by Rain Chu 6 月 6, 2026 | AI , 圖型處理
2026 年最受矚目的 AI 繪圖模型之一,莫過於 Ideogram 團隊正式釋出的:
Ideogram 4
這是 Ideogram 首次公開模型權重(Open Weight),也是目前開源陣營中,在:
文字生成(Text Rendering)
海報設計
品牌廣告
排版控制
JSON 結構化提示詞
官方 資料顯示,Ideogram 4 採用 9.3B 參數的單流 Diffusion Transformer(DiT)架構,並支援原生 2K 圖像生成。
本篇將帶你使用 ComfyUI,在本機部署 Ideogram 4。
系統需求
官方模型共有兩個版本:
版本 量化 Ideogram 4 FP8 品質最佳 Ideogram 4 NF4 VRAM需求較低
目前 ComfyUI 官方整合版本主要使用:
其中 FP8 畫質最佳。
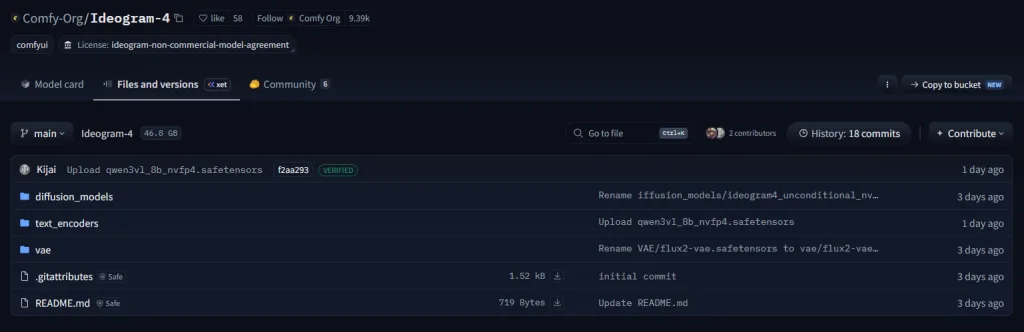
第一步:下載模型
ComfyUI 專用模型
官方:
Comfy-Org Ideogram-4
原始模型:
Ideogram 4 FP8 官方 模型
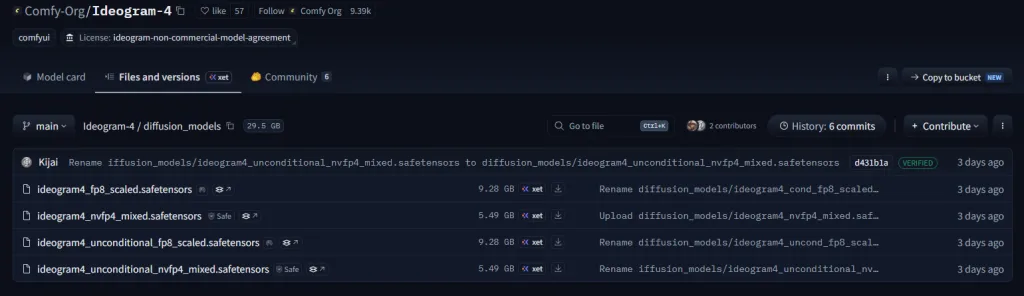
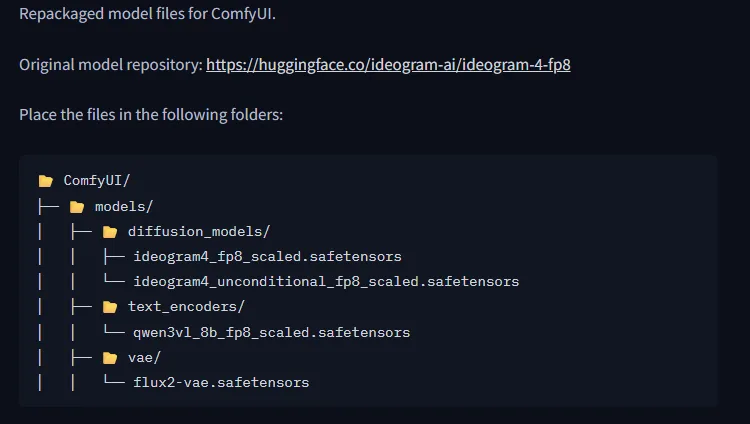
第二步:放置模型檔案
依照官方說明建立目錄。
ComfyUI
│
├─ models
│ ├─ diffusion_models
│ │ ├─ ideogram4_fp8_scaled.safetensors
│ │ └─ ideogram4_unconditional_fp8_scaled.safetensors
│ │
│ ├─ text_encoders
│ │ └─ qwen3vl_8b_fp8_scaled.safetensors
│ │
│ └─ vae
│ └─ flux2-vae.safetensors 第三步:了解每個模型用途
ideogram4_fp8_scaled
主模型
負責:
ideogram4_unconditional_fp8_scaled
CFG 引導模型
負責:
提升細節
強化 Prompt Follow
改善品質
官方建議兩個模型一起使用。若只載入主模型雖可運作,但畫質會下降。
qwen3vl_8b_fp8_scaled
文字編碼器
負責:
Prompt 理解
JSON 理解
空間推理
海報版面配置
flux2-vae
VAE 解碼器
負責將 Latent 轉換成圖片。
第四步:更新 ComfyUI
Ideogram 4 需要最新版本的 ComfyUI。
更新方式:
或:
官方於 Day-0 即已原生支援 Ideogram 4。
第五步:載入官方 Workflow
ComfyUI 官方已提供範例工作流。
建議直接從:
Comfy Blog
下載 Workflow 。
基礎工作流架構
Prompt
↓
Qwen3-VL Encoder
↓
Ideogram 4
↓
Sampler
↓
Flux VAE Decode
↓
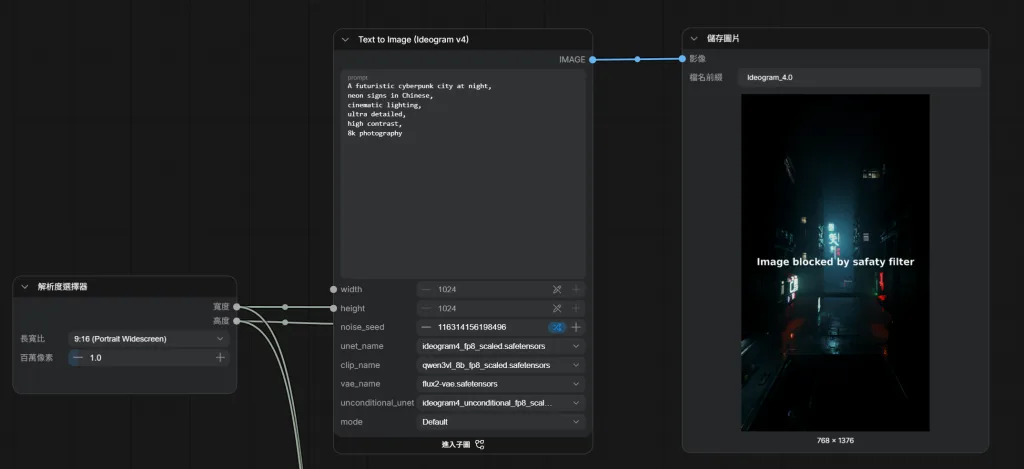
Save Image 第六步:第一張圖片
測試 Prompt:
A futuristic cyberpunk city at night,
neon signs in Chinese,
cinematic lighting,
ultra detailed,
high contrast,
8k photography 生成尺寸:
推理模式:
第七步:體驗 JSON Prompt
Ideogram 4 最大特色就是:
Structured JSON Prompt
官方模型訓練時即使用 JSON Caption。
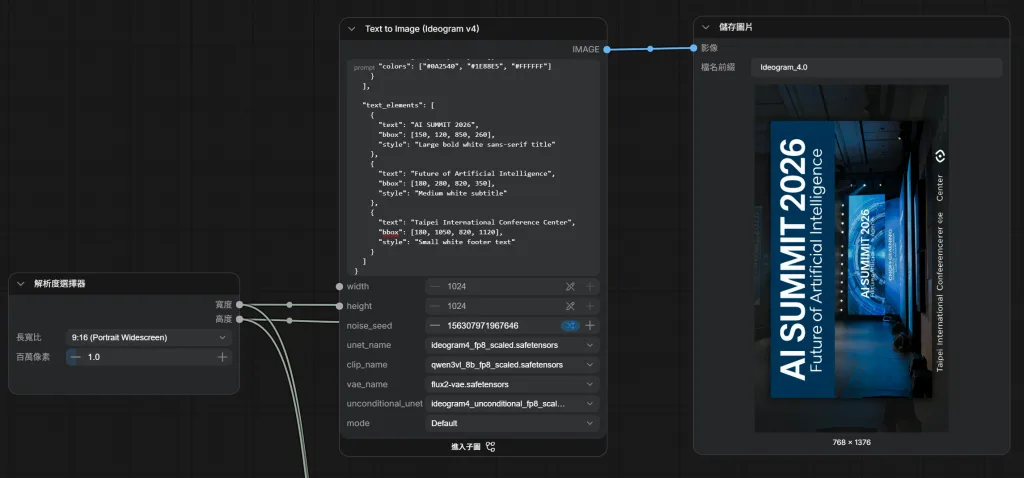
範例:海報設計
{
"scene_summary": "Professional technology conference poster",
"background": {
"description": "Modern convention center stage with blue ambient lighting, large LED screen, clean professional environment"
},
"style": {
"description": "Corporate marketing design, professional conference poster, clean typography, premium branding, modern layout"
},
"objects": [
{
"description": "Conference stage",
"bbox": [100, 150, 900, 850],
"colors": ["#0A2540", "#1E88E5", "#FFFFFF"]
}
],
"text_elements": [
{
"text": "AI SUMMIT 2026",
"bbox": [150, 120, 850, 260],
"style": "Large bold white sans-serif title"
},
{
"text": "Future of Artificial Intelligence",
"bbox": [180, 280, 820, 350],
"style": "Medium white subtitle"
},
{
"text": "Taipei International Conference Center",
"bbox": [180, 1050, 820, 1120],
"style": "Small white footer text"
}
]
} Bounding Box 控制
可直接指定位置。
{
"text_elements":[
{
"text":"SALE 50%",
"bbox":[100,100,500,300]
}
]
} 座標範圍:
原點:
這是目前 FLUX 與 Stable Diffusion 所不具備的能力。
色彩盤控制
品牌設計超級好用。
{
"color_palette":[
"#FF6600",
"#FFFFFF",
"#000000"
]
} 官方支援:
與 FLUX 比較
FLUX 強項
Ideogram 4 強項
Logo
海報
Banner
電商素材
排版設計
中文文字生成
若你是:
Ideogram 4 很可能比 FLUX 更適合。
結論
Ideogram 4 不只是另一個 AI 繪圖模型。
它最大的創新在於:
把 Prompt 從自然語言升級為結構化設計規格。
透過:
Qwen3-VL
Diffusion Transformer
JSON Prompt
Bounding Box
Color Palette
使用者終於可以像操作 Figma 一樣控制 AI 生成內容。
對於需要:
海報設計
品牌素材
Banner 製作
AI Agent 自動產圖
的開發者來說,Ideogram 4 是目前最值得研究與部署的開源模型之一。
by rainchu 12 月 18, 2025 | AI , 圖型處理 , 影片製作
眾多 AI 創作平台之中,Liblib 憑藉其高度整合的功能、生態完整度以及對中文使用者的極致友善設計,迅速成為中國最領先的 AI 創作平台之一 。
一站式 AI 影像與視頻創作平台
Liblib 不僅僅是一個圖片生成網站,而是一個超級齊全的 AI 創作平台 ,涵蓋:
AI 圖片生成 AI 視頻特效與動畫 模型管理與分享 視覺化工作流(Workflow) LoRA 訓練與應用
透過雲端化的設計,使用者無需自行架設環境,即可直接在瀏覽器中使用高階 AI 生成能力。
深度整合 WebUI 與 ComfyUI
對於熟悉 Stable Diffusion 生態的使用者而言,Liblib 最大的優勢之一,在於它同時支援:
WebUI :操作直覺、上手快速,適合大多數創作者ComfyUI :節點式工作流,適合進階用戶進行複雜控制與自動化生成
這種雙軌並行的設計,讓初學者與專業用戶都能在同一平台中找到最適合自己的創作方式。
強大的 LoRA 訓練能力
Liblib 在 LoRA 訓練 方面表現尤為突出,提供完整且視覺化的訓練流程:
上傳資料集即可開始訓練
支援多種風格與角色 LoRA
訓練完成後可直接套用於生成
社群分享與模型市集機制
這讓創作者能快速打造專屬風格模型 ,大幅降低 AI 模型訓練的門檻。
中文使用者極度友善
相較於許多國外 AI 平台對中文支援不足,Liblib 在以下方面明顯優於同類產品:
完整繁體與簡體中文介面 中文 Prompt 理解度高
中文模型與 LoRA 資源豐富
適合華語創作者的社群內容
對中文內容創作者來說,這是一個真正「為中文而生」的 AI 創作平台。
工作流與創作效率全面升級
Liblib 內建的 工作流系統(Workflow) ,讓使用者可以:
將複雜生成流程模組化
重複使用高品質生成邏輯
快速套用他人分享的創作流程
大幅提升商業與批量創作效率
這對於需要大量產出視覺內容的團隊與個人創作者而言,是極具價值的功能。
為什麼 Liblib 是中國最領先的 AI 創作平台?
綜合來看,Liblib 的核心優勢包括:
✅ 視頻特效 + 圖片模型完整整合
✅ WebUI 與 ComfyUI 同時支援
✅ 強大且易用的 LoRA 訓練
✅ 中文高度友善,資源豐富
✅ 從新手到專業用戶皆適用
這不僅是一個工具,更是一個完整的 AI 創作生態系 。
官方網站
👉 Liblib 官方平台 https://www.liblib.art/
by rainchu 12 月 15, 2025 | AI , 圖型處理 , 模型 , 繪圖
Nano Banana Pro 剛出,就馬上成為「圖像生成與視覺應用」領域的新標準,它不只是畫圖工具,而是一個高度可控、支援中文、能維持一致性的 AI 視覺引擎 。
以下整理 Google Nano Banana Pro 的 15 種超強應用場景 ,無論你是設計師、行銷企劃、教育工作者或產品經理,都能立即上手。
1️⃣ 簡報/企劃海報快速生成
只要輸入企劃主題與風格,Nano Banana 就能產出投影片主視覺、封面海報、提案插圖 ,大幅減少找素材與修圖時間。
2️⃣ 草圖秒變產品實景圖
手繪線稿、低擬真草圖,可直接轉為擬真產品照 ,特別適合工業設計、UI / UX、新創產品驗證。
3️⃣ 設計材質紋理
可精準生成木頭、金屬、皮革、布料、玻璃等高解析材質貼圖 ,支援不同光源與粗糙度設定。
4️⃣ 角色一致性
透過角色描述與參考設定,即使多次生成,也能維持臉型、服裝、風格高度一致 ,非常適合漫畫、品牌代言角色。
5️⃣ 品牌指南手冊
一次生成品牌色彩、字體風格、視覺範例 ,快速完成 Brand Book 視覺示意。
6️⃣ 生成各種尺寸
同一視覺可自動輸出 社群貼文、橫幅廣告、直式限動、網站 Banner 等多尺寸版本。
7️⃣ 食譜圖超清晰
針對食物細節表現極佳,油光、層次、質地自然,特別適合餐飲菜單、食譜部落格、外送平台 。
8️⃣ 多國語言菜單 Menu
結合 Gemini 的語言能力,可直接生成多國語言版本菜單圖片 ,且排版自然、不違和。
9️⃣ 景點/教材圖卡
可用於旅遊介紹、歷史教材、地理圖卡、兒童學習素材 ,風格可愛或寫實皆可。
🔟 風格轉換更精細
支援攝影風、插畫風、3D 風、日系、美式、復古等,且保留原圖構圖與細節 。
1️⃣1️⃣ 教學假桌面生成
快速生成「假作業系統畫面」、「教學用後台介面」,適合製作教學簡報與線上課程 。
1️⃣2️⃣ 腳本 → 連續劇照
輸入分鏡或劇本段落,即可生成連續一致的劇照畫面 ,對影視提案與動畫前期極有幫助。
1️⃣3️⃣ 中文超強
對繁體中文理解精準,無論是菜單、教材、標語、情境文字,都能自然呈現,不再需要英文轉譯 。
1️⃣4️⃣ 畫 3D 圖也可以
可生成擬 3D、等角視圖、產品爆炸圖概念,適合簡報與技術說明使用。
1️⃣5️⃣ 任意切換焦距
同一場景可切換廣角、標準、特寫、微距 ,視覺敘事能力大幅提升。
參考與官方資源
by rainchu 12 月 12, 2025 | AI , PPT , Prompt , 圖型處理
最近 Google Labs 再次投下震撼彈——推出全新的視覺協作工具 Google Mixboard 。這款被科技界譽為「進階版的 AI Pinterest 」的創作平台,不只提供一張能無限延伸的靈感畫布,讓使用者自由拼貼、蒐集、創作,更強大的是它整合了 Google 最新影像模型 Gemini Nano Banana Pro ,讓「圖片與文字的轉化能力」大幅進化。
Mixboard 不只是找圖工具,它是一款真正能把雜亂靈感整合成專業產出 的 AI 創作平台。從蒐集參考、生成圖像、到一鍵變成簡報,你的創作流程從此不再分散於各個應用工具,全部在 Mixboard 一站式完成。
🌈 AI 靈感畫布:願景、概念、素材一次整合
Mixboard 的核心概念是一張能無限延伸的 Infinite Canvas(無限畫布) 。你可以:
任意拖放圖片與文字
建立 Moodboard / 風格版
生成 AI 圖像
標記重點、串連思考流程
與團隊同步協作
它的使用體驗與 Pinterest 的收藏便利性類似,但功能延伸到即時生成、編輯與視覺敘事,因此被形容為「AI 時代的 Pinterest 2.0」。
對設計師、行銷人、PM、內容創作者而言,這款工具能大幅提升發想到產出的速度與品質 。
⚡ Nano Banana Pro 模型強化「圖文轉化」:簡報不再需要手動排版
Mixboard 最大亮點,就是 Google Labs 全新的 Gemini Nano Banana Pro 影像模型。
它最令人驚豔的能力是:
⭐ 一鍵把零散靈感 → 自動變成專業簡報
只要選擇畫布內容並下指令,Mixboard 能:
自動辨識素材意圖
依據內容自動重構敘事結構
自動生成排版精美的投影片
產出高解析度圖片與文字
保留原本的風格、色調、敘事邏輯
無論你是做品牌提案、產品靈感收集、UI 改版構思、或社群 campaign 規劃,原本需要花上數小時整理的簡報,都只要 一鍵轉換 就能完成。
🧩 Mixboard 解決了哪些過往創作痛點?
1. 靈感雜亂、難以整理
貼在 Notion?存到 Pinterest?散落在相簿?
2. 簡報排版耗時
你只需要負責「想法」,簡報排版由 AI 完成。
3. 多工具切換降低效率
找圖 → 裁圖 → 設計 → 編排 → 簡報,全部一站式完成,大幅縮短製作流程。
4. 團隊協作斷層
Mixboard 支援分享與多人編輯,視覺溝通更直觀。
🚀 更適合哪些族群使用?
品牌行銷團隊
社群小編、內容創作者
新創團隊 Pitch Deck 製作者
設計師、UI/UX 規劃者
教育工作者、講師
想快速整理靈感的人
如果你常常在 Canva、Keynote、Notion、Pinterest 之間切換,Mixboard 將會是你最強的替代方案。
🔗 更多資訊
官方網站:https://labs.google.com/mixboard/welcome
by rainchu 11 月 23, 2025 | AI , 圖型處理 , 繪圖
所謂 AI 圖像生成,是指利用人工智慧模型(如「文本轉圖片」或「圖片轉圖片」)從文字提示、或現有影像作為輸入,產出全新視覺作品。這類工具背後常用「擴散模型」(diffusion models)或其他生成式架構。
快速上手指南:三步驟產出視覺作品
步驟 1:明確構思內容 步驟 2:輸入提示(Prompt)並生成 步驟 3:後製與整合
模型推薦:哪個最穩定、最強?
經檢視多項資料後,我們推薦使用 Analog Madness 模型。這裡說明為什麼選它:
Analog Madness 是一款靠近真實攝影質感的影像生成模型,据社群評論和模型頁面資料指出,其在「真實風格」、「類比攝影風格」方面表現優異。
它常被描述為「非常多用途(versatile)」、「提示越強效果越好」的模型。
在專門探討 AI 模型的討論中,有使用者提問:「Is Analog Madness the best 1.5 photorealistic model?」可見其在社群中名字較為常見。
使用建議 :
若你想要達成「真實感+類比攝影風格」的圖片,可選擇 Analog Madness 並搭配精細提示。
提示範例可加入「ultra realistic close up portrait, film grain, analog style, 4K」等描述。
注意:即便是最強模型,也仍需你提供具體而精準的提示詞;模型本身不是完全自動完美,仍須人為設計輔助。
LoRA 濾鏡玩法:讓 AI 直接「化妝」你的圖
除了選擇強模型之外,另一個提升圖片風格自由度與創意控制的關鍵是 LoRA(Low-Rank Adaptation)濾鏡 。以下為其玩法介紹:
什麼是 LoRA? 怎麼使用?
選擇一個支持 LoRA 的 UI 或工具(如 Stable Diffusion 前端)。
將你想加入的 LoRA 模組載入(如「beauty-makeup LoRA」、「film-grain LoRA」等)。
在提示(prompt)中明確加入你想的濾鏡風格,例如: prompt: 「A glamorous portrait of a woman, heavy makeup, glossy lips, dramatic eyeshadow, analog film style, beauty light」
效果與建議 :
利用 LoRA,你能讓 AI 圖像加上「化妝效果」、「風格化妝感」、「光影膠片質感」等,使圖片更具商業或時尚感。
建議提示中加入「makeup, dramatic eyeshadow, high-gloss skin, studio lighting」等描述詞,再搭配 LoRA,效果更佳。
若你生成系列圖片(例如插畫系列或社群貼文系列),可固定同一個 LoRA 濾鏡,以維持風格一致性。
注意事項 :
某些 LoRA 模組可能只用於私人、非商業用途,使用前請確認授權。
濾鏡效果強度過高可能導致圖片不自然,建議生成後進一步微調。
快速上手指南:三步驟產出視覺作品
步驟 1:明確構思內容 步驟 2:選模型+載入 LoRA +輸入提示 步驟 3:後製與整合
注意事項與實用 Tips
提示越具體,效果越好 :描述中加入「情緒、光線、構圖、色調」等詞彙。檢查版權與用途限制 :若將圖片用於商業用途,請確認工具條款。視覺風格一致性 :若產出系列圖像,建議統一提示中指定風格,以維持一致性。避免過度依賴 AI :AI 是輔助工具,創作者仍可加入人性化元素、構思與個人風格。輸出檔案備份 :建議保存原始生成圖片與提示文字,以便未來回溯或修改。
參考資料
https://aigallery.app
by rainchu 11 月 21, 2025 | AI , 圖型處理
Google 於 2025 年 8 月正式推出其 AI 圖像生成模型 「Nano Banana」 ,隨後在 11 月發佈進階版 Nano Banana Pro(亦稱 Gemini 3 Pro Image) 。這款模型支援文字與圖片提示生成高畫質圖像,並加入進階編輯控制!以下為你拆解五大亮點、技術優勢與實用建議。
亮點特色
文字+圖片提示生成適用於海報、邀請卡類作品 可視化資訊圖表與示意圖能力強 一次處理多素材、最多 14 張圖片融合、至多 5 位人物一致性 進階編輯功能:局部選擇+攝影機角度+背景虛化+色彩分級+日夜切換、支援多比例與 4K 輸出 能識別並翻譯商品上的文字
技術與應用洞察
Nano Banana Pro 是建立在 Google Gemini 3 Pro Image 的架構上,具備「推理(reasoning)模型核心 + 高級渲染」能力。
模型支援「thinking mode」或「多回合提示」(multi-turn prompting),透過內部「思考階段」生成中繼草圖,再產出高解析圖像。
在輸出方面,支援高達 4K 解析度、精確字體呈現、多語言文字支援、跨平台比例(如社群貼文、海報、橫幅、影片封面)。
應用場景包括:品牌/行銷設計、資訊圖表製作、產品視覺呈現、社群內容創作、教育/說明圖像、活動邀請卡等。
使用建議與注意事項
在提示(prompt)撰寫時,建議提供「文字提示+圖片提示(若有)+指定比例/解析度/風格」三項要素。
若想保持人物一致性或場景融合,建議提供多張圖片提示(最多 14 張),並指定「5 位人物一致外觀」。
若使用文字渲染功能或多語言文字素材(如包裝文字翻譯),可在提示中明確說明「請將英文字 ‘XXX’ 翻譯為韓文/中文並置於包裝正面」。
參考資料
https://gemini.google/





近期留言