###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
"""
In some versions of torchaudio, the first line works but in other versions, so does the second line.
"""
try:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
except:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]), 24000)
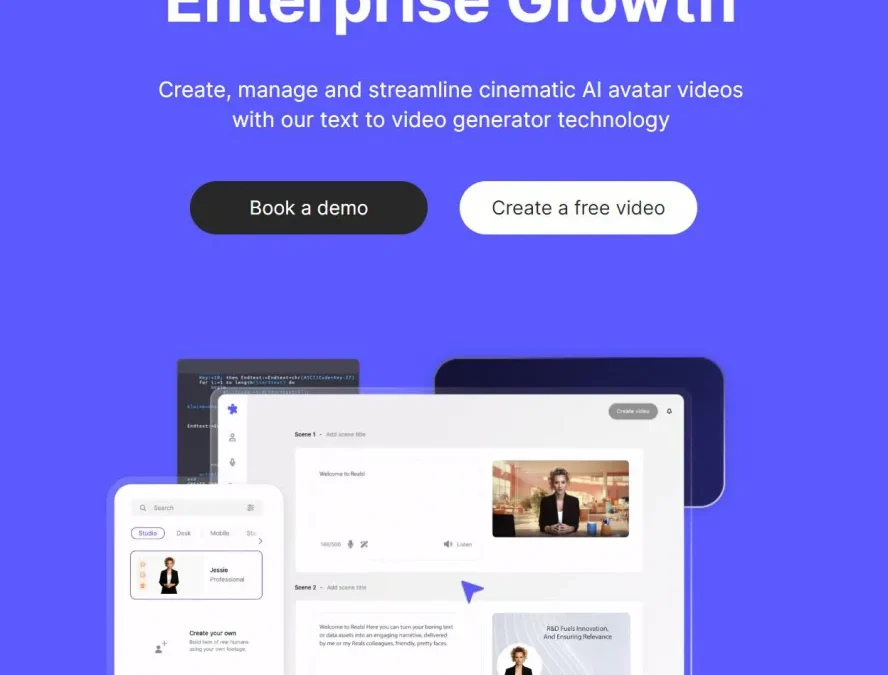
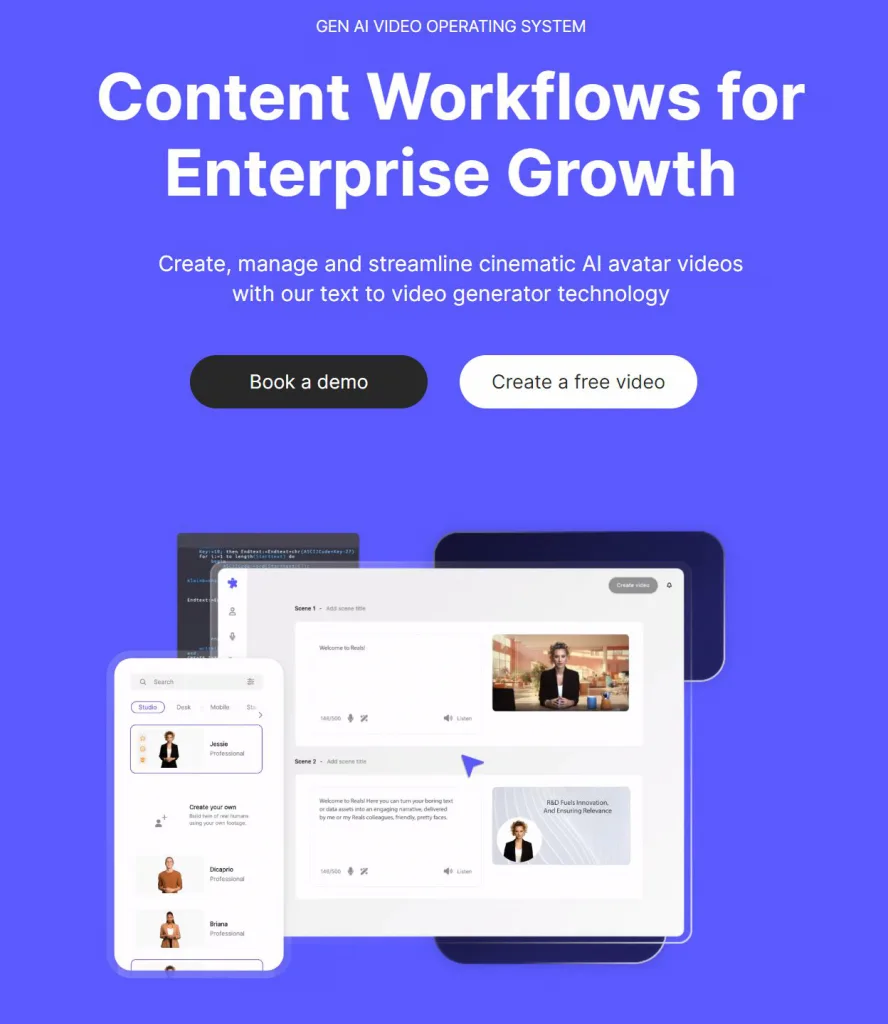
Hour One AI 是一家專注於人工智能技術的創新公司,其技術主要應用於生成逼真的虛擬人物和語音合成領域。這家公司利用最新的AI和機器學習技術,創造出可以在各種數字媒體和虛擬環境中自然互動的虛擬角色。Hour One AI的技術不僅僅是將數字人物作為娛樂或遊戲的一部分,而是旨在於教育、培訓、新聞報導、客戶服務以及其他需要人機互動的領域中發揮作用。
技術創新
Hour One AI 的一大創新是其能夠創建出與真人幾乎無法區分的虛擬角色。這些角色不僅外觀逼真,還能夠模仿人類的語音、語調和面部表情。公司使用先進的深度學習技術,通過分析大量的人類語音和面部表情數據,來訓練其AI模型,從而生成自然流暢且富有表情的虛擬角色。
應用場景
Hour One AI 的技術在多個領域中都有廣泛的應用前景:
教育和培訓:通過創建虛擬教師和培訓師,提供更加個性化和互動的學習體驗。
新聞和報導:使用虛擬新聞主播來報導最新新聞,提供更加多樣化的報導角度和語言選擇。
客戶服務:創建虛擬客服代表,24小時提供服務,改善客戶體驗。
娛樂和社交媒體:為社交媒體和娛樂行業提供虛擬角色,創造新的互動方式。
企業級安全性、信任和服務
在追求技術創新的同時,Hour One AI深知企業級安全性、信任和服務的重要性。公司致力於達到AI安全和倫理的最高標準,確保其技術的應用不僅高效而且安全可靠。
企業級安全:Hour One AI採用最先進的安全技術和協議,保護用戶數據免受未經授權的訪問和濫用。從數據加密到嚴格的訪問控制,Hour One AI確保所有虛擬角色的創建和使用過程都遵循最嚴格的安全標準。
信任和透明度:Hour One AI在其所有操作中強調信任和透明度。公司不僅公開其AI模型的工作原理,還積極參與公開討論,關於AI倫理和負責任地使用AI技術的重要性。這種開放性賦予了用戶對Hour One AI技術的信任,同時鼓勵了對AI應用倫理問題的持續探討。
客戶服務:Hour One AI提供卓越的客戶服務,確保用戶能夠最大限度地利用其技術。從技術支持到定制開發,Hour One AI與客戶緊密合作,以滿足其獨特需求,推動其業務發展。


近期留言