by Rain Chu | 4 月 24, 2026 | Agent, AI, Microsoft, Tool
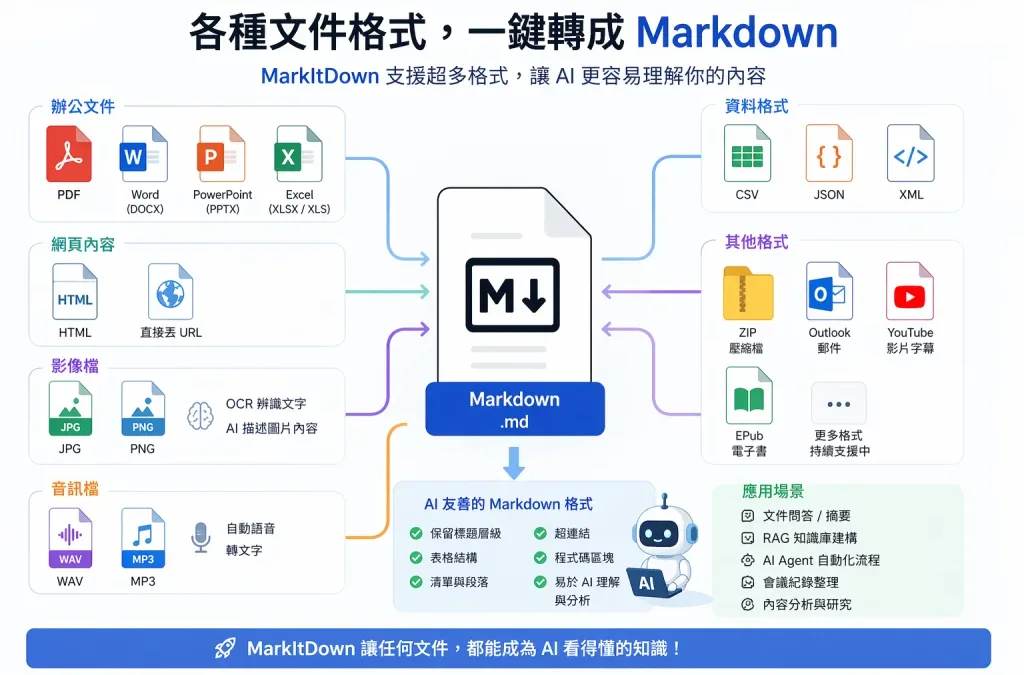
在 AI 時代,「讓 AI 看懂文件」變成一個非常關鍵的能力,但現實世界的資料格式五花八門,從 PDF、Word 到 PPT、甚至影片與音訊,這些內容對 AI 來說其實並不好直接處理。
這時候,MarkItDown 就成為一把真正的「文件瑞士刀」。
由 Microsoft 開源推出,MarkItDown 能將各種格式的檔案,一鍵轉換成乾淨、結構化、AI 友善的 Markdown,讓 ChatGPT、Claude 或各種 AI Agent 能輕鬆理解與分析。
你只要把 https://github.com/microsoft/markitdown 網址貼給 agent ,請他安裝就可以了
🚀 為什麼 MarkItDown 這麼強?
MarkItDown 最大的優勢只有一句話:
👉 幾乎什麼格式都能轉,而且還轉得漂亮
📂 支援格式(強到誇張)
🧾 辦公文件
- PDF
- Word(DOCX)
- PowerPoint(PPTX)
- Excel(XLSX / XLS)
🌐 網頁內容
🖼️ 影像檔
- JPG / PNG
- 支援 OCR 文字辨識
- 可搭配 AI 產生圖片描述
🎧 音訊檔
- WAV / MP3
- 自動語音轉文字(Speech-to-Text)
📊 資料格式
📦 其他進階格式
- ZIP(自動解壓並轉換)
- Outlook 郵件
- YouTube(自動擷取字幕)
- EPub 電子書
✨ 不只是轉檔,而是「結構理解」
很多轉檔工具的問題是:
👉 轉出來變成一坨純文字(完全不能用)
但 MarkItDown 不一樣,它會:
- 保留標題層級(# ## ###)
- 還原表格結構
- 保留清單與段落
- 維持超連結
👉 轉出來就是 AI 可以直接理解的 Markdown 結構
這對以下應用非常關鍵:
- RAG(檢索增強生成)
- AI 文件摘要
- Agent 自動閱讀文件
⚡ 安裝與使用(超簡單)
安裝
pip install "markitdown[all]"
👉 如果只需要特定格式:
pip install "markitdown[pdf,docx,pptx]"
CLI 使用
markitdown 報告.pdf -o 報告.md
Python 使用
from markitdown import MarkItDownmd = MarkItDown()
result = md.convert("文件.docx")print(result.markdown)
👉 幾行程式碼就搞定
🤖 搭配 AI:威力直接翻倍
MarkItDown 真正強的地方,是它「原生為 AI 設計」。
🧠 AI 圖片理解
- 可串接 OpenAI 視覺模型
- 自動產生圖片描述
- 讓 AI 看懂圖片內容
🔍 OCR 文字辨識
- 整合 Azure Document Intelligence
- 可讀取掃描 PDF / 圖片文字
🔌 MCP(Model Context Protocol)整合
- 可直接接入 Claude Desktop
- 或各種 AI Agent 系統
👉 這點對在做 AI Agent / LangChain / 自動化流程 特別重要
🧩 外掛系統
📌 實際應用場景
1️⃣ 餵 AI 吃文件(超省 Token)
👉 先轉 Markdown,再丟 AI
效果:
- Token 減少最多可達 80%
- AI 理解更準確
2️⃣ 建構企業知識庫(RAG)
流程:
文件 → MarkItDown → Markdown → Embedding → Vector DB
👉 完整 AI 知識庫 pipeline
3️⃣ AI Agent 文件閱讀能力
在你的 Agent 流程中加入:
文件 → MarkItDown → LLM 分析
👉 Agent 直接具備「讀文件能力」
4️⃣ 會議紀錄自動化
錄音 → 轉文字 → Markdown → AI整理
👉 自動產出結構化會議紀錄
⚠️ 不是萬能
MarkItDown 雖然強,但有幾個限制:
- 複雜圖表(Chart / Graph)解析較弱
- 高度排版文件可能失真
- 不適合做「高保真排版還原」
👉 如果你要的是「完美排版還原」
建議用:
👉 Pandoc
👉 如果你要的是「讓 AI 看懂」
👉 MarkItDown 完勝
🧠 結論:AI 時代的文件標準工具
MarkItDown 解決了一個非常關鍵但常被忽略的問題:
👉 AI 看不懂文件格式
它的價值在於:
- ✅ 超廣格式支援
- ✅ 保留結構(不是純文字)
- ✅ 原生為 AI 設計
- ✅ 可整合 Agent / RAG / 自動化流程
- ✅ 免費開源
👉 如果你正在做:
- AI Agent
- 文件分析
- 自動化流程
- 知識庫建構
MarkItDown 是 AI Agent 必裝工具。

by Rain Chu | 4 月 24, 2026 | Agent, AI
在過去,AI 只是工具
現在,AI 正在變成你的「員工」
而未來,你的團隊中——
真正工作的,可能不再是人類
🧠 什麼是 Multica?

Multica 是一個開源的 Managed Agents(智能體管理)平台,核心概念非常直接:
把 AI 編碼 Agent,變成真正的「隊友」
不像傳統 AI 工具需要你手動下 prompt、盯著結果,
Multica 讓 AI:
- 自己接任務
- 自己執行工作
- 自己回報進度
- 自己累積能力
👉 就像你真的聘請了一個工程師。
根據官方說明,它的目標是打造「人類 + AI 的混合團隊」基礎設施。
💥 核心理念:AI 不再是工具,而是「員工」
傳統 AI:
Multica 的 AI:
👉 這是從「工具」到「組織角色」的巨大轉變。
⚙️ Multica 的核心功能
1️⃣ Agent 即隊友
你可以像在 Jira 或 Linear 一樣:
- 指派任務給 AI
- AI 會自動認領
- 在看板上更新進度
- 主動回報問題
👉 AI 成為專案管理的一等公民
2️⃣ 全自動任務執行
AI 會:
- 排隊 → 接任務 → 執行 → 完成 / 失敗
- 全程自動運作
- 即時回報進度(WebSocket)
👉 不需要再「盯著 AI 跑」
3️⃣ 技能累積(最關鍵)
每一次任務:
➡️ 都會變成「可重用技能」
例如:
- 部署流程
- DB migration
- Code review
👉 團隊能力會「越用越強」
4️⃣ 多 Agent 協作
你可以同時:
- 跑 10 個 AI 任務
- 多個 Agent 協同工作
- 平行處理專案
👉 等於一個 AI 工程團隊
5️⃣ 統一運行與算力管理
- 本地 + 雲端 runtime
- 自動偵測 CLI 工具
- 統一控制台管理
👉 不用自己拼基礎設施
🧩 為什麼這件事重要?
現在 AI 最大的問題是:
- 每個人用自己的 Agent
- 知識無法共享
- 工作流程碎片化
Multica 解決的是:
👉 AI 協作的「組織問題」
它讓:
👉 這就是「AI 組織化」的開始
🏢 這其實是「AI HR 系統」
如果用一句話形容:
Multica = AI 員工管理系統
它提供:
- 任務分配(像 HR)
- 進度追蹤(像 PM)
- 能力累積(像培訓系統)
👉 AI 不只是會做事,還會「成長」
🔮 未來趨勢:公司將變成「人類 + AI 混合組織」
你可以想像未來公司長這樣:
| 類型 | 角色 |
|---|
| 人類 | 決策 / 創意 / 策略 |
| AI Agent | 開發 / 測試 / 自動化 / 文書 |
甚至:
- 一個人帶 10 個 AI 工程師
- 一個團隊管理 100 個 Agent
👉 生產力直接提升 10 倍(甚至更多)
⚔️ Multica vs 傳統 AI 工具
| 比較 | 傳統 AI | Multica |
|---|
| 使用方式 | Prompt | 任務分配 |
| 工作模式 | 單次互動 | 長時間運行 |
| 協作 | 無 | 多 Agent |
| 記憶 | 無 | 技能累積 |
| 管理 | 人盯 | 自動化 |
👉 本質差異:
工具 → 組織系統
🧠 結論:你該開始思考的事
這不是未來,而是現在正在發生的事。
by Rain Chu | 4 月 18, 2026 | AI, Hermes
🧠 Hermes Agent 是什麼?
Hermes Agent 是由 Nous Research 推出的開源 AI Agent 框架,具備:
- 🔁 跨對話記憶(Memory)
- 🧠 技能(Skill)可持續累積
- 🌐 內建網頁瀏覽與工具調用
- ⏱️ 任務排程(Cron-like)
- 🔌 OpenAI 相容 API(可接各種 LLM)
👉 本質上,它不是單純聊天機器人,而是「可執行任務的 AI 系統」
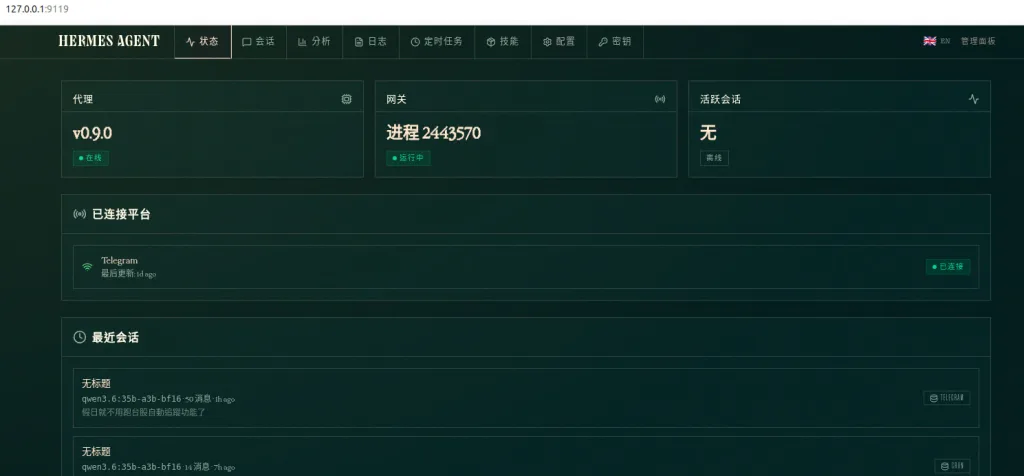
🖥️ Hermes WebUI(Dashboard)帶來什麼改變?
1️⃣ 從 CLI → GUI 的巨大轉變
過去:
- OpenClaw / Agent 系統 → CLI + config + prompt
現在:
- Hermes WebUI → 點擊操作 + 視覺化管理
👉 這是 AI Agent 商業化的關鍵一步
2️⃣ 多 Agent 管理(未來 SaaS 核心)
透過 WebUI,可以:
- 管理多個 Agent
- 設定不同任務流程
- 控制記憶與技能
👉 這意味著:
👉 你可以做「多人 AI 平台」
3️⃣ 技能(Skill)可視化
Hermes 最大亮點:
任務會被記錄成「技能」,並可重複使用
例如:
👉 這其實就是:
👉 AI workflow engine(未來企業標準)
Hermes 實作
先更新到最新版本
然後就可以直接啟用 hermes webui
之後就可以用瀏覽器使用,預設是 http://localhost:9119/
🔍 Hermes WebUI 深度觀察(關鍵洞察)
💡 與 Open WebUI 深度整合
在社群中有人指出:
Hermes 可以當成「有狀態的 LLM endpoint」
意思是:
- WebUI(前端)
- Hermes(Agent)
- LLM(模型)
👉 三層架構:
User → WebUI → Hermes Agent → LL
「Hermes 開箱就像調教一週的 OpenClaw」
官方資訊
https://docs.openwebui.com/getting-started/quick-start/connect-an-agent/hermes-agent
第三方套件
https://github.com/nesquena/hermes-webui
by Rain Chu | 4 月 14, 2026 | AI, Hermes
🧠 什麼是 Hermes Agent?
近期在 GitHub 爆紅、甚至登頂排行榜的 AI Agent —— Hermes Agent,被視為可能「完全取代」OpenClaw 的下一代架構。
它不只是 AI 工具,而是一個會學習、會記憶、會進化的 Agent 系統。
👉 核心概念只有一句話:
「AI 不只是回答問題,而是累積經驗、變強」
🧬 為什麼 Hermes Agent 是結構性突破?
傳統 AI Agent(包含 OpenClaw):
- 每次任務 = 重新開始
- 沒有真正「記憶」
- 沒有「經驗累積」
而 Hermes Agent:
👉 導入「LLM Wiki + 學習迴圈」
🔁 Hermes Agent 的 4 大進化核心機制
1️⃣ Episodic Memory(任務記憶寫入)
每次任務結束,Agent 會寫入完整紀錄:
{
"task": "部署 API",
"steps": [
{"tool": "docker", "result": "success"},
{"tool": "gcloud", "result": "fail"}
],
"errors": ["permission denied"],
"duration": "32s"
}👉 這不是 log,是「可學習資料」
2️⃣ Retrieval(經驗檢索)
下一次遇到類似任務:
👉 不是重來
👉 而是「先查歷史」
例如:
「上次部署失敗是因為 IAM 權限問題」
👉 直接避開錯誤
3️⃣ Skill 抽象(自動技能生成)
當某個流程成功 ≥ 3 次:
👉 自動轉成 skill(Markdown)
# deploy-cloud-run
steps:
- build image
- push to artifact registry
- deploy cloud run
📌 特點:
- 遵循 agentskills.io 標準
- 可共享 / 可版本化
- 真正「技能庫」
👉 這就是 AI 會「學會做事」的關鍵
4️⃣ Honcho 使用者建模(人格記憶)
跨 session 記住你:
- 偏好用 CLI 還是 GUI
- 是否喜歡 Terraform
- 過去拒絕的方案
因為它會變成:
「懂你 workflow 的 AI」
🔍 FTS5 + LLM 搜尋能力(超關鍵)
Hermes Agent 使用:
你可以直接問:
「上週我們討論過哪個 API 設計?」
👉 它真的找得到,而且會整理給你
這點遠超過一般 AI memory
⚙️ Provider 無痛切換(超實用)
不用改 code:
hermes model
直接切換:
- OpenAI
- Claude
- Ollama
- 本地模型
👉 完全符合你多模型架構需求
🛡️ 安全性測試(B+ 評級)
Hermes Agent 在安全測試中達到:
👉 B+ 等級
代表:
- 基本 prompt injection 防禦
- 任務隔離能力
- Tool 使用風險控制
📌 對企業環境安全很重要
⚡ 安裝方式(超快)
Mac / Linux / WSL2
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash
⚔️ Hermes Agent vs OpenClaw
| 項目 | Hermes Agent | OpenClaw |
|---|
| 記憶 | ✅ 長期記憶 | ✅ 依靠 md 文件 |
| 學習能力 | ✅ 自動進化 | ❌ 弱 |
| Skill 系統 | ✅ 自動生成 | ✅ 手動安裝 |
| 使用者建模 | ✅ Honcho | ❌ 無 |
| 搜尋能力 | ✅ FTS5 + LLM | ❌ 弱 |
| 模型切換 | ✅ 一行指令 | ⚠️ 需設定 |
| 圖形介面 | ❌ 無 | ✅ WEB |
| 外部資源 | ❌ 剛開始 | ✅ 支援豐富,skill超多 |
👉 結論:
Hermes 是「會成長的 Agent」,OpenClaw 是「會執行的 Agent」,我兩個都要
🧠 為什麼它會「越用越強」?
因為它形成一個閉環:
任務 → 記錄 → 檢索 → 優化 → 抽象 skill → 再使用
👉 這就是真正的:
🔥 自我進化 AI
🧩 實際應用(你可以做什麼)
以你現在的技術背景,可以直接做:
1️⃣ DevOps AI Agent
- 自動部署 Cloud Run
- 自動修復錯誤
- 記住你的 GCP 架構
2️⃣ WordPress 維運 Agent
- 自動修 DB 問題
- 自動處理圖片路徑
- 學習你的 wp-cli 操作
3️⃣ AI 自動化工程師
- 幫你寫 Terraform
- 幫你 debug CI/CD
- 幫你優化效能
🧨 關鍵結論
👉 Hermes Agent 不是工具升級
👉 是 AI 架構世代升級
開始使用
多人使用
可以使用 hermes profile create + 使用者名稱,詳細指令
hermes profile create agent-name
關鍵資源
Agent Skills
HermesAgent One Wechat bot, two AI brains
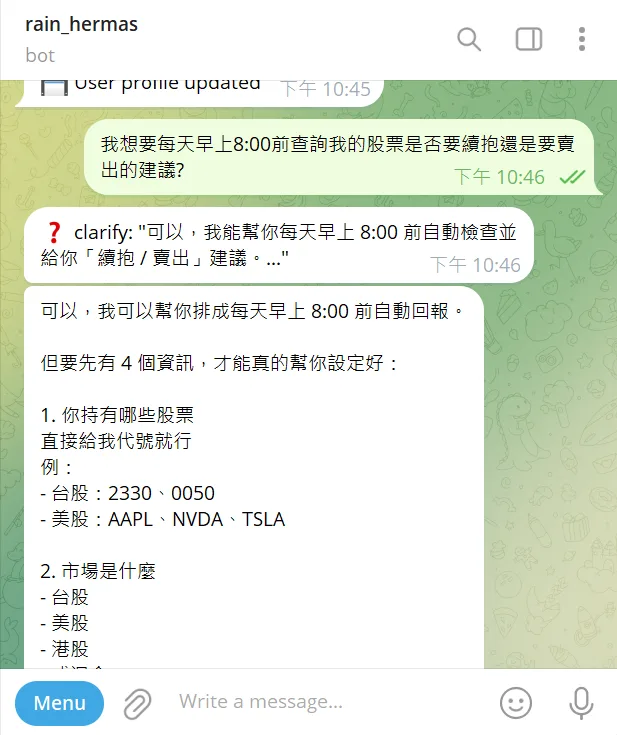
by Rain Chu | 4 月 7, 2026 | Agent, AI, OpenClaw
在 2026 年,AI 不再只是聊天工具,而是「會幫你做事的代理人(AI Agent)」。
而現在,你可以擁有一個——
👉 完全屬於你自己的 AI 智能體(OpenClaw)
不再依賴 SaaS、不再擔心資料外流
👉 私有化 + 24 小時在線 + 可自動執行任務
更關鍵的是:
👉 用 Hostinger,一鍵部署只要約 $7/月
🤖 什麼是 OpenClaw?
OpenClaw 是一款開源 AI Agent(AI 智能代理)平台,可以讓 AI 不只是聊天,而是「幫你做事情」。
它可以:
- 自動回覆訊息(Telegram / WhatsApp / Slack)
- 幫你整理資料、寫報告
- 控制瀏覽器執行任務
- 呼叫 API、自動化流程
- 長期記憶與上下文管理
👉 本質上,它是:
「你的私人 AI 員工」
而且是——
🟢 24 小時不休息
🟢 永遠在線
🟢 完全由你掌控
⚡ 為什麼 OpenClaw 爆紅?
OpenClaw 在 2026 年爆紅的原因只有一個:
👉 它讓 AI 從「聊天」進化成「做事」
傳統 AI(ChatGPT):
OpenClaw:
例如:
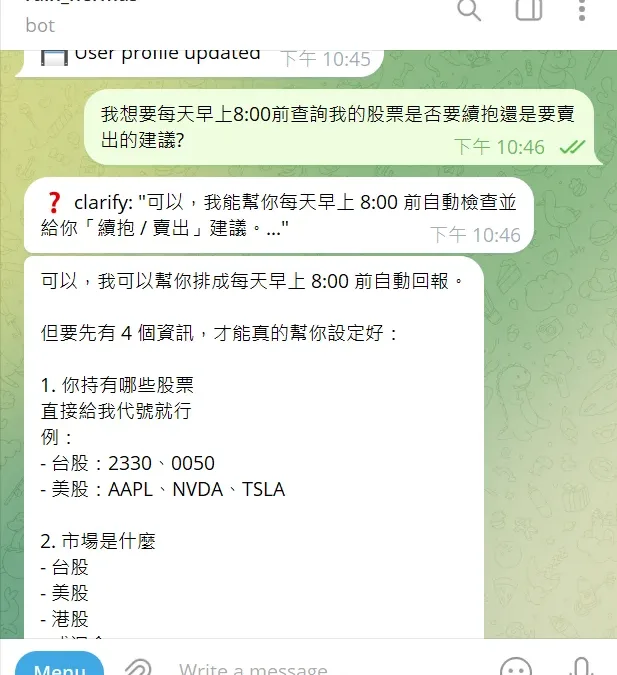
- 幫你每天抓股價 → 傳 Telegram
- 自動回覆客戶訊息
- 幫你爬資料 → 整理成報告
- 自動操作網站(RPA + AI)
👉 這就是「AI Agent 時代」
☁️ 為什麼用 Hostinger 部署 OpenClaw?
如果你自己部署 OpenClaw:
❌ 要裝 Docker
❌ 要設定環境
❌ 要處理網路與安全
但用 Hostinger:
👉 全部幫你做好了
✅ Hostinger + OpenClaw 優勢
- 一鍵部署(不用 CLI)
- 預先配置 AI 環境
- 全球 VPS(穩定 24/7)
- 免費網域 + SSL
- 防火牆 + 備份
👉 官方直接提供 OpenClaw 模板
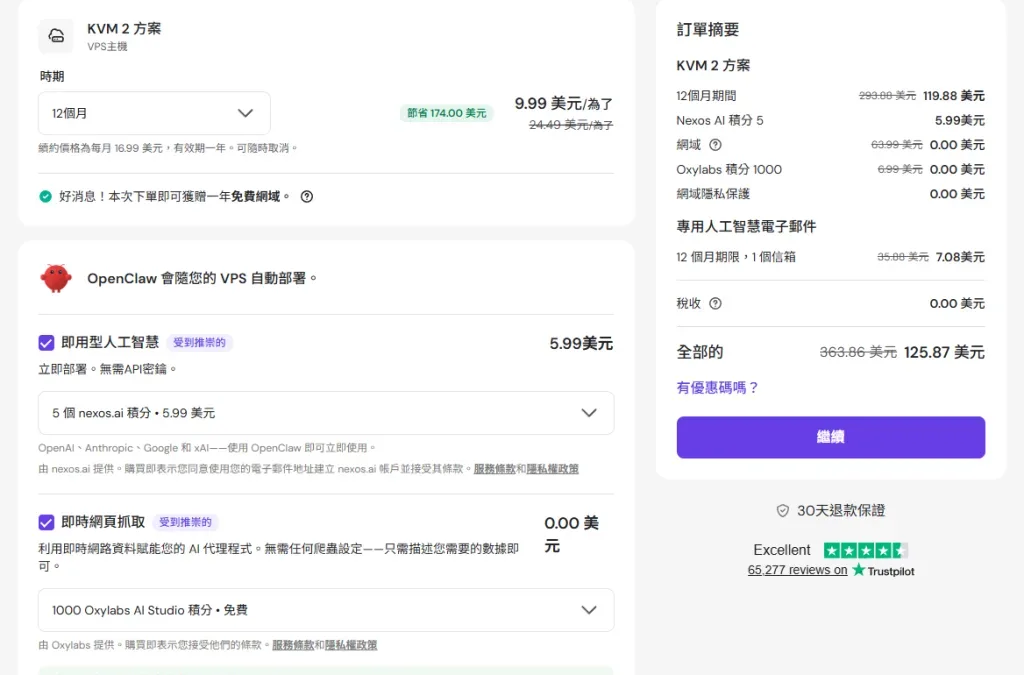
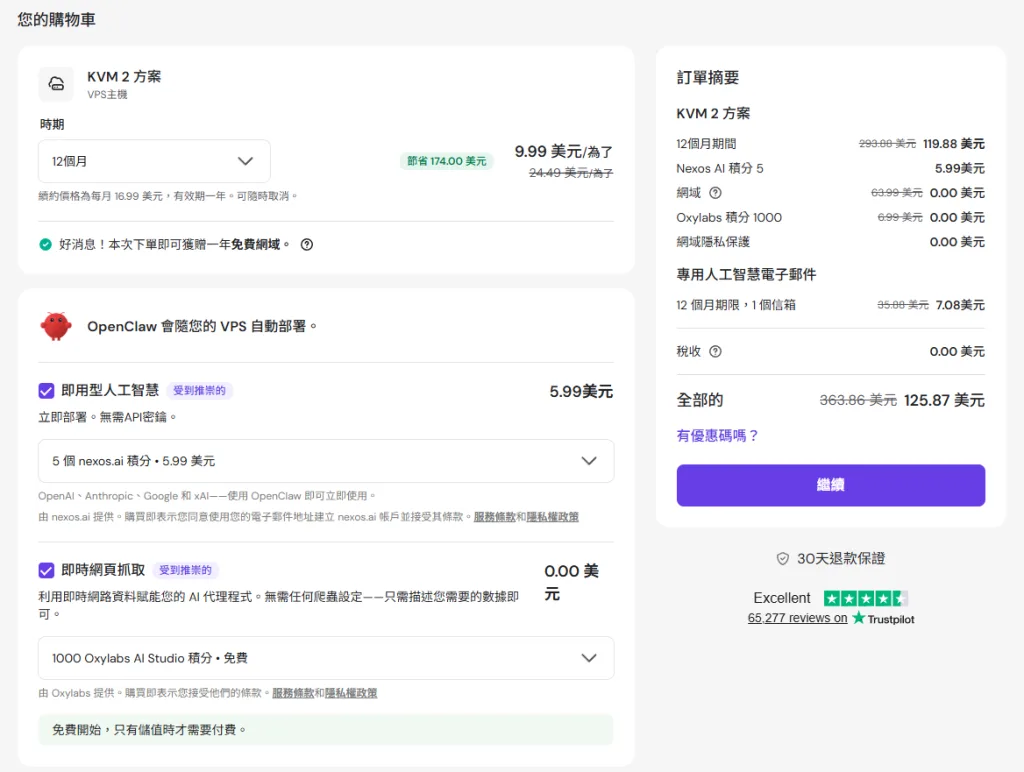
💰 成本有多低?
👉 最低只要約 $7/月
實際成本結構:
| 項目 | 價格 |
|---|
| VPS 主機 | 約 $5~$10/月 |
| AI API(選擇性) | 視使用量 |
| 總成本 | 約 $7/月起 |
👉 比你請一個員工便宜 1000 倍 😅
甚至有資料指出:
👉 VPS 部署 OpenClaw 最低約 $5/月即可開始
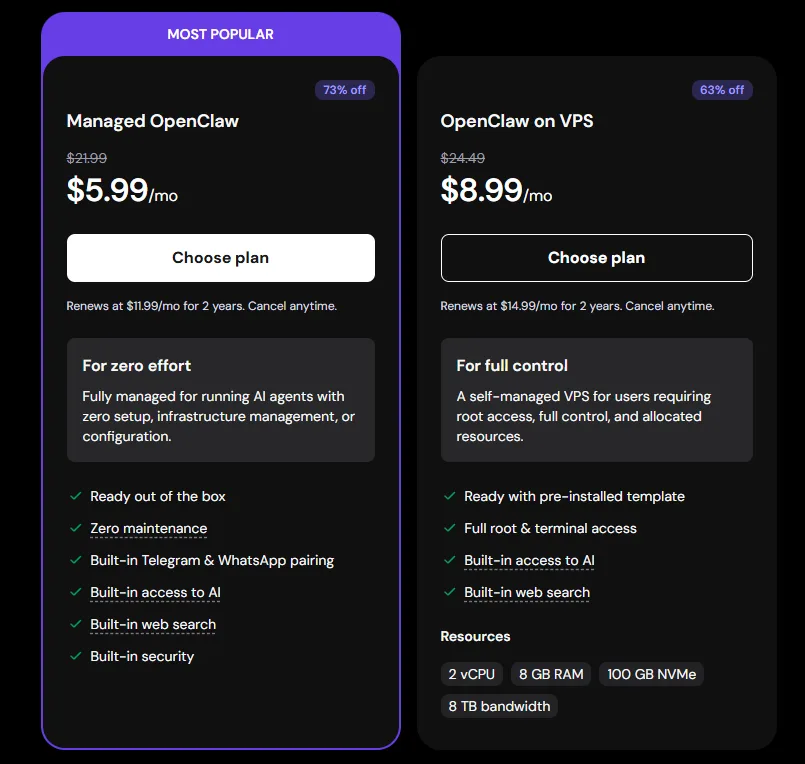
🚀 60 秒部署流程(Hostinger)
超簡單流程:
Step 1️⃣
購買 VPS(選 KVM 2 即可)
Step 2️⃣
選擇 OpenClaw 模板
Step 3️⃣
點「Deploy」
Step 4️⃣
登入 Web UI
Step 5️⃣
接上 AI(OpenAI / Claude / Ollama)
👉 完成 🎉
🔐 私有 AI 的最大價值
為什麼大家開始瘋 OpenClaw?
1️⃣ 資料完全私有
不像 SaaS AI:
2️⃣ 完全控制
3️⃣ 可自動化一切
👉 這才是真正的「AI Agent」
⚠️ 但一定要注意
OpenClaw 很強,但也有風險:
- AI 可以執行指令(高權限)
- 插件可能有安全問題
- Token 洩漏 = 全部被控
👉 建議:
- 使用 VPS(不要跑在本機)
- 分離權限
- 使用防火牆 / Cloudflare
🧠 誰適合用?
非常適合你這類型:
- DevOps / 架構師
- WordPress / SaaS 維運
- 想做 AI Agent 商業化
- 想打造自動化系統
甚至可以做:
👉 「AI SaaS 創業」
🔮 未來趨勢(很重要)
未來會變成:
- 每個人都有一個 AI Agent
- 每家公司都有 AI 自動化流程
- SaaS → AI Agent 化
👉 OpenClaw 就是這個入口
相關資訊
官方網站
https://www.hostinger.com/openclaw
by Rain Chu | 4 月 2, 2026 | Agent, AI
🧠 什麼是 OpenCLI?
OpenCLI 是一個結合 CLI(命令列)+AI Agent+瀏覽器控制能力 的工具。
它讓你可以:
- 用 AI 操作你的瀏覽器(真的操作你的 Chrome)
- 控制本地開發工具(例如 Cursor)
- 串接自訂 Plugin(抓資料、爬網站、整合 API)
👉 簡單來說,它是「本地版 AI Agent 作業系統」
🧠 核心組件說明
1️⃣ Runtime(最重要)
OpenCLI 本體負責:
👉 類似:
- LangChain Agent Executor
- 或 AutoGPT 的 runtime
2️⃣ Plugin Adapter(YAML)
👉 這是 OpenCLI 最強的地方之一
你可以:
- 把網站轉成 CLI
- 定義資料抓取規則
- 建立 AI 工具鏈
📌 重點:
👉 不是寫程式,而是寫 YAML
3️⃣ Browser Bridge(關鍵黑科技)
OpenCLI 不是用 Selenium
👉 而是:
- Playwright MCP bridge
- Chrome DevTools Protocol(CDP)
👉 直接控制「你正在用的瀏覽器」
4️⃣ Channel / Gateway
負責:
⚡ 核心特色
1️⃣ 直接使用你的 Chrome(含登入狀態)
OpenCLI 最大的優勢之一:
👉 直接控制你正在使用的 Chrome
這代表:
- ✅ 可以使用已登入的帳號(Google、FB、銀行等)
- ✅ 可以存取 cookies / session
- ✅ 不需要重新登入
背後技術是:
👉 Chrome DevTools Protocol(CDP) ( opencli chrome外掛)
這比 Selenium 強的地方在於:
2️⃣ 控制 Cursor 寫程式(AI 自動開發)
Cursor 是目前非常強的 AI 編輯器,而 OpenCLI 可以直接操控它 👇
🛠️ 設定方式
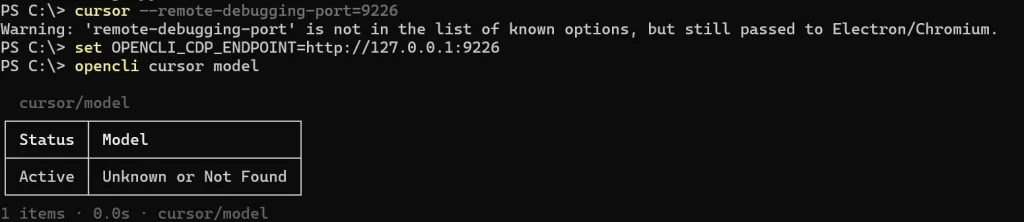
Step 1:啟動 Cursor Debug 模式
cursor --remote-debugging-port=9226
⚠️ 注意:
- 視窗 不能關閉
- 這會開啟 CDP 讓 OpenCLI 控制
Step 2:設定環境變數
mac or linux
export OPENCLI_CDP_ENDPOINT="http://127.0.0.1:9226"
windows 版本
set OPENCLI_CDP_ENDPOINT=http://127.0.0.1:9226
Step 3:測試是否成功
opencli cursor model
Step 4:讓 AI 寫程式
opencli cursor send "新增一個 readme.txt"
👉 OpenCLI 會直接:
🔥 實際應用場景
- 自動生成專案 README
- 批次修改程式碼
- 自動補齊文件
- AI Refactor 專案
👉 等於你有一個「真的會操作 IDE 的 AI 工程師」
3️⃣ 自訂 Plugin Adapter(YAML 抓網站)
OpenCLI 支援自訂 Plugin,透過 YAML 定義資料來源 👇
🧩 範例概念
name: fetch_news
description: 抓取新聞網站資料request:
url: https://example.com/news
method: GETparse:
type: html
selectors:
title: h1.title
content: div.article
👉 你可以做到:
- 抓網站資料
- 做 ETL pipeline
- 整合 API
- 建立 AI 工具鏈
📦 安裝 OpenCLI
官方資源:
npm install -g @jackwener/opencli
安裝 OpenCLI Chorm extension
https://github.com/jackwener/opencli/releases
下載 opencli-extension.zip
解壓縮後放到 chrome 的擴充套件中
檢查安裝狀態
opencli doctor
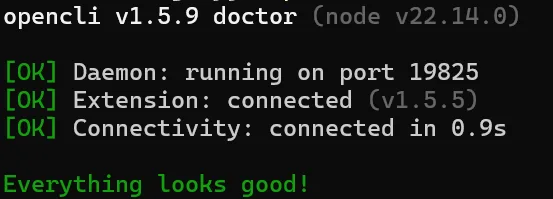
看到上面的資訊就代表成功
可以測試用自己的帳號去查 B 站的最熱門影片了
opencli bilibili hot –limit 5

⚡ 三大核心能力
🔥 1. 把任何網站變 CLI
👉 這是 OpenCLI 最核心功能
例如:
opencli hackernews top
opencli twitter mentions
opencli gmail read
背後:
🔥 2. 直接用你 Chrome(含登入)
👉 這點非常關鍵(你前面有用到)
OpenCLI:
- 不模擬登入
- 不存 cookie
- 不重建 session
👉 直接用你 Chrome 裡的登入狀態
🔥 這代表什麼?
你可以:
- 操作 Gmail
- 操作 FB / IG
- 操作內部系統(SSO)
👉 完全不像傳統爬蟲
🔥 3. 控制本地工具(Cursor / VSCode)
👉 這才是 AI Agent 真正關鍵
OpenCLI 可以:
👉 等於:
AI 可以「真的幫你寫程式」
🧪 真實應用場景
📌 1. 自動收集資訊
👉 每天做:
📌 2. 自動寫程式
👉 例如:
opencli cursor send "建立 flask API"
📌 3. 自動操作後台
👉 例如:
- WordPress 發文
- Cloud Console 操作
- CRM 系統
📌 4. 自動化工作流
👉 一句話:
👉「抓資料 → 分析 → 寫報告 → 存檔」
📱 延伸:手機 + Termux + OpenCLI
Termux + Android 手機也可以跑:
👉 搭配:
可以做到:
⚠️ 注意事項
🔒 安全性
因為它可以:
👉 建議:
⚙️ 穩定性
- CDP port 被占用會失敗
- Cursor 視窗關閉會斷線
- Plugin YAML 要寫正確
🎯 總結
OpenCLI 的本質不是工具,而是:👉 AI 的「手」
👉 AI 操作你電腦的入口
它讓你可以:
- 🧠 用 AI 控制瀏覽器
- 💻 用 AI 操作 IDE(Cursor)
- 🔗 串接任何資料來源(Plugin)
🧠 AI 能力分層
| 層級 | 能力 |
|---|
| LLM | 思考 |
| LangChain | 決策 |
| OpenCLI | 行動 |
👉 沒有 OpenCLI:
👉 AI 只能「講」
👉 有 OpenCLI:
👉 AI 才能「做」
參考資訊
https://opencli.info/docs
近期留言