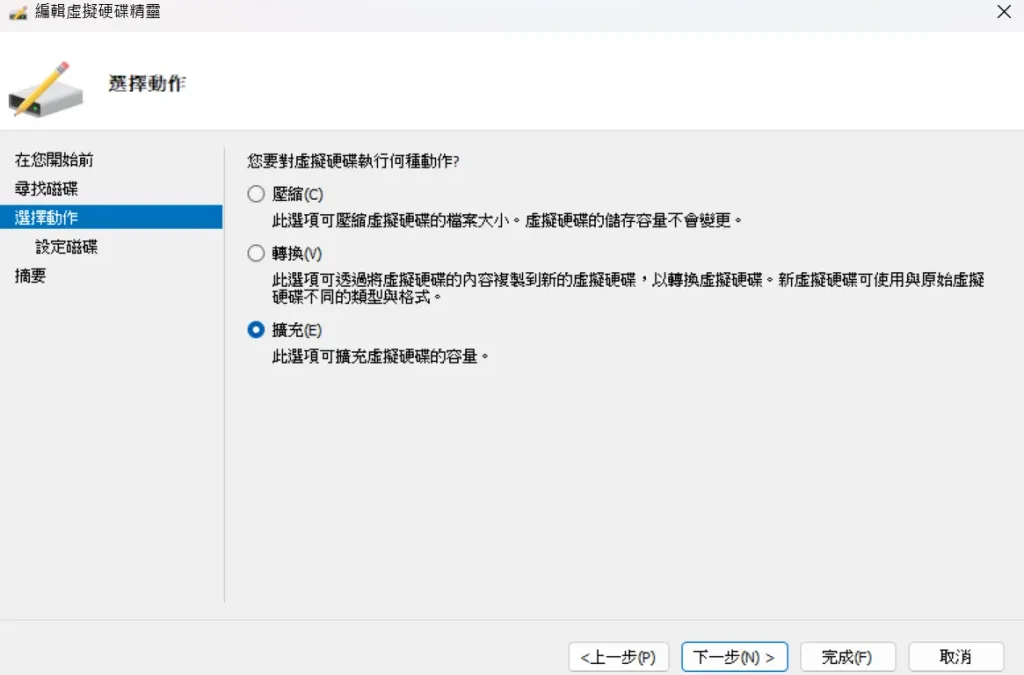
Ubumtu VM 動態擴展根目錄(Hyper-V適用)
當你使用VM的時候,常常會預估錯誤硬碟的大小,預留太小的空間,要增加空間可以用以下的方法
1.在 VM 管理中先增大硬碟空間
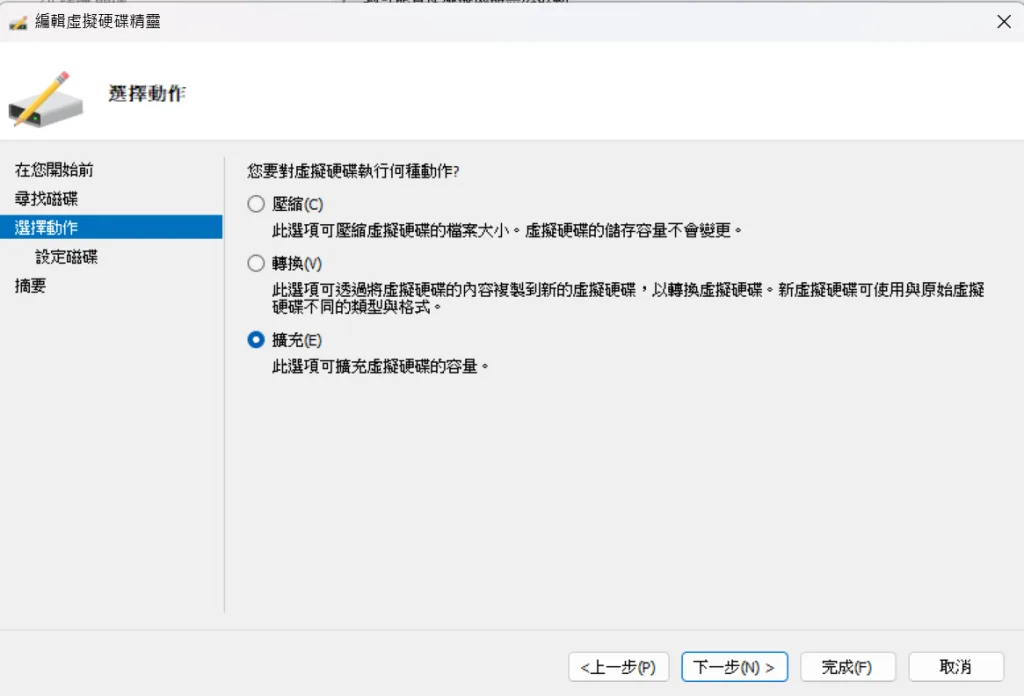
2.確認分割區大小
3.下載擴展工具
sudo apt update && sudo apt install cloud-guest-utils -y
4.使用 growpart 將硬碟擴展大最大空間
sudo resize2fs /dev/sda1
當你使用VM的時候,常常會預估錯誤硬碟的大小,預留太小的空間,要增加空間可以用以下的方法
sudo apt update && sudo apt install cloud-guest-utils -y
sudo resize2fs /dev/sda1
Wubuntu(全名為 Windows Ubuntu)是一款基於 Ubuntu 的作業系統,在提供與 Microsoft Windows 相似的主題和工具,但不需要高規格的系統要求,並且可以在 linux 環境下使用 exe 檔案和 Android 應用,也可以支援 Nvidia 顯卡和繁體中文。
Wubuntu 的最新版本基於 Kubuntu 24.04.1 LTS,代號為「Winux」或「Windows Theme Over Linux」。
這是一組工具,提供類似於 Windows 系統的控制面板和設定,以及增強的 Windows 和 Android 子系統支援,還可以上網用 OneDrive 和 Google Drive。
使用者可以透過官方網站下載 Wubuntu 的最新版本,安裝檔案是 ISO 檔案,是可以用 VM 安裝或是用 USB 隨身碟安裝。
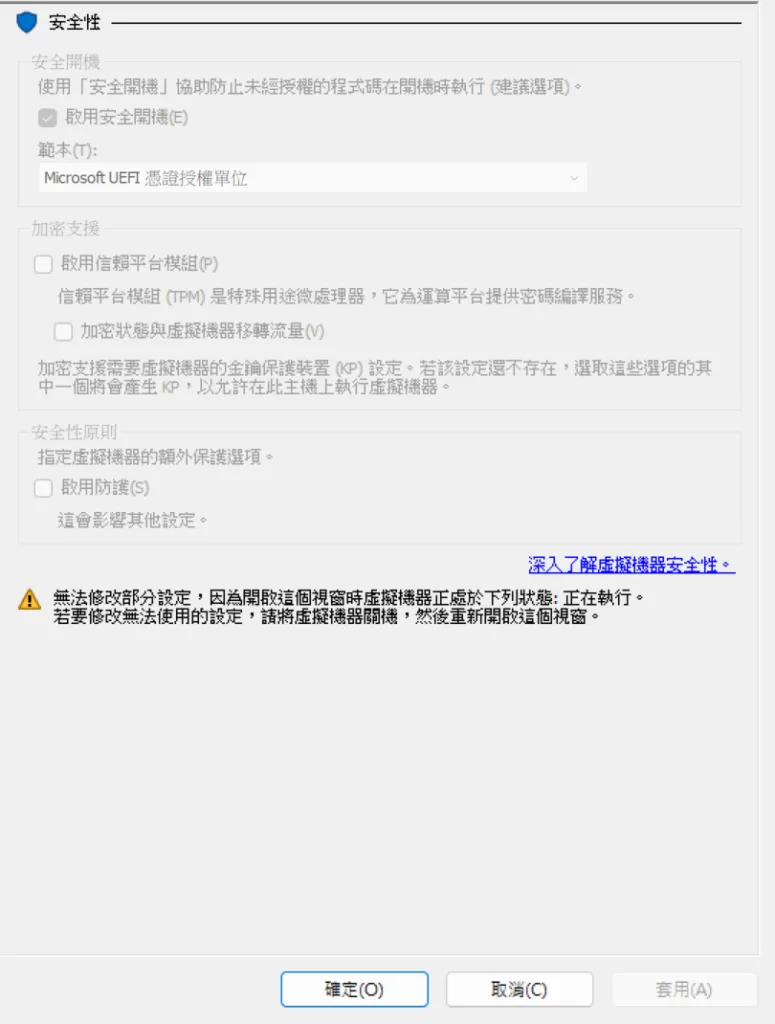
開機的安全性選項要選擇 Microsoft UEFI
Wubuntu 可能涉及一些版權和商標問題,以及使用者資料處理方面的爭議。
今天來實做一個備份任務,要在 Ubuntu 上設定每日凌晨 4:00 自動備份 MariaDB 中的所有資料庫,我們可以使用 cron 和一個自定義的 Shell 腳本來完成這個任務,以下是詳細步驟和代碼:
先創建一個備份 Shell Script,這個腳本將備份所有資料庫並分開儲存。
1.在 /usr/local/bin 目錄下創建一個新的 Shell 腳本:
sudo nano /usr/local/bin/backup_mariadb.sh
2. Script 的內容指令如下
#!/bin/bash
# 設定資料庫的用戶名和密碼
DB_USER="your_db_user"
DB_PASSWORD="your_db_password"
DB_HOST="10.0.0.1"
# 設定備份儲存目錄
BACKUP_DIR="/path/to/backup/dir"
mkdir -p $BACKUP_DIR
# 獲取當前日期和時間
CURRENT_DATE=$(date +%Y-%m-%d-%H-%M-%S)
# 獲取所有資料庫名稱
DATABASES=$(mysql -h$DB_HOST -u$DB_USER -p$DB_PASSWORD -e "SHOW DATABASES;" | tr -d "| " | grep -v Database)
# 備份每個資料庫
for DB in $DATABASES; do
if [[ "$DB" != "information_schema" && "$DB" != "performance_schema" && "$DB" != "mysql" && "$DB" != "sys" ]]; then
BACKUP_FILE="$BACKUP_DIR/$CURRENT_DATE-$DB.sql"
mysqldump -h$DB_HOST -u$DB_USER -p$DB_PASSWORD --databases $DB > $BACKUP_FILE
fi
done其中要修改的有
3.將 .sh 變成可執行擋
sudo chmod +x /usr/local/bin/backup_mariadb.sh
1.打開 cron
crontab -e
2.加入設定內容,要注意的是實間是主機時間,通常主機是 UTC+0 的時區,要注意轉換,才會是正確的當地時間,可以參考這篇
0 4 * * * /usr/local/bin/backup_mariadb.sh
這樣就會在每天的早上四點去備份資料庫了
程式碼區塊要改成下面這一個
# 備份每個資料庫並壓縮
for DB in $DATABASES; do
if [[ "$DB" != "information_schema" && "$DB" != "performance_schema" && "$DB" != "mysql" && "$DB" != "sys" ]]; then
BACKUP_FILE="$BACKUP_DIR/$CURRENT_DATE-$DB.sql"
ZIP_FILE="$BACKUP_DIR/$CURRENT_DATE-$DB.zip"
mysqldump -h$DB_HOST -u$DB_USER -p$DB_PASSWORD --databases $DB > $BACKUP_FILE
zip $ZIP_FILE $BACKUP_FILE
rm $BACKUP_FILE
fi
done可以利用下面的指令,放在程式碼的最後面
# 刪除兩天前的備份文件
find $BACKUP_DIR -type f -name "*.zip" -mtime +2 -exec rm {} \;需要改時間的話,只要修正 -mtime +2 ,把+2改成自己需要的時間
https://help.ubuntu.com/community/CronHowto
預設在你的windows下的 Linux 系統會取得一個 IP,通常是172.19開頭的,這是因為用的是 Hyper-V 架構導致的,變成你再 WSL 內開發的服務都很難對外,但其實只要利用 windows 內建的 Netsh interface portproxy 即可
透過 netsh interface portproxy 來作設定
netsh interface portproxy add v4tov4 listenport=<yourPortToForward> listenaddress=0.0.0.0 connectport=<yourPortToConnectToInWSL> connectaddress=(wsl hostname) -I)
其中
listenport 和 connectport 通常設定一樣,也就是你的服務的 port
listenaddress=0.0.0.0 (固定)
connectaddress 要記得是填入你 ubuntu 的IP喔,可以透過 wsl hostname -I 找出 IP
wsl hostname -I
假設你有一個服務是運行在 port 3001,ubuntu 的 ip 172.19.227.52,修改後的你指令應該要長成
netsh interface portproxy add v4tov4 listenport=3001 listenaddress=0.0.0.0 connectport=3001 connectaddress=172.19.227.5
最後記得要打開對應的防火牆的設定喔
關於 netsh 的控制指令說明
顯示目前所有的設定
netsh interface portproxy show all
重新設定 netsh
netsh interface portproxy reset
https://learn.microsoft.com/zh-tw/windows/wsl/networking
AnythingLLM是一款全功能的應用程序,支持使用商業或開源的大語言模型(LLM)和向量數據庫建構私有ChatGPT。用戶可以在本地或遠端運行該系統,並利用已有文檔進行智能對話。此應用將文檔分類至稱為工作區的容器中,確保不同工作區間的資料隔離,保持清晰的上下文管理。
特點:多用戶支持、權限管理、內置智能代理(可執行網頁瀏覽、代碼運行等功能)、可嵌入到網站的聊天窗口、多種文檔格式支持、向量數據庫的簡易管理界面、聊天和查詢兩種對話模式、引用文檔內容的展示,以及完善的API支持客戶端定制整合。此外,該系統支持100%雲端部署,Docker部署,且在處理超大文檔時效率高,成本低。
注意,以下要用 linux 平台安裝,windows 用戶可以用 WSL,推薦用 Ubuntu OS
在自己的 home 目錄下,到 GitHub 中下載原始碼
git clone https://github.com/Mintplex-Labs/anything-llm.git
利用 yarn 作設定資源
cd anything-llm yarn setup
把環境變數建立起來,後端主機是 NodeJS express
cp server/.env.example server/.env nano server/.env
密文需要最少12位的字元,檔案的存放路徑也記得改成自己的
JWT_SECRET="my-random-string-for-seeding" STORAGE_DIR="/your/absolute/path/to/server/storage"
前端的環境變數,先把/api打開即可
# VITE_API_BASE='http://localhost:3001/api' # Use this URL when developing locally # VITE_API_BASE="https://$CODESPACE_NAME-3001.$GITHUB_CODESPACES_PORT_FORWARDING_DOMAIN/api" # for Github Codespaces VITE_API_BASE='/api' # Use this URL deploying on non-localhost address OR in docker.
如果你在設定的時候,遇到更新請求,可以跟我著我下面的方法作
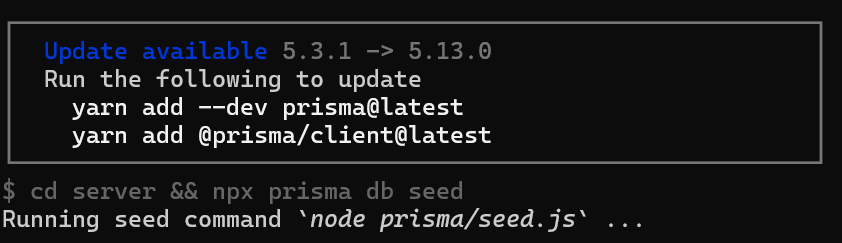
把 prisma 更新好
yarn add --dev prisma@latest yarn add @prisma/client@latest
先編譯前端程式碼,前端是由 viteJS + React
cd frontend && yarn build
將編譯好的資料放到 server 的目錄下
cp -R frontend/dist/* server/public/
選項,如果需要用到本地端的 LLM 模型,就把 llama-cpp 下載下來
cd server && npx --no node-llama-cpp download
把資料庫建立好
cd server && npx prisma generate --schema=./prisma/schema.prisma cd server && npx prisma migrate deploy --schema=./prisma/schema.prisma
Server端是用來處理 api 以及進行向量資料庫的管理以及跟 LLM 交互
Collector 是一個 NodeJS express server,用來作UI處理和解析文檔
cd server && NODE_ENV=production node index.js & cd collector && NODE_ENV=production node index.js &
現在 anything llm 更新速度超快,把這一段指令碼複製起來,方便未來作更新的動作
#!/bin/bash cd $HOME/anything-llm &&\ git checkout . &&\ git pull origin master &&\ echo "HEAD pulled to commit $(git log -1 --pretty=format:"%h" | tail -n 1)" echo "Freezing current ENVs" curl -I "http://localhost:3001/api/env-dump" | head -n 1|cut -d$' ' -f2 echo "Rebuilding Frontend" cd $HOME/anything-llm/frontend && yarn && yarn build && cd $HOME/anything-llm echo "Copying to Sever Public" rm -rf server/public cp -r frontend/dist server/public echo "Killing node processes" pkill node echo "Installing collector dependencies" cd $HOME/anything-llm/collector && yarn echo "Installing server dependencies & running migrations" cd $HOME/anything-llm/server && yarn cd $HOME/anything-llm/server && npx prisma migrate deploy --schema=./prisma/schema.prisma cd $HOME/anything-llm/server && npx prisma generate echo "Booting up services." truncate -s 0 /logs/server.log # Or any other log file location. truncate -s 0 /logs/collector.log cd $HOME/anything-llm/server (NODE_ENV=production node index.js) &> /logs/server.log & cd $HOME/anything-llm/collector (NODE_ENV=production node index.js) &> /logs/collector.log &

wpa_cli 是一個用於與 wpa_supplicant 交互的命令行界面工具,當然也支持在 command line 下直接使用命令控制 WIFI,可以用來管理無線網絡接口的設定和運行狀態。這個工具非常強大,支持多種操作,如掃描無線網絡、連接到網絡、變更設定等,而我都用python 透過 wpa_cli 來控制 WIFI。
打開終端,並且記得要用 root 權限來執行 wpa_cli
sudo wpa_cli -i wlan1 scan sleep 5 # 給予一些時間來完成掃描 sudo wpa_cli -i wlan1 scan_results
回應如下圖
利用 ssid 和 paswword 來連線到一個已知的無線網路上,可以將下面的指令編寫成 wpa_cli_add_network.sh ,並且執行她,也可以直接使用,執行後取得的 network id 通常是一個 int 的數字,把她記起來,之後就可以透過這個 network id 來連接網路,和斷開網路
# 添加新的網絡配置
network_id=$(wpa_cli -i wlan1 add_network | awk '{print $NF}')
# 設置SSID和密碼
wpa_cli -i wlan1 set_network $network_id ssid '"你的SSID"'
wpa_cli -i wlan1 set_network $network_id psk '"你的密碼"'
# 啟用該網絡
wpa_cli -i wlan1 enable_network $network_id
# 保存配置
wpa_cli -i wlan1 save_config# 重新連線 wpa_cli -i wlan1 reconnect #斷開連線 wpa_cli -i wlan1 disconnect
wpa_cli -i wlan1 remove_network $network_id
wpa_cli -i wlan1 status
得到的輸出通常如下
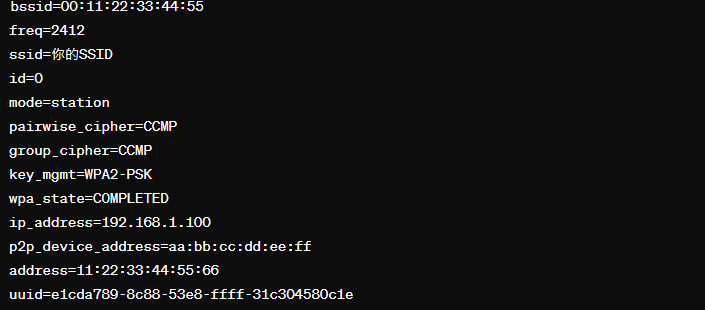
其中,檢查是否有連線成功,可以看 wpa_state 是否為 COMPLETED
sudo wpa_cli -i wlan1 list_networks
輸出如下
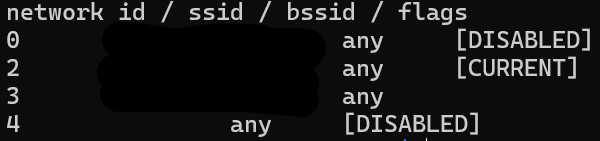
可以用 flags CURRENT 來檢查現在是連線到那一個 network ,也可以取得 network id ,並且用他來連線
近期留言