by Rain Chu 4 月 18, 2026 | AI , 語音合成
🧠 什麼是 VoxCPM?
VoxCPM 是由 OpenBMB 推出的新一代語音生成模型,主打:
👉 超低樣本聲音克隆(只需5秒) 完全本地運行(無需雲端) 多語言+多方言支持(30+)
簡單講一句話:
👉 它就是「語音界的 Stable Diffusion」
🚀 核心特色
🎙️ 1️⃣ 極致聲音複製(5秒搞定)
只需要一段短短語音(約5秒):
👉 幾乎達到「真人等級」
🎚️ 2️⃣ 專業播音員等級輸出
生成語音具備:
清晰度高(接近錄音室品質)
節奏自然
可長文本生成(Podcast / 有聲書)
👉 可直接商用(需注意授權)
🌏 3️⃣ 多語言+方言(重點)
支援:
中文(普通話)
台語(閩南語)
廣東話
四川話
英文 / 日文 / 韓文 等
👉 這點直接屌打很多 TTS 工具
🔒 4️⃣ 完全本地運行
不像:
ElevenLabs(雲端)
PlayHT(雲端)
VoxCPM:
✅ 無需上傳聲音
⚙️ 安裝教學(本地部署)
📦 硬體需求(建議)
GPU:RTX 3060 以上(最佳)
RAM:16GB+
OS:Ubuntu / Windows(WSL)
🧩 Step 1:下載專案
官方 Repo👇
🧩 Step 2:安裝環境
🧩 Step 3:下載模型
依照 repo 指示下載:
🧩 Step 4:執行推理
🧩 Step 5:使用WEBUI
# WebUI
python lora_ft_webui.py # http://localhost:7860 🧠 進階玩法(你可以做什麼)
💰 商業應用
AI 配音 SaaS
有聲書生成平台
YouTube 自動旁白
🧪 高階玩法
聲音角色庫(多人 voice profile)
Telegram 語音 Bot
客製客服語音
⚠️ 注意事項(很重要)
⚙️ 技術限制
🆚 VoxCPM vs 其他 TTS
工具 本地 聲音克隆 方言 成本 VoxCPM ✅ ✅ ✅ 免費 ElevenLabs ❌ ✅ 普通 $$$ PlayHT ❌ ✅ 普通 $$$
👉 結論:本地部署 = VoxCPM 完勝
參考資料
官方網站
移除背景聲音工具(UVR5)
by Rain Chu 5 月 12, 2025 | AI , 語音合成
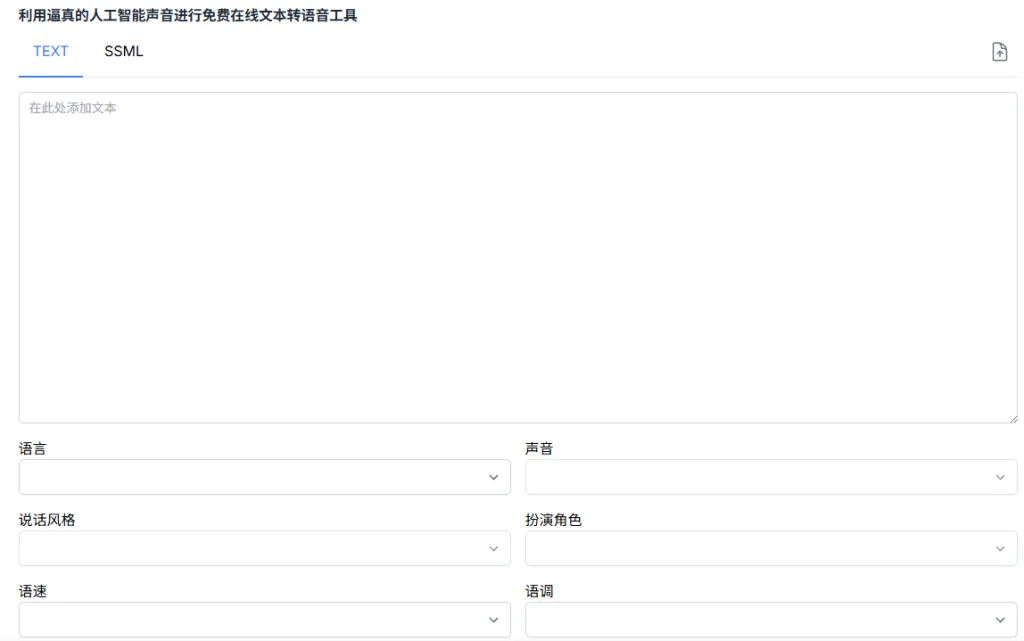
Speech Synthesis 是一款免費的線上文字轉語音工具,支援超過 40 種語言和數百種語音選擇,並可自訂語調(SSML)、節奏與語氣,讓語音更貼近您的需求。
🔑 主要特色
多語言支援 :涵蓋繁體中文、粵語、英語、日語等多種語言,滿足全球用戶的需求。多樣化語音選擇 :提供數百種語音,包括不同性別、年齡和口音的選項。自訂語音參數 :可調整語速(如 x-slow、slow、medium、fast、x-fast)、語調和音量,打造個性化的語音輸出。支援 SSML :支援語音合成標記語言(SSML),讓進階用戶能夠更精細地控制語音輸出。多種音訊格式 :可選擇 MP3、WAV 等格式,並提供不同的音質設定,如 16kHz-128k、24kHz-160k、48kHz-192k。
🧪 使用方式
前往 Speech Synthesis 官方網站 。
在「TEXT」欄位輸入您要轉換的文字,或上傳文件。
選擇語言和語音,並調整語速、語調和音量等參數。
點擊「合成語音」按鈕,系統將生成語音檔案。
試聽並下載生成的語音檔案。
🔍 與其他熱門 TTS 工具的比較
工具名稱 語言支援數 語音選擇數 自訂參數 支援 SSML 價格 Speech Synthesis 40+ 數百種 ✅ ✅ 免費 TTSMaker 100+ 600+ ✅ ✅ 免費 Google Text-to-Speech 30+ 220+ ✅ ✅ 免費(有使用限制) MyEdit 26+ 多種 ✅ ❌ 免費
參考資料
by rainchu 12 月 19, 2024 | AI , 影片製作 , 語音合成 , 音樂
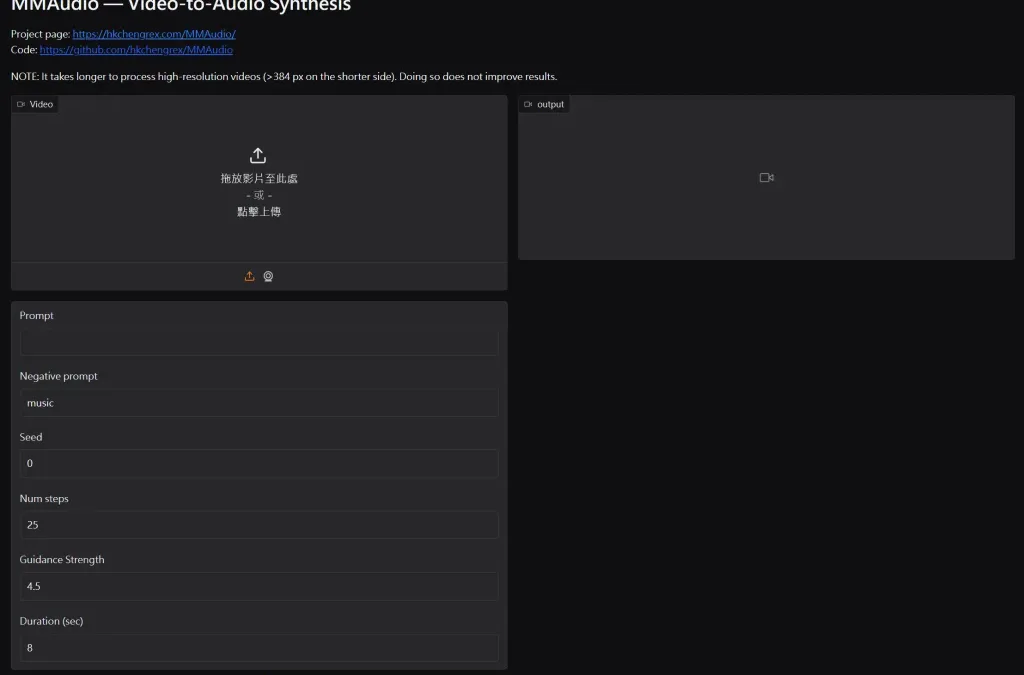
MMAudio 是一款開源的多模態影片轉音訊工具,透過多模態聯合訓練技術,可以將高品質的影片與音訊合成。該專案由伊利諾大學厄巴納-香檳分校、Sony AI 及 Sony 集團公司合作開發,適用於影片配音、虛擬角色語音等多媒體創作場景。
主要特色:
多模態聯合訓練: MMAudio 採用多模態聯合訓練方法,能夠同時處理影片和文字輸入,生成與內容同步的音訊。高品質音訊合成: 透過先進的模型架構,MMAudio 能夠生成高品質且自然的音訊,適用於各類應用場景。同步模組: MMAudio 的同步模組確保生成的音訊與影片畫面精確匹配,實現高度同步。
適用場景:
影片配音: 自動為無聲 影片生成對應的音訊,提升影片的可觀賞性。虛擬角色語音生成: 為虛擬角色生成符合其動作和表情的語音,增強互動性。多媒體內容創作: 協助創作者快速為視覺內容添加音訊,豐富作品表現力。
技術原理: MMAudio 基於深度學習技術,特別是神經網路,理解和生成音訊資料。模型能夠處理影片和文字輸入,透過深度學習網路提取特徵,進行音訊合成。在訓練時,模型考慮音訊、影片和文字資料,使生成的音訊能夠與影片和文字內容相匹配。透過同步模組,確保音訊輸出與影片畫面或文字描述的時間軸完全對應,實現同步。
使用方法: MMAudio 提供命令列介面和 Gradio 介面,使用者可以根據需求選擇使用。在命令列中,使用者可以透過指定影片路徑和文字提示,生成對應的音訊。Gradio 介面則提供了更友善的使用者介面,支援影片到音訊和文字到音訊的合成。
已知限制: 目前,MMAudio 存在以下限制:
有時會生成不清晰的語音或背景音樂。
對某些陌生概念的處理不夠理想。
相關資源:
by Rain Chu 10 月 20, 2024 | AI , Chat , 語音合成
by Rain Chu 9 月 2, 2024 | AI , 語音合成
免費且超強大的 AI TTS,文字轉語音模型+工具,有許多語氣的控制,也可以很精準的寫程式控制效果,是RD眼中好用的Local端開源的TTS
特色說明
1.大規模的數據:10萬小時的訓練資料,現在開源的是4小時的版本
2.專用設計:專門對於對話情境、視頻介紹的情境所設計的模型
3.開源特性:可以很簡單的整合到你的WEB中
4.支持語氣:oral, laugh, break
安裝前準備
python 3.10
CUDA
GIT
gradio
安裝說明
github 複製
git clone https://github.com/2noise/ChatTTS
cd ChatTTS 安裝依賴
pip install --upgrade -r requirements.txt 執行 webui
python examples/web/webui.py 利用 CLI
python examples/cmd/run.py "Your text 1." "Your text 2." 要整合在 python 程式碼中,可以安裝 PyPI
pip install ChatTTS
pip install git+https://github.com/2noise/ChatTTS
pip install -e . 整合程式碼
###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
"""
In some versions of torchaudio, the first line works but in other versions, so does the second line.
"""
try:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
except:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]), 24000) V3版本
VIDEO
音色庫
https://www.modelscope.cn/studios/ttwwwaa/chattts_speaker
注意事項
1.是否要使用CUDA,需要的話,記得安裝依賴
2.要用CUDA,怎選擇 Linux 平台,相容性比較好
3.Python最好用3.10版本,並且用conda
直接使用
https://chattts.com
colab
modalScope
參考資源
ChatTTS Github
ChatTTS官網
Chat TTS UI
Chat TTS 翻譯
MediaFire一件安裝包
Lobe Chat UI-有plugin,多模態的AI CHAT UI – 雨 (rain.tips)
AI Tools – AI工具大全(總整理) – 雨 (rain.tips)
搭配 Free AI 產圖Flux
VIDEO
VIDEO
VIDEO
by Rain Chu 6 月 27, 2024 | AI , 人臉辨識 , 影片製作 , 語音合成
主要功能介紹:
語音動畫同步 :用戶只需上傳一張照片及一段WAV格式的英語語音,Hallo AI就能使照片中的人物按語音內容進行動作,包括說話和唱歌。動作自然流暢 :結合精確的面部識別和動作捕捉技術,保證人物動作的自然流暢,令人印象深刻。
技術框架:
音頻處理 :使用Kim_Vocal_2 MDX-Net的vocal removal模型分離語音。面部分析 :透過insightface進行2D和3D的臉部分析。面部標記 :利用mediapipe的面部檢測和mesh模型進行精確標記。動作模組 :AnimateDiff的動作模組為動作生成提供支持。影像生成 :StableDiffusion V1.5和sd-vae-ft-mse模型協同工作,用於生成和調整圖像細節。聲音向量化 :Facebook的wav2vec模型將WAV音頻轉換為向量數據。
安裝方法
盡量採用 Linux 平台,我這邊測試成功的有 Ubuntu 20 WSL 版本,就可以簡單三個步驟,部過前提要記得先安裝好 WSL CUDA 支援
1.建立虛擬環境
conda create -n hallo python=3.10
conda activate hallo 2.安裝相關的依賴
pip install -r requirements.txt
pip install . 3.要有 ffmpeg 支援
4.測試與驗證
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav 最近更新:
在🤗Huggingface空間克隆了一個Gradio演示。
新增Windows版本、ComfyUI界面、WebUI和Docker模板。
參考資料
Hallo GitHub
Hallo Model
大神開發的Windows介面
Hallo 線上版本
Hallo Docker版
影片跳舞合成


近期留言