無論是菜單、教材、標語、情境文字,都能自然呈現,不再需要英文轉譯。
1️⃣4️⃣ 畫 3D 圖也可以
可生成擬 3D、等角視圖、產品爆炸圖概念,適合簡報與技術說明使用。
1️⃣5️⃣ 任意切換焦距
同一場景可切換廣角、標準、特寫、微距,視覺敘事能力大幅提升。
參考與官方資源

by rainchu | 12 月 15, 2025 | AI, 影片製作
✨ 評測機構最佳影片剪輯軟體:Filmora AI 賦能,你也是剪輯大師
現代影片創作者越來越仰賴智能剪輯工具來提升效率與作品品質, Wondershare 旗下的 Filmora 便是一款兼具 易用性與 AI 能力 的影片剪輯軟體,無論你是新手、行銷人員、還是專業剪輯者,都能輕鬆上手並創作出具有專業感的作品。

🎬 一、直覺操作 + AI 加速創意流程
Filmora 提供清晰易懂的操作介面,搭配智能化的 AI 功能,讓剪輯流程不再繁瑣。無論你是初次剪片或進階創作者,都能有效縮短學習曲線並加速製作流程。Filmora 不只提供基本剪輯工具,更加入 AI 驅動的智能剪輯、自動字幕與語音處理等功能,大幅提升效率。
✏️ 二、鋼筆工具與動態路徑控制:精準掌握每一格畫面
其中 鋼筆工具(Pen Tool) 是 Filmora 一大亮點,可讓你:
- 自由繪製動態路徑
- 控制動態軌跡的曲線與速度
- 套用到文字、圖像與圖層上
- 透過 關鍵影格(Keyframes) 微調動作,使畫面過渡自然流暢
這項工具不需外部插件就能在時間軸上直接繪製動畫路徑,讓你打造更具故事性與視覺張力的動態畫面。
📊 三、動態圖表套用:讓資訊表現更具說服力
除了影片剪輯,Filmora 也支援將資料套用至 動態圖表,透過動畫與視覺效果強化資訊表現,不論是:
- 行銷影片中的 KPI 呈現
- 簡報影片中的數據分析
- 產品報告或企劃影片
這功能超好用,可以做出很多超專業的YT他們的專業影片,可以讓抽象數據具體化、呈現更專業的視覺吸引力。
這種結合多媒體與資訊可視化的能力,是傳統剪輯工具較難一次做到的。整體來說,它非常適合 行銷影片與專業簡報內容製作。
🤖 四、AI 擴增場景:智慧剪輯、字幕與生成效率提升
Filmora 不僅提供基礎剪輯功能,還整合了多項 AI 擴增工具:
- 智慧剪輯與自動選段:快速抽取影片精華片段,剪出短片或精簡版內容,大幅提高編輯效率。
- AI 影片翻譯與動態字幕:支援多語字幕生成,甚至連人物唇型都可同步調整。
- AI 去背與人像偵測:精準移除背景,讓場景創作更加靈活。
- Copilot 2.0 智能助理:高效協助批次處理與素材搜尋。
這些 AI 加速工具使得剪輯過程不再只是 手動剪接,而是變成具策略性、智能化的創作流程。
📈 五、適合所有創作者的剪輯方案
Filmora 提供跨平台支援(Windows、macOS、iOS、Android),不論你是在電腦、平板或手機,都能隨時製作影片。內建豐富的 模板、特效、音樂與轉場效果,大幅提升作品的可看性與質感。
此外,官方也提供試用版讓你先體驗功能,再決定是否購買完整版。整體評價指出它非常適合社群短片、YouTube 影片與教學影片等多種創作場景。
🎬 Filmora 與 剪映 CapCut 的主要差異比較
🆚 1. 功能定位與使用者族群
- Filmora:設計上結合 直覺操作界面 + 專業剪輯能力,非常適合從入門到進階剪輯者。Filmora 支援豐富的 AI 工具與精細控制功能,例如鋼筆路徑、關鍵影格等進階細節表現,適合製作行銷影片、專業簡報或內容品牌影片等。
- 剪映(CapCut):由 TikTok / ByteDance 支援,主打 簡單、快速、免費 的剪輯體驗,對於製作短影片、社群內容非常友好,尤其適合初學者或需要大量快速輸出短影片的工作者。
🛠️ 2. 操作介面與學習曲線
- Filmora:介面直覺但功能更全面,適合中階創作者深入調整每個細節。時間軸控制精準,支援雙時間軸、動態路徑與微調功能,提升影片細節掌控感。
- 剪映:主打 極簡操作,拖放式編輯非常容易上手,對於不想投入太多剪輯學習時間的使用者尤其友善。
🤖 3. AI 自動化剪輯與進階功能
- Filmora:提供包括 AI 智能蒙版、AI 去背、人像分離、動態字幕、AI 影片延長 等多種 AI 功能,可以用來提升影片品質與創意表現。
- 剪映(CapCut):同樣具備 AI 自動字幕、AI 去背、熱門模板、一鍵成片 等工具,對於快速產出影片與社群導向內容非常有效。
🌐 4. 平台與成本
- Filmora:提供 Windows、macOS 與行動裝置版本,功能完整但某些進階素材與模板可能需要額外付費或訂閱。
- 剪映(CapCut):本身以免費使用為主(含大部分功能),無浮水印且可跨平台使用(例如手機、桌面與網頁版),對預算有限的創作者非常友好。奇寶網路 –
📈 5. 適用場景總結比較
| 對比項目 | Filmora | 剪映 CapCut |
|---|
| 初學者上手難易 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 多軌與精細控制 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ |
| AI 進階功能 | ⭐⭐⭐⭐ | ⭐⭐⭐ |
| 社群短影片效率 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 專業影片剪輯 | ⭐⭐⭐⭐ | ⭐⭐ |
| 成本 | 中等/付費方案 | 免費為主 |
參考資料
官方網站
https://filmora.wondershare.tw/
延伸閱讀
by rainchu | 12 月 14, 2025 | AI, 影片製作, 音樂
Tunee.AI 不只是能「生音樂」,它更厲害的是真正理解畫面、情緒與旋律邏輯,甚至可以把你生成的音樂直接自動拍成一支完整 MV。
不是套模板、不是隨便剪,而是從音樂情緒出發,重新定義 AI 音樂創作流程。
這篇文章將完整帶你體驗 Tunee AI 的實際玩法,並解析為什麼它被稱為「Suno 殺手」。
👉 官方網站:
https://www.tunee.ai/
🎵 圖片轉音樂|對話式圖片生音樂
Tunee AI 最讓人驚豔的功能之一,就是 「圖片 → 音樂」。
你只需要上傳一張圖片,例如:
Tunee AI 會解析畫面情緒、色調與構圖,並透過對話方式詢問你想要的:
- 曲風(流行、抒情、電子、Lo-fi…)
- 情緒(憂鬱、溫暖、熱血、浪漫)
- 語言與人聲設定
這不是單向指令,而是真正的「對話式 AI 作曲體驗」,成品自然度遠超傳統 AI 音樂模板。
🎥 影片轉歌曲|影片解析生成完整歌曲
接下來這個功能,直接顛覆創作者的想像。
Tunee AI 可以:
👉 上傳影片 → 自動生成一首完整歌曲
系統會分析:
然後生成:
這對於:
幾乎是 一鍵完成專屬主題曲,效率直接拉滿。
🎼 風格化音樂生成
很多人用 AI 音樂最怕的就是:「學不像」。
Tunee AI 在「風格化生成」這一塊,表現非常成熟。
你可以指定參考曲目(例如:周杰倫《晴天》),但 不會抄旋律、不侵權。
AI 只會學習:
生成的作品:
✔ 有熟悉感
✔ 但旋律完全原創
✔ 非常適合商用與創作發表
🌍 二創外文歌曲|AI 多語音樂製作
Tunee AI 在「語言與人聲」方面,也明顯優於許多 AI 音樂平台。
支援:
你可以進行:
- 外文歌曲二次創作
- 中文歌改英文版
- 不同語言同旋律版本
而且咬字自然、情緒到位,已經接近真人歌手水準。
🎬 AI 自動拍 MV|生成音樂 MV 長片
這一段,就是 Tunee AI 封神的關鍵。
Tunee AI 可以:
👉 把你生成的音樂,自動轉成一支完整 MV
不是簡單素材拼接,而是:
- 根據音樂段落切換畫面
- 副歌自動放大情緒張力
- 視覺節奏完全貼合旋律
生成的是「可直接上架 YouTube 的 MV 長片」,
對創作者來說,等於 音樂 + 影像一次完成。
🔥 Tunee AI 為什麼被說是「Suno 殺手」?
| 功能 | Tunee AI | Suno |
|---|
| 圖片轉音樂 | ✅ | ❌ |
| 影片轉歌曲 | ✅ | ❌ |
| 對話式作曲 | ✅ | ❌ |
| 風格理解深度 | 高 | 中 |
| AI 自動拍 MV | ✅ | ❌ |
結論只有一句話:
Tunee AI 是一套「完整的 AI 音樂 + 影像創作系統」,不是只有生歌。
✅ 適合哪些人使用?
- YouTuber / 短影音創作者
- 音樂創作新手
- 廣告、品牌行銷
- 想快速產出原創歌曲與 AI MV 的創作者
👉 官方入口:
https://www.tunee.ai/
by rainchu | 12 月 12, 2025 | Agent, AI
一句話說明
支援工具調用、多 Agents 協作的微軟最強開源可視化 Agents 框架 — 輕鬆打造旅遊規劃智能體、處理複雜任務的最佳利器!
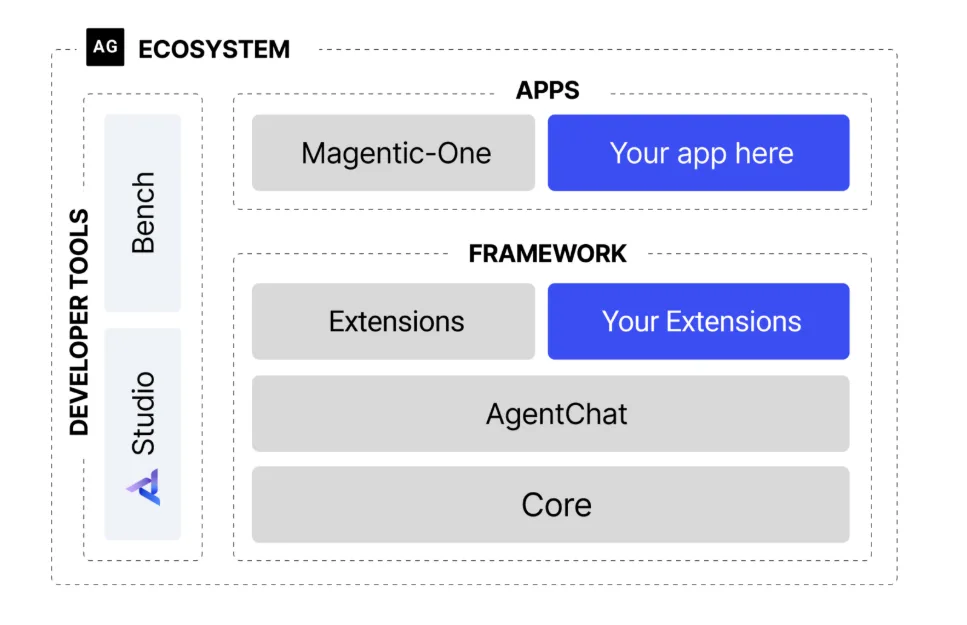
在 AI 智能體(AI Agents)快速崛起的時代,微軟推出的 AutoGen Studio 讓任何人都能以「零代碼」、「可視化拖拉介面」打造各種自動化工作流。無論是旅遊規劃智能體、資料分析助理、客服回覆機器人,甚至多智能體互動的複雜任務流程,都能在短時間內建立與部署。
AutoGen Studio 讓過去需要高階程式能力的 AI 協作流程變得像玩積木一樣簡單,只要拖動 Agents、設定工具、串接提示與流程,就能建立具備邏輯判斷、工具調用(Tool Calling)、資料取得與任務分解能力的完整 AI 系統。
🔥 為什麼 AutoGen Studio 如此強大?
1. 零代碼可視化工作流
AutoGen Studio 最大亮點就是它的 Flow 介面:
只需拖曳 Agents、工具與節點,即可建立流程圖般的 AI 工作流程。
不用寫一行程式碼,新手也能三分鐘上手!
2. 支援多智能體協作(Multi-Agent Collaboration)
要讓多個 AI Agents 聊天、討論、分工?
AutoGen Studio 完全支援!
例如:
- 規劃旅遊行程的 Planner Agent
- 搜尋航班與飯店的 Tools Agent
- 彙整結果輸出的 Writer Agent
它們可以自動來回互動、分工完成任務,就像一組虛擬團隊。
3. 強大的工具調用(Tool Calling)
AutoGen 完整支援 LLM 的工具調用能力,例如:
- 呼叫外部 API
- 執行 Python 程式
- 查詢資料庫
- 擷取網頁內容
這意味著 AI 不再只是回答,而是能夠「行動」。
4. 開源、可擴充、跨平台
AutoGen 由微軟研究院開源,擁有極高可擴充性:
- 可以接入任何 LLM(OpenAI、Azure、Claude…)
- 可以擴展自訂工具
- 可與 AutoGen Python SDK 整合
- 可部署於本地或雲端
5. 專為「複雜任務」設計
AutoGen 的重點不只是聊天,而是處理需要多步驟推理與協作的任務,例如:
- 報表自動化
- 資料分析
- 內容生成
- 專案規劃
- 多工具串聯流程
其強大的任務協作機制遠超一般 ChatGPT Prompt Flow。
🚀 AutoGen Studio 三分鐘快速入門
以下是最常見的新手流程,只要三分鐘就能打造第一個智能體工作流!
步驟 1:建立一個新的 Flow
在 Studio 中點擊「Create Flow」即可開始建構可視化流程。
步驟 2:加入兩個 Agents
例如:
- User Proxy Agent:負責接收使用者輸入
- Assistant Agent:負責執行任務
也可以加入更多 Agents 並設定參數,例如角色、工具、溝通方式等。
步驟 3:加入工具(Tools)
你可以啟用 AutoGen 內建工具或自訂:
- Python 執行器
- HTTP API
- 檔案處理
- 計算器
- 資料庫查詢
步驟 4:連接節點、設定觸發事件
就像畫流程圖一樣,連接 Agents → 工具 → 回傳結果。
步驟 5:點擊「Run」即可開始執行
AI 智能體會自動互動並完成任務。
🧭 範例:打造「旅遊規劃 AI 智能體工作流」
這是一個 AutoGen Studio 非常經典也最吸引人的應用情境!
你可以建立:
Agent 角色分工
- 旅遊規劃師(Planner Agent):負責制定行程
- 搜尋工具 Agent(Search Tool Agent):查詢航班、景點、天氣
- 彙整撰稿 Agent(Writer Agent):輸出易讀的旅遊計畫表
工具串接
- Web Search API
- 天氣 API
- 飯店 API
- Python 資料處理
輸出成果
AutoGen Studio 能交付:
只要輸入:「幫我規劃 5 天東京自由行」,就能自動完成一整套旅遊計畫!
💡 AutoGen Studio vs 傳統 Agents 工具
| 功能 | 傳統 Agents | AutoGen Studio |
|---|
| 可視化介面 | ❌ 無 | ✔ 直覺拖拉 |
| 工具調用 | 部分支援 | ✔ 深度整合 |
| 多 Agents 協作 | 複雜 | ✔ 自動化運作 |
| 部署方式 | 程式碼導向 | ✔ 零代碼工作流 |
| 新手友善度 | 低 | 非常高 |
AutoGen Studio 就是為「人人都能打造 AI Agents」而生。
⭐ AutoGen Studio + Animon AI:最強 AI Agents 組合
目前網路上爆紅的 Animon AI(AI Agents 捷徑平台) 常與 AutoGen/AutoGen Studio 結合使用。
Animon AI 擅長:
- 快速調用多個模型
- 整合多來源資料
- 部署輕量級 Agents
AutoGen Studio 擅長:
- 視覺化工作流
- 多 Agents 協作
- 擴充與工具調用
兩者搭配可建立更完整的 AI Agents 生態。
📌 AutoGen Studio 官方資源
近期留言