
by rainchu | 12 月 16, 2025 | AI, 人臉辨識
前言:為什麼需要專門的人臉辨識 YOLO?
在電腦視覺領域中,YOLO(You Only Look Once) 以「即時、快速、準確」聞名。然而,通用的物件偵測模型在面對「人臉」這種尺寸小、變化大、環境複雜的目標時,仍然存在效能瓶頸。
這正是 YOLO Face 誕生的原因——它是 YOLO 家族中,專為臉部辨識打造的專家級模型。
什麼是 YOLO Face?
YOLO Face 是基於 YOLO 模型架構延伸而來的人臉偵測模型,由 YapaLab 開發並開源於 GitHub。
它在保留 YOLO 高速推論優勢的同時,針對人臉特徵進行最佳化訓練,使模型能在各種嚴苛條件下,仍能精準找出人臉位置。
📌 官方專案
👉 https://github.com/YapaLab/yolo-face
YOLO Face 的三大核心特色
🚀 1. 搭配 YOLO 模型框架,快速且準確地找出人臉
YOLO Face 繼承 YOLO 單階段(One-stage)偵測的優勢:
- 單次前向推論即可完成偵測
- 高 FPS,適合即時影像串流
- 可部署於 GPU、Edge 裝置、嵌入式系統
這讓 YOLO Face 非常適合應用於:
🌙 2. 在黑暗或極度複雜環境中依然能偵測人臉
相較於傳統臉部偵測方法,YOLO Face 在訓練時納入多種困難場景:
- 低光源、夜間畫面
- 背光或強烈光影
- 遮擋、多人重疊
- 複雜背景干擾
即使在幾乎「看不清楚」的影像條件下,仍能穩定框出人臉位置,這對安防與戶外應用尤其重要。
⚽ 3. 準確且快速地追蹤足球比賽中的足球員
你可能會好奇:臉部辨識為何能應用在足球比賽?
答案是:
在高速運動、多人場景中,「臉部」是最穩定的身份線索之一。
YOLO Face 能夠:
- 在快速移動的畫面中鎖定球員臉部
- 協助後續的球員追蹤(Tracking)
- 結合 Re-ID、戰術分析、轉播輔助系統
這讓 YOLO Face 不只是一個臉部辨識模型,更是運動分析與智慧影像的重要基石。
YOLO Face 適合哪些應用場景?
- 智慧監控與安防系統
- 夜間人臉偵測
- 體育賽事影像分析
- 智慧城市
- 邊緣運算(Edge AI)
- 即時串流分析系統
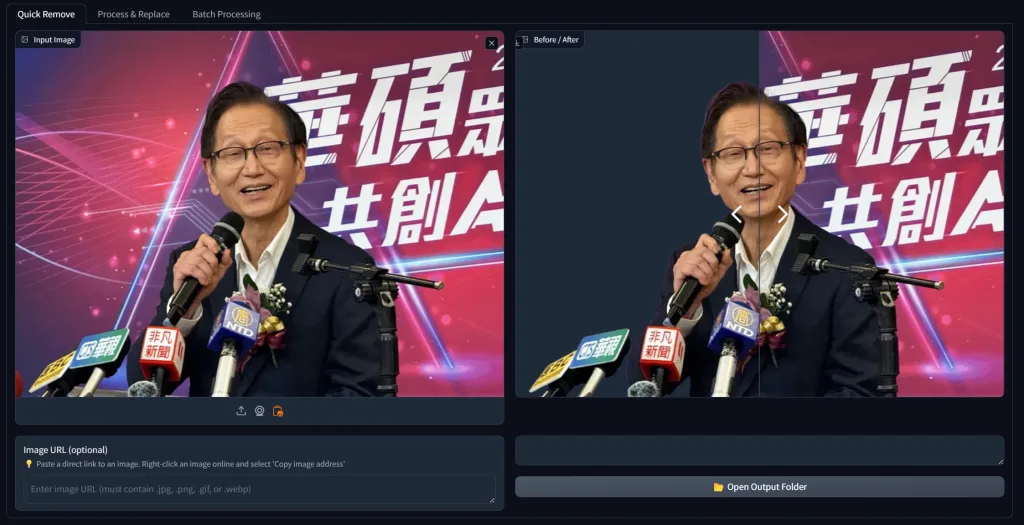
by rainchu | 12 月 27, 2024 | AI, 人臉辨識, 圖型處理, 繪圖
MBG-2-Studio 是一款基於 BRIA-RMBG-2.0 模型開發的開源應用程式,專門用於高效地移除和替換圖像背景,提供了背景移除、圖像合成、顏色分級和批次處理,可以用於電子商務、廣告製作、遊戲開發等多種場景。
主要功能:
- 背景移除:利用先進的 AI 技術,精確分離前景與背景,達到高精度的背景去除效果。
- 拖放圖庫:用戶可以直接從圖庫中拖放處理後的圖像,進行背景替換和顏色調整。
- 圖像合成:將處理後的圖像放置在新的背景上,並進行位置和大小的調整,以實現自然的合成效果。
- 顏色分級:調整圖像的亮度、對比度、飽和度、色溫和色調,提升圖像質量。
- 批次處理:一次性處理多張圖像,提高工作效率,適合需要大量處理的用戶。
- URL 支援:直接從 URL 加載圖像進行處理,方便處理線上圖片。
使用指南:
使用 node js 安裝
- 安裝:從 GitHub 頁面下載最新版本的安裝包,解壓後運行
install.js 進行安裝。
- 啟動:安裝完成後,運行
start.js 啟動應用程式。
- 背景移除:在「背景移除」標籤下,將需要處理的圖像拖放到指定區域,應用程式會自動進行背景移除。
- 圖像合成:在「合成工作區」標籤下,從圖庫中拖放處理後的圖像到合成區域,調整位置和大小,選擇新的背景,並使用顏色分級工具進行調整。
使用 pip 安裝
- 安裝:到 app 目錄下,執行 pip install -r requirements.txt
- 啟動:執行 app\app.py
相關資源:
GitHub 頁面

by rainchu | 12 月 3, 2024 | AI, 人臉辨識
完全開源的 AI 換臉工具,也提供了預先編譯好的程式碼,只需要簡單的三個步驟
有支援多人臉的尋找以及合成,合成的效果還不錯,只是訓練的時間有點久

by rainchu | 9 月 23, 2024 | AI, 人臉辨識, 圖型處理, 影片製作
用有多張臉,即時更換人臉的開源軟體,而且有綠色直接使用版本,已經幫忙把環境都打包好了,給懶人使用,支援windows、MAC、GPU
必要條件
Git 原始碼
https://github.com/hacksider/Deep-Live-Cam.git
下載模型
- GFPGANv1.4
- inswapper_128.onnx (Note: Use this replacement version if an issue occurs on your computer)
並且將這兩個檔案放在 models 的目錄下
安裝相關依賴
pip install -r requirements.txt
參考資料
https://github.com/hacksider/Deep-Live-Cam

by Rain Chu | 6 月 27, 2024 | AI, 人臉辨識, 影片製作, 語音合成
Fusion Lab 又有新款力作,Hallo AI 可以讓用戶僅需提供一張照片和一段語音,就能讓照片中的人物進行說話、唱歌甚至進行動作,為數字內容創作帶來了革命性的突破。

主要功能介紹:
- 語音動畫同步:用戶只需上傳一張照片及一段WAV格式的英語語音,Hallo AI就能使照片中的人物按語音內容進行動作,包括說話和唱歌。
- 動作自然流暢:結合精確的面部識別和動作捕捉技術,保證人物動作的自然流暢,令人印象深刻。
技術框架:
- 音頻處理:使用Kim_Vocal_2 MDX-Net的vocal removal模型分離語音。
- 面部分析:透過insightface進行2D和3D的臉部分析。
- 面部標記:利用mediapipe的面部檢測和mesh模型進行精確標記。
- 動作模組:AnimateDiff的動作模組為動作生成提供支持。
- 影像生成:StableDiffusion V1.5和sd-vae-ft-mse模型協同工作,用於生成和調整圖像細節。
- 聲音向量化:Facebook的wav2vec模型將WAV音頻轉換為向量數據。
安裝方法
盡量採用 Linux 平台,我這邊測試成功的有 Ubuntu 20 WSL 版本,就可以簡單三個步驟,部過前提要記得先安裝好 WSL CUDA 支援
1.建立虛擬環境
conda create -n hallo python=3.10
conda activate hallo
2.安裝相關的依賴
pip install -r requirements.txt
pip install .
3.要有 ffmpeg 支援
4.測試與驗證
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav
最近更新:
- 在🤗Huggingface空間克隆了一個Gradio演示。
- 新增Windows版本、ComfyUI界面、WebUI和Docker模板。
參考資料
Hallo GitHub
Hallo Model
大神開發的Windows介面
Hallo 線上版本
Hallo Docker版
影片跳舞合成

by Rain Chu | 11 月 8, 2023 | AI, 人臉辨識, 圖型處理, 影片製作, 繪圖
Rope以其令人矚目的功能,站在了這場技術革新的前沿。這款AI工具不僅能夠輕鬆去除臉部遮擋,更整合了多種高清化算法,讓處理速度快如閃電。然而,在介紹如何安裝和使用Rope之前,我們必須提醒每一位用戶:這項強大的技術應當用於正當的創造和學術研究,千萬別拿去做壞事。現在,讓我們詳細了解如何在您的本地設備上安裝並運行Rope。

安裝必要軟體
在開始使用Rope之前,需要先安裝一些必要的軟體:
- 安裝Python
- 安裝FFmpeg
- FFmpeg是處理影片不可或缺的組件,可以通過命令行進行安裝,或是參考我之前的ffmpeg教學。
- Nvidia顯卡安裝CUDA
- 為了充分發揮Rope的性能,Nvidia顯卡用戶應安裝CUDA 11.8,這對於AI運算至關重要。
安裝Rope
安裝了必要的軟體後,便可以開始安裝Rope:
- 下載Rope壓縮包
- 安装visual studio 2022
- 創建虛擬環境
- 使用Python建立一個新的虛擬環境,這有助於管理依賴包和版本。
- python -m venv venv
- 啟動虛擬環境
- 透過命令行啟動虛擬環境,準備安裝Rope。
- call venv\scripts\activate.bat
- 安裝依賴包
- 在虛擬環境中,使用pip指令安裝Rope需要的所有依賴包。
- pip install -r requirements.txt
- 如果安裝失敗,要先執行下面的指令
- pip install –no-cache-dir -r requirements.txt
- pip uninstall onnxruntime onnxruntime-gpu
- pip install onnxruntime-gpu==1.15.0
- 下載換臉模型
透過這些步驟,您可以在本地機器上成功安裝和配置Rope,並開始進行高效的臉部轉換。隨著AI技術的快速發展,Rope提供了一個既方便又強大的工具,使創意和創新更加無限。
操作指南:如何使用Rope進行批量換臉
請先確認安裝 Rope 已經成功,接著,遵循以下步驟來執行Rope的批量換臉功能:
- 打開命令提示字元
- 進入Rope的本地根目錄
- 激活虛擬環境
- 通過執行
call venv\Scripts\activate.bat指令來激活Rope的Python虛擬環境。
- 運行Rope主程式
- 使用
python run.py --execution-provider cuda指令,開始執行批量換臉處理。
自定義選項:提升處理質量與效率
Rope提供多個可選參數來滿足用戶的特定需求:
- 面部增強
- 加入
face_enhancer選項,可以對換臉後的面部進行增強處理,使其更加清晰細緻。
- python run.py –execution-provider cuda face_enhancer
- 調整輸出視頻質量
- 使用
--video-quality選項並指定一個0到50的數值(數值越小,輸出質量越高)。
- python run.py –execution-provider cuda –video-quality 1
- 指定內存使用
- 若需要管理程序的內存使用,可透過
--max-memory選項設定最大內存限制。
- python run.py –execution-provider cuda –max-memory 16
- 指定執行線程
- 對於較老的Nvidia顯卡,可使用
--execution-threads來指定執行線程數,以達到最佳運行效能。
- python run.py –execution-provider cuda –execution-threads 2
- 預設是4
使用方法可以看YT
Rope又一款强大的一键换脸AI!可消除脸部遮挡,多种高清化算法,飞一般的处理速度!本地安装与参数使用详解。 – YouTube
解除roop检测深度换脸 – YouTubehttps://www.youtube.com/watch?v=YH4hB3wmRcQ
roop新奇用法:一键直播换脸、批量换图 – YouTube
Rope 分支
https://github.com/Hillobar/Rope/
https://github.com/s0md3v/sd-webui-roop
近期留言