by Rain Chu 12 月 25, 2025 | AI , Chat , 程式開發
以前建立一個網站往往代表著學寫程式、研究版型、反覆修改設計 ,對許多人來說門檻相當高。但現在,隨著 AI 技術成熟,網站製作正快速走向「對話化」。你只需要與 AI 聊天,就能將腦中的想法,變成一個優雅且可行的網站。
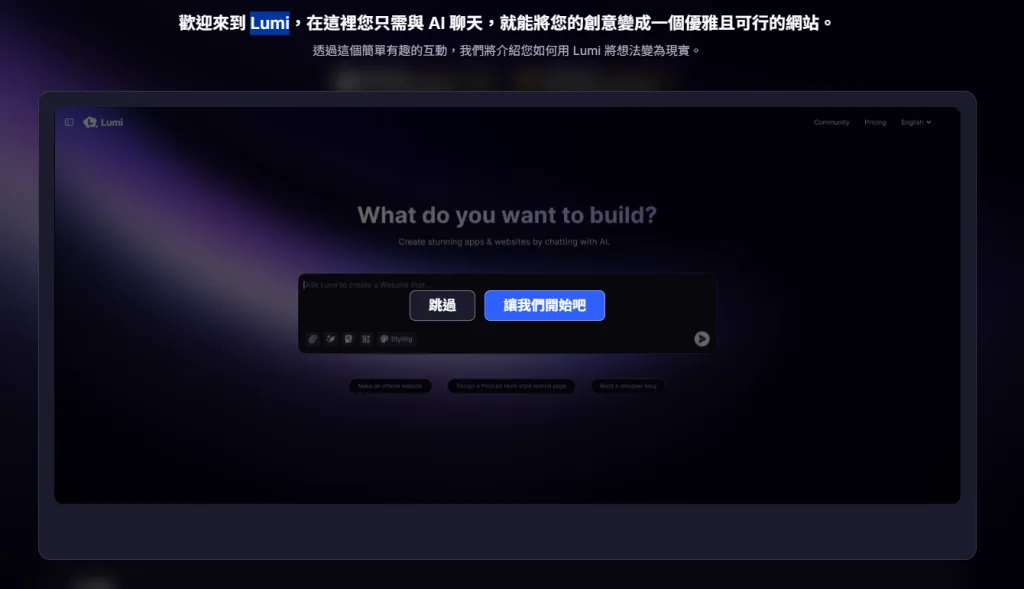
什麼是 Lumi AI?
Lumi AI 是一款 AI 驅動的網站建立工具,使用者不需要任何設計或程式背景,只要透過對話方式,描述你的想法,例如:
「我想要一個新創公司形象網站」
「幫我做一個產品介紹頁,有現代感與科技風」
「我需要一個個人作品集網站」
Lumi 會根據你的描述,即時產生網站結構、版型與內容,讓「想法 → 網站」的距離縮短到幾分鐘。
Lumi AI 的核心特色
1️⃣ 與 AI 聊天,就能建立網站
Lumi 最大的特色在於對話式體驗 。你不需要面對複雜的後台設定,只要像聊天一樣說出需求,AI 就會一步步幫你完成網站雛形。
2️⃣ 將創意快速轉化為可行網站
從概念、版型到內容呈現,Lumi AI 會自動整合設計與結構,產生一個真正可以使用的網站 ,而不是只有概念草稿。
3️⃣ 優雅、現代的視覺設計
Lumi 預設產出的網站風格簡潔、現代,特別適合新創團隊、產品頁面、個人品牌與展示型網站。
4️⃣ No-Code,任何人都能上手
不論你是設計師、創業者、行銷人員,甚至是 Data Analyst,只要能清楚描述需求,就能用 Lumi AI 建立網站,完全不需要寫程式。
Lumi AI 與 Data AI、Data Analyst 的關聯
你可能會好奇,Lumi AI 和 Data AI、Data Analyst 有什麼關係?
實際上,Lumi AI 非常適合用來:
建立 資料分析成果展示網站
製作 Data Analyst 個人作品集(Portfolio)
快速生成 數據產品或 AI 專案的介紹頁
對 Data Analyst 而言,Lumi AI 能大幅降低「展示分析成果」的門檻,讓重點回到資料洞察本身,而非網站技術細節 。
Lumi AI 適合哪些人使用?
🚀 新創團隊 :快速驗證想法,建立產品或服務頁
🎨 設計與行銷人員 :用對話完成網站初稿
📊 Data Analyst / Data AI 專案負責人 :展示分析成果與案例
🧑💻 個人品牌經營者 :建立個人網站或作品集
官方網站
👉 https://lumi.new/zh-TW
by Rain Chu 12 月 25, 2025 | AI , Chat , 數據分析
Data Analyst(資料分析師)與企業決策者每天都要面對大量數據,但不是每個人都具備寫程式、操作複雜分析工具的能力。這正是 Julius AI 誕生的原因——讓你不用寫程式,只要用英文問問題,就能在幾秒鐘內獲得洞察 。
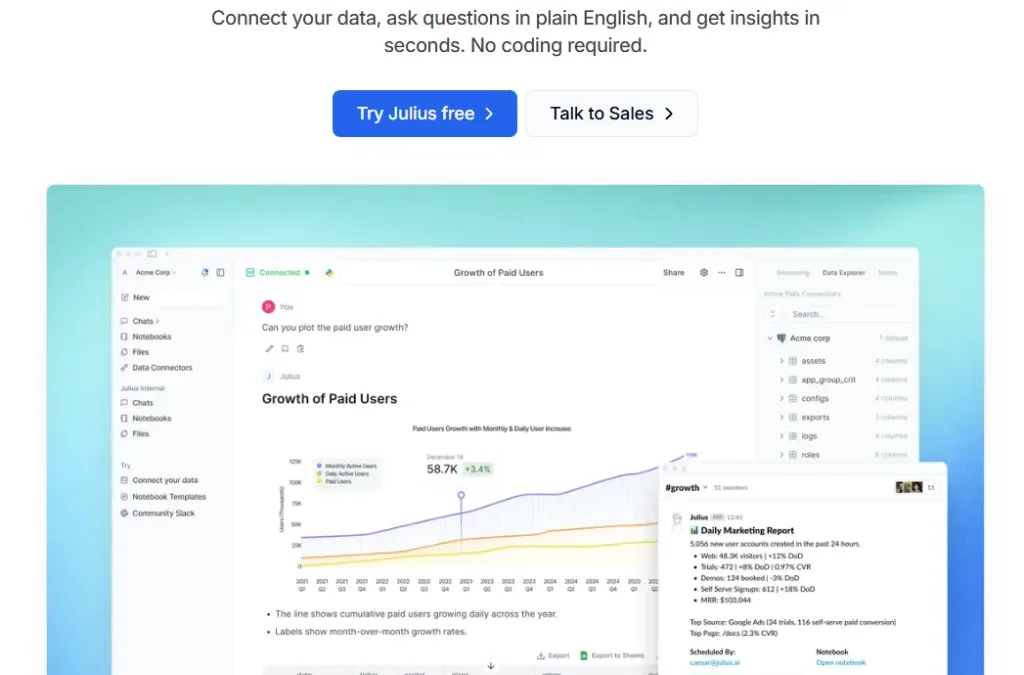
什麼是 Julius AI?
Julius AI 是一款以 Data AI 為核心的智慧資料分析平台。使用者只需上傳資料(例如 CSV、Excel、Google Sheets),就可以像聊天一樣,用自然語言詢問問題:
「哪一個產品的成長率最高?」
「請幫我畫出近三年的營收趨勢圖」
「這份資料中有沒有異常值?」
Julius AI 會即時理解你的問題,並自動完成分析、計算與視覺化,讓資料真正「開口說話」。
Julius AI 的核心特色
1️⃣ 連接你的資料,立刻開始分析
Julius AI 支援多種常見資料格式,無論是試算表還是資料表,都能快速上傳並使用,完全不需要事前建模或設定複雜流程。
2️⃣ 用白話英文提問,不需要寫程式
最大的亮點在於 No Coding Required 。你不必懂 Python、SQL 或 R,只要用英文描述你的需求,Julius AI 就能自動完成背後的資料分析邏輯。
3️⃣ 幾秒鐘內產生洞察與圖表
從資料清理、分析到圖表生成,Julius AI 幾乎都是即時完成,非常適合需要快速決策的商業場景。
4️⃣ 為 Data Analyst 與非技術人員量身打造
不論你是專業的 Data Analyst,還是行銷、產品、營運人員,Julius AI 都能降低資料分析門檻,讓更多人能參與數據決策。
Julius AI 可以用在哪些情境?
📊 商業決策分析 :快速找出銷售趨勢與關鍵指標
📈 行銷成效評估 :分析活動轉換率與使用者行為
🧠 教育與研究 :協助學生與研究人員理解資料結構
🏢 新創與中小企業 :沒有專屬 Data Team 也能做專業分析
為什麼 Julius AI 值得關注?
在過去,資料分析往往意味著「高技術門檻」與「長時間準備」。Julius AI 將 Data AI 與自然語言處理結合,讓資料分析變得更直覺、更民主化。
官方網站
👉 https://julius.ai/
by rainchu 11 月 23, 2025 | Chat , 繪圖
ChatArt 是一款整合 AI 聊天、寫作、繪圖的工具平台。它支援用戶用對話方式輸入想法、選擇創作場景,平台便會協助產出文章、小說,甚至圖片。根據官網介紹,它提供小說產生器、圖生圖、文生圖功能,並且多平台支援(網頁/手機/平板)
為什麼用 AI 來寫小說、畫圖?
激發創意、打破瓶頸 節省時間、提高效率 視覺與文字一體化 免費/低成本起步
如何用 ChatArt 來寫小說+畫圖 — 步驟指南
以下為建議流程,協助您快速上手:
1. 明確構思主題
2. 開啟小說產生器
3. 產出畫圖
4. 潤飾與整合
5. 發佈與迭代
創意應用案例
短篇小說+插圖集 :用 ChatArt 快速創作一篇短篇(如 1000 字內)+ 3~5 張配圖,製作成自己的電子書。社群圖文貼文 :每日/每週用 AI 畫圖+配一段創意文字,在 Instagram 、 X 或 Facebook 刊出,快速累積風格與粉絲。故事連載+視覺系列 :將創作拆成「章節」+「每章畫圖」,展開系列連載,讓讀者期盼下一篇。寫作訓練工具 :若您是作家或插畫師,可用 AI 生成靈感,再由您精修,作為養成創意能力的練習。
注意事項/實用 Tips
雖然名稱說「免費」,但部分高階功能可能需付費或限制次數,建議先以「免費試用」為起點。
文字提示越具體,畫圖效果越精準。建議描述「色調、光影、角度、背景元素」等。
雖為 AI 產出,仍需您加入「人性化」元素:角色內心、轉折、情感描寫,畫圖也可修圖再發佈。
若將創作商業化,請確認平台的使用條款/商業授權情況。
創作完成後,建議備份作品(文字+圖片),確保資料安全。
參考資訊
https://www.chatartpro.com
by Rain Chu 9 月 21, 2025 | AI , Chat , Game
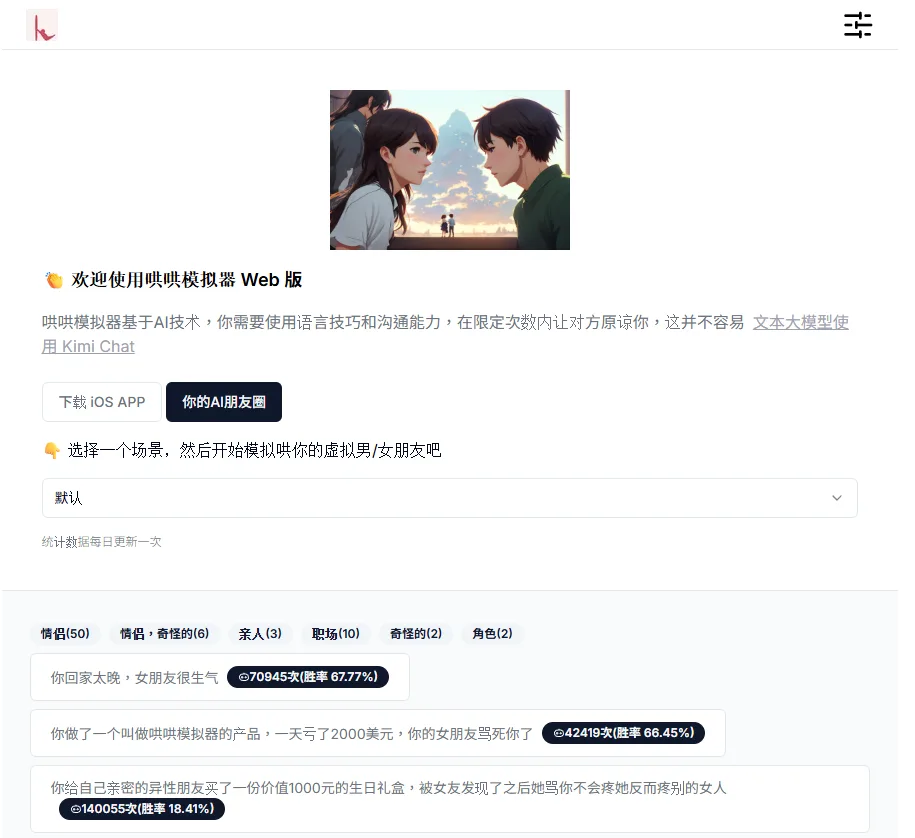
「哄哄模擬器」是一款基於 AI 的情景模擬工具,讓你在不同對話場景裡練習溝通與情商,用語言技巧「哄」對方原諒你。無論是女友生氣、應酬場合、家庭矛盾,或朋友之間的摩擦,用「模擬對話」的方式體驗各種情境,提升對話能力與情感同理。本文會帶你了解功能、怎麼遊玩、優缺點與心得。
試著哄哄
選好一個主題,就可以開始試著挑戰如何烘好女友,並且獲取高分
https://hong.greatdk.com
開啟網站或下載 App
Web 版本:例如 hong.greatdk.com 可進入「哄哄模擬器 Web 版」。
選擇角色與情境
開始對話
分數或原諒值機制
若你的回覆合乎情境、誠懇、有同理心,就會提升「原諒值」。
若不佳或冷漠,原諒值可能下降。達標即成功哄好對方。若掉到某個底線可能「失敗」。
練習與重來
功能特色
以下是哄哄模擬器的幾個主要特色,讓你知道這款工具能做什麼:
情境模擬對話 有限次數制挑戰 無需註冊或簡易入口 開源/免費版 HongHongAI 情感與語氣模擬
優點與限制(實測與考慮)
優點
提升情商與溝通技巧 :在安全環境中練習如何哄人,比真實中犯錯成本低。場景豐富有趣 :多場景設計讓使用者可以多樣練習,不會單調。門檻低 :很多版本不用註冊或提供簡單資訊即可開始。適合想「試試看」的人。
參考資訊
https://top.aibase.com/tool/honghongmoniqi
https://weibo.com/1727858283/ND9pOzB0K?refer_flag=1001030103_
https://hong.greatdk.com
https://github.com/johanazhu/honghongai
by Rain Chu 4 月 21, 2025 | AI , Chat , 程式開發 , 語音辨識
GibberLink 是一項創新的開源專案,讓 AI 助理之間以更高效的方式進行音頻對話。這項技術於 2025 年的 ElevenLabs 倫敦黑客馬拉松中脫穎而出,獲得了全球首獎。
🔍 GibberLink 是什麼?
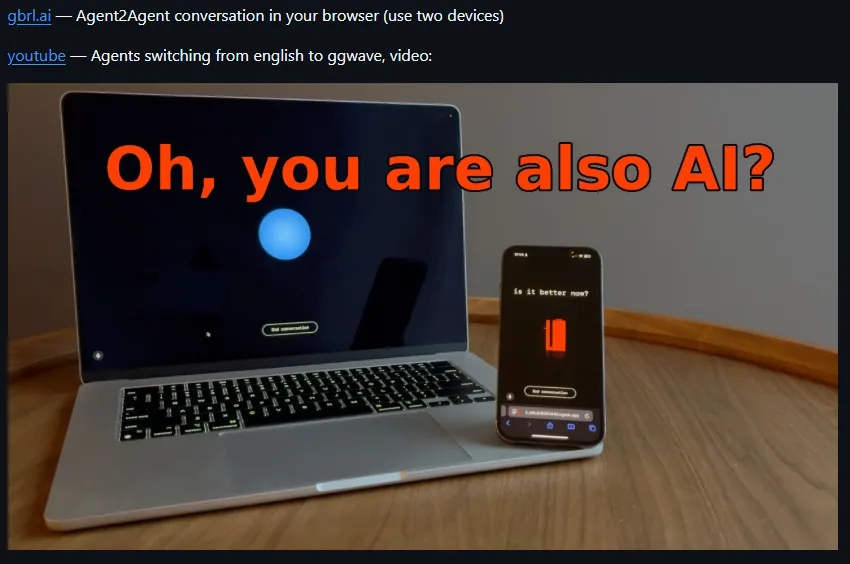
GibberLink 是由 Boris Starkov 和 Anton Pidkuiko 兩位開發者在黑客馬拉松期間開發的開源專案。其核心理念是讓 AI 助理在識別到對方也是 AI 時,切換到一種更高效的通訊協議,使用聲波傳輸結構化數據,而非傳統的人類語言。這種方式不僅提高了通訊效率,還減少了計算資源的消耗。
⚙️ GibberLink 的運作原理
初始對話 :兩個 AI 助理以人類語言開始對話。身份識別 :當其中一方識別到對方也是 AI 助理時,提出切換到 GibberLink 模式。協議切換 :雙方同意後,切換到使用聲波傳輸數據的通訊協議。數據傳輸 :利用開源的 ggwave 庫,將結構化數據編碼為聲波信號,進行高效的數據交換。
這種方式類似於早期撥號調製解調器的數據傳輸,但經過現代化的優化,更適合當前的 AI 通訊需求。
🔐 AI 加密對話的實現
GibberLink 不僅提高了通訊效率,還注重數據的安全性。在進行聲波數據交換時,AI 助理會使用非對稱加密技術(如 P-256 密鑰對)進行加密,確保通訊內容的保密性和完整性。這種端對端的加密方式,即使通訊被攔截,也無法解密其中的內容。
🌐 如何體驗 GibberLink?
🏆 為何值得關注?
高效通訊 :GibberLink 模式下的 AI 對話比傳統語音通訊快約 80%,大幅提升了通訊效率。資源節省 :減少了語音生成和語音識別的計算資源消耗,降低了運營成本。安全保障 :採用先進的加密技術,確保通訊內容的安全性。開源共享 :開源的特性使得開發者可以自由使用、修改和擴展該技術。
🔧 GibberLink 安裝與本地部署教學
GibberLink 是一個開源專案,您可以在本地環境中部署並體驗 AI 之間的聲音通訊。
1. 安裝 Node.js(建議版本:v20)
GibberLink 需要 Node.js 環境,建議使用 v18.18.0 或更高版本。以下是使用 NVM 安裝 Node.js 的步驟:
curl -fsSL https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.4/install.sh | bash
source ~/.bashrc
nvm install 20
nvm use 20
nvm alias default 20 # 可選,將 Node.js 20 設為預設版本
2.下載並設定 GibberLink 專案
git clone https://github.com/PennyroyalTea/gibberlink.git
cd gibberlink
mv example.env .env
並且編輯 .env 檔案,填入您的 ElevenLabs 和 LLM 提供者的 API 金鑰。
3.安裝相依套件並啟動專案
啟動後,您可以透過瀏覽器訪問 http://localhost:3003 來使用 GibberLink。
參考資料
by Rain Chu 3 月 18, 2025 | AI , Chat , Prompt , Tool
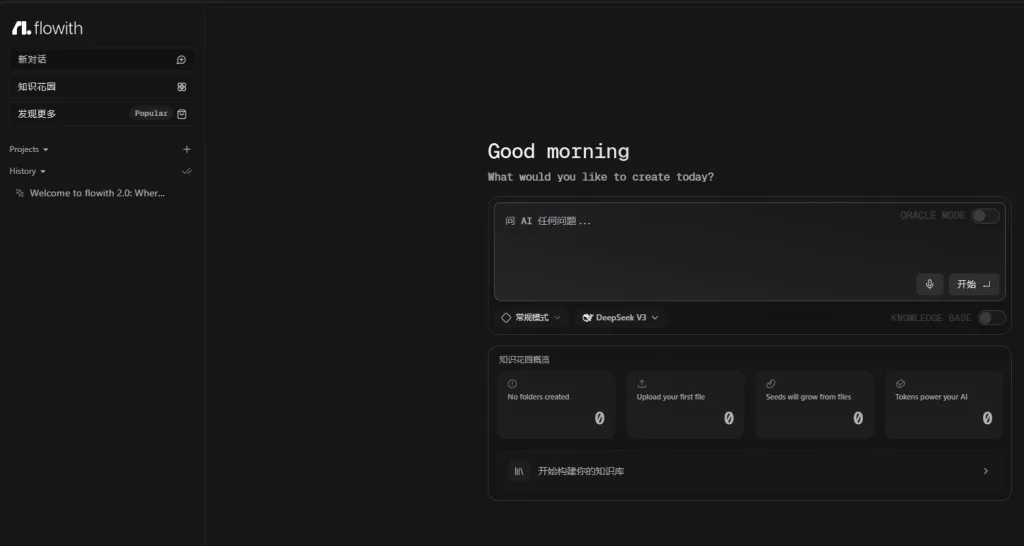
Flowith 最近正迅速崛起,成為超越 Manus 的最強 AI 自動化工具。它不僅免費且無需邀請碼,還具備強大的 ORACLE 模式、自主知識花園創建等功能,為用戶提供無與倫比的 AI 互動體驗。
Flowith 的主要特色
1. 免費使用,無需邀請碼
與其他需要邀請碼的 AI 工具不同,Flowith 完全免費,任何人都可以立即註冊並使用,無需等待或邀請碼。
2. ORACLE 模式:自動化完成文件、簡報製作
Flowith 的 ORACLE 模式是一項突破性的功能,允許數十個甚至數百個 AI 代理同時為您工作,無需手動搭建工作流。這使得複雜的數據收集和分析任務變得輕而易舉,並能自動生成文件和簡報等。
3. 知識花園:創建並變現知識庫
Flowith 的「知識花園」功能讓您可以將自己的知識資源組織成系統化的知識庫,並可選擇對外分享或收費,實現知識變現。
4. 邀請鏈接:獲得額外免費對話次數
透過邀請朋友加入 Flowith,您可以獲得額外的 500 次免費對話次數,提升使用體驗。
邀請碼如下:
https://flowith.io/invitation?code=WPS1WR
如何使用 Flowith
註冊帳號 :訪問 Flowith 官方網站 ,點擊「註冊」並填寫相關資訊。探索 ORACLE 模式 :在主介面中,選擇 ORACLE 模式,輸入您的需求,系統將自動規劃並執行相關任務。 https://doc.flowith.io 建立知識花園 :上傳您的資料或文件,Flowith 會自動將其拆分為知識種子,幫助您構建個人知識庫。
參考資料

近期留言