by Rain Chu 7 月 28, 2026 | Agent , AI
CrewAI 不是一個大語言模型,而是一套用來編排 AI Agent 的 Python 框架,它把一個複雜任務拆成不同角色,再透過 Task、Process 與 Crew 控制合作方式。模型負責思考,工具負責行動,知識庫負責補充事實,而 CrewAI 負責讓這些元件按照可理解的流程運作。
提示詞優化是一個很適合理解 CrewAI 的案例,只要把工作拆成分析、改寫、測試與最終審核,就能看見多 Agent 的價值,也能看見它的代價,Agent 數量增加後,模型呼叫、檢索次數、延遲與費用都會一起增加。真正重要的不是組一支看起來很熱鬧的 AI 團隊,而是讓每個角色都有不可取代的責任。
CrewAI 是什麼
CrewAI 是獨立開發的多 Agent 自動化框架,不依賴 LangChain,官方把主要能力分成 Crews 與 Flows,Crews 適合需要角色分工、探索與協作的任務,Flows 適合需要明確順序、狀態、條件分支與可稽核結果的工作流。
可以把它想成一間小型公司,Crew 是團隊,Agent 是成員,Task 是工作單,Process 是工作順序,Tool 是成員可以使用的工具。Knowledge 則是團隊共同或個別可查閱的資料庫。
元件 負責內容 提示詞優化案例 Agent 角色、目標、模型、工具與行為 分析師、改寫者、測試者 Task 工作描述、輸入、預期輸出與驗收條件 找出缺漏、產生新版、比較品質 Crew 組合 Agent 與 Task 並啟動執行 完整的提示詞優化團隊 Process 決定工作如何安排 依序分析、改寫、測試與定稿 Flow 控制狀態、事件與條件路徑 品質不合格時退回重寫 Knowledge 提供文件、網站或結構化資料 提示詞規範與優秀案例 Tool 讓 Agent 存取外部能力 向量檢索、網頁搜尋與評分器
提示詞優化 Crew 的完整架構
使用者輸入原始需求
↓
RAG 檢索提示詞規範與案例
↓
Prompt Analyzer 找出目標、限制與缺漏
↓
Prompt Optimizer 建立第一版完整提示詞
↓
Prompt Tester 以驗收標準比較品質
↓
Ultimate Optimizer 整合修正並輸出定稿
這種設計的關鍵是讓每個 Agent 產生下一個 Task 能直接使用的結果,分析師不應只給模糊評論,而要輸出結構化問題清單,改寫者要根據問題清單產生完整版本,測試者要使用固定量表,而不是憑感覺說新版比較好,最後的審核者只整合已確認的修正,不再任意改變需求。
若要進一步降低漂移,可以用 Pydantic 或 JSON 結構固定每一階段的輸出。這比單純增加角色背景故事更有效,因為下一個步驟能明確知道要讀取哪些欄位。
四個 Agent 不一定比兩個好
分析、優化、測試與最終優化看起來很完整,但每個角色都使用大型模型,還在每一階段重複查詢向量資料庫時,成本很容易放大。對簡單提示詞而言,分析與改寫可以由同一個 Agent 完成,再保留一個獨立測試 Agent,就已經有清楚的製作與驗收分工。
保留不同 Agent,當兩個角色需要不同工具、不同權限或不同模型時。
合併 Agent,當工作只是同一段文字的連續改寫時。
改用一般函式,當步驟不需要推理,只是格式轉換或資料驗證時。
改用 Flow,當流程需要條件分支、重試、人工確認與狀態保存時。
RAG 在 CrewAI 裡負責什麼
RAG 的用途不是替 Agent 增加想像力,而是讓它在執行任務前找到可靠的參考資料,提示詞優化系統可以把提示詞指南、優秀範例、品牌規範與輸出格式放進知識庫。使用者送出需求後,系統只取回最相關的片段,再讓 Agent 根據這些內容工作。
2024 年的實作組合是 Phidata、pgvector 與 OpenAI Embedding,Phidata 現在已改名為 Agno ,如果要維護舊專案,應先確認套件名稱與匯入路徑,不宜直接照搬舊版命令。
目前 CrewAI 已有內建 Knowledge ,可讀取文字、PDF、CSV、Excel、JSON 與網站內容,官方的 provider-neutral RAG client 預設使用 ChromaDB,也支援 Qdrant,若既有系統已使用 PostgreSQL,仍可把 pgvector 封裝成自訂 Tool,若只是做第一個原型,先用內建 Knowledge 通常更省事。
想理解本地檢索的完整取捨,可以搭配 GraphRAG 使用本地 Ollama ,若知識來源主要是專案文件與程式碼,OpenWiki 建立 Agent 共用知識庫 也很適合一起比較。
先用 RAG,不要急著訓練模型
手上有大量人工撰寫的中英文檢索式或高品質提示詞時,第一步不一定是微調。先把資料清理成「需求、上下文、限制、輸入範例、理想輸出」的成對資料,再用 RAG 找相似案例,通常能更快驗證需求。
先建立測試集,保留一批資料完全不進知識庫。
用 RAG 加單一 Agent 建立基準結果。
加入獨立評分 Agent,比較正確性、完整性與格式。
只有在格式高度穩定、資料量充足且 RAG 已到瓶頸時,再評估微調。
這樣做的好處是資料更新不必重新訓練,錯誤案例也能快速撤換。若資料彼此關聯複雜,還可以參考 Graphify 知識圖譜 ,評估是否需要從純向量檢索進一步加入實體與關係。
CrewAI 2026 最新安裝方式
截至 2026 年 7 月,官方文件要求 Python 3.10 以上且低於 3.14,並建議使用 uv 管理套件。CrewAI 現在預設建立 JSON-first 專案,Agent 放在 agents/*.jsonc,Task 與 Crew 設定放在 crew.jsonc。若需要早期常見的 Python 與 YAML 結構,才使用 --classic。
uv tool install crewai
uv tool update-shell
crewai create crew prompt_optimizer
cd prompt_optimizer
crewai install
crewai run 建立後會看到 crew.jsonc、agents/、knowledge/、skills/ 與 tools/。這個結構已經把多數需求放進設定檔,適合先從角色與任務定義開始,再加入自訂 Python Tool。
需要舊版 Python 與 YAML 專案時
crewai create crew prompt_optimizer --classic 舊版教學常出現 crew.py、agents.yaml 與 tasks.yaml,這些概念仍然有效,但預設腳手架已經不同。遇到匯入錯誤時,先確認 CrewAI 版本,再對照該版本官方文件。
CrewAI 如何連接 Ollama
CrewAI 不限定 OpenAI 或 Anthropic。官方文件提供 Ollama 設定,只要在 Agent 指定 LLM 與 base_url 即可。這能把多數推理留在本地端,避免每個 Agent 都產生雲端 API 費用。
from crewai import Agent, LLM
local_llm = LLM(
model="ollama/qwen3:8b",
base_url="http://localhost:11434"
)
analyzer = Agent(
role="提示詞分析師",
goal="找出需求缺漏並建立清楚的改寫規格",
backstory="你擅長把模糊需求拆成可驗收的條件",
llm=local_llm
) 如果 Ollama 在另一台主機,把網址換成實際內網位置即可。部署前要確認 Ollama 有對區域網路監聽、防火牆已開放,而且 CrewAI 使用的模型名稱與 ollama list 完全一致。選擇模型時可以參考 本地大模型推理框架比較 。
Docker 與硬體需求怎麼看
Docker Desktop 不是 CrewAI 的必要條件。早期範例需要 Docker,是因為它用容器啟動 PostgreSQL 與 pgvector。Linux 伺服器可以直接使用 Docker Engine,也可以把 PostgreSQL 安裝成系統服務。若改用 CrewAI 內建 Knowledge 與本地 ChromaDB,第一版甚至不一定需要 Docker。
一般筆電可以執行 CrewAI,因為框架本身不重。真正決定硬體需求的是模型、Embedding、向量資料庫與同時執行的 Agent 數量。雲端模型加本地向量庫的門檻最低。本地模型則要依參數量、量化格式與上下文長度準備足夠的記憶體或顯示記憶體。
成本最高的地方不是框架
CrewAI 開源框架本身不是主要成本。費用通常來自每個 Agent 的模型呼叫、反覆 RAG 檢索、長上下文、Embedding 建庫與失敗重試。四個 Agent 各自檢索並呼叫一次大型模型,很可能比單一 Agent 加一次驗收多出數倍費用。
讓檢索結果在同一輪工作流中共用,不要每個 Agent 重複搜尋。
分類、格式檢查與簡單摘要改用小模型。
昂貴模型只負責最終改寫或高風險判斷。
為 Task 設定清楚的 expected output、guardrail 與最大重試次數。
保存每次輸入、檢索片段、輸出與評分,才能知道錢花在哪裡。
Crews 與 Flows 應該怎麼選
若任務需要研究、創作、分析與不同專業觀點,使用 Crew。若工作需要固定順序、條件分流、錯誤重試、人工核准與狀態恢復,使用 Flow。正式系統通常會把兩者結合,由 Flow 控制整體流程,只在需要推理的節點呼叫 Crew。
需求 建議方式 研究後寫成報告 Crew 分析、改寫與交叉審核 Crew 依分數決定重寫或通過 Flow 呼叫 API 並等待人工批准 Flow 完整內容生產管線 Flow 控制流程,Crew 處理創作
如果需要從桌面工作台管理 Agent 專案,也可以參考 OpenWork 與 OpenCode Agent 工作台 ,比較框架層與操作介面的差異。
我會怎麼重做這套提示詞優化系統
先用單一 Agent 加 Knowledge 建立基準版本。
定義固定評分表,檢查目標、背景、限制、格式與可驗收性。
加入一個獨立測試 Agent,只負責找問題與打分。
分數未達門檻時,由 Flow 送回改寫,並限制重試次數。
先用 Ollama 小模型跑分析與分類,必要時才把最終改寫交給較強模型。
用保留測試集比較原始提示詞與優化結果,不把自我評價當成唯一證據。
這個版本的 Agent 更少,但責任更清楚,也更容易測試。CrewAI 的價值不是替程式多包幾層,而是讓角色、任務、工具、知識與執行順序都能被明確描述。當每個步驟都能觀察、驗證與替換,多 Agent 才真正從展示走向可維護的系統。
官方資源與案例程式碼
FAQ
CrewAI 是模型還是框架
CrewAI 是多 Agent 編排框架。它負責組織 Agent、Task、Process、Tool、Knowledge 與 Flow,實際推理由 OpenAI、Anthropic、Ollama 或其他模型提供。
CrewAI 可以完全使用本地模型嗎
可以。Agent 的 LLM 可指向 Ollama,也能連接其他 OpenAI 相容端點。若 Embedding 與知識庫也改用本地方案,就能大幅降低雲端 API 成本。
Crew 和 Flow 有什麼差別
Crew 強調角色分工與自主協作。Flow 強調精確的執行路徑、狀態、條件分支與可恢復性。正式系統常用 Flow 管理整體流程,再把需要創作或分析的工作交給 Crew。
建立提示詞優化工具需要微調模型嗎
通常不需要先微調。先用 RAG 提供規範與案例,再建立獨立測試集評估品質。只有資料格式穩定、數量足夠,而且 RAG 已無法改善時,才值得評估微調。
使用 CrewAI 一定要安裝 Docker Desktop 嗎
不一定。Docker Desktop 只是啟動 pgvector 的方便方式。CrewAI 本身不依賴 Docker,Linux 可以使用 Docker Engine,也能改用本機 ChromaDB 或遠端向量資料庫。
by Rain Chu 7 月 28, 2026 | AI , PPT
傳統簡報的限制不只在動畫比較少,而是內容、視覺與互動通常被綁在同一個封閉檔案裡,改用 HTML 後,圖表可以依資料更新,產品可以用 3D 呈現,卡片能拖曳與吸附,按鈕也能真的回應操作。更重要的是,Codex 可以讀懂 HTML、CSS 與 JavaScript,直接修改、測試並反覆改善。
真正有效的方法不是叫 AI 一次做完,而是先把參考案例拆成設計規則,再把內容交給規則處理。這個做法能把「好看」從模糊感覺變成可重複使用的系統,也更適合品牌簡報、產品發表、作品集與資料看板。
HTML 簡報為什麼比 PPT 更適合 AI Agent
內容可程式化 :文字、圖片與資料都能從檔案或 API 載入互動更完整 :可加入篩選、拖曳、滾動、吸附、主題切換與即時圖表容易驗證 :Codex 可搭配瀏覽器測試畫面尺寸、按鈕、動畫與手機版容易複用 :風格規則可整理成 DESIGN.md,工作流程可封裝成 SKILL.md交付彈性高 :可直接開啟 HTML,也能再輸出 PDF、圖片、PPTX 或 MP4
如果你已經在使用 Codex,可以把瀏覽器驗證接進製作流程。相關做法可參考站內的 Playwright CLI 是什麼?讓 Codex 用 CLI 操作瀏覽器 。
最穩定的五段式工作流程
蒐集參考 :挑一到三個真正符合目標的網站、品牌頁或既有簡報拆成規則 :整理配色、字體、字級、網格、留白、圖片比例、元件與動效帶入內容 :提供主題、章節、資料表、圖片與必要連結加入能力 :用 ECharts、Spline 與 GSAP 補上圖表、3D 與動畫驗證與封裝 :測試桌面與手機版,再把成熟規則做成 Skill
一次直出的頁面常會出現字級、卡片與配色彼此不協調的問題。兩段式做法先產生設計規格,再產生實際頁面,能讓 AI 在每一輪修改時都有共同標準。若你希望更進一步改善 AI 常見的模板感,可以搭配 用 Impeccable 改善 AI 網站設計 。
Open Design 是什麼
Open Design 是開源、local-first 的 AI 設計工作區,原始碼放在 nexu-io/open-design 。它不是另一個封閉模型,而是把 Codex、Claude Code、Cursor、Gemini CLI、OpenCode、Qwen 等既有 Coding Agent 接進一套視覺設計流程。
它能建立原型、Landing Page、Dashboard、簡報、設計系統與 HTML 動態內容,輸出會落在自己的專案資料夾中。核心流程是 Brief、Template、Visual direction、Artifact、Memory,也就是從需求、模板、視覺方向一路走到可執行成品與可重用記憶。
為什麼可視為 Claude Design 的替代方案
比較項目 Claude Design Open Design 使用方式 Anthropic 託管的設計工作區 本機桌面程式、Agent、MCP 或自行部署 Agent 以 Claude 與 Claude Code 為核心 可接 Codex、Claude Code、Cursor、OpenCode、Qwen 等 檔案控制 畫布內建立後可匯出或交接 直接產生專案內可執行檔案 設計系統 可匯入程式庫與設計檔 使用可攜式 DESIGN.md 與 SKILL.md 授權與費用 Beta 功能包含在 Claude Pro、Max、Team、Enterprise Apache-2.0 開源,模型或 Agent 成本依所接服務而定
Claude Design 適合想要託管畫布、直接編輯與快速交接 Claude Code 的使用者,Open Design 則更適合重視本機檔案、可更換 Agent、可自行修改 Skill,以及希望沿用 Codex 工作方式的人。
Open Design 安裝與 Codex 用法
到 Open Design 下載頁 安裝 macOS、Windows 或 Linux 版本
桌面版建議登入後直接開始,官方下載頁標示不必另外設定 API Key
若要接 Codex,先到 Open Design 的 Settings,再進入 MCP server,複製 Codex 專用設定
若終端機的 od 指令確定指向 Open Design,也可以使用下方命令
git clone https://github.com/nexu-io/open-design
cd open-design
pnpm install macOS 內建另一個同名 od 指令,因此桌面版使用者以 Settings 裡提供的完整路徑設定最穩。完成後可以直接對 Codex 說:
請使用 open-design,依照我提供的品牌資料與參考網站,先建立 DESIGN.md,再產生一份 16 比 9 的互動式 HTML 產品簡報。請保留可編輯文字、響應式版面與鍵盤翻頁,完成後用瀏覽器檢查每一頁。可直接使用的繁體中文提示詞
以下內容已把可辨識的簡體中文提示改成繁體中文,並保留原本任務結構。方括號內的文字請換成自己的資料。
提示詞一:直接參考網站製作產品頁
請參考這個網站 [參考網址] 的設計風格,再根據我提供的資料,重製一個 [品牌與產品名稱] 的產品展示頁面。請保留品牌辨識度、響應式版面與可操作的互動效果。提示詞二:把參考素材拆成設計規則
你是一位專業的前端網站設計師。請幫我拆解並整理這個 [網站或圖片] 的設計風格,包括配色、字體、字級、留白、網格、圖片比例、卡片樣式與動畫方式。請提煉成一套明確、可執行的設計規則,並整理成 Markdown 格式的規則文件。提示詞三:使用規則產生 HTML
請根據 [我提供的內容],套用剛才整理完成的設計規則,製作一個互動性高的 HTML 網頁。請保留一致的配色、字體、網格、留白、圖片比例、卡片與動畫節奏,並確保桌面與手機版都能正常使用。提示詞四:用 ECharts 建立動態 GDP 排名
請載入 ECharts,幫我製作一個中國 2000 至 2025 年各省份年度 GDP 的動態長條圖。資料放在附件試算表中。請把下方範例程式碼換成附件資料,保持原有視覺樣式,最後用 HTML 呈現。畫面要精美、可互動,並提供播放、暫停、速度與年份控制。
[貼上從 ECharts 範例頁取得的程式碼]提示詞五:用 GSAP 改造作品集
這一段是依實際操作需求補全的繁體中文版本,適合直接交給 Codex:
請把我上傳的作品集改造成互動式 HTML 網頁,並使用 GSAP 實作卡片無限循環輪播。需要支援滑鼠與觸控拖曳、平滑吸附、拖曳時的動態回饋,以及上一個與下一個按鈕。請加入一鍵切換主題色功能,保留每張作品卡片的連結,並檢查手機版操作。提示詞六:把成熟版型封裝成 Skill
請根據這套已經驗證過的 HTML 設計風格,幫我封裝成一個可重複使用的 Skill。它需要記錄頁面的整體視覺風格、配色、字體、留白、元件樣式、圖表規範與動效原則,同時整理出封面頁、資料頁、功能拆解頁、案例頁與總結頁等常用頁面模板。
之後我只需要輸入主題、內容大綱、圖片與資料,任何相容的 AI Agent 就能自動套用這套規則,產生風格一致、可編輯、適合簡報展示的 HTML 頁面。
輸出 HTML 前,請自動檢查字體、顏色、間距、圖表樣式與頁面節奏是否統一。第一次建立自訂 Skill,可以先閱讀站內的 用 skill-creator 建立 Skill ,再把設計規則、資產與驗證流程拆成獨立檔案。
提示詞七:加入像 PPT 的可視化編輯功能
請在現有 HTML 中加入一套簡單的可視化編輯功能,支援直接點擊文字修改內容、拖曳元素調整位置、上傳圖片替換素材,並透過側邊欄統一修改字體、顏色、字級與動畫。
同時加入頁面複製、元件刪除、復原、重做與匯出 HTML 功能。編輯時顯示控制框,播放時自動隱藏。整體操作盡量接近傳統 PPT,不要破壞原有設計與動畫。提示詞八:補上主題色切換
請在既有編輯側欄加入主題色設定。提供四組預設色票與一個自訂色彩選擇器。修改後要同步更新頁面背景、卡片、按鈕、圖表與重點文字,同時維持足夠對比。請保留原有內容、互動與動畫。三個能大幅提升 HTML 簡報的前端工具
工具 官方網址 適合用途 建議用法 Apache ECharts echarts.apache.org 長條圖、折線圖、地圖、關係圖與資料看板 先從官方 Examples 找接近的範例,再把程式碼與資料表一起交給 Codex Spline spline.design 產品、空間、3D 模型與互動展示 建立或 Remix 場景,從 Export 取得公開網址或嵌入碼,再放進 HTML GSAP gsap.com 滾動敘事、拖曳、吸附、時間軸、文字與 SVG 動畫 先描述互動狀態與觸發條件,再讓 Codex 用 timeline 組織動畫
ECharts 不只負責把資料畫出來,還能讓篩選條件與簡報節奏同步。Spline 適合讓產品從靜態圖片變成可旋轉的物件。GSAP 則負責讓捲動、拖曳與狀態轉換具有一致節奏。三者一起使用時,先確認內容目標,再決定是否真的需要特效,避免互動比訊息更搶眼。
六個 HTML 與設計 Skill
安裝指令整理
npx skills add https://github.com/alchaincyf/huashu-design
npx skills add https://github.com/op7418/guizang-ppt-skill --skill guizang-ppt-skill
npx skills add https://github.com/lewislulu/html-ppt-skill
npx skills add https://github.com/Leonxlnx/taste-skill --skill design-taste-frontend UIUX Pro Max 目前建議安裝 ui-ux-pro-max-cli,再用 uipro init --ai codex 加入專案。更完整的 WordPress 使用方式可看 UIUX Pro Max 教學 。
npm install -g ui-ux-pro-max-cli
uipro init --ai codex frontend-slides 的 Claude Code Marketplace 指令與一般 Agent 不同。Codex 最簡單的方式是提供 GitHub 網址,要求它讀取 SKILL.md 與必要參考檔,再安裝到自己的 Skill 目錄。每個專案都可能更新,正式安裝前仍應以 GitHub README 為準。
設計靈感網站完整清單
使用靈感網站時,不要只丟首頁網址給 AI。最好指定一個實際案例,說清楚要借用的是資訊層級、網格、留白、字體或動畫,並列出不能照抄的品牌元素。需要從文字或圖片快速建立 UI,也可以延伸閱讀 Google Stitch 教學 。
最後的品質檢查
每頁是否只有一個主要訊息
字體是否已載入,中文與英文是否都有替代字型
圖表標籤、單位與資料來源是否清楚
動畫是否支援停止,是否干擾閱讀
滑鼠、鍵盤與觸控是否都能操作
桌面、平板與手機是否沒有溢出或遮擋
編輯模式與播放模式是否能明確切換
外部程式庫失效時是否有基本內容可看
輸出檔案是否保留來源與授權資訊
HTML 簡報的價值不是把 PPT 換成另一種檔案格式,而是把設計規則、資料、互動與驗證串成一條可重複執行的流程。先讓 Codex 理解規則,再讓它寫頁面,最後用瀏覽器檢查。當這套方法成熟後,再封裝成 Skill,下一份報告就不必重新教一次。
常見問題
Open Design 可以直接配合 Codex 嗎
可以。Open Design 官方列出 Codex 支援,桌面版可在 Settings 的 MCP server 取得 Codex 設定。產出仍會保留在本機專案目錄。
Open Design 完全免費嗎
Open Design 原始碼採 Apache-2.0。桌面下載頁提供登入後使用的官方模型路由,自行部署或 BYOK 模式則可能產生所接模型與 Agent 的費用。
HTML 簡報可以再輸出成 PPTX 嗎
部分 Skill 與 Open Design 提供 PPTX 或相關匯出能力,但複雜互動、3D 與 GSAP 動畫通常無法完整保留。需要保留互動時,建議直接交付 HTML。
最適合先安裝哪一個 Skill
要做一般網頁簡報可先看 frontend-slides。要快速選主題、版型與動畫可用 html-ppt-skill。要建立品牌化設計流程可研究 huashu-design。畫面總有模板感時,再加入 taste-skill 或 UIUX Pro Max。
參考資料
by Rain Chu 7 月 28, 2026 | AI , 語音合成
VibeVoice 現在不能只理解成一個文字轉語音模型,它已經變成 Microsoft 的開源語音模型家族,包含長音訊語音辨識、即時串流 TTS、長篇多人 TTS,以及最新的 CPU 量化辨識版本,值得注意的地方,不只是能把文字念出來,而是它開始把「聽懂一小時內容」與「收到文字後立刻開口」做成兩條可以獨立部署的路線。
先講我的結論。如果要做會議轉錄、訪談整理或字幕,先看 VibeVoice-ASR。如果只有一般電腦,優先測試 VibeVoice-ASR-BitNet。如果要讓 Agent 邊產生答案邊說話,選 VibeVoice-Realtime-0.5B,至於能合成 90 分鐘、最多四人對話的 VibeVoice-TTS-1.5B,目前官方快速體驗仍標示為停用,不能把社群整合包的功能直接當成官方現況。
VibeVoice 四個版本怎麼選
模型 主要工作 適合場景 部署重點 VibeVoice-ASR-7B 長音訊轉文字 會議、訪談、字幕、多人對話 可一次處理最長 60 分鐘,完整模型需要較多 GPU 記憶體 VibeVoice-ASR-BitNet CPU 語音辨識 桌機、Mac、邊緣設備、離線轉錄 模型約 1.58 GB,不需要 GPU VibeVoice-Realtime-0.5B 即時文字轉語音 語音 Agent、即時旁白、串流回應 單一說話人,英文為主要目標,其他語言仍屬實驗 VibeVoice-TTS-1.5B 長篇多人語音合成 Podcast、有聲內容、多人對話 原始能力可達 90 分鐘與四位說話人,但官方程式與快速體驗目前停用
VibeVoice 的核心不是單純縮小模型
VibeVoice 使用聲學與語意連續語音 tokenizer,運作頻率只有 7.5 Hz,這代表模型不需要把長音訊展開成極密集的離散 token,處理長序列時比較節省,生成端再用 next-token diffusion,把語言模型負責的文字脈絡與對話流程,交給 diffusion head 補上聲學細節。
這個架構帶來兩個很實際的能力。ASR 可以在 64K token 長度內一次接收最長 60 分鐘音訊,輸出誰在什麼時間說了什麼。
Realtime TTS 則採用交錯的視窗設計,一邊接收新增文字,一邊延續前文產生聲音,讓 LLM 不必等完整答案寫完才開始說話。
如果正在組本地語音 Agent,可以把它放進 speech-to-speech 的 VAD、STT、LLM、TTS 管線 。VibeVoice-ASR 負責聽,Realtime 負責說,中間的 LLM 可以換成本地模型。這比把整套功能綁死在單一 App 裡更容易維護。
ASR 不只是逐字稿,還會分辨說話人
一般 Whisper 工作流常要再接一套 speaker diarization,才能把不同說話人分開。VibeVoice-ASR 把語音辨識、說話人分離與時間戳放進同一個輸出,直接得到 Who、When、What 的結構。對會議記錄、Podcast 整理、客服通話和長篇訪談,這比單純吐出一整段文字更有用。
它也支援自訂 hotwords,可以先提供人名、產品名、技術術語與背景資料,減少專有名詞被聽錯的機率。官方 Transformers 版本支援超過 50 種語言,也能處理語句內與語句間的語言切換。這讓 Python 整合不必依賴特定 WebUI。
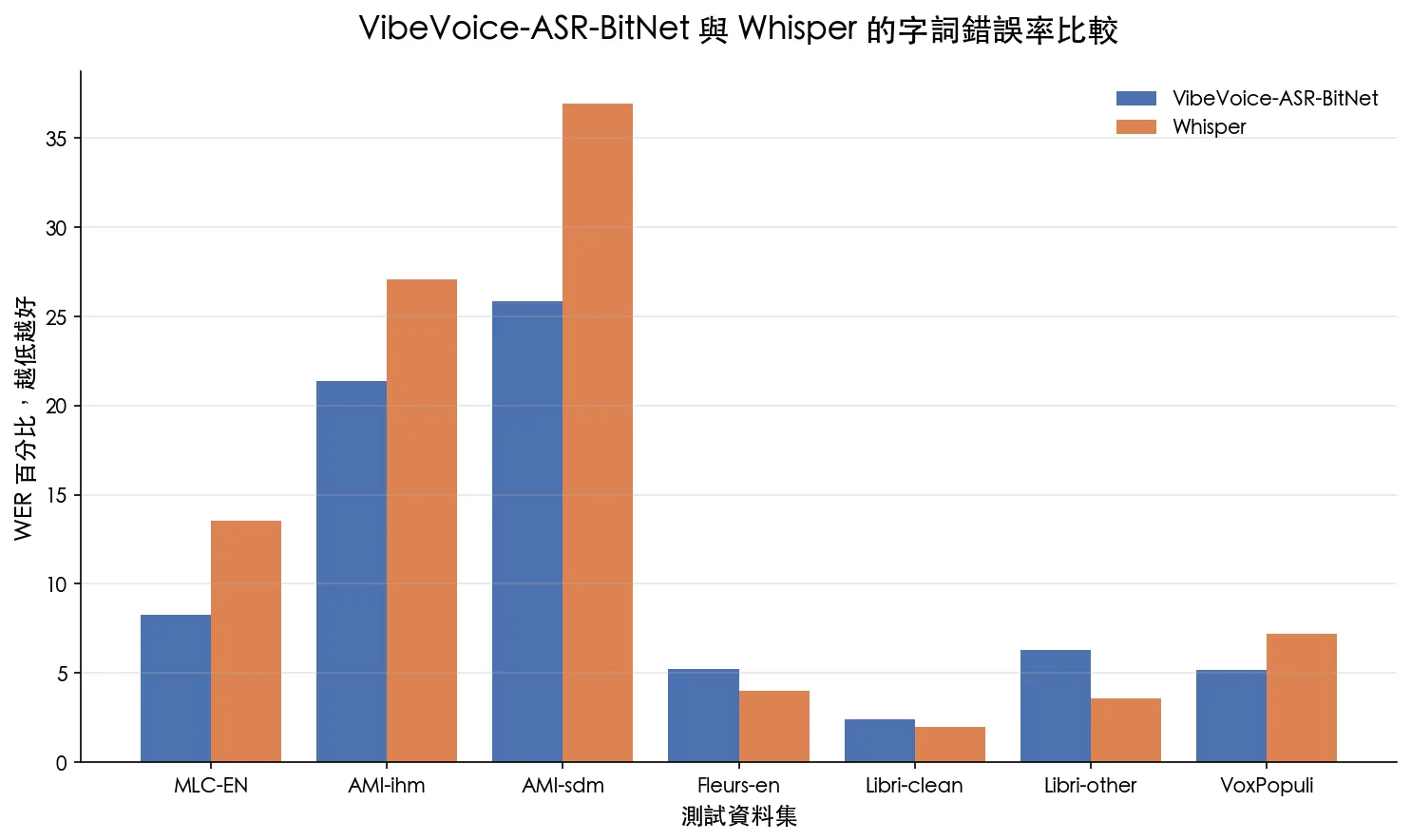
VibeVoice 真的比 Whisper 快又準嗎
答案不是單純的「是」,Microsoft 公布的 CPU BitNet 測試中,在 AMD EPYC 7V13 上使用三條 CPU 執行緒時,RTF 為 0.77,已經快於即時播放速度,四條執行緒降到 0.63。Apple M4 使用四條執行緒的 RTF 為 0.43。這些結果證明 CPU 即時辨識成立,但不同處理器、音訊長度與編譯方式都會影響速度。
官方 WER 測試顯示兩個模型各有優勢,數值越低越好 準確率也要分資料集看。BitNet 在 MLC-EN、AMI-ihm、AMI-sdm 與 VoxPopuli 的 WER 低於 Whisper,但在 Fleurs-en、Libri-clean 與 Libri-other 則是 Whisper 較低。所以比較正確的說法是,VibeVoice-ASR-BitNet 在多說話人與部分長音訊測試很有競爭力,不能直接延伸成所有語言、所有錄音條件都勝過 Whisper。
如果目前的工作流已經大量使用 Whisper,可以先看我整理的 Whisper 本地語音辨識 ,再拿自己的中文會議、多人訪談與背景噪音資料做同一套測試。真正有意義的是自己的素材,不是只看單一排行榜。
最省硬體的做法,用 VibeASR.cpp 跑 BitNet
只想在 CPU 上完成轉錄,官方的 VibeASR.cpp 是目前最直接的路線。需要 Python 3.9 以上、CMake 3.14 以上,以及 GCC 或 Clang。Windows 需要 MinGW-w64,MSVC 目前不支援。
git clone --recursive https://github.com/microsoft/VibeASR.cpp.git
cd VibeASR.cpp
pip install -r requirements.txt
python setup_env.py 準備一個 WAV 音檔後,用四條 CPU 執行緒開始轉錄。
./build/bin/asr_infer \
--vae-model models/vibeasr/vibeasr-vae-encoder-i8_s.gguf \
--lm-model models/vibeasr/vibeasr-lm-i2_s-embed-q6_k.gguf \
--audio input.wav -t 4 模型頁也提供 Ollama 的啟動方式。這條命令適合先快速取得模型,若要穩定處理音訊檔與調整執行緒,VibeASR.cpp 的 CLI 參數會更清楚。
ollama run hf.co/microsoft/VibeVoice-ASR-BitNet:Q6_K 用 Transformers 在 Python 呼叫 ASR
需要接進自己的 Python 程式時,使用 Transformers 5.3.0 以上的官方模型最乾淨。完整 ASR 權重較大,先確認顯卡記憶體與磁碟空間,不要把 Realtime 0.5B 的硬體需求套過來。
python -m venv .venv
source .venv/bin/activate
pip install transformers==5.3.0 accelerate soundfile from transformers import AutoProcessor, VibeVoiceAsrForConditionalGeneration
model_id = "microsoft/VibeVoice-ASR-HF"
processor = AutoProcessor.from_pretrained(model_id)
model = VibeVoiceAsrForConditionalGeneration.from_pretrained(
model_id,
device_map="auto"
)
inputs = processor.apply_transcription_request(
audio="input.wav"
).to(model.device, model.dtype)
output_ids = model.generate(**inputs)
generated_ids = output_ids[:, inputs["input_ids"].shape[1]:]
result = processor.decode(generated_ids, return_format="parsed")[0]
for item in result:
print(item)
如果要讓多人共用,官方還提供 vLLM 外掛,對外開出 OpenAI 相容的 /v1/chat/completions 端點,並支援串流、長音訊、hotwords、資料平行與張量平行。這條路比較適合公司內部的集中式轉錄服務。
啟動 Realtime 0.5B 即時 TTS
Realtime 版本的價值是讓 LLM 還在產生文字時就開始發聲。官方資料寫的是約 200 毫秒產生第一段聲音,但實際聽到的時間還會加上網路與播放緩衝。官方測試中 NVIDIA T4 與 Mac M4 Pro 可以達到即時速度,這不代表每一台 Mac 或每張 6GB 顯卡都一定相同。
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice
python -m venv .venv
source .venv/bin/activate
pip install -e ".[streamingtts]"
python demo/vibevoice_realtime_demo.py \
--model_path microsoft/VibeVoice-Realtime-0.5B Realtime 0.5B 目前只支援單一說話人,英文仍是主要目標。德文、法文、義大利文、日文、韓文、荷蘭文、波蘭文、葡萄牙文與西班牙文屬於實驗音色。中文長篇多人合成若來自社群分支或整合包,應分開標示版本與來源。想比較更偏聲音克隆的方案,可以延伸看 dots.tts 的 3 秒聲音復刻架構 ,若重點是音色設計,則可以看 Qwen3-TTS 的音色控制 。
文字正規化是長篇 TTS 的必做前處理
長篇語音最常見的問題不是音色,而是日期、金額、百分比、網址與特殊符號被念錯。輸入「2026/7/28」與輸入「二零二六年七月二十八日」,模型收到的任務並不相同。正式生成前應先清理 Markdown、程式碼、罕見符號與過度複雜的標點,再把數字轉成預期的口語形式。
from wetext import Normalizer
normalizer = Normalizer(lang="zh", operator="tn")
text = normalizer.normalize("2026年7月28日,版本 1.0")
print(text) WeText 可以做中文、英文與日文的 TN 和 ITN。它不是萬能修正器,品牌名、縮寫與人名仍要自行建立字典。這一步也適合放在 Voicebox 本地 AI 語音工作室 這類批次工作流前面,避免同一個錯誤被大量生成。
安裝時最容易卡住的地方
PyTorch 裝成 CPU 版 :先用 python -c "print(__import__('torch').cuda.is_available())" 檢查,再依自己的 CUDA 版本重裝官方 PyTorch 套件。把所有版本當成同一套需求 :ASR-7B、Realtime-0.5B 與 BitNet 的模型大小和執行後端完全不同。把社群功能當成官方保證 :自訂音色、中文多人 TTS 與一鍵整合包要確認來源、commit 與安全性。忽略 FFmpeg :Gradio 與長音訊服務通常需要 FFmpeg 解碼,先確認 ffmpeg -version 能正常執行。直接丟進正式產品 :Microsoft 明確把目前版本定位在研究與開發用途,正式商用前要自行測試準確率、延遲、授權與風險。
我會怎麼選
VibeVoice 最有價值的不是某一個模型贏過所有對手,而是它把語音工作拆成幾個明確層級。只有 CPU 就用 BitNet。需要長音訊、說話人與時間戳,就用完整 ASR。需要 Agent 邊想邊說,就用 Realtime。需要中文音色克隆與更強的角色控制,則把 dots.tts、Qwen3-TTS 或其他本地 TTS 放進比較名單。
我特別喜歡 BitNet 這次的方向。它不是叫使用者為了語音辨識再買一張顯卡,而是透過量化與專用 CPU runtime,把模型帶回一般電腦。這種改進比單純把參數做大更接近真正能落地的本地 AI。
官方資源
FAQ
VibeVoice 可以完全離線使用嗎
可以。模型與依賴下載完成後,VibeASR.cpp、Transformers ASR 與 Realtime TTS 都可以在本地執行。第一次安裝與下載權重仍需要網路。
6GB 顯存可以跑所有 VibeVoice 模型嗎
不可以。6GB 是特定 TTS 或 Realtime 組合的實測條件,完整 ASR 權重需要更多資源。只有一般電腦時,CPU 版 BitNet 是更合理的起點。
VibeVoice-Realtime 支援中文嗎
官方目前仍把英文列為主要目標,另提供九種實驗語言,名單不含中文。社群版本可能加入中文或自訂音色,但要分開看待。
by Rain Chu 7 月 28, 2026 | AI , skills , Tool , 圖型處理
AI Agent 很會理解「月份、營收、百分比變化」代表什麼,卻不一定能穩定處理座標軸、刻度、色階、標籤間距與版面配置,直接要求模型輸出完整 Vega-Lite 或 ECharts 規格,常見結果不是設定冗長,就是參數彼此衝突,甚至渲染後只得到空白畫布。
Flint Chart 的做法,是讓 AI 只負責描述資料的意義與圖表意圖,再由確定性的編譯器完成幾何與渲染細節 ,這不只是圖表工具的改良,也是一種值得用在 AI Agent 系統的架構。模型產生小型、可驗證的中介格式,程式再負責執行可重現的工作。
如果你正在用 Codex 製作視覺內容,可以先參考站內的Codex 動態圖表與短影音工作流程 ,Flint 則更專注在資料圖表的語意、驗證與多後端輸出。
Flint Chart 是什麼
Flint 是微軟研究院與中國人民大學 IDEAS Lab 合作開發的開源視覺化中介語言,它不是另一套直接把圖畫到畫布上的函式庫,而是位在 AI Agent 與 Vega-Lite、Apache ECharts、Chart.js、Plotly、Excel 之間的語意層。
AI Agent 判斷欄位代表月份、價格、利潤、國家、排名或百分比變化Flint 規格 保存資料、語意型別、圖表種類與欄位映射Flint 編譯器 推導日期解析、聚合、刻度、色彩、標籤與版面繪圖後端 接收原生規格並渲染互動圖表、PNG、SVG 或 Excel 原生圖表
截至 2026 年 7 月 28 日,官方 GitHub 顯示 JavaScript 與 TypeScript 函式庫已能輸出 Vega-Lite、ECharts、Chart.js、Plotly 與 Office.js 使用的 Excel 原生圖表。7 月 11 日的 iThome 報導只列出前三種,是因為後續 0.4.0 版才加入 38 種 Plotly 圖表與 18 種可編輯 Excel 範本。
為什麼 AI 直接產生圖表容易失敗
製作圖表其實包含兩種不同工作。第一種是理解語意,例如 revenue 是金額,month 是年月,growth 是百分比變化。第二種是安排幾何,例如軸的範圍、刻度密度、文字旋轉、圖例位置與色彩映射。
語言模型擅長第一種工作,第二種工作卻牽涉許多互相依賴的數值與規則。Flint 把兩者拆開後,AI 不必一次猜完所有低階設定。規格也從難以檢查的大段設定,縮成可閱讀、可修改、可在渲染前驗證的小型 JSON。
模型負責意義,編譯器負責數學。真正的價值不是少寫幾行,而是讓每一步都能被驗證與重現。
Flint 規格的三個核心部分
一份 Flint 輸入主要由資料、semantic_types 與 chart_spec 組成。下面用季度營收長條圖示範最小結構。
{
"data": {
"values": [
{ "quarter": "Q1", "revenue": 1200 },
{ "quarter": "Q2", "revenue": 1450 },
{ "quarter": "Q3", "revenue": 980 },
{ "quarter": "Q4", "revenue": 1800 }
]
},
"semantic_types": {
"quarter": "Quarter",
"revenue": "Price"
},
"chart_spec": {
"chartType": "Bar Chart",
"encodings": {
"x": { "field": "quarter" },
"y": { "field": "revenue" }
},
"baseSize": { "width": 480, "height": 320 }
}
}
data 可以直接放入列資料,也能在本機 MCP 模式下引用 JSON、CSV 或 TSV 檔案。semantic_types 告訴編譯器每個欄位的實際意義。chart_spec 則決定圖表種類,以及欄位要放在 x、y、color、size、shape、column、row、group 或 detail 等通道。
語意型別可以重複使用。探索同一份資料時,多半只要更換 chart_spec。例如把 Quantity 改成 PercentageChange,編譯器就能改用適合正負變化的發散色階、百分比格式與對應的軸設定。這比每次都讓模型重新生成完整圖表設定更穩定。
在 Codex 安裝 Flint MCP
本機版本需要 Node.js 18 以上。Codex 可以用一行命令加入 stdio MCP 伺服器。
codex mcp add flint -- npx -y flint-chart-mcp接著確認伺服器是否已經出現在清單。
codex mcp list如果資料不需要從本機檔案讀取,可以關閉檔案引用。這個設定要求代理把資料列直接放進 data.values,能縮小不受信任工作流程的檔案存取範圍。
codex mcp add flint-safe -- npx -y flint-chart-mcp --disable-file-reference官方也提供遠端 MCP 端點,適合只能連接 HTTP MCP 的客戶端。處理私有資料時,仍建議優先選擇本機 stdio 版本。
codex mcp add flint-remote --url https://flint.data-formulator.ai/mcp第一次使用的提示詞
安裝後不要只下「幫我畫圖」。把資料來源、語意、圖表目的、驗證方式與輸出格式一起交代,結果會更可靠。
請載入 flint://agent-skill,並呼叫 list_chart_types 檢查 vegalite 後端是否可用。讀取目前資料夾的 sales.csv,把 month 判定為 YearMonth,revenue 判定為 Price,growth 判定為 PercentageChange。先用 validate_chart 驗證,再建立每月營收折線圖,並用顏色標示成長率。若支援 MCP Apps 就使用 create_chart_view,否則用 render_chart 輸出 SVG。最後列出所有警告與被截斷的資料。
Flint MCP 提供五個主要工具。create_chart_view 適合互動調整,validate_chart 用來檢查規格與警告,render_chart 產生 PNG 或 SVG,compile_chart 回傳後端原生 JSON,list_chart_types 則用來確認可用的圖表與通道。
這套做法和讓 Codex 用 Playwright CLI 操作瀏覽器 有相同精神。模型不必自己模擬每個底層步驟,而是呼叫邊界清楚、結果可檢查的工具。
在 JavaScript 與 TypeScript 專案使用
若你正在開發產品,而不是只在對話中產生圖表,可以直接安裝函式庫。
npm install flint-chartimport { assembleVegaLite } from "flint-chart"
const input = {
data: { values: myData },
semantic_types: {
weight: "Quantity",
mpg: "Quantity",
origin: "Country"
},
chart_spec: {
chartType: "Scatter Plot",
encodings: {
x: { field: "weight" },
y: { field: "mpg" },
color: { field: "origin" }
},
baseSize: { width: 400, height: 300 }
}
}
const spec = assembleVegaLite(input) 相同輸入可以交給 assembleECharts、assembleChartjs、assemblePlotly 或 assembleExcel。後端若不支援指定圖表,組裝器會在渲染前拋出錯誤,因此產品端應先查詢範本支援狀態,再把錯誤與警告顯示給使用者。
Excel 原生圖表特別適合需要後續人工編輯的報表工作。如果工作流程還包含 Word、PowerPoint 或試算表處理,可以延伸閱讀OfficeCLI 與 AI Agent 的 Office 自動化教學 。
Flint、Vega-Lite、Mermaid 與一般 Chart MCP 的差異
工具 主要用途 AI 要處理的細節 適合情境 Flint 語意中介格式與編譯 資料意義、圖表意圖與欄位映射 需要可靠生成、多後端與可驗證規格 Vega-Lite 統計視覺化文法 較完整的編碼、比例尺與版面設定 需要精細控制與成熟生態 Mermaid 流程圖與軟體圖解 節點、關係與圖形語法 架構圖、流程圖與文件 一般 Chart MCP 把特定繪圖服務包成工具 視工具設計而定 已有固定渲染服務或單一後端
Flint 並不是 Vega-Lite 的替代品,因為它可以直接編譯成 Vega-Lite 規格。它處理的是更前面的一層,讓模型先表達「這些資料是什麼」,再由編譯器決定「如何正確畫出來」。
目前限制與使用前要知道的事
仍是研究專案 官方論文尚未正式公開,產品決策不能只靠宣傳數字Python 套件尚未發布 目前只有原始碼預覽,正式套件仍以 JavaScript 與 TypeScript 為主後端支援並不完全相同 同一圖表不一定能在所有後端輸出,MCP 指南目前列出的編譯後端仍以 Vega-Lite、ECharts 與 Chart.js 為主Flint 不負責完整資料整理 聚合、過濾、關聯、樞紐與衍生欄位最好先在上游完成自動版面可能截斷資料 離散項目超過空間預算時會套用保留策略,整合端必須顯示 _warnings本機渲染仍要管理權限 預設會讀取代理指定的本機檔案,不受信任的環境應啟用 –disable-file-reference
iThome 整理的測試顯示,Flint 在 GPT-5.1、GPT-5-mini 與 GPT-4.1 三組 LLM 評分中,都優於直接產生完整 Vega-Lite 規格的 DirectVL。不過官方仍標示研究論文即將公開,因此比較結果適合視為早期證據,不能取代自己的資料集與視覺驗收。
真正值得帶走的是代理系統的分工方式
Flint 最值得學習的不只是圖表規格,而是代理系統的分工。讓模型輸出小型、結構化、可以先驗證的意圖,再讓確定性程式負責計算、渲染與錯誤處理。這個模式也能延伸到 UI 元件、文件排版、測試流程與自動化操作。
但「成功回傳 JSON」不等於任務完成。視覺工作必須真的渲染,再檢查畫布是否空白、文字是否重疊、顏色是否誤導、資料是否被截斷。AI Agent 的可靠性,來自可驗證的中介格式與最後一哩的實際驗收,而不是更長的提示詞。
常見問題
Flint 可以取代 ECharts 或 Vega-Lite 嗎
不會。Flint 是位在 AI 與繪圖函式庫之間的中介語言,最後仍會輸出 ECharts、Vega-Lite 等後端可使用的原生規格。
Flint MCP 會把資料上傳到外部服務嗎
本機 stdio 版本會在主機上執行,內嵌資料與本機檔案不會送到遠端渲染服務。若改用官方 HTTP 端點,資料會透過遠端連線處理,因此敏感資料仍應優先採用本機版本。
Codex 看不到互動圖表怎麼辦
create_chart_view 需要客戶端支援 MCP Apps。若目前介面不支援,可以要求 Flint 使用 render_chart 輸出 SVG 或 PNG,再直接檢查成品。
Flint 適合什麼工作
它適合需要大量產生資料圖表、希望規格可被人工修改、需要切換不同後端,或不能接受偶發空白與錯誤圖表的 Agent 工作流程。若只是一次性的簡單圖表,現有大型模型或熟悉的圖表函式庫可能已經足夠。
參考資料
by Rain Chu 7 月 23, 2026 | AI , 語音分離 , 語音合成 , 語音辨識
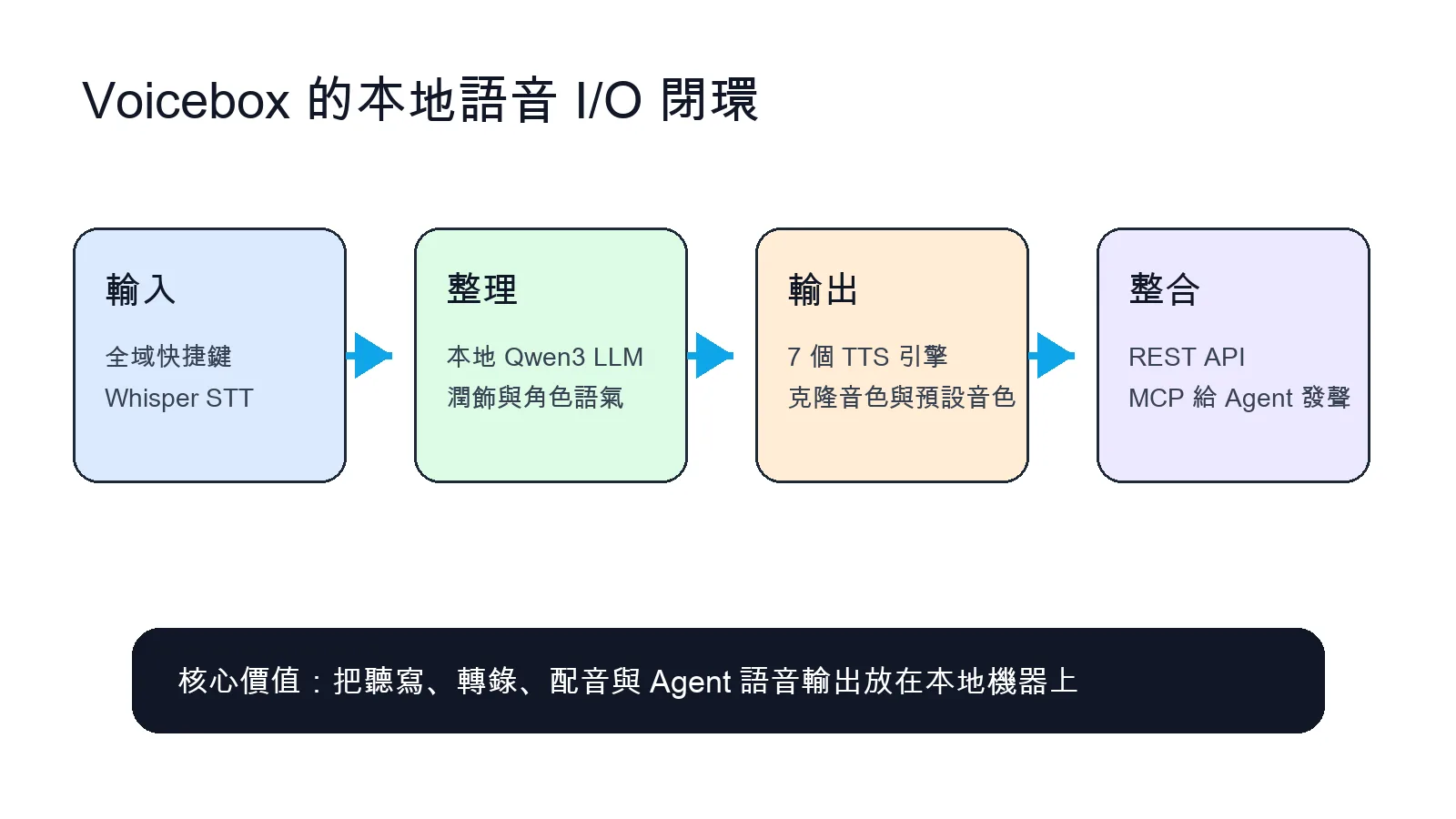
Voicebox 最吸引我的地方,是它不是只做 TTS,也不是只做 Whisper 聽寫,而是把語音輸入、語音輸出、聲音克隆、故事編輯器、REST API 和 MCP server 放在同一個本地優先的工具裡。這讓 AI Agent 不只會回文字,也能用你指定的音色說話。
如果說過去的語音工具常常分成兩邊,ElevenLabs 偏輸出,WisprFlow 偏輸入,那 Voicebox 想做的是完整 voice I/O stack。更重要的是,它預設把模型、聲音資料和錄音留在本機,這對語音克隆和工作資料來說很關鍵。
先講結論
Voicebox 是 Jamie Pine 開源的 AI voice studio,官方定位是 local-first。它可以做文字轉語音、聲音克隆、全域快捷鍵聽寫、Whisper 轉錄、故事多軌編輯,還能透過 REST API 和 MCP server 讓 Claude Code、Cursor、Cline 這類 MCP-aware agent 發聲。
我會把它放在「本地語音 AI 底座」這一類,之前整理過 audio.cpp 本地語音 AI WebUI 和 Hugging Face speech-to-speech 本地語音 Agent ,Voicebox 則更偏向桌面應用和創作者工具,並且把 Agent 整合做得很直接。
Voicebox 把聽寫、轉錄、配音和 Agent 語音輸出放在同一個本地工具裡。 Voicebox 在補語音 AI 的哪一塊
很多語音工具只有單點能力。TTS 工具能把文字變聲音,但不一定能做聽寫。STT 工具能轉錄,但不一定能配音。聲音克隆工具效果強,但常常依賴雲端 API。Voicebox 的取向比較完整:輸入端用 Whisper,輸出端有多個 TTS 引擎,中間還有本地 Qwen3 LLM 做潤飾、角色語氣和 persona。
這種整合方式很適合兩種人:
第一種是內容創作者,想做旁白、podcast、故事對話、角色音色。
第二種是 AI Agent 使用者,想讓 Claude Code、Cursor 或自己的工具在完成任務後,用指定聲音提醒你,而不是只丟一段文字。
7 個 TTS 引擎和 23 種語言
官方 README 列出 7 個 TTS 引擎:Qwen3-TTS、Qwen CustomVoice、LuxTTS、Chatterbox Multilingual、Chatterbox Turbo、HumeAI TADA 和 Kokoro。它們的定位不同,有的適合多語言克隆,有的適合 CPU 快速推理,有的適合加入情緒標籤和語氣控制。
能力 Voicebox 的做法 適合用途 高品質 TTS Qwen3-TTS、Chatterbox、HumeAI TADA 等引擎 旁白、教學、產品介紹 聲音克隆 用參考音訊做 zero-shot cloning 個人聲音、角色聲音、品牌聲線 快速預設音色 Kokoro 和 Qwen CustomVoice 提供 50+ 音色 快速試稿、多角色對話 語音輸入 全域快捷鍵加 Whisper STT 聽寫、轉錄、工作筆記
如果你對開源 TTS 的音色設計有興趣,可以搭配看 Qwen3-TTS 的音色設計整理 和 dots.tts 聲音復刻架構 。Voicebox 比較像把這些能力打包成桌面工作台,而不是單一模型 demo。
聲音克隆和預設音色的差別
聲音克隆適合你有一段參考音訊,想生成相似聲線。預設音色適合你只是要快速找一個可用聲音,不想準備樣本。Voicebox 同時支援兩種路線,這點很實用。創作者可以先用預設音色打草稿,確定文本節奏後,再換成克隆音色做正式版本。
但聲音克隆也有界線。它很適合克隆你自己擁有權利的聲音,或明確授權的角色聲音。不要拿來模仿名人、同事或客戶聲音做未授權內容。語音模型越容易使用,倫理和授權越要先想清楚。
Whisper 聽寫補上輸入端
Voicebox 的另一半是輸入。它用 OpenAI Whisper 做 speech-to-text,支援全域 dictation hotkey、push-to-talk 和 toggle mode。macOS 上可以把轉錄結果直接貼到目前焦點文字欄位,這會讓它接近一個本地版語音輸入法。
Whisper 對長音訊和技術內容一直很適合。如果你常做訪談、會議紀錄、口述筆記,Voicebox 把 captures、replay、re-transcribe、refine 放在同一個介面裡,會比單純命令列轉錄更順。這裡也可以延伸看之前整理的 Whisper 開源語音轉文字 。
MCP 讓 Agent 真的開口說話
Voicebox 最有意思的一點,是內建 MCP server,官方 README 寫到它提供 `voicebox.speak`、`voicebox.transcribe`、`voicebox.list_captures`、`voicebox.list_profiles` 四個工具,這代表 MCP-aware agent 可以呼叫 Voicebox,把文字變成指定音色播放出來,也可以讀取 captures 和 voice profiles。
這不只是好玩。Agent 的語音輸出可以拿來做任務完成提醒、錯誤警告、長任務回報、pair programming 對話。你甚至可以把不同 agent 綁定不同聲音,例如 Claude Code 用一個音色,Cursor 用另一個音色,聽聲音就知道是哪個工具在回報。
{
"tool": "voicebox.speak",
"arguments": {
"text": "任務完成,測試已通過",
"profile": "Morgan"
}
} 如果你已經在玩 Playwright CLI 讓 Codex 操作瀏覽器 ,Voicebox 可以補上另一個感官通道。Agent 不只可以操作網頁,也能在完成後直接用語音提醒你。
Stories editor 適合做多角色內容
Voicebox 也有 Stories editor,可以做 conversation、podcast、narrative 這類多段落、多角色內容。這對部落格轉 podcast、教學腳本、角色對話、短劇旁白都很有用。比起一次產生一整段音訊,多軌 timeline 更適合慢慢調整角色、節奏和轉場。
如果你平常會把文章轉成短影片或語音內容,Voicebox 可以放在內容工作流後段。先由 Agent 整理稿件,再用 Voicebox 做角色分配和配音,最後再進剪輯工具。
安裝與使用入口
Voicebox 官方網站是 voicebox.sh ,GitHub repo 是 jamiepine/voicebox 。官方 README 提供 macOS Apple Silicon、macOS Intel 和 Windows 下載入口,也有開發者本地建置方式。
我會怎麼用
我不會只把 Voicebox 當成免費配音工具:
更有價值的用法,是把它接進 AI Agent 工作流,平常寫文章、整理筆記、跑 Codex、跑 Claude Code,最後都可以由 Voicebox 轉成語音摘要。長任務完成時不用一直盯螢幕,讓 Agent 開口提醒就好。
第二個用法是做內容實驗,先用預設音色快速產出版本,再用克隆音色做正式版。
第三個用法是本地聽寫,把口述想法直接丟進任何 app,再交給 Agent 整理。這會比只靠鍵盤更接近自然工作流。
我的判斷
Voicebox 不是單一模型展示,而是把語音 AI 變成桌面工作台。它的亮點不是某個 TTS 引擎本身,而是整合:本地隱私、TTS、STT、故事編輯、聲音 profile、REST API、MCP server。
如果你只需要偶爾產一段聲音,線上 TTS 服務可能更快。但如果你想要長期建立自己的聲音素材庫、做本地聽寫、讓 Agent 用聲音回報任務,Voicebox 會是值得試的工具。
延伸資源
FAQ
Voicebox 是什麼?
Voicebox 是開源的本地優先 AI 語音工作室,可以做 TTS、聲音克隆、Whisper 聽寫轉錄、故事編輯和 MCP Agent 語音輸出。
Voicebox 可以離線使用嗎?
官方定位是 local-first,模型、聲音資料和 captures 會留在本機。實際能否完全離線,取決於你是否已下載需要的模型和使用的引擎。
Voicebox 支援哪些 TTS 引擎?
官方列出 Qwen3-TTS、Qwen CustomVoice、LuxTTS、Chatterbox Multilingual、Chatterbox Turbo、HumeAI TADA 和 Kokoro。
Voicebox 可以接 Claude Code 或 Cursor 嗎?
可以。Voicebox 內建 MCP server,MCP-aware agent 可以使用 `voicebox.speak`、`voicebox.transcribe`、`voicebox.list_captures` 和 `voicebox.list_profiles`。
by Rain Chu 7 月 20, 2026 | Agent , AI , API , Tool
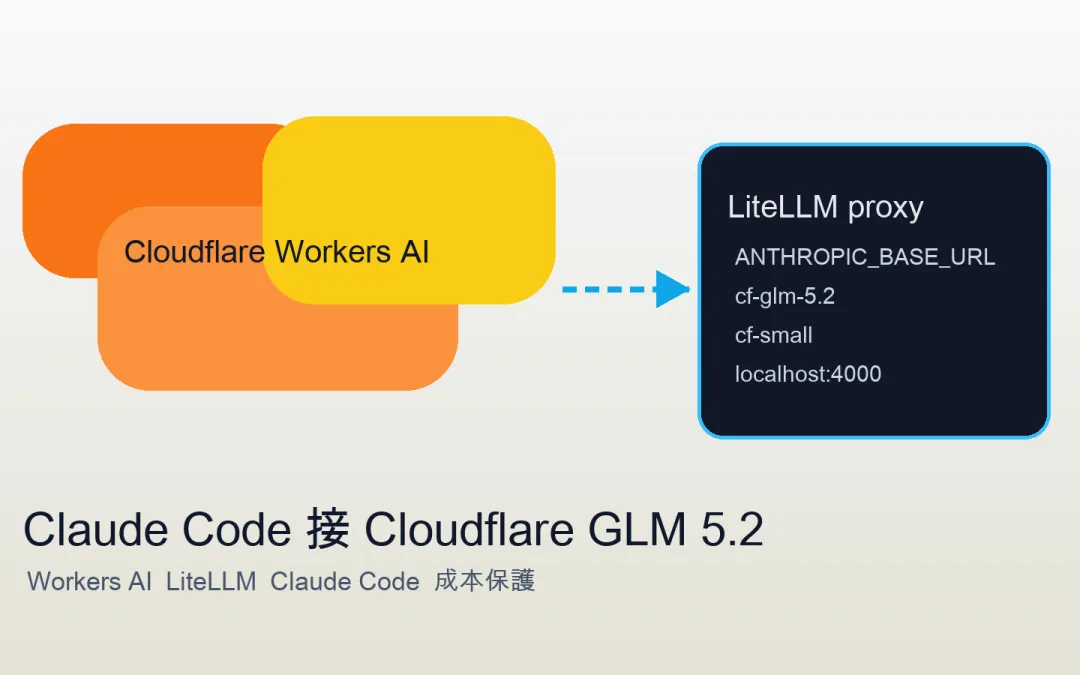
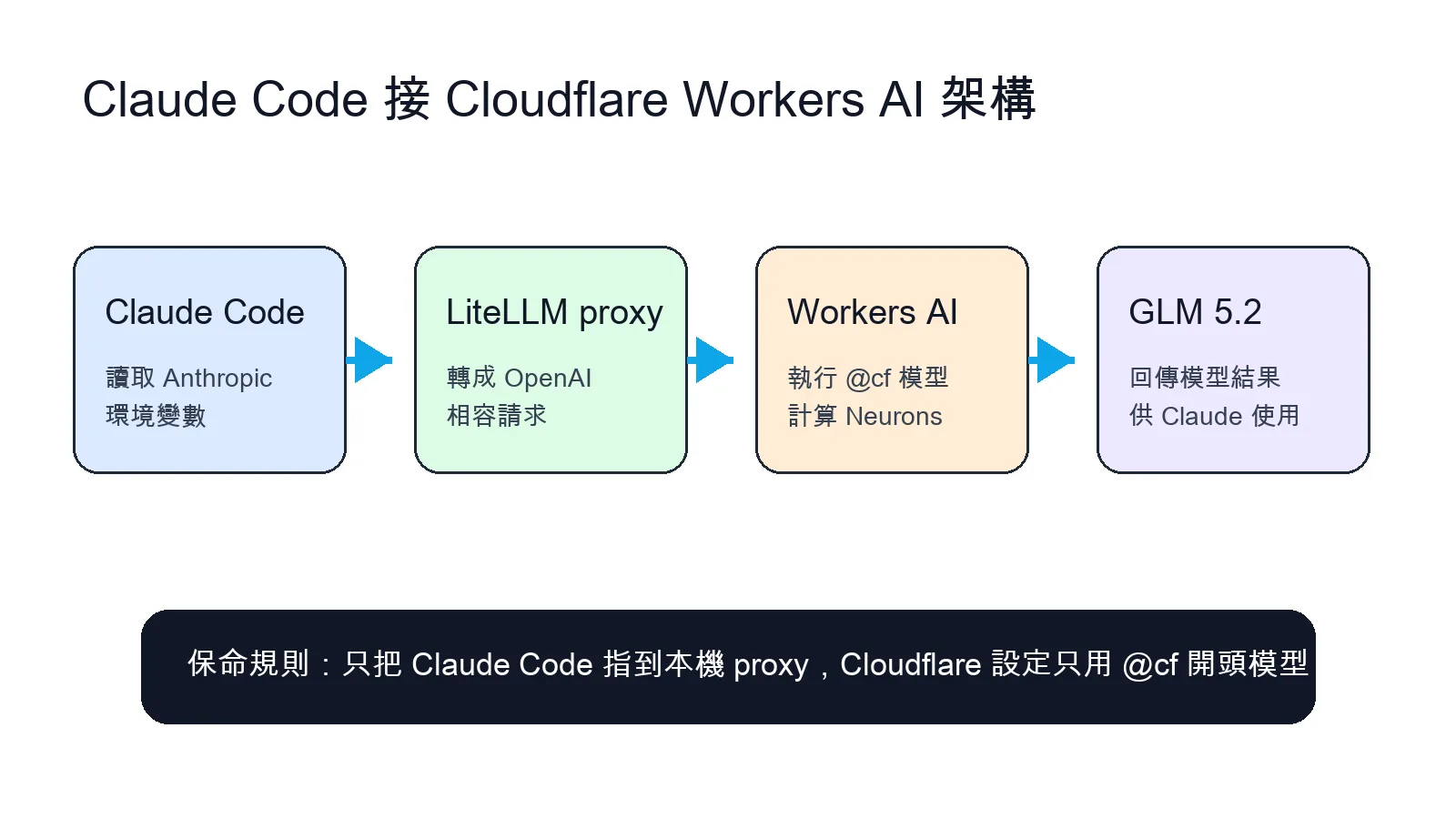
Cloudflare Workers AI 拿來接 Claude Code 的做法很簡單:Cloudflare 跑模型,LiteLLM 在本機當轉接橋,Claude Code 只需要改 Anthropic 相關環境變數,就能把請求送到本機 proxy。
這篇整理的是一個比較務實的路線。它不是要你把所有模型成本都消失,而是讓你知道免費額度在哪裡、帳單風險在哪裡、命令怎麼下、哪些設定一定要看清楚。
先講結論
Cloudflare Workers AI 有免費額度,官方價格頁寫明 Free plan 每天有 10,000 Neurons,GLM 5.2 目前也在 Cloudflare Workers AI 模型列表裡,可以透過 Cloudflare API 呼叫。這代表你可以把 Claude Code 的模型入口改成本機 LiteLLM proxy,再由 LiteLLM 轉送到 Cloudflare 的 @cf/zai-org/glm-5.2。
但「免費」不是「無限」,Cloudflare 的計費單位是 Neurons,免費額度用完後會受到方案限制,更重要的是,Cloudflare AI Gateway 也能接外部模型,如果你把 OpenAI 或 Anthropic 這類外部模型接進去,那就不再是 Cloudflare Workers AI 的免費模型邏輯,帳單會回到外部供應商那邊。
Claude Code 只改成本機 Anthropic 入口,真正的模型請求由 LiteLLM 轉到 Cloudflare Workers AI。 這個架構在解什麼問題
Claude Code 很好用,但長時間寫程式、重構、跑測試、修錯時,模型成本會變得很有感。若只是一些低風險任務,例如產生腳手架、改小工具、做簡單 demo、先跑一輪想法,Cloudflare Workers AI 的免費額度可以拿來當低成本緩衝層。
這和 用 Claude Code 搭配 LM Studio 與 Ollama 的思路很像,只是這次不是跑本地模型,而是把免費雲端額度接進本機開發流程。若你的工作流已經在用 Claude Code、Codex 和 skill 組合工作流 ,這種 proxy 入口會很有彈性。
完整操作命令
下面命令以 macOS 或 Linux 為主。你需要先有 Cloudflare 帳號,並在 Cloudflare dashboard 取得 Account ID 和 API Token。API Token 建議只給 Workers AI 需要的最小權限,不要用過度寬鬆的全域 token。
0. 安裝 Claude Code
npm install -g @anthropic-ai/claude-code 1. 用 curl 單測 GLM 5.2
先確認 Cloudflare 端可以呼叫模型。把 `你的ACCOUNT_ID` 和 `你的API_TOKEN` 換成自己的值。
curl https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/run/@cf/zai-org/glm-5.2 \
-H "Authorization: Bearer 你的API_TOKEN" \
-d '{"messages":[{"role":"user","content":"用一句話介紹你自己"}]}' 2. 安裝 uv
LiteLLM proxy 用 uvx 跑,可以固定 Python 3.12,避開較新 Python 版本造成的編譯問題。
curl -LsSf https://astral.sh/uv/install.sh | sh 3. 驗證 LiteLLM 能跑
uvx --python 3.12 --from 'litellm[proxy]' litellm --version 4. 建立 cf-config.yaml
建立 `cf-config.yaml`。`你的ACCOUNT_ID` 有兩處要換。`cf-glm-5.2` 給 Claude Code 主要模型用,`cf-small` 給較輕量任務用。
model_list:
- model_name: cf-glm-5.2
litellm_params:
model: openai/@cf/zai-org/glm-5.2
api_base: https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/v1
api_key: os.environ/CLOUDFLARE_API_TOKEN
- model_name: cf-small
litellm_params:
model: openai/@cf/meta/llama-3.1-8b-instruct-fp8
api_base: https://api.cloudflare.com/client/v4/accounts/你的ACCOUNT_ID/ai/v1
api_key: os.environ/CLOUDFLARE_API_TOKEN
litellm_settings:
use_chat_completions_url_for_anthropic_messages: true 5. 啟動 LiteLLM 翻譯橋
這個終端視窗要保持開啟。Claude Code 之後會連到 `localhost:4000`。
export CLOUDFLARE_API_TOKEN=你的token
uvx --python 3.12 --from 'litellm[proxy]' litellm --config cf-config.yaml --port 4000 6. 新開視窗測 proxy
curl http://localhost:4000/v1/models -H 'Authorization: Bearer sk-1234' 7. 把 Claude Code 指到本機 proxy
export ANTHROPIC_BASE_URL=http://localhost:4000
export ANTHROPIC_AUTH_TOKEN=sk-1234
export ANTHROPIC_MODEL=cf-glm-5.2
export ANTHROPIC_DEFAULT_HAIKU_MODEL=cf-small 接著啟動 Claude Code,若跳出自訂 API 設定就選是。進入後用 `/status` 確認 Base URL 指向 `localhost:4000`。
8. 把設定寫進 shell profile
如果你確定要長期使用,可以把上面四行 `ANTHROPIC_` export 加到 `~/.zshrc` 或 `~/.bashrc`。我會建議先手動跑幾次確認沒有問題,再寫進 profile。
Windows PowerShell 寫法
PowerShell 不用 `export`,改用 `$env:`。
$env:ANTHROPIC_BASE_URL="http://localhost:4000"
$env:ANTHROPIC_AUTH_TOKEN="sk-1234"
$env:ANTHROPIC_MODEL="cf-glm-5.2"
$env:ANTHROPIC_DEFAULT_HAIKU_MODEL="cf-small" 若要永久保存,放進 PowerShell 的 `$PROFILE`。Windows 跑 AI Agent 時,環境隔離也很重要,可以延伸看 Windows 跑 AI Agent 為什麼要用 WSL 。
保命提醒:不要把外部模型當免費額度
最容易出事的地方,是把 Cloudflare Workers AI、Cloudflare AI Gateway、OpenAI、Anthropic 混在一起。這篇的低成本前提,是 Cloudflare config 裡的模型走 `@cf/` 開頭,例如 `@cf/zai-org/glm-5.2`。這類模型用的是 Cloudflare Workers AI 額度。
如果你把 Gateway 接到 GPT 或 Claude,那些請求可能會回到 OpenAI 或 Anthropic 的帳單。Cloudflare 只是通道,不代表外部模型突然免費。真正要保命,就是把模型名稱、api_base、API key 來源逐一檢查,並在 Cloudflare 後台看用量。
官方價格頁目前寫得很明確:Free plan 每天 10,000 Neurons,Paid plan 也有每天 10,000 Neurons 免費額度,超出後依 Neurons 計費。免費方案超出額度通常是操作失敗,不是自動無限跑。這點比「無限免費」四個字重要太多。
省額度的三個做法
第一,任務分層。小任務用 `cf-small`,複雜推理再用 `cf-glm-5.2`。第二,讓 Agent 先輸出計畫再執行,避免一次丟太長上下文。第三,把重複流程寫成腳本或 skill,減少模型反覆讀同一批資料。
這也是我一直看好的方向:不要只追求模型本身,而是把模型接到穩定工具鏈。像 Playwright CLI 讓 Codex 操作瀏覽器 ,或 讓 Agent 自己搜尋和使用 skills ,本質上都是把昂貴推理留給真正需要判斷的地方。
我會怎麼用
我不會把這套當成主力模型的完全替代品,而是當成低成本實驗層。適合拿來跑 demo、試 prompt、生成小工具、做簡單 code review、補文件、處理一次性腳本。真正重要的架構決策、複雜除錯、長上下文專案,還是要保留更強模型或本地大模型選項。
如果你已經在用 Codex 和 ChatGPT Work 這類 AI 代理工作流 ,這套 Cloudflare Workers AI + LiteLLM 的做法可以當成另一個模型入口。它的價值不是讓你省到零,而是讓你有更多成本可控的實驗空間。
延伸資源
FAQ
Cloudflare Workers AI 接 Claude Code 真的免費嗎?
不是無限免費。Cloudflare Workers AI 有每日免費 Neurons 額度,超出後會依方案限制或計費。要把它當成低成本額度,不要當成沒有上限的模型。
為什麼需要 LiteLLM?
LiteLLM 在本機當 proxy,把 Claude Code 發出的 Anthropic 入口請求轉成 Cloudflare Workers AI 可接受的 OpenAI 相容請求。
最容易踩到哪個帳單風險?
最容易把 Cloudflare AI Gateway 接到外部 GPT 或 Claude,卻以為仍在用 Cloudflare 免費 @cf 模型。設定時要確認模型名稱是 `@cf/` 開頭,並檢查 API key 來源。
這套適合取代主力 Claude 嗎?
不建議直接取代。它比較適合低成本實驗、簡單任務、小工具和批次工作。複雜架構、長上下文和高風險任務,仍應保留更強模型。



近期留言