by Rain Chu | 4 月 13, 2026 | AI, claude
在 AI 開發工具快速演進的時代,Claude Code 正逐漸成為開發者與 AI Agent 架構中的核心工具。然而,多數人卡在同一個問題:
👉「文件看懂了,但就是不會用」
如果你也遇到這個問題,那麼這個教學網站會是目前最有效的解法之一👇
👉 Learn Claude Code 教學平台
🎯 為什麼這個網站值得學?
這個網站最大的核心理念只有一句話:
「Learn Claude Code by doing, not reading」
也就是——用做的學,而不是用看的學
它提供:
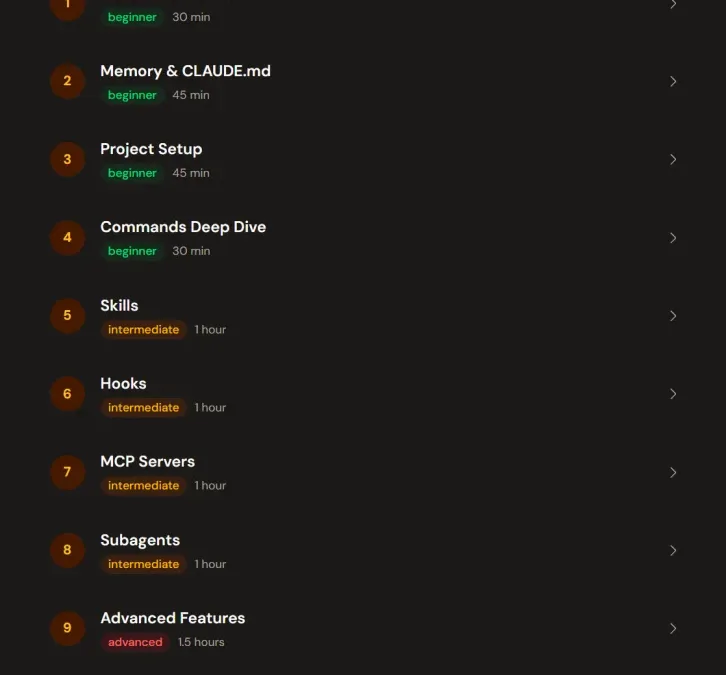
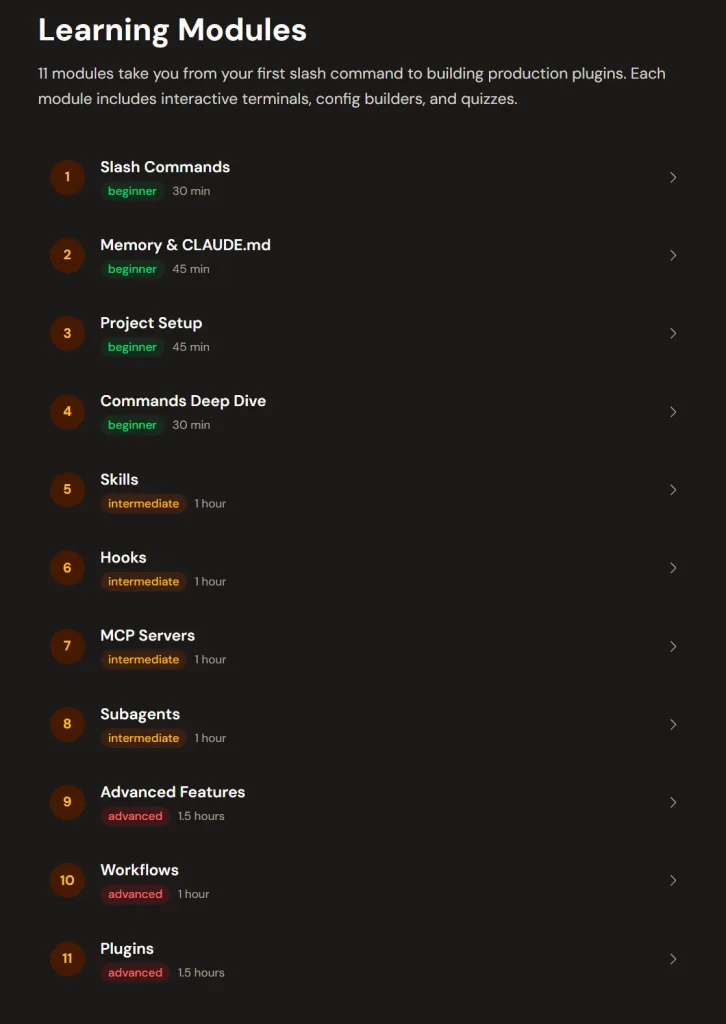
- ✅ 完整 11 個學習模組(從 beginner → advanced)
- ✅ 瀏覽器內建終端機(不用安裝)
- ✅ 可直接生成設定檔(CLAUDE.md / hooks / plugins)
- ✅ 每章節都有測驗+錯誤解析
👉 重點:學完可以直接上 production,不只是看懂概念
🧠 教學架構:真正「由淺入深」的學習路線
這個平台的設計非常接近實務開發流程:
🔰 初學者階段(建立基礎)
- Slash Commands(指令操作)
- Memory & CLAUDE.md(記憶與設定)
- Project Setup(專案初始化)
- Commands Deep Dive(指令進階)
👉 幫你打好 Claude Code 的「操作基礎」
⚙️ 中階能力(開始做系統)
- Skills(技能模組)
- Hooks(自動觸發邏輯)
- MCP Servers(外部資料整合)
- Subagents(子代理)
👉 開始打造 AI Agent 系統
🚀 進階實戰(Production 等級)
- Advanced Features
- Workflows
- Plugins
👉 直接進入「可商用」的 AI 系統設計
⚡ 最大亮點:邊學邊做,立即實作
1️⃣ 瀏覽器就是你的開發環境
不需要:
- ❌ 安裝 Claude Code
- ❌ 設定 API Key
- ❌ 處理環境問題
👉 直接開網頁就能練習指令
2️⃣ 超強 Config Builder
你只要填表單,它會幫你產生:
- CLAUDE.md
- Skills
- Hooks
- MCP Server 設定
- Plugins
👉 直接 copy 到專案就能用
3️⃣ Quiz 機制(真的會學會)
不像一般教學只是:
👉 對 / 錯
這裡是:
👉 ❌ 錯了 → 告訴你「為什麼錯」
這點對理解 Claude Code 非常關鍵。
🧩 適合哪些人?
這個教學網站特別適合:
- 🔹 想學 Claude Code 的新手
- 🔹 想做 AI Agent / 自動化系統的人
- 🔹 已經會用,但不懂 hooks / MCP / skills 的開發者
- 🔹 想快速做出 AI SaaS 或內部工具的人
🧠 為什麼這種學習方式更有效?
傳統學習方式:
文件 → 理解 → 嘗試 → 卡住 → 放棄
這個平台:
操作 → 立即回饋 → 修正 → 建立理解
👉 這其實就是「工程師最有效的學習方式」

by Rain Chu | 4 月 12, 2026 | AI, API
🧠 ApiFree 沒法讓你財富自由,但你可以先實現 API 自由
在 AI 時代,真正的競爭力不再只是技術能力,而是「調用資源的效率」。
你可能用過 OpenAI、Anthropic、Google 的模型,但你一定也遇過這些問題:
- API 太貴,Token 一直燒
- 每個模型都要不同 SDK / endpoint
- 模型切換麻煩,整個系統要改一堆
- 成本難控,難以 scale
這時候,一個新概念出現了:
👉 API 自由(API Freedom)
而 ApiFree,就是專門為這件事而生。
⚡ 什麼是 ApiFree?
ApiFree 是一個 AI API 聚合平台,讓你用「一個 API」就可以調用多個主流 AI 模型。
簡單來說:
👉 One API. Any Model.
你不需要再為每個模型寫不同整合
也不需要再管理一堆 API Key
🔥 核心特色解析
🚀 Faster and Cheaper(更快、更便宜)
ApiFree 透過優化推理(Inference)層,讓你在使用 AI 模型時:
- 延遲更低(Low Latency)
- 成本更低(Cost Reduction)
- 更適合高併發應用(High Concurrency)
👉 對你這種在做 AI Agent / SaaS / WP + AI 整合 的架構來說
這點直接影響毛利率。
🤖 Popular Models, Ready to Use
不用再自己整合:
- GPT 系列
- Claude 系列
- 開源模型(如 LLaMA / Mistral 等)
全部都已經 ready:
👉 你只要呼叫 API,就能直接用
🔌 One API. Any Model.
這是最關鍵的能力:
你可以:
- 同一套程式碼切換模型
- 動態 routing(例如 fallback)
- 做 multi-model ensemble
例如:
# 原本
openai.chat.completions.create(...)# 用 ApiFree
client.chat.completions.create(
model="gpt-4o" # 可隨時改成 Claude / LLaMA
)
👉 對在做 LangChain / AI Agent 架構
這直接是神器等級。
🧠 Powered by Cutting-Edge Inference
ApiFree 的底層不是單純 proxy,而是:
- 模型調度(Model Routing)
- 推理優化(Inference Optimization)
- 成本最佳化(Cost-aware execution)
這代表:
👉 不是只有整合,而是幫你「用得更聰明」
💡 為什麼這叫「API 自由」?
以前你是這樣:
現在變成:
- 想換模型 → 直接換
- 想降成本 → 自動 routing
- 想升級品質 → 切高階模型
👉 你從「使用者」變成「調度者」
✅ 但它可以讓你更快做到這件事
👉 降低成本 = 提高存活率
👉 提升效率 = 更快迭代
👉 降低技術門檻 = 更快上線
這才是關鍵。
🎯 結論
❌ ApiFree 不能讓你財富自由
✅ 但它可以讓你先實現「API 自由」
而在 AI 時代:
👉 API 自由 = 開發自由 = 商業自由
by Rain Chu | 4 月 10, 2026 | AI, 記憶
覺得 AI 助理總是問一次忘一次?這次不一樣 Rowboat 深度解析
你應該也遇過這種情況:
👉 跟 AI 聊了一堆專案細節
👉 隔天再問,它完全忘光
這不是你錯,是目前大多數 AI 的「設計限制」。
但現在,有一個專案正在顛覆這件事 —— Rowboat
它的目標不是做一個聊天機器人,而是:
✅ 一個「有長期記憶」的 AI 數位同事
✅ 一個能理解你工作脈絡的 AI Agent
✅ 一個真正能幫你處理工作的系統
🚀 Rowboat 是什麼?
Rowboat 是一個 Local-First 的 AI Agent 系統,核心概念很簡單但非常關鍵:
👉 AI 不應該只靠 prompt,而應該有「記憶系統」
它的架構結合了:
- 本地資料存儲
- 知識圖譜(Knowledge Graph)
- Markdown-based 知識庫
- AI 任務自動化
👉 簡單講:它讓 AI 變成「真的記得事情的人」
🎥 Rowboat 實際運作
這支影片展示了 Rowboat 如何:
- 自動整理資訊
- 建立關聯
- 持續累積記憶
- 協助日常工作
🏗️ 核心特色一:Local-First 架構(真正的資料主權)
🔐 為什麼 Local-First 很重要?
傳統 AI:
Rowboat:
👉 所有資料存在你的電腦裡
這帶來幾個關鍵優勢:
✅ 完全資料掌控
✅ 可離線運作(搭配本地模型)
✅ 適合企業 / 敏感資料
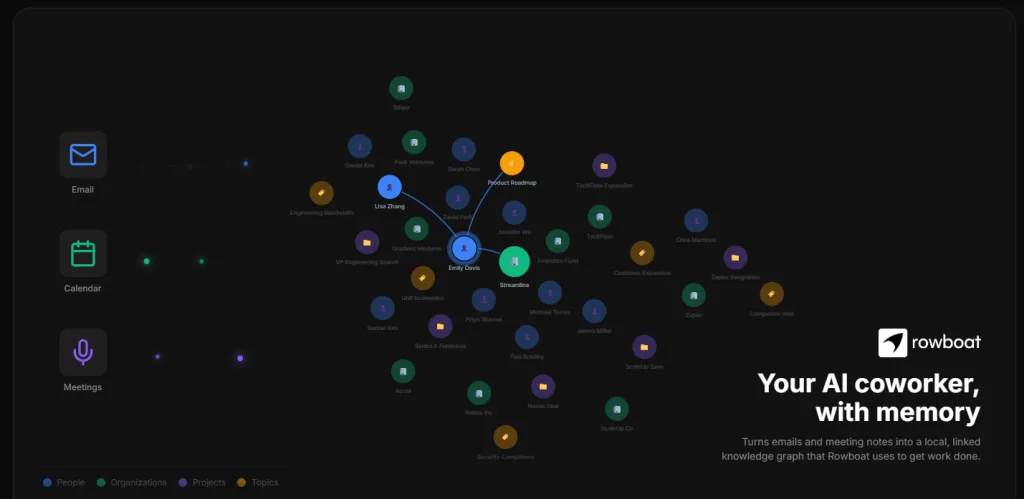
🧩 核心特色二:知識圖譜(AI 長期記憶的核心)
Rowboat 最大的突破在這裡:
👉 它不是存資料,而是建立「關係」
📊 傳統 AI vs Rowboat
| 類型 | 記憶方式 |
|---|
| ChatGPT | 單次對話 |
| RAG | 文件檢索 |
| Rowboat | 🧠 知識圖譜 |
🧠 知識圖譜能做什麼?
Rowboat 會自動:
- 連結 Email ↔ 人物
- 連結會議 ↔ 專案
- 連結任務 ↔ 文件
- 建立「上下文關係」
例如:
Rain → GCP 專案 → Cloud Run 架構 → WordPress
👉 AI 會「理解脈絡」,不是只找資料
📝 核心特色三:Obsidian 相容(Markdown = 最強知識格式)
Rowboat 選擇一個非常聰明的設計:
👉 用 Markdown 當資料格式
並且相容 Obsidian
💡 為什麼這很重要?
✅ 永遠不被綁架
✅ 可讀可改
✅ AI 友善
- 非結構 → 可結構化
- 易於 embedding / parsing
👉 這點比很多 SaaS 工具高級非常多
🤖 核心特色四:數位分身(真正能工作的 AI)
Rowboat 的最終目標:
👉 建立一個「數位分身 AI」
🧪 實際應用場景
🧑💼 1. 會議助理
- 自動整理會議紀錄
- 建立關聯人物
- 產生 follow-up 任務
📂 2. 專案理解
📧 3. Email 分析
🧠 4. 個人知識庫
👉 AI 不只是回答問題,而是「幫你做事」
🆚 Rowboat vs 一般 AI Agent
| 功能 | 一般 Agent | Rowboat |
|---|
| 記憶 | ❌ 短期 | ✅ 長期 |
| 資料位置 | 雲端 | 本地 |
| 結構 | 無 | 知識圖譜 |
| 控制權 | 低 | 高 |
| 可擴展 | 中 | 高 |
💡Rowboat 的實戰評價
如果你是:
- DevOps / 架構師
- 多專案管理者
- WordPress / GCP 維運
- AI Agent 開發者
👉 Rowboat 很可能是你下一步的「核心系統」
因為它解決一個關鍵問題:
❗ AI 沒有記憶,就永遠只是工具
✅ AI 有記憶,才會變成「同事」
🚀 結論:Rowboat 是 AI 的「第二階段」
第一階段:
👉 ChatGPT(會回答)
第二階段:
👉 Rowboat(會記住 + 會做事)
未來:
👉 每個人都會有一個「數位分身 AI」
而 Rowboat,正在把這件事變成現實。
🔗 官方資源
參考資訊
by Rain Chu | 4 月 10, 2026 | AI, google
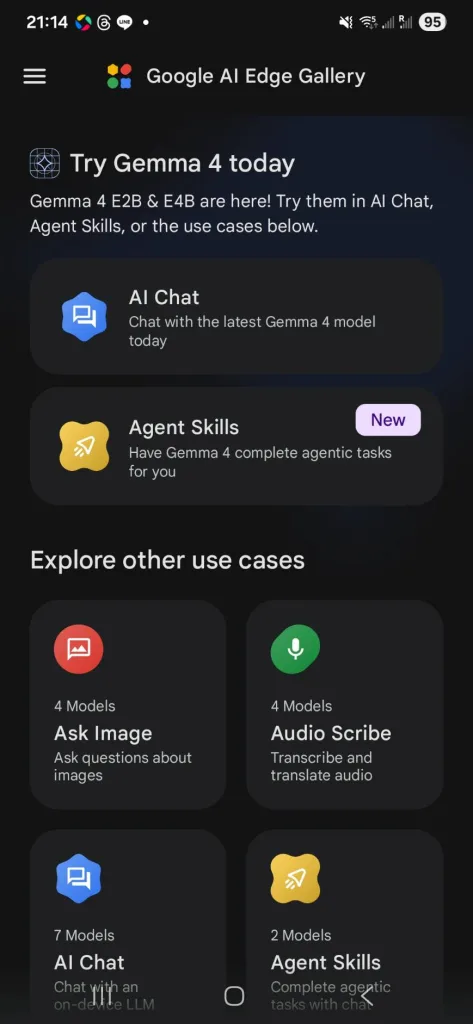
近年 AI 發展幾乎都依賴雲端,但現在 Google 正在顛覆這一切,透過最新的 Google AI Edge Gallery App,你已經可以在手機上「離線」直接運行 Gemma 4 大模型,不只文字對話,還能做到圖片理解、語音應用,甚至 AI Agent。
👉 換句話說:
你的手機,正在變成一台隨身 AI 伺服器。
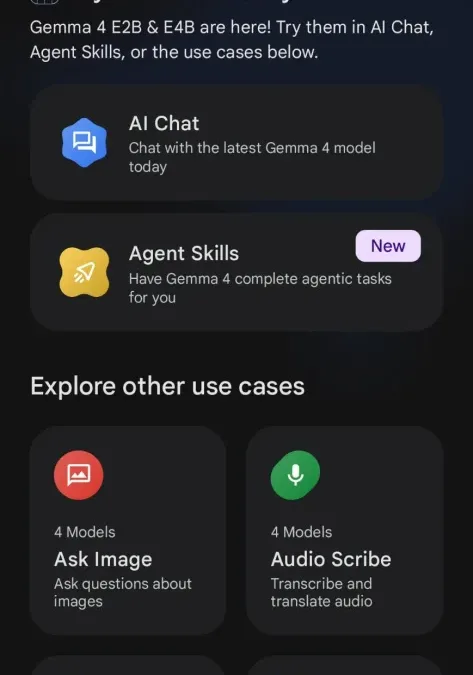
📱 什麼是 Google AI Edge Gallery?
Google AI Edge Gallery 是 Google 推出的開源應用,讓使用者可以:
- 在手機上下載 AI 模型
- 完全「離線」執行
- 不需要連網、不上傳資料
👉 也就是「On-device AI(裝置端 AI)」
📌 重點特色:
- 🔒 完全隱私(資料不離開手機)
- 📡 完全離線(無網路也能用)
- ⚡ 低延遲(不用等雲端回應)
這款 App 主打「直接在硬體上運行生成式 AI」,讓手機具備高效 AI 推理能力
🧠 Gemma 4 是什麼?為什麼這麼強?
Gemma 4 是 Google 最新開源大模型,基於 Gemini 技術打造。
👉 核心重點:
- 支援多種尺寸(可跑在手機)
- 強化推理能力與邏輯能力
- 可本地執行(Edge AI)
目前部分版本(如 E2B / E4B)已經可以在手機透過 AI Edge Gallery 直接跑
👉 簡單講:
| 類型 | 傳統 AI | Gemma 4 |
|---|
| 運算位置 | 雲端 | 本地(手機) |
| 隱私 | 低 | 高 |
| 延遲 | 高 | 低 |
| 成本 | 訂閱制 | 免費 |
🖼️ 不只是聊天:圖片+語音也能搞定
這次最關鍵的不是「能聊天」,而是👇
🔍 多模態能力(Multimodal)
Gemma 4 + Edge AI 已經可以支援:
- 📷 圖片理解(Image Recognition)
- 🎤 語音相關應用(Speech)
- 🧾 OCR / 文件理解
- 🤖 Agent 自動任務
👉 代表未來:
手機 AI 可以直接「看圖、聽聲音、做決策」
⚙️ 實際運作方式
👉 關鍵技術:
- 模型量化(Quantization)
- 邊緣推論(Edge Inference)
- NPU 加速
這也是為什麼現在手機能跑 AI 的核心原因。
🧪 實測重點
✔ 優點
- 不用網路也能用 AI
- 資料完全私密
- 速度比雲端更即時
- 免費使用
❌ 缺點
- 模型體積大(2GB~5GB)
- 手機會發熱
- 功能還在成長中
🤖 AI Agent 能力(未來最可怕的地方)
AI Edge Gallery 還支援「Agent Skills」:
- 可接工具(如地圖、知識庫)
- 可自動完成任務
- 可擴展插件
👉 官方甚至強調:
AI 可以從單純聊天變成「主動助理」
🌍 這代表什麼?(重點分析)
這不只是 App,而是產業轉折點👇
1️⃣ AI 從「雲端」走向「個人設備」
- ChatGPT → 雲端 AI
- Gemma 4 → 個人 AI
2️⃣ AI 成為手機標配(像相機一樣)
未來:
- 每支手機都有 AI
- AI 常駐本地運行
- 即時處理所有需求
3️⃣ 新創機會爆炸(你可以做)
結合你現在在做的 AI Agent / LangChain:
👉 你可以做:
- 本地 AI 房仲助理
- 離線 AI CRM
- 私有 AI 商業分析工具
- Edge AI SaaS(超有機會)
🧭 實際使用流程(超簡單)
- 安裝 App(Play Store / iOS)
- 下載模型(Gemma 4)
- 開始使用(Chat / Image / Voice)
👉 約 5 分鐘內完成
🏁 結論:AI 正在「回到你手上」
Google 這一步很關鍵:
👉 AI 不再只是雲端服務
👉 而是變成「你手機的一部分」
未來 3 年:
每個人都會有一個「離線 AI 助理」
而你現在就可以先卡位。
官方網頁
https://play.google.com/store/apps/details?id=com.google.ai.edge.gallery&pli=1
https://github.com/google-ai-edge/gallery?tab=readme-ov-file
by Rain Chu | 4 月 8, 2026 | AI, 記憶
在 AI 進入 Agent 時代後,「記憶」成為最關鍵的能力之一。而令人意外的是,這場技術突破,竟然來自好萊塢女星 —— Milla Jovovich(蜜拉·喬娃維琪)。
她與開發者合作,在 GitHub 上開源了一個震撼業界的專案:MemPalace。
👉 一個主打「AI 永不失憶」的記憶系統。
🧠 為什麼 AI 需要「記憶系統」?
目前主流 LLM(像 Claude / GPT)都有一個致命缺陷:
👉 沒有長期記憶(Stateless)
每次對話都是重新開始:
- 不記得你昨天做了什麼
- 不記得專案決策
- 不記得 debug 過程
這對 AI Agent、開發助手、甚至個人助理來說,是致命問題。
蜜拉喬娃維琪正是因為這個痛點,才開始打造 MemPalace。
🏛️ 核心創新:AI 版「記憶宮殿」
MemPalace 的靈感來自古希臘的記憶技巧 —— 記憶宮殿(Memory Palace)
👉 用空間來組織記憶,而不是用「列表」
MemPalace 架構:
- 🏛️ Wings(翼):專案 / 人物
- 🚪 Rooms(房間):主題分類
- 🏙️ Halls(走廊):記憶類型
- 📦 Drawers(抽屜):原始資料(永不刪除)
- 🧳 Closets(櫃子):壓縮記憶
這種結構讓 AI:
✔ 可以「導航記憶」
✔ 不只是搜尋,而是理解上下文
✔ 記住「過程」而不是只有結論
👉 比傳統 RAG 更接近人類記憶方式
⚙️ 技術亮點解析
1️⃣ 無損記憶(Verbatim Storage)
與傳統工具(Mem0、Zep)不同:
❌ 不做摘要
❌ 不丟棄資訊
👉 全部原始資料保留
「你不能失去從未刪除的東西」
2️⃣ AAAK:AI 專用無損壓縮語言
MemPalace 提出一個創新概念:
👉 AAAK(AI Abbreviation Language)
特點:
- 約 30 倍的無損壓縮
- LLM 可直接讀取(無需解碼)
- 保留語義完整性
但也有爭議:
⚠ 壓縮後準確率可能下降(約 96% → 84%)
3️⃣ 完全本地運行(Local-first)
👉 使用:
- ChromaDB(向量搜尋)
- SQLite(知識圖譜)
這對企業與隱私場景極具吸引力。
4️⃣ ClaudeCode 深度整合
MemPalace 專為 Claude Code 設計:
- MCP server 架構
- 可直接被 AI 呼叫
- 支援自動寫入 / 搜尋記憶
👉 幾乎零程式碼即可整合
📊 效能與市場迴響
MemPalace 一推出就引爆 AI 社群:
- ⭐ GitHub 星數:數千~上萬(短時間內暴增)
- 👀 觀看數:約 35 萬+
- 🧪 LongMemEval:
👉 被稱為「史上最強 AI 記憶系統」
但也有爭議:
- 100% 分數有調整測試案例
- 部分 benchmark 設定被質疑
👉 結論:強,但不是完美
🔥 為什麼這個專案重要?
MemPalace 代表一個關鍵轉變:
🧩 從「模型能力」→「記憶系統」
未來 AI 能力不只取決於模型:
👉 更取決於:
🧠 如何使用?
以下是實際應用場景:
👨💻 AI 開發助手
🧑💼 AI 商業助理
🤖 AI Agent 系統
🧭 未來趨勢:AI 記憶戰爭開始
MemPalace 只是第一步。
未來會看到:
- Memory OS(記憶作業系統)
- AI Personal Brain(個人 AI 大腦)
- Persistent Agent(永續 AI)
👉 AI 的競爭,不再只是模型大小,而是「誰記得更多」。
🏁 總結
MemPalace 的價值不只是技術,而是觀念:
👉 AI 不應該忘記你
透過:
蜜拉喬娃維琪不只是跨界成功,而是直接切入 AI 最核心問題之一。
參考資訊
by Rain Chu | 4 月 7, 2026 | Agent, AI, OpenClaw
在 2026 年,AI 不再只是聊天工具,而是「會幫你做事的代理人(AI Agent)」。
而現在,你可以擁有一個——
👉 完全屬於你自己的 AI 智能體(OpenClaw)
不再依賴 SaaS、不再擔心資料外流
👉 私有化 + 24 小時在線 + 可自動執行任務
更關鍵的是:
👉 用 Hostinger,一鍵部署只要約 $7/月
🤖 什麼是 OpenClaw?
OpenClaw 是一款開源 AI Agent(AI 智能代理)平台,可以讓 AI 不只是聊天,而是「幫你做事情」。
它可以:
- 自動回覆訊息(Telegram / WhatsApp / Slack)
- 幫你整理資料、寫報告
- 控制瀏覽器執行任務
- 呼叫 API、自動化流程
- 長期記憶與上下文管理
👉 本質上,它是:
「你的私人 AI 員工」
而且是——
🟢 24 小時不休息
🟢 永遠在線
🟢 完全由你掌控
⚡ 為什麼 OpenClaw 爆紅?
OpenClaw 在 2026 年爆紅的原因只有一個:
👉 它讓 AI 從「聊天」進化成「做事」
傳統 AI(ChatGPT):
OpenClaw:
例如:
- 幫你每天抓股價 → 傳 Telegram
- 自動回覆客戶訊息
- 幫你爬資料 → 整理成報告
- 自動操作網站(RPA + AI)
👉 這就是「AI Agent 時代」
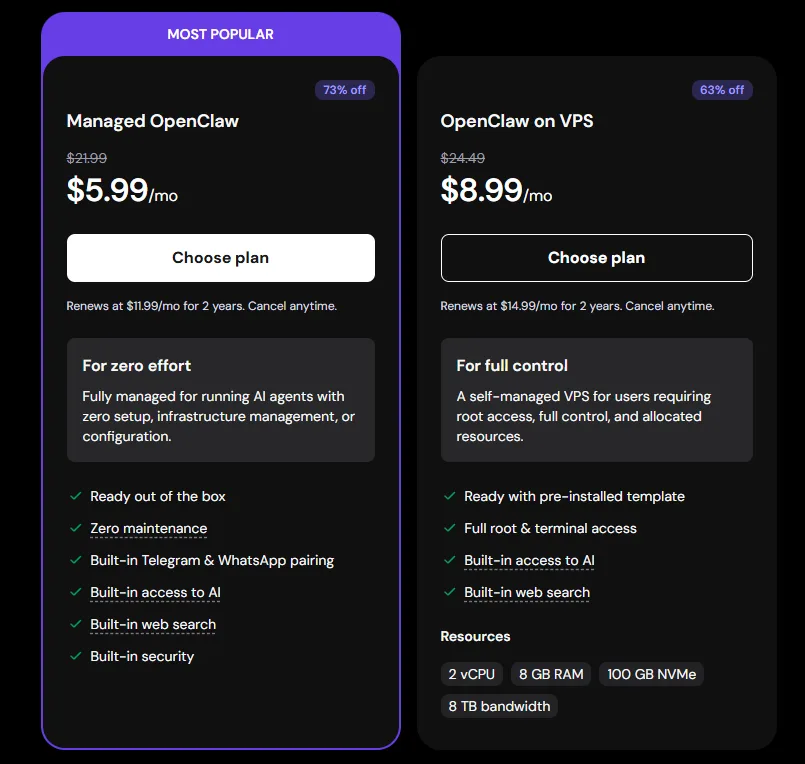
☁️ 為什麼用 Hostinger 部署 OpenClaw?
如果你自己部署 OpenClaw:
❌ 要裝 Docker
❌ 要設定環境
❌ 要處理網路與安全
但用 Hostinger:
👉 全部幫你做好了
✅ Hostinger + OpenClaw 優勢
- 一鍵部署(不用 CLI)
- 預先配置 AI 環境
- 全球 VPS(穩定 24/7)
- 免費網域 + SSL
- 防火牆 + 備份
👉 官方直接提供 OpenClaw 模板
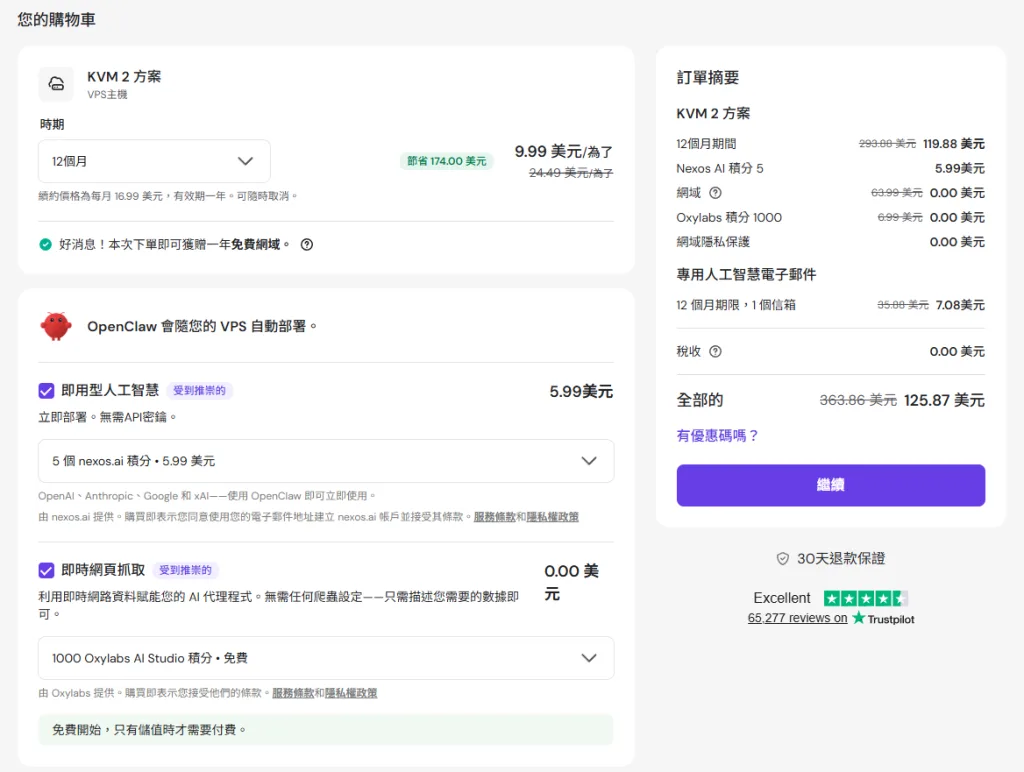
💰 成本有多低?
👉 最低只要約 $7/月
實際成本結構:
| 項目 | 價格 |
|---|
| VPS 主機 | 約 $5~$10/月 |
| AI API(選擇性) | 視使用量 |
| 總成本 | 約 $7/月起 |
👉 比你請一個員工便宜 1000 倍 😅
甚至有資料指出:
👉 VPS 部署 OpenClaw 最低約 $5/月即可開始
🚀 60 秒部署流程(Hostinger)
超簡單流程:
Step 1️⃣
購買 VPS(選 KVM 2 即可)
Step 2️⃣
選擇 OpenClaw 模板
Step 3️⃣
點「Deploy」
Step 4️⃣
登入 Web UI
Step 5️⃣
接上 AI(OpenAI / Claude / Ollama)
👉 完成 🎉
🔐 私有 AI 的最大價值
為什麼大家開始瘋 OpenClaw?
1️⃣ 資料完全私有
不像 SaaS AI:
2️⃣ 完全控制
3️⃣ 可自動化一切
👉 這才是真正的「AI Agent」
⚠️ 但一定要注意
OpenClaw 很強,但也有風險:
- AI 可以執行指令(高權限)
- 插件可能有安全問題
- Token 洩漏 = 全部被控
👉 建議:
- 使用 VPS(不要跑在本機)
- 分離權限
- 使用防火牆 / Cloudflare
🧠 誰適合用?
非常適合你這類型:
- DevOps / 架構師
- WordPress / SaaS 維運
- 想做 AI Agent 商業化
- 想打造自動化系統
甚至可以做:
👉 「AI SaaS 創業」
🔮 未來趨勢(很重要)
未來會變成:
- 每個人都有一個 AI Agent
- 每家公司都有 AI 自動化流程
- SaaS → AI Agent 化
👉 OpenClaw 就是這個入口
相關資訊
官方網站
https://www.hostinger.com/openclaw
近期留言