
by Rain Chu | 3 月 24, 2026 | AI, claude
一、什麼是 Claude for Financial Services Plugins?
Claude 是由 Anthropic 推出的 AI 助手,而 Claude for Financial Services Plugins 則是專為金融產業打造的擴充工具組。
該插件系統讓 Claude 不只是聊天工具,而是直接進化為:
👉 投資分析師
👉 財務建模專家
👉 研究助理
👉 Deal sourcing 引擎
透過整合多個金融資料供應商與自動化工作流,Claude 能夠執行完整的金融分析流程。
⚙️ 核心亮點:41 個技能 + 38 個斜線指令
這套系統最強大的地方在於:
🔹 41 個自動觸發技能(Skills)
當你輸入自然語言時,Claude 會自動判斷並執行對應任務,例如:
- 自動建立 DCF 模型
- 解析財報(10-K、10-Q)
- 預測公司未來現金流
- 計算估值(WACC、IRR)
- 分析市場趨勢
👉 幾乎等於「AI 自動跑完整投資分析流程」
🔹 38 個 Slash Commands(斜線指令)
你也可以直接用指令操作,例如:
/dcf
/valuation
/earnings-analysis
/company-profile
/deal-sourcing
👉 類似「金融版 CLI + Copilot」
🧠 Claude 可以做哪些金融工作?
以下是實際應用場景:
📊 1️⃣ DCF 建模(Discounted Cash Flow)
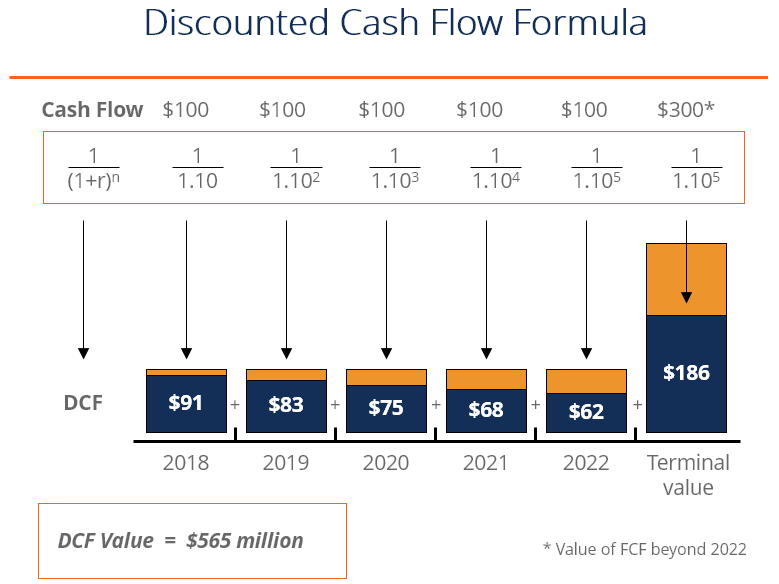
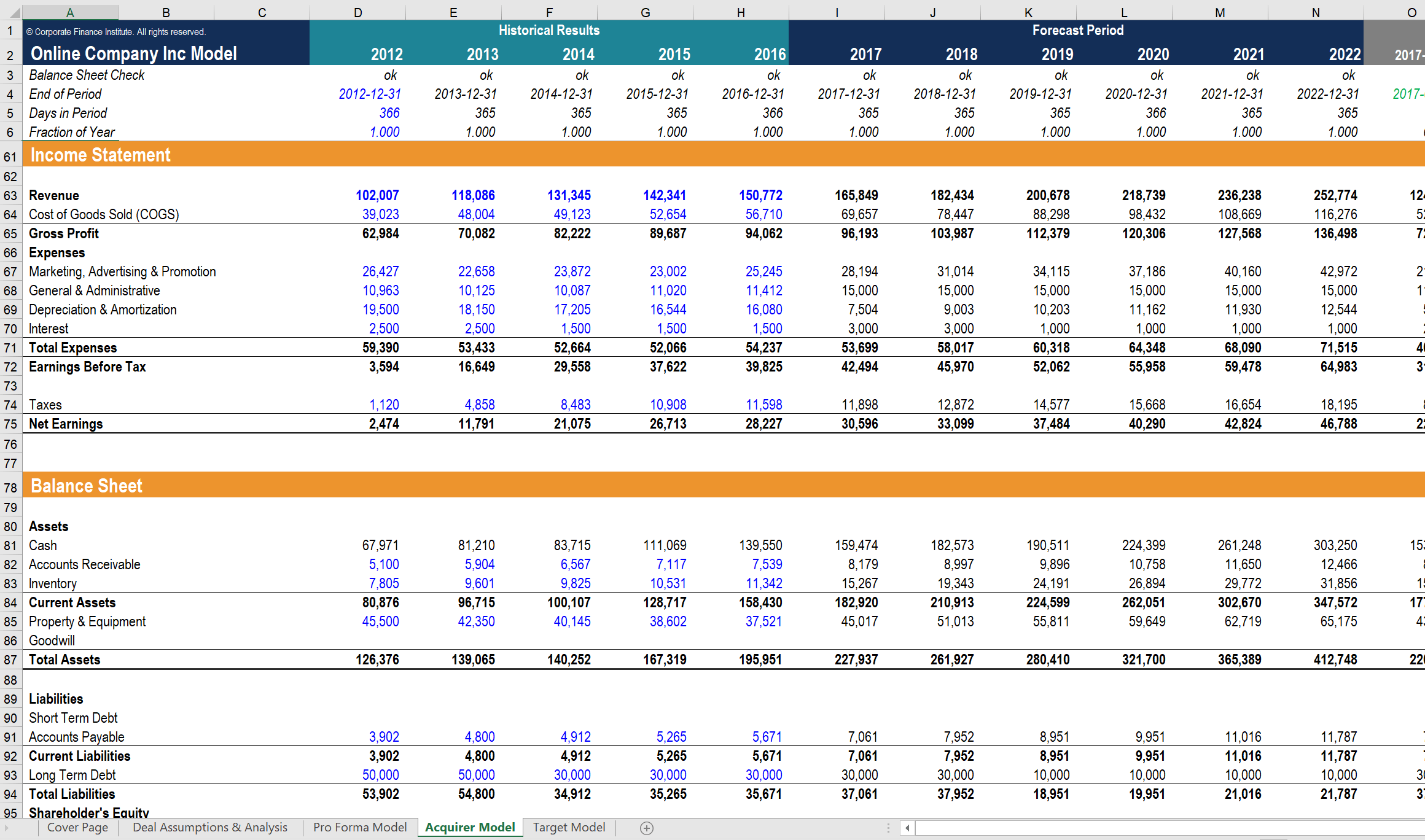
Claude 可自動:
- 抓取公司財務數據
- 預測未來營收與現金流
- 計算折現率(WACC)
- 輸出估值結果
👉 傳統需要 2–3 小時 → 現在幾分鐘完成
📑 2️⃣ 財報分析(Financial Statements Analysis)
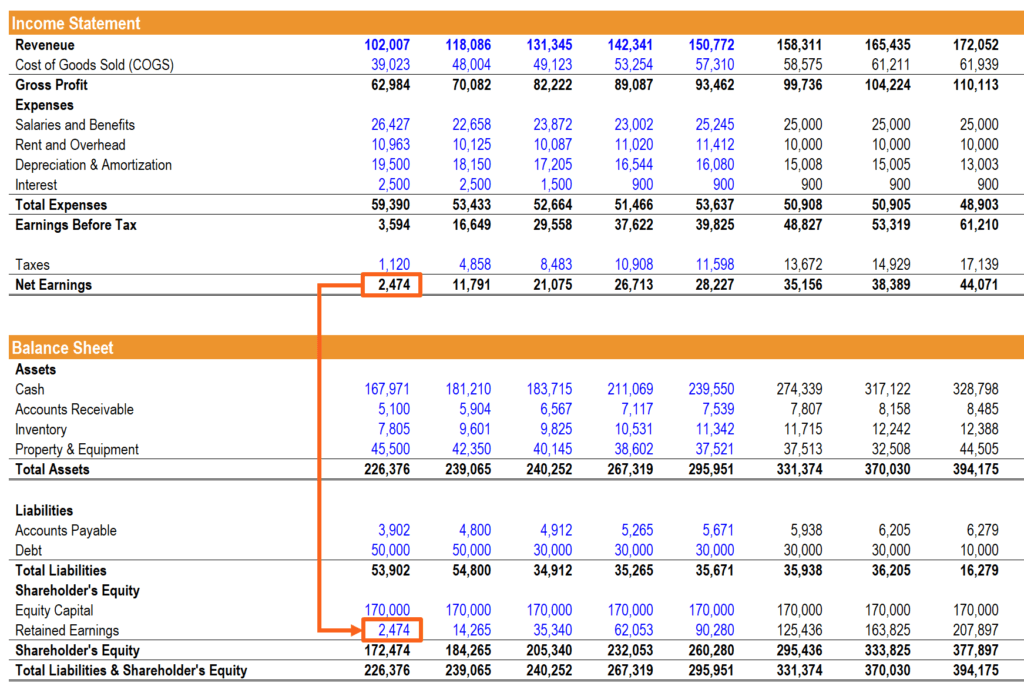
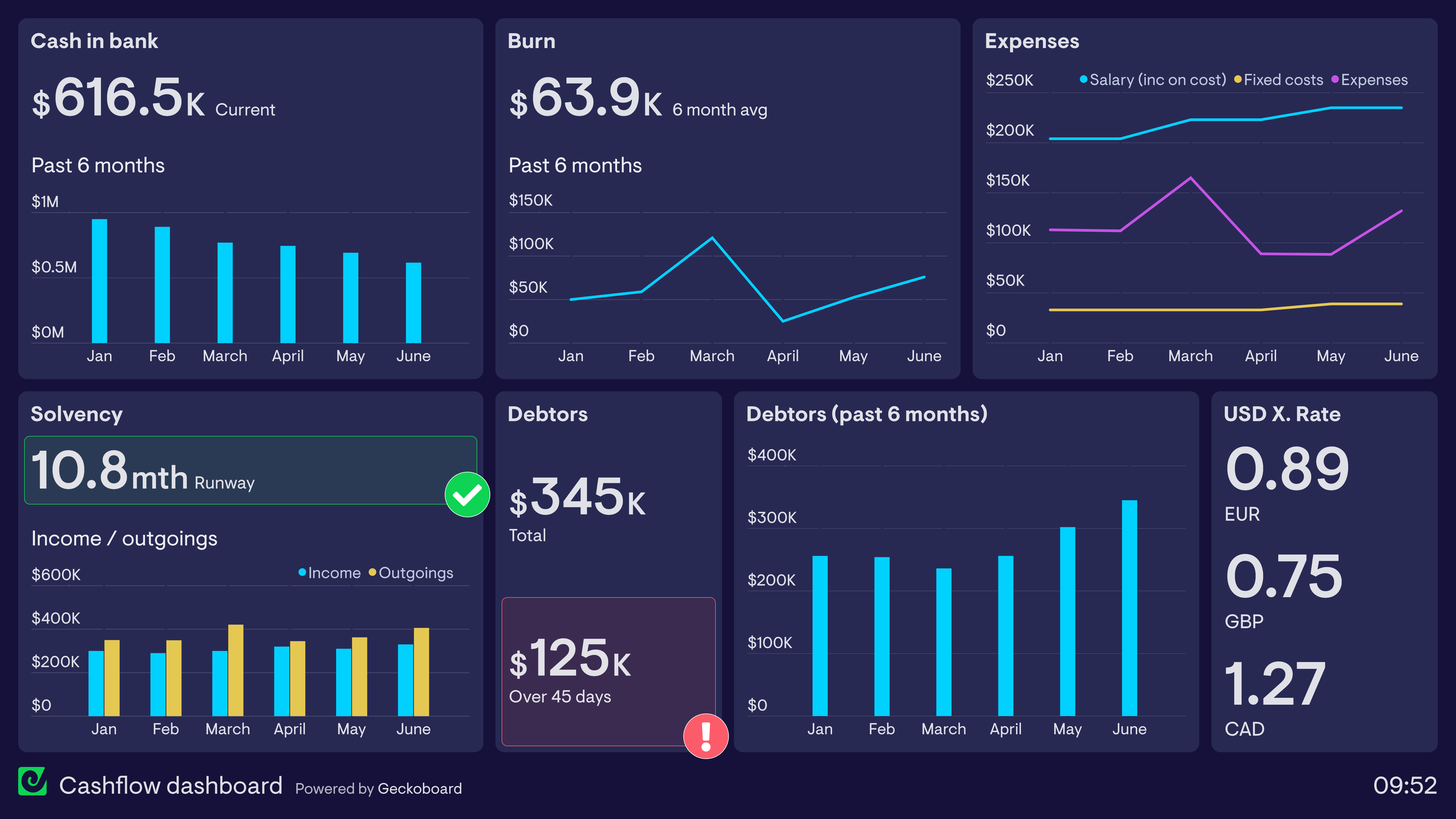

Claude 可自動解析:
- Income Statement
- Balance Sheet
- Cash Flow
並產出:
🏢 3️⃣ 公司研究(Equity Research)
4
輸入公司名稱即可:
- 自動產出公司報告
- 分析競爭對手
- 市場定位與護城河
- 投資建議(Bull / Bear case)
🔍 4️⃣ Deal Sourcing(投資機會發掘)


Claude 能:
- 搜尋潛在投資標的
- 篩選符合條件公司
- 分析市場機會
- 建立 pipeline
👉 對 VC / PE / 投資銀行極具價值
🔗 整合 11 個資料供應商
根據官方設計,Claude plugins 已整合多個金融數據來源,例如:
- 市場數據(股價、交易量)
- 財報資料
- 宏觀經濟指標
- 公司基本面資料
👉 AI 不再「幻想」,而是基於真實數據分析
🧩 技術架構概念(你會有興趣的重點)
從工程角度看,這其實是一個:
Claude (LLM)
↓
Plugin Orchestrator
↓
Skills (41 modules)
↓
Data Providers (11 sources)
↓
Structured Financial Output
👉 本質就是「金融版 AI Agent」
⚡ 為什麼這個東西很關鍵?
這代表一個重大趨勢:
🔥 AI 正在取代「重複性高的金融分析工作」
過去:
現在:
🚀 未來發展
Claude Financial Plugins 只是開始,接下來可能會出現:
- 自動生成投資簡報(Pitch Deck)
- 即時交易策略 AI
- 完整 AI 投資顧問
👉 最終形態:AI 投資銀行
相關文章
by Rain Chu | 12 月 25, 2025 | AI, Chat, 程式開發
以前建立一個網站往往代表著學寫程式、研究版型、反覆修改設計,對許多人來說門檻相當高。但現在,隨著 AI 技術成熟,網站製作正快速走向「對話化」。
Lumi AI 主打一個簡單卻強大的理念:你只需要與 AI 聊天,就能將腦中的想法,變成一個優雅且可行的網站。
什麼是 Lumi AI?
Lumi AI 是一款 AI 驅動的網站建立工具,使用者不需要任何設計或程式背景,只要透過對話方式,描述你的想法,例如:
- 「我想要一個新創公司形象網站」
- 「幫我做一個產品介紹頁,有現代感與科技風」
- 「我需要一個個人作品集網站」
Lumi 會根據你的描述,即時產生網站結構、版型與內容,讓「想法 → 網站」的距離縮短到幾分鐘。
Lumi AI 的核心特色
1️⃣ 與 AI 聊天,就能建立網站
Lumi 最大的特色在於對話式體驗。你不需要面對複雜的後台設定,只要像聊天一樣說出需求,AI 就會一步步幫你完成網站雛形。
2️⃣ 將創意快速轉化為可行網站
從概念、版型到內容呈現,Lumi AI 會自動整合設計與結構,產生一個真正可以使用的網站,而不是只有概念草稿。
3️⃣ 優雅、現代的視覺設計
Lumi 預設產出的網站風格簡潔、現代,特別適合新創團隊、產品頁面、個人品牌與展示型網站。
4️⃣ No-Code,任何人都能上手
不論你是設計師、創業者、行銷人員,甚至是 Data Analyst,只要能清楚描述需求,就能用 Lumi AI 建立網站,完全不需要寫程式。
Lumi AI 與 Data AI、Data Analyst 的關聯
你可能會好奇,Lumi AI 和 Data AI、Data Analyst 有什麼關係?
實際上,Lumi AI 非常適合用來:
- 建立 資料分析成果展示網站
- 製作 Data Analyst 個人作品集(Portfolio)
- 快速生成 數據產品或 AI 專案的介紹頁
對 Data Analyst 而言,Lumi AI 能大幅降低「展示分析成果」的門檻,讓重點回到資料洞察本身,而非網站技術細節。
Lumi AI 適合哪些人使用?
- 🚀 新創團隊:快速驗證想法,建立產品或服務頁
- 🎨 設計與行銷人員:用對話完成網站初稿
- 📊 Data Analyst / Data AI 專案負責人:展示分析成果與案例
- 🧑💻 個人品牌經營者:建立個人網站或作品集
官方網站
👉 https://lumi.new/zh-TW
by Rain Chu | 12 月 25, 2025 | AI, Chat, 數據分析
Data Analyst(資料分析師)與企業決策者每天都要面對大量數據,但不是每個人都具備寫程式、操作複雜分析工具的能力。這正是 Julius AI 誕生的原因——讓你不用寫程式,只要用英文問問題,就能在幾秒鐘內獲得洞察。

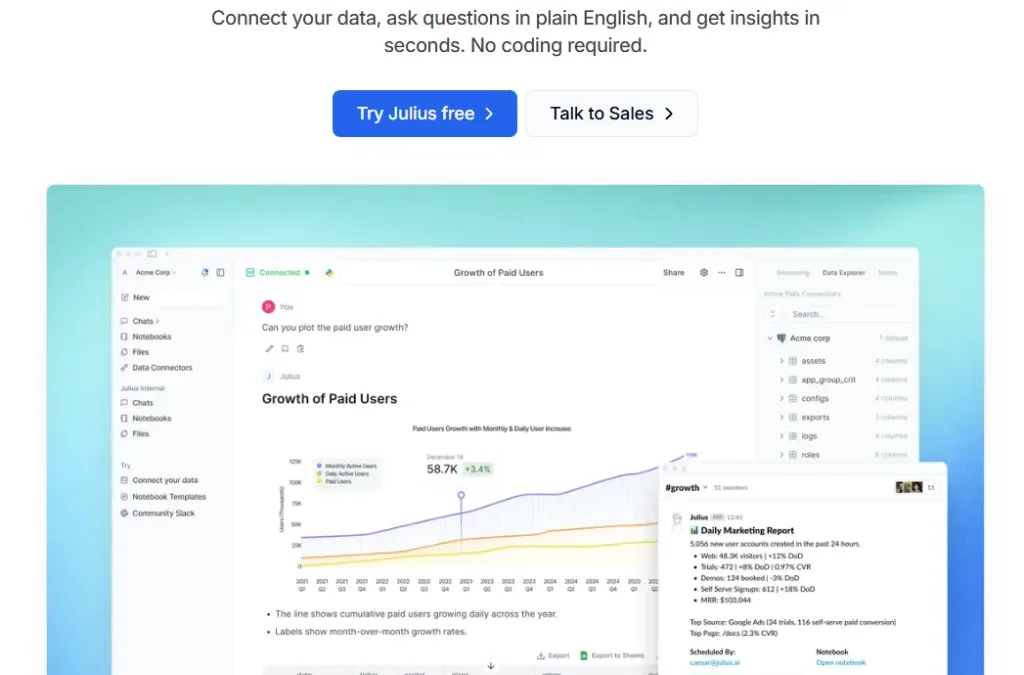
什麼是 Julius AI?
Julius AI 是一款以 Data AI 為核心的智慧資料分析平台。使用者只需上傳資料(例如 CSV、Excel、Google Sheets),就可以像聊天一樣,用自然語言詢問問題:
- 「哪一個產品的成長率最高?」
- 「請幫我畫出近三年的營收趨勢圖」
- 「這份資料中有沒有異常值?」
Julius AI 會即時理解你的問題,並自動完成分析、計算與視覺化,讓資料真正「開口說話」。
Julius AI 的核心特色
1️⃣ 連接你的資料,立刻開始分析
Julius AI 支援多種常見資料格式,無論是試算表還是資料表,都能快速上傳並使用,完全不需要事前建模或設定複雜流程。
2️⃣ 用白話英文提問,不需要寫程式
最大的亮點在於 No Coding Required。你不必懂 Python、SQL 或 R,只要用英文描述你的需求,Julius AI 就能自動完成背後的資料分析邏輯。
3️⃣ 幾秒鐘內產生洞察與圖表
從資料清理、分析到圖表生成,Julius AI 幾乎都是即時完成,非常適合需要快速決策的商業場景。
4️⃣ 為 Data Analyst 與非技術人員量身打造
不論你是專業的 Data Analyst,還是行銷、產品、營運人員,Julius AI 都能降低資料分析門檻,讓更多人能參與數據決策。
Julius AI 可以用在哪些情境?
- 📊 商業決策分析:快速找出銷售趨勢與關鍵指標
- 📈 行銷成效評估:分析活動轉換率與使用者行為
- 🧠 教育與研究:協助學生與研究人員理解資料結構
- 🏢 新創與中小企業:沒有專屬 Data Team 也能做專業分析
為什麼 Julius AI 值得關注?
在過去,資料分析往往意味著「高技術門檻」與「長時間準備」。Julius AI 將 Data AI 與自然語言處理結合,讓資料分析變得更直覺、更民主化。
對 Data Analyst 來說,它能加快工作流程;對非技術背景的使用者來說,則是一條直接進入數據世界的捷徑。
官方網站
👉 https://julius.ai/
by Rain Chu | 12 月 21, 2025 | AI, 模型
CherryNio AI(CherryChat.org) 是一個提供 一站式整合 AI 服務平台,聚合了多個頂級大語言模型,如 Sora2、GPT-5、Claude 4.5、Gemini 2.5 Pro 等,讓使用者在同一個介面內即可呼叫不同模型進行聊天、翻譯、分析與客製化應用。
CherryNio 不僅是一個 AI 聊天介面,還能透過 API 金鑰中轉與整合服務,讓開發者在自己的應用中也能使用這些模型。
📌 為什麼 CherryNio AI 可以替代所有 AI 訂閱?
你可能會為 ChatGPT、Gemini、Claude、甚至 Perplexity 分別付費訂閱。但 CherryNio AI 將這些 AI 能力整合在同一個平台,用更彈性的付費方式替代多個訂閱,大幅降低成本並提升效率。
🧪 案例一:沉浸式翻譯
透過 CherryNio 的 沉浸式翻譯功能(類似瀏覽器翻譯插件),你可以把外語內容即時翻譯並呈現在同一個視窗中,不需跳來跳去切換工具。這對長篇網頁閱讀與即時對話翻譯超級實用。
🛒 案例二:Nano Banana
Nano Banana 是影片中提到的一個實際使用案例,可理解為結合 CherryNio 的 AI 能力,用以 生成或優化產品描述/創意寫作等工作流程,展現平台在不同任務上的彈性應用。
🖱 案例三:Cursor 替代品
許多使用者會用 Cursor 來進行程式碼輔助、資料分析等 AI 工作。CherryNio 提供整合式接口與多模型支援,讓你可以在單一平台內呼叫不同模型執行類似 Cursor 的任務,不再需要額外訂閱 Cursor。
🔍 案例四:Perplexity 替代品
Perplexity 是一個主打資料檢索與摘要的 AI 工具。在 CherryNio 中,只要選擇合適的模型和 prompt,就可以達到類似的效果:從大量資料中萃取資訊與整理答案,甚至結合多個模型輸出更豐富的答案。
📚 案例五:本地知識庫
CherryNio 支援建立 本地知識庫或整合 API 查詢功能,讓使用者能夠基於自有資料來源進行檢索與對話。這對於企業內部知識管理、客服智能回覆甚至技術文檔搜索都非常有幫助,更是一種 替代雲端知識庫訂閱的方式。
💡 使用模式與付費方式
CherryNio AI 的付費方式通常不是傳統的年費訂閱,而是 透過 Token 或套餐方式彈性付費,讓使用者按需支付,減少不必要的訂閱浪費。
參考資料
https://chat.cherrychat.org
by rainchu | 12 月 18, 2025 | AI, 影片製作
HailuoAI 海螺 AI 成為影片製作領域的一匹黑馬。它是一款由中國團隊開發的先進 AI 影片生成工具,擁有強大的「文字轉影片」與「圖像轉影片」能力,讓使用者無需任何剪輯技巧,就能快速生成令人驚豔的影片作品。
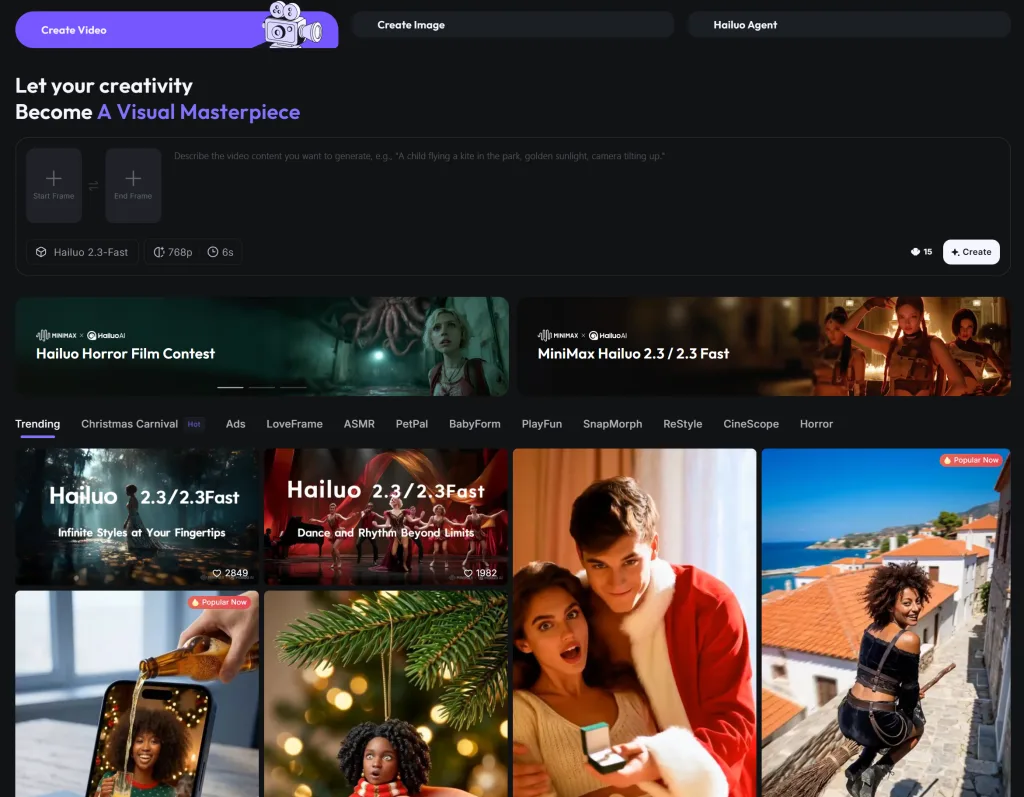
🎬 一句話:每個想法都是一部大片
海螺 AI 的核心宗旨就是——「每個想法都是一部大片」。無論你是內容創作者、社群經營者還是行銷人員,只要透過簡單的文字敘述或靜態圖片,就能讓 AI 將你的想像變為動態影片。其操作流程極為簡單直覺,支援中文提示詞,因此特別適合華語內容創作者使用。
✨ 核心特色與功能
🧠 1. 文字轉影片(Text-to-Video)
使用者只需輸入一段文字描述,海螺 AI 就能根據提示詞生成一段影片。這個過程中,AI 會自動理解場景、動作與情緒,快速渲染出高品質短片,無需剪輯工具或專業技巧。
🖼️ 2. 圖像轉影片(Image-to-Video)
不只文字,海螺 AI 也能將靜態圖像「活化」。只要上傳一張照片,它就能為圖片添加動態效果、鏡頭運動與動畫動作,使靜態內容變成引人注目的影片。
🌍 3. 多語言與中文支援
相較於某些只支援英語操作的工具,海螺 AI 不僅支援多語言輸入,更對中文提示詞有良好理解能力,讓華語使用者能直接用母語敘述想法,就能有效生成影片內容。
🚀 為什麼它值得關注?
HailuoAI 海螺 AI 的優勢在於其“先進 AI 影片製作”的地位:它不只是一個簡單的素材素材生成器,而是具備 電影級視覺效果生成能力 的 AI 平台。使用者可以在短時間內快速從文字或圖像生成高品質影片,節省大量剪輯時間,並擴大創作可能性。
此外,它也提供免費體驗方案,讓新手能零成本嘗試創作。雖然生成影片的長度目前傾向於短片(如約 5~6 秒影片為主),但對於社群貼文、短影音內容來說,已相當實用。
🛠️ 使用小技巧
- 提示詞描述越詳盡 → 輸出影片越精準
- 結合圖像與文字 → 可創造更具故事感的影片
- 善用主體參考功能 → 讓同一角色在不同場景中保持一致性
官方網站
https://hailuoai.video
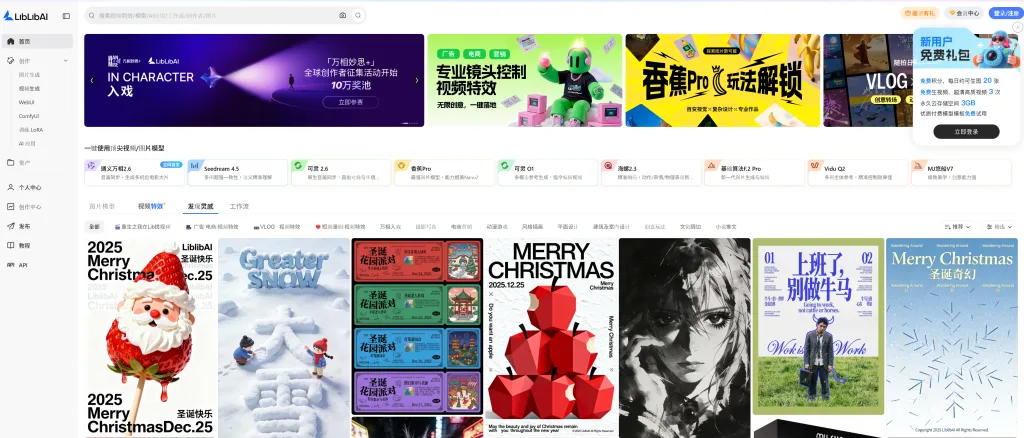
by rainchu | 12 月 18, 2025 | AI, 圖型處理, 影片製作
眾多 AI 創作平台之中,Liblib 憑藉其高度整合的功能、生態完整度以及對中文使用者的極致友善設計,迅速成為中國最領先的 AI 創作平台之一。
一站式 AI 影像與視頻創作平台
Liblib 不僅僅是一個圖片生成網站,而是一個超級齊全的 AI 創作平台,涵蓋:
- AI 圖片生成
- AI 視頻特效與動畫
- 模型管理與分享
- 視覺化工作流(Workflow)
- LoRA 訓練與應用
透過雲端化的設計,使用者無需自行架設環境,即可直接在瀏覽器中使用高階 AI 生成能力。
深度整合 WebUI 與 ComfyUI
對於熟悉 Stable Diffusion 生態的使用者而言,Liblib 最大的優勢之一,在於它同時支援:
- WebUI:操作直覺、上手快速,適合大多數創作者
- ComfyUI:節點式工作流,適合進階用戶進行複雜控制與自動化生成
這種雙軌並行的設計,讓初學者與專業用戶都能在同一平台中找到最適合自己的創作方式。
強大的 LoRA 訓練能力
Liblib 在 LoRA 訓練方面表現尤為突出,提供完整且視覺化的訓練流程:
- 上傳資料集即可開始訓練
- 支援多種風格與角色 LoRA
- 訓練完成後可直接套用於生成
- 社群分享與模型市集機制
這讓創作者能快速打造專屬風格模型,大幅降低 AI 模型訓練的門檻。
中文使用者極度友善
相較於許多國外 AI 平台對中文支援不足,Liblib 在以下方面明顯優於同類產品:
- 完整繁體與簡體中文介面
- 中文 Prompt 理解度高
- 中文模型與 LoRA 資源豐富
- 適合華語創作者的社群內容
對中文內容創作者來說,這是一個真正「為中文而生」的 AI 創作平台。
工作流與創作效率全面升級
Liblib 內建的 工作流系統(Workflow),讓使用者可以:
- 將複雜生成流程模組化
- 重複使用高品質生成邏輯
- 快速套用他人分享的創作流程
- 大幅提升商業與批量創作效率
這對於需要大量產出視覺內容的團隊與個人創作者而言,是極具價值的功能。
為什麼 Liblib 是中國最領先的 AI 創作平台?
綜合來看,Liblib 的核心優勢包括:
- ✅ 視頻特效 + 圖片模型完整整合
- ✅ WebUI 與 ComfyUI 同時支援
- ✅ 強大且易用的 LoRA 訓練
- ✅ 中文高度友善,資源豐富
- ✅ 從新手到專業用戶皆適用
這不僅是一個工具,更是一個完整的 AI 創作生態系。
官方網站
👉 Liblib 官方平台
https://www.liblib.art/
近期留言