by Rain Chu 6 月 14, 2026 | Agent , AI , Hermes , OpenClaw , Prompt
當我們開始用 AI 寫網站、做 Landing Page、產生前端介面時,常常會遇到一個問題
畫面看起來很快就完成了,但總覺得「哪裡怪怪的」。
按鈕很像、卡片很多、漸層很浮誇、字級沒有層次、留白不夠精準,甚至每個 AI 產生的網站都像是同一套模板改出來的。這種「可以用,但不高級」的設計感,就是許多 AI 前端作品容易落入的平庸陷阱。
而 Impeccable 官方網站 想解決的,正是這個問題。
什麼是 Impeccable?
Impeccable 是一套專為 AI Coding Agent 設計的前端設計輔助工具,它不是單純幫你產生漂亮畫面的 AI 設計工具,而是提供一套「設計語彙」與「設計指令」,讓你可以更精準地指揮 AI 改善網站畫面。
簡單說,Impeccable 讓 AI 不只是會寫程式,也更懂設計。
它可以協助 AI 理解網站中的層級、對比、留白、色彩、字體、動畫、產品脈絡與品牌調性,讓 AI 產生的前端畫面不再只是堆滿卡片、套上漸層、加一點陰影,而是更接近真正設計師會思考的介面。
你可以把 Impeccable 想像成:
一套給 AI 前端工程師使用的設計總監指令集。
為什麼 AI 做出來的網站常常很平庸?
現在很多人會用 AI 幫忙做網站,例如請 Claude Code、Cursor、Codex CLI 或 Gemini CLI 產生頁面。AI 很擅長快速完成版型,但如果沒有足夠清楚的設計方向,它很容易產生幾種常見問題:
每個區塊都用卡片包起來,看起來很模板化
喜歡使用過度常見的紫色漸層、玻璃擬態、發光陰影
字體大小與層級不夠精準,主標、副標、內文沒有明確節奏
留白太平均,缺乏視覺重點
按鈕、表單、導覽列看起來功能正確,但沒有品牌感
Landing Page 和後台 Dashboard 使用同一種設計邏輯
作品看起來像 AI 產物,而不是成熟產品
Impeccable 的價值就在於,它不是只叫 AI「設計得漂亮一點」,而是提供更具體的設計方向,例如讓畫面更有層次、更安靜、更大膽、更精煉、更符合產品情境。
Impeccable 的核心特色
1. 提供 AI 可理解的設計語言
Impeccable 的官方介紹中提到,它補上了 AI Agent 缺少的設計語彙,這代表你可以用更接近設計師的方式指揮 AI,例如改善排版、調整顏色、強化視覺層次、降低過度設計、整理產品脈絡。
這對不熟設計術語的人很有幫助,因為你不需要長篇大論解釋「我要更高級、更有質感、更像品牌網站」,而是可以透過 Impeccable 的指令,把設計意圖轉成 AI 比較能執行的動作。
2. 支援多種 AI Coding 工具
Impeccable 可以搭配多種主流 AI Coding 工具使用,例如 Cursor、Claude Code、GitHub Copilot、Gemini CLI、Codex CLI 等。
這代表它不是只服務單一平台,而是比較像一套可以帶進不同開發流程的設計輔助層。對於已經習慣用 AI 寫前端的開發者來說,Impeccable 可以直接加入現有工作流程,不需要重新學一套完整設計軟體。
3. 透過指令改善網站設計
Impeccable 提供多個設計指令,讓你可以針對不同設計任務下達命令。例如:
/impeccable init
/impeccable shape
/impeccable critique
/impeccable audit
/impeccable polish
/impeccable bolder
/impeccable quieter
/impeccable distill
這些指令的好處是,你可以更像在跟設計師溝通,而不是一直對 AI 說:「再漂亮一點」、「再高級一點」、「不要這麼普通」。
4. 幫你減少 AI 生成網站的套路感
很多 AI 產生的網站會有明顯套路,例如紫色漸層、大量圓角卡片、發光邊框、過度一致的版面節奏。Impeccable 內建反套路的設計檢查,可以幫助你找出這些容易讓網站看起來廉價、模板化或過度 AI 感的元素。
這對品牌網站、形象頁、SaaS Landing Page、產品頁、作品集網站尤其重要。因為這些頁面的重點不只是功能完成,而是要讓使用者在第一眼感覺到專業、信任與差異化。
5. 保留你的設計系統,不是硬套新風格
Impeccable 的另一個優點是,它不是粗暴地把你的網站改成另一種風格,而是會盡量尊重既有的設計系統,例如顏色、字體、元件、間距、按鈕樣式與品牌規則。
這對已經有產品雛形或既有網站的人很重要。你不一定想要整個重做,而是希望 AI 幫你把現有介面整理得更成熟、更一致、更像一個真正的產品。
Impeccable 適合誰使用?
Impeccable 特別適合以下幾種人:
1. 用 AI 寫前端的開發者
如果你常用 Cursor、Claude Code、Codex CLI、GitHub Copilot 來產生 React、Next.js、Astro、Tailwind CSS 或其他前端頁面,Impeccable 可以幫你補上 AI 在設計判斷上的不足。
2. 想快速做出高質感 Landing Page 的創業者
很多創業者會用 AI 快速做 MVP,但 Landing Page 如果太普通,會影響使用者信任感,Impeccable 可以幫助你把「能用的頁面」推進到「比較有品牌感的頁面」。
3. 會寫程式但不擅長設計的人
你可能知道功能怎麼做,但不知道為什麼畫面不夠好看。Impeccable 可以用指令化的方式協助你檢查排版、層級、色彩與互動細節。
4. 想降低 AI 生成感的網站製作者
如果你的網站看起來太像 AI 產物,Impeccable 可以幫你找出常見的 AI 設計套路,讓畫面更有辨識度。
如何安裝 Impeccable?
你可以到 GitHub 下載與查看 Impeccable 專案:
Impeccable GitHub 下載頁
官方建議可以在專案根目錄執行:
npx impeccable skills install
接著在你的 AI Coding 工具中執行:
如果之後要更新,可以執行:
npx impeccable skills update
官方網站也提供更多說明與範例:
Impeccable 官方網站
使用 Impeccable 的工作流程建議
如果你正在做一個網站或前端產品,可以用以下流程開始:
第一步,先用 AI 產生基本頁面結構。
第二步,執行 /impeccable init。
第三步,用 /impeccable shape 先整理畫面架構。
第四步,用 /impeccable critique 檢查設計問題。
第五步,用 /impeccable polish 做上線前修飾。
第六步,必要時使用 /impeccable audit。
對 WordPress 網站製作者有什麼幫助?
雖然 Impeccable 本身比較偏向 AI Coding Agent 與前端開發流程,但對 WordPress 網站製作者也很有參考價值。
如果你使用 WordPress 搭配自訂佈景主題、區塊編輯器、Elementor、Bricks、Breakdance 或自製前端元件,你可以先在本機或開發環境中,用 AI 建立前端區塊,再透過 Impeccable 改善設計品質。
例如:
首頁 Hero 區塊不夠有記憶點
服務介紹區塊太像模板
價格表太普通
Call to Action 不夠明確
部落格列表頁缺乏層次
後台管理介面太陽春
品牌網站缺乏高級感
這些都可以透過 Impeccable 的設計指令進行調整,再整合回 WordPress 佈景主題或頁面模板中。
結論:Impeccable 讓 AI 網站設計從「能用」走向「有質感」
AI 讓網站製作變快,但速度不代表品質。真正影響使用者感受的,往往是那些細節:字體層級、留白、對比、色彩、互動節奏、品牌一致性,以及畫面是否有明確的設計意圖。
Impeccable 的重點不是取代設計師,而是讓 AI 更容易理解設計師的語言,也讓開發者可以用更精準的方式指揮 AI 做出不平庸的網站。
如果你正在用 AI 製作網站,卻覺得畫面總是差一點質感,那麼 Impeccable 很值得加入你的前端工作流程。
官方網站:https://impeccable.style/
GitHub 下載:https://github.com/pbakaus/impeccable
by rainchu 12 月 12, 2025 | AI , PPT , Prompt , 圖型處理
最近 Google Labs 再次投下震撼彈——推出全新的視覺協作工具 Google Mixboard 。這款被科技界譽為「進階版的 AI Pinterest 」的創作平台,不只提供一張能無限延伸的靈感畫布,讓使用者自由拼貼、蒐集、創作,更強大的是它整合了 Google 最新影像模型 Gemini Nano Banana Pro ,讓「圖片與文字的轉化能力」大幅進化。
Mixboard 不只是找圖工具,它是一款真正能把雜亂靈感整合成專業產出 的 AI 創作平台。從蒐集參考、生成圖像、到一鍵變成簡報,你的創作流程從此不再分散於各個應用工具,全部在 Mixboard 一站式完成。
🌈 AI 靈感畫布:願景、概念、素材一次整合
Mixboard 的核心概念是一張能無限延伸的 Infinite Canvas(無限畫布) 。你可以:
任意拖放圖片與文字
建立 Moodboard / 風格版
生成 AI 圖像
標記重點、串連思考流程
與團隊同步協作
它的使用體驗與 Pinterest 的收藏便利性類似,但功能延伸到即時生成、編輯與視覺敘事,因此被形容為「AI 時代的 Pinterest 2.0」。
對設計師、行銷人、PM、內容創作者而言,這款工具能大幅提升發想到產出的速度與品質 。
⚡ Nano Banana Pro 模型強化「圖文轉化」:簡報不再需要手動排版
Mixboard 最大亮點,就是 Google Labs 全新的 Gemini Nano Banana Pro 影像模型。
它最令人驚豔的能力是:
⭐ 一鍵把零散靈感 → 自動變成專業簡報
只要選擇畫布內容並下指令,Mixboard 能:
自動辨識素材意圖
依據內容自動重構敘事結構
自動生成排版精美的投影片
產出高解析度圖片與文字
保留原本的風格、色調、敘事邏輯
無論你是做品牌提案、產品靈感收集、UI 改版構思、或社群 campaign 規劃,原本需要花上數小時整理的簡報,都只要 一鍵轉換 就能完成。
🧩 Mixboard 解決了哪些過往創作痛點?
1. 靈感雜亂、難以整理
貼在 Notion?存到 Pinterest?散落在相簿?
2. 簡報排版耗時
你只需要負責「想法」,簡報排版由 AI 完成。
3. 多工具切換降低效率
找圖 → 裁圖 → 設計 → 編排 → 簡報,全部一站式完成,大幅縮短製作流程。
4. 團隊協作斷層
Mixboard 支援分享與多人編輯,視覺溝通更直觀。
🚀 更適合哪些族群使用?
品牌行銷團隊
社群小編、內容創作者
新創團隊 Pitch Deck 製作者
設計師、UI/UX 規劃者
教育工作者、講師
想快速整理靈感的人
如果你常常在 Canva、Keynote、Notion、Pinterest 之間切換,Mixboard 將會是你最強的替代方案。
🔗 更多資訊
官方網站:https://labs.google.com/mixboard/welcome
by Rain Chu 9 月 30, 2025 | AI , Prompt
你常常只給 AI 九個字,卻期望它做出奇蹟嗎?根據 Google 官方統計資訊,只有當提示詞達到 21 個字以上,AI 才有機會輸出高品質答案。Google 在提示工程白皮書中也強調,好的提示詞結構比簡單請求更能引導大模型解出我們要的內容。
在這篇文章,我要分享給你一個 Google 推薦的「萬用公式」提示架構:角色 + 任務 + 背景 + 格式 ,輔以動詞導向的敘述方式,讓你的 AI 提示更加有力、精準。
✅ Google 萬用提示公式:角色、任務、背景、格式
組成部分 目的 範例 角色 設定 AI 扮演的身份或專業領域 「請你扮演一位專業的旅遊部落客…」 任務 定義主要目標與行動 「…撰寫一份為期三天的行程…」 背景 加入情境、限制條件、目標對象 「…針對要去東京的小資旅行。」 格式 指定輸出的結構與型式 「…請用簡單的條列式清單呈現。」
用這樣的架構引導 AI,能讓提示詞具體、有結構,減少 AI 的猜測空間。
🛠 用詞與語法技巧 TIPS(提升提示效能的小技巧)
盡量用動詞開頭 :給 AI「做什麼」比「什麼是」更有力。例如用「撰寫」「列出」「翻譯」「審校」等動詞開頭。避免模糊語詞 :少用「很棒」「不錯」這類曖昧形容詞,改用具體指標(如「300 字」「三段落」「條列式」)。提供範例或模板 :在提示中給一個輸出範例讓 AI 參考,降低偏差。讓 AI 回問你需要什麼 :可以讓 AI 主動反問「你要什麼風格/語氣/受眾?」來細化需求。
🧩 實例演練:讓 AI 幫妳寫提示詞
下面示範一個互動流程:
你對 AI 說:
AI 回覆後你可以加一句:
「請問你要什麼風格?正式、活潑、針對女性或男性?」
AI 反問後,你回答語氣與受眾,它就能生成更貼合你需求的文案。
這樣的對話式提示設計也比一次寫好全部提示更靈活有彈性。
💡 為什麼 21 字以上比 9 字好?
模型理解上下文有門檻:過短提示缺乏足夠上下文,AI 容易「自由發揮」,未必對應你真正需求。
更精準引導模型工作:加入角色、任務、背景與格式,能讓 AI 經過「角色思考」後才動手回答。
提示後段不易被截斷:雖然 AI 提示有長度限制,在合理長度內放些條件比過短更能保留關鍵訊息。
小結與建議
使用 角色 + 任務 + 背景 + 格式 為提示骨架
用動詞為主語,引導 AI 行動
鼓勵 AI 反問細節,加強精準度
避免過於簡短的提示詞,適度增加字數與條件
只要掌握這套公式與技巧,你的 AI 提示力可能真的能提升 80% 或以上。試著用它設計你的下個提示詞吧!
https://gemini.google.com
by Rain Chu 9 月 21, 2025 | AI , Prompt , 程式開發 , 繪圖
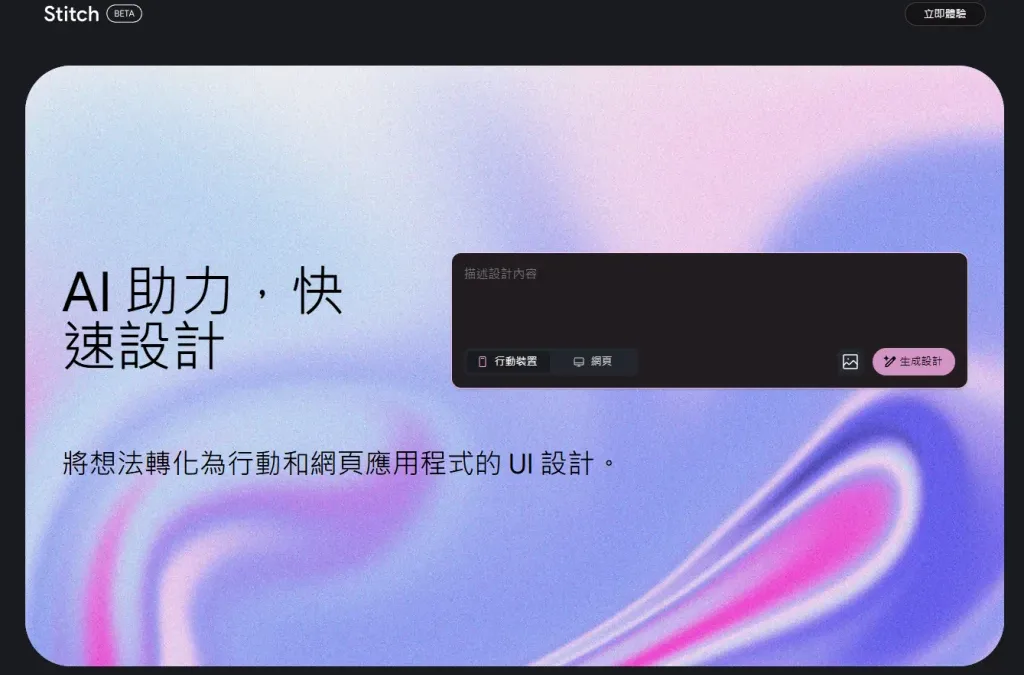
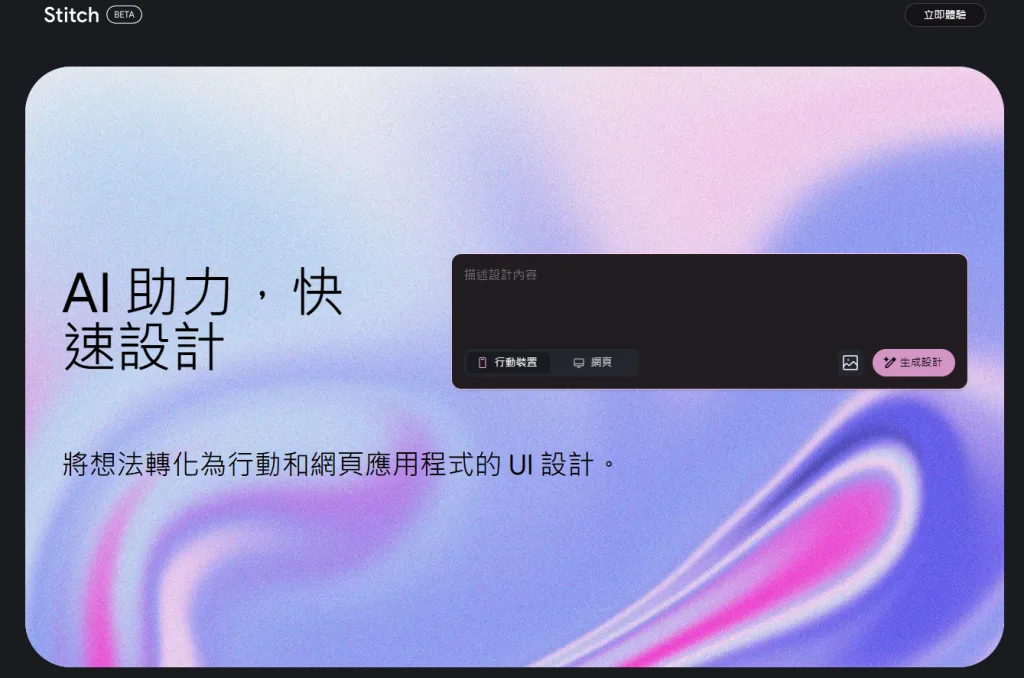
Google I/O 2025 上,Google 推出了名為 Stitch 的全新 AI 工具,目標是用文字或圖片提示(prompt / image prompt)快速生成網頁與 App 的 UI 設計與前端程式碼。Stitch 結合 Gemini 2.5 Pro 與 Flash 模型,並支持 Figma 匯出與 IDE 編輯,雖不是要取代專業設計工具如 Figma,但它能大幅簡化設計初期流程,是設計師與前端開發者的新利器。以下詳細介紹功能、優勢與使用心得。
功能特色與技術細節
從文字或圖片提示產生 UI + 前端程式碼
用戶可以用簡單的中英文描述(這真的是google模型的好處),例如「建立一個深色主題的行動 app 登入頁面,有按鈕和表單欄位」來生成設計。
或者上傳草圖、線框圖(wireframe)或其他 UI 的範例圖片來作為參考。Stitch 會根據這些提示產生對應設計。
整合 Gemini 2.5 Pro/Flash 模型 + 主題與設計流程工具
Stitch 是由 Google Labs 實驗性專案(experimental tool)之一,背後運行的是 Gemini 2.5 Pro 模型,這使得生成的 UI 設計在色彩、佈局與細節上更乾淨與現代感。
提供主題(theme)選擇、樣式(style)調整等交互功能;可視化設計流程內建 Canvas,可以看到完整頁面流程與介面切換模式。
輸出與匯出支持:HTML/CSS/Figma 等
Stitch 可以匯出為 HTML / CSS 程式碼,讓開發者能夠「拿來就用」於前端專案當中。
同時有「Paste to Figma」或「Copy to Figma」功能,可將設計匯入 Figma 進行進一步編輯。
Stitch 的定位與比較優勢
輔助工具,而非全面取代設計平台 :Stitch 的設計是為了縮短「從構思到原型 UI +程式碼」之間的落差,而不是完全取代專業設計師在 Figma、Sketch、Adobe XD 等工具中的工作。設計師仍可用這些工具做精細調整。速度與效率 :使用 Stitch 生成 UI 設計/前端程式碼所需時間比從零開始設計加寫碼快很多,對於初期原型與快速驗證需求特別有用。可訪問性 :Stitch 在 Google Labs 平台上可用,用戶界面相對友好,降低新手與非設計背景者的進入門檻。
限制與要注意的地方
雖然 Stitch 支持匯出至 Figma,但某些情況(如從上傳圖片/草圖的模式)之下,Figma 匯出功能尚未全功能完善。
設計細節(例如文字對齊、某些複雜元件組件化)有時候不完美,需要人工修正。
現階段仍為實驗性/預覽模式(experimental / Labs),可能在某些瀏覽器支援或功能穩定性上有差異。
使用流程簡易指南
前往 Stitch 官方網站 (stitch.withgoogle.com)並登入 Google 帳號。
選擇撰寫 prompt 或上傳參考圖片/草圖/線框圖。描述顏色、風格、佈局等細節。
等待 Stitch 生成 UI 設計與初步程式碼(HTML/CSS)。
若要匯出至 Figma,可使用「Copy to Figma / Paste to Figma」功能以便進一步編輯。
若為開發者,可直接取出 HTML/CSS 並嵌入 IDE 或網頁專案中。
Google Stitch 的收費/使用限額情況
從目前公開資訊來看,Google Stitch 屬於 Google Labs 的實驗性工具(beta 或公測階段),目前是免費使用 ,但有一些使用次數與模式上的限額/差異。下面是具體情況:
模式 免費與否 每月生成次數限額 Standard Mode(Flash 模式) 免費 每帳號每月約 350 次生成 │ 適合一般快速原型與草圖生成,可匯出 Figma 或 Code。 Experimental Mode(實驗/Pro 模式) 免費 每帳號每月約 50 次生成 │ 使用更強的 Gemini 2.5 Pro 模型;目前部分功能(如匯出 Figma)或效能有些限制。
參考資料
VIDEO
by Rain Chu 3 月 18, 2025 | AI , Chat , Prompt , Tool
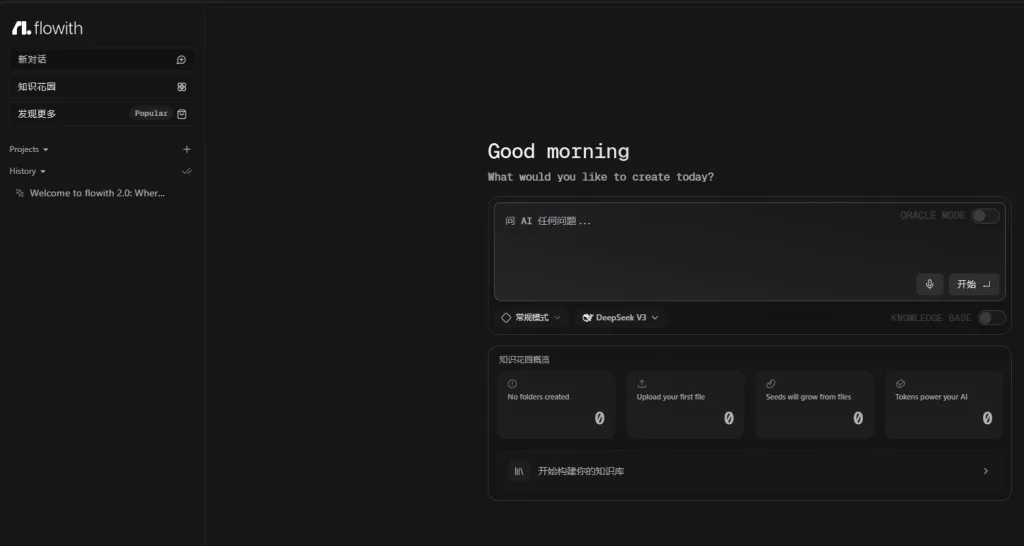
Flowith 最近正迅速崛起,成為超越 Manus 的最強 AI 自動化工具。它不僅免費且無需邀請碼,還具備強大的 ORACLE 模式、自主知識花園創建等功能,為用戶提供無與倫比的 AI 互動體驗。
Flowith 的主要特色
1. 免費使用,無需邀請碼
與其他需要邀請碼的 AI 工具不同,Flowith 完全免費,任何人都可以立即註冊並使用,無需等待或邀請碼。
2. ORACLE 模式:自動化完成文件、簡報製作
Flowith 的 ORACLE 模式是一項突破性的功能,允許數十個甚至數百個 AI 代理同時為您工作,無需手動搭建工作流。這使得複雜的數據收集和分析任務變得輕而易舉,並能自動生成文件和簡報等。
3. 知識花園:創建並變現知識庫
Flowith 的「知識花園」功能讓您可以將自己的知識資源組織成系統化的知識庫,並可選擇對外分享或收費,實現知識變現。
4. 邀請鏈接:獲得額外免費對話次數
透過邀請朋友加入 Flowith,您可以獲得額外的 500 次免費對話次數,提升使用體驗。
邀請碼如下:
https://flowith.io/invitation?code=WPS1WR
如何使用 Flowith
註冊帳號 :訪問 Flowith 官方網站 ,點擊「註冊」並填寫相關資訊。探索 ORACLE 模式 :在主介面中,選擇 ORACLE 模式,輸入您的需求,系統將自動規劃並執行相關任務。 https://doc.flowith.io 建立知識花園 :上傳您的資料或文件,Flowith 會自動將其拆分為知識種子,幫助您構建個人知識庫。
參考資料
by Rain Chu 2 月 23, 2025 | Agent , AI , Chat , Prompt
硅基流動 (SiliconFlow)是一家致力於加速通用人工智慧(AGI)普惠化的公司,主要可以讓生成式人工智慧惠及開發者和終端使用者使用,最近,硅基流動與華為雲合作,推出了基於昇騰雲的 DeepSeek R1 和 V3 推理服務 ,為使用者提供高效、穩定的 AI 模型推理體驗。
DeepSeek R1 與硅基流動的合作 DeepSeek R1 是一款由強化學習驅動的推理模型,旨在解決模型生成內容的重複性和可讀性問題。在強化學習之前,DeepSeek R1 引入了冷啟動數據,進一步優化推理效能。然而,近期由於 DeepSeek 官方伺服器頻繁出現繁忙狀態 ,許多使用者在使用時受到限制。
為了解決這一問題,硅基流動與華為雲合作,將 DeepSeek R1 部署在基於昇騰的計算平台上 ,提供更 穩定、高速 的 DeepSeek R1 API 服務 ,讓使用者可以在更低的成本下獲得優質的 AI 推理服務。
如何使用 DeepSeek R1 API 使用者可以透過 註冊硅基流動平台 ,取得 API 金鑰,並將 DeepSeek R1 模型整合到各種應用之中。硅基流動提供了詳細的 技術文件與教學 ,幫助開發者快速上手,充分發揮 DeepSeek R1 的強大功能。
硅基流動透過與華為雲的合作,成功解決了 DeepSeek R1 在使用過程中的伺服器繁忙問題 ,為開發者和終端使用者提供了一個 高效、穩定的 AI 模型推理平台 。這不僅展現了 硅基流動的技術優勢 ,也體現了其在推動 AGI 普惠化 方面的努力。
API使用



近期留言