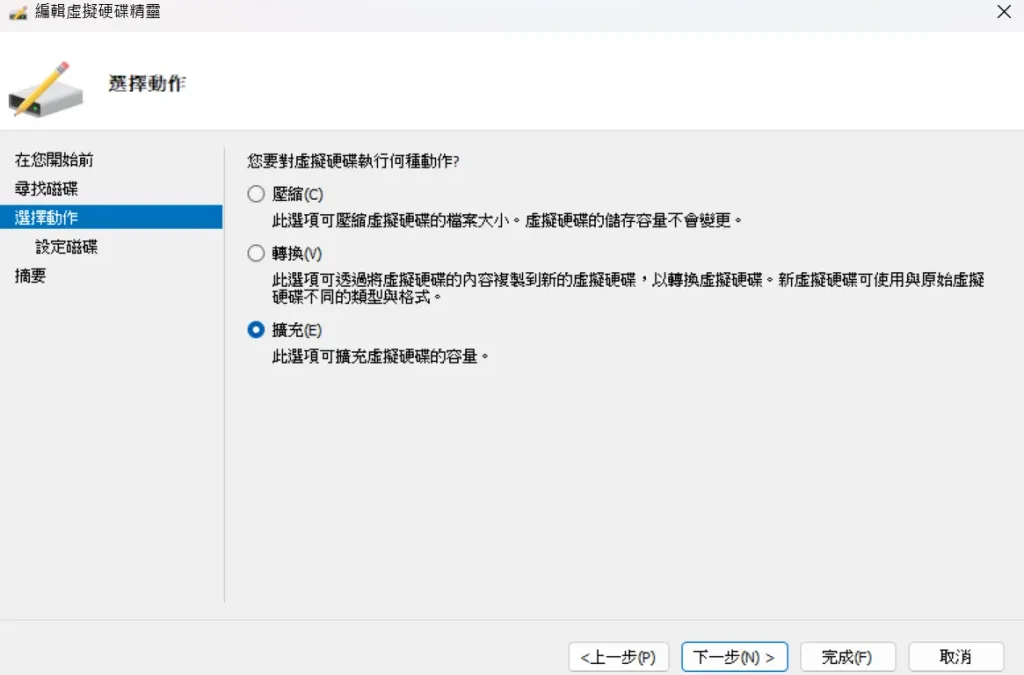
Ubumtu VM 動態擴展根目錄(Hyper-V適用)
當你使用VM的時候,常常會預估錯誤硬碟的大小,預留太小的空間,要增加空間可以用以下的方法
1.在 VM 管理中先增大硬碟空間
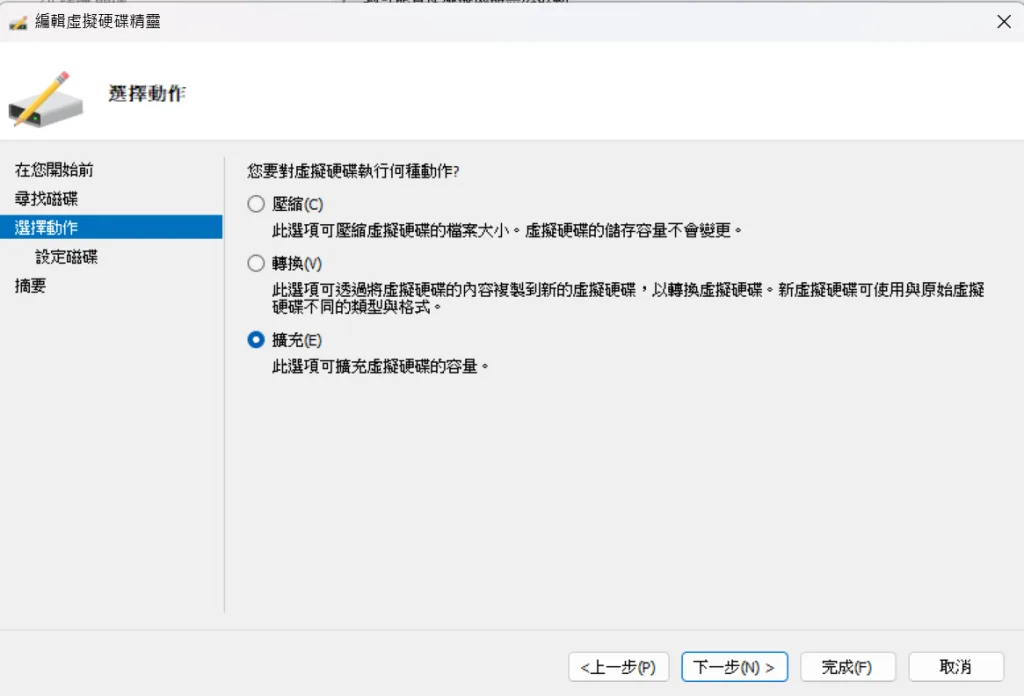
2.確認分割區大小
3.下載擴展工具
sudo apt update && sudo apt install cloud-guest-utils -y
4.使用 growpart 將硬碟擴展大最大空間
sudo resize2fs /dev/sda1
當你使用VM的時候,常常會預估錯誤硬碟的大小,預留太小的空間,要增加空間可以用以下的方法
sudo apt update && sudo apt install cloud-guest-utils -y
sudo resize2fs /dev/sda1

AMD於2024年7月推出了Amuse 2.0 Beta版本,這是一款專為AMD平台設計的AI創作工具,替 AMD CPU、GPU的用戶提供更簡便的AI圖像生成體驗。
Amuse 2.0的推薦配置包括:
目前只有Ryzen AI 300系列和更新驅動後的Ryzen 8000系列處理器支援AMD XDNA超分辨率技術。
到官網去下載 Amuse 2.0為單一可執行(EXE)檔案,無需額外的相依性,安裝過程簡單。首次啟動時,系統會自動偵測硬體配置,並自動設定最佳化參數。建議初次使用者選擇「平衡」設定,以在性能和品質之間取得良好平衡。
Portaly 一款由台灣團隊「真實引擎」開發的社群微型網站工具,可以協助創作者在數分鐘內建立專屬的 Link-in-Bio 頁面,整合 Facebook、Instagram、YouTube 與 Podcast 等多個平台的連結
Portaly 提供免費的基本方案,讓使用者可以建立功能完善的頁面。若需要更多進階功能,如無限區塊與分頁、自訂主題與配色、自訂網域、E-mail 名單收集等,則可選擇付費的頂級方案。
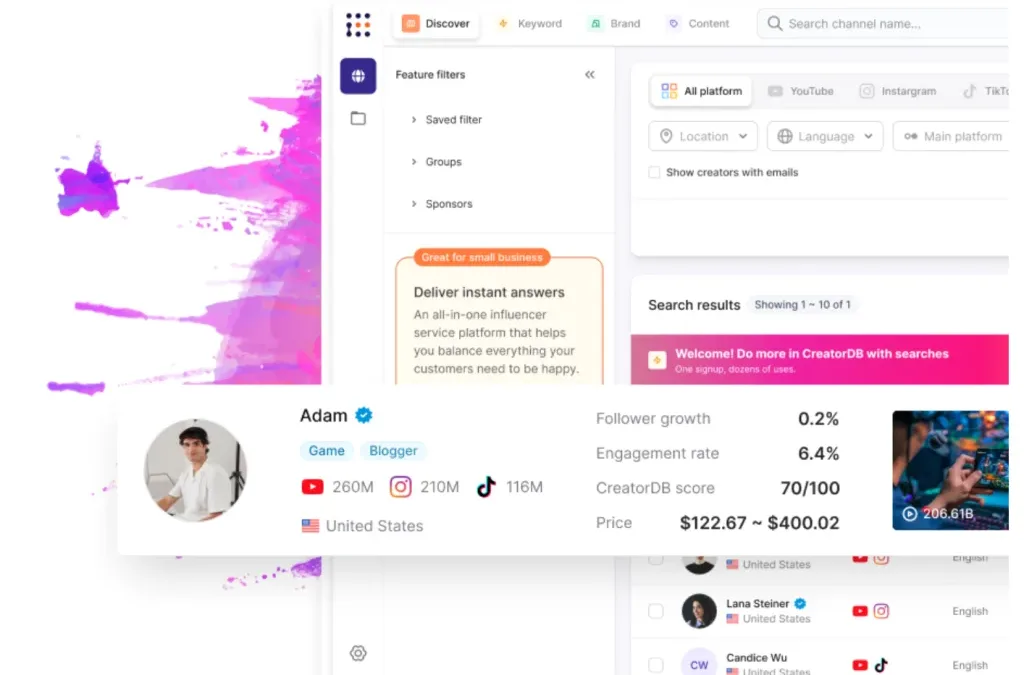
CreatorDB(https://www.creatordb.app/) 有 AI 大數據分析,為品牌和企業提供一站式服務,涵蓋找網紅、內容分析和社群洞察等功能,協助最大化行銷成效。

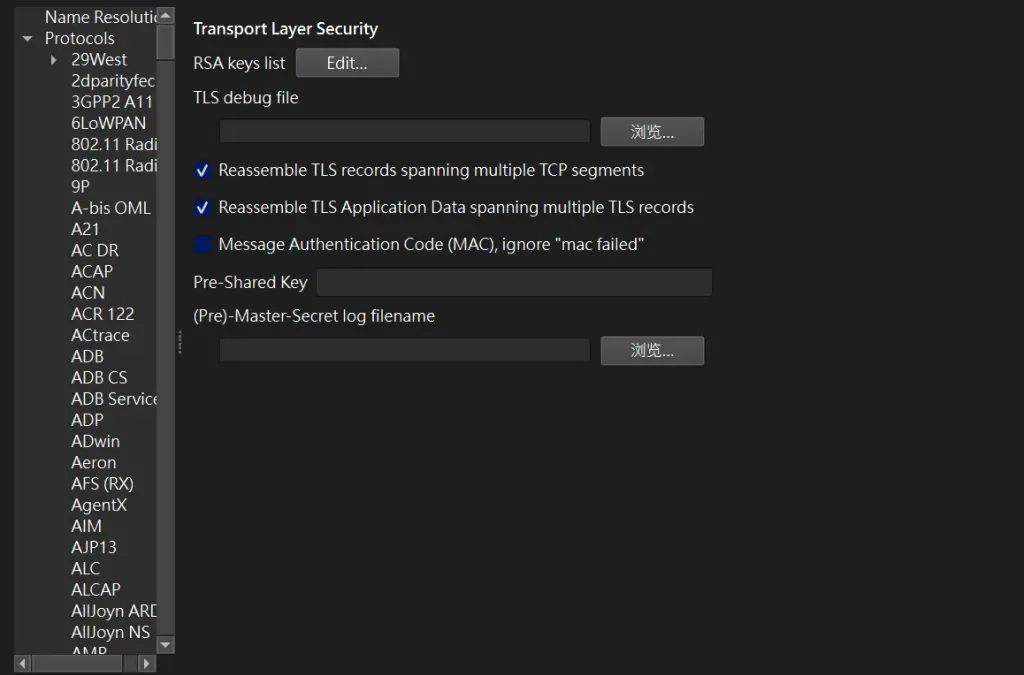
Wireshark 是一款功能強大的網絡協議分析工具,可以幫助我們深入了解網絡流量,在日常使用中,我們有時需要檢查 HTTPS 流量,這些流量通常是加密的,通過配置 Wireshark,我們可以抓取並解碼 SSL/TLS 的加密資訊。
首先,從 Wireshark 官方網站 下載適合您系統的安裝包,並完成安裝。安裝過程中,建議選擇安裝 WinPcap 或 Npcap,這是用於抓取網絡數據包的必要工具。
要讓瀏覽器記錄 SSL/TLS 的密鑰,我們需要設置環境變量。
SSLKEYLOGFILEC:\logsC:\logs 路徑下,會生成一個名為 sslkeylog.log 的文件。這個設置的作用是讓支持 SSLKEYLOGFILE 的應用程序(例如 Chrome)記錄密鑰到指定文件中。
接下來,我們需要將生成的密鑰文件導入 Wireshark,以便解碼 HTTPS 流量。
sslkeylog.log 文件的完整路徑,例如: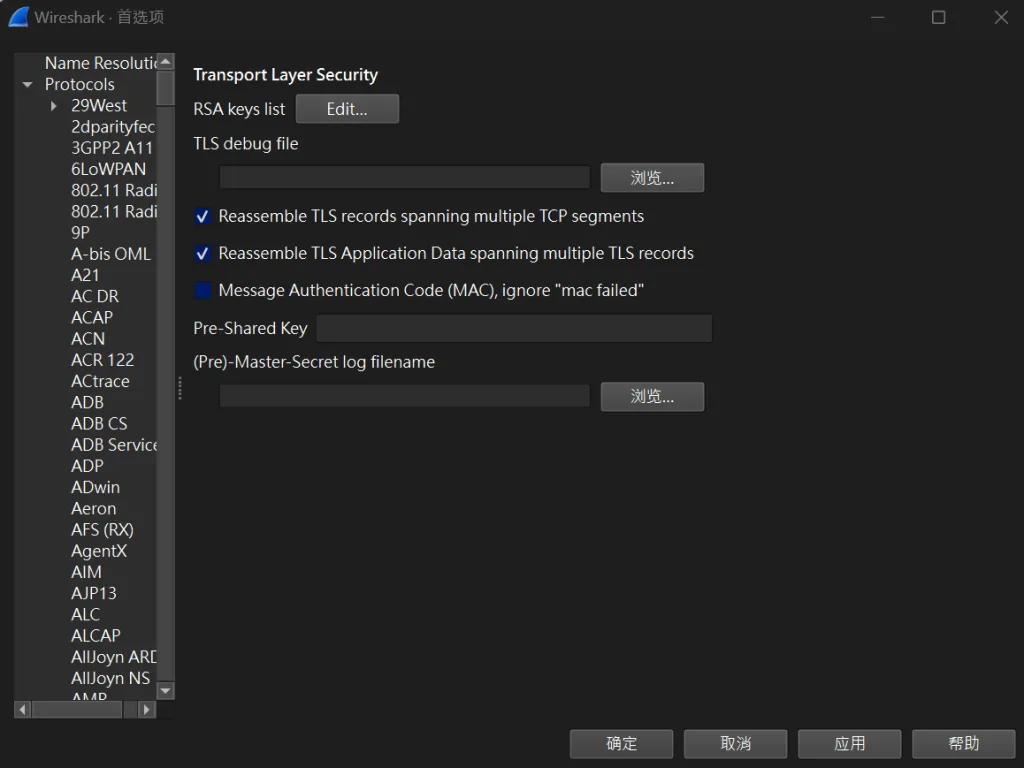
Ctrl+E)。Client Hello 或 Server Hello 消息。sslkeylog.log 自動解碼加密的數據流,您可以在「解碼」區域中看到未加密的數據內容。
近期留言