by Rain Chu 3 月 12, 2026 | Docker , google , wordpress
在管理多個 WordPress 專案時,傳統 VM 加架構往往面臨擴展性與維護成本的挑戰。透過 Google Cloud Run (Serverless) 、Cloud SQL (代管資料庫) 與 Cloud Storage (雲端儲存) 的組合,我們可以建立一個自動縮放、安全且高效率的網站環境。
一、 架構預覽
計算節點 :Google Cloud Run (Docker 容器化運行)。資料庫 :Google Cloud SQL (MySQL 8.0)。靜態檔案 :Google Cloud Storage (GCS)。流量分配 :Google Cloud Load Balancing (HTTPS 負載平衡器)。
二、 準備 Docker 鏡像與環境排除
在打包之前,請務必設定 .dockerignore 以優化鏡像體積並保護敏感資訊
my-wp-site/
├── Dockerfile # 自動化打包腳本
├── wp-config.php # 修改為讀取環境變數的版本
├── .dockerignore # 排除不需要打包的檔案 (如 .git, local backups)
└── wp-content/
├── plugins/ # 放置您自定義的外掛
└── themes/ # 放置您自定義的主題 建立 標準化 Dockerfile 範本
# 使用官方 PHP-Apache 映像檔,穩定且相容性高
FROM wordpress:php8.2-apache
# 1. 設定環境變數 (Cloud Run 預設監聽 8080,但官方 WP 鏡像預設是 80)
# 這裡我們讓 Apache 監聽 Cloud Run 指定的 PORT
RUN sed -i 's/Listen 80/Listen ${PORT}/g' /etc/apache2/ports.conf
RUN sed -i 's/:80/:${PORT}/g' /etc/apache2/sites-available/000-default.conf
# 2. 安裝必要的系統套件 (如有需要自訂 PHP 擴展可在這加)
RUN apt-get update && apt-get install -y \
libpng-dev \
libjpeg-dev \
&& docker-php-ext-configure gd --with-jpeg \
&& docker-php-ext-install gd
# 3. 複製現有的自定義檔案進入容器
# 建議只複製 plugins 和 themes,核心檔案由官方鏡像提供
COPY ./wp-content/plugins/ /var/www/html/wp-content/plugins/
COPY ./wp-content/themes/ /var/www/html/wp-content/themes/
COPY ./wp-config.php /var/www/html/wp-config.php
# 4. 設定正確的檔案權限 (對 WordPress 運行至關重要)
RUN chown -R www-data:www-data /var/www/html
# 5. 設定預設環境變數 (可在部署時被 gcloud 指令覆蓋)
ENV PORT=8080
ENV DB_HOST=127.0.0.1
ENV DB_USER=root
ENV DB_PASSWORD=password
# 暴露埠號
EXPOSE 8080 1. 建立 .dockerignore
Plaintext
.git
.gitignore
.dockerignore
Dockerfile
*.sql
*.zip
.vscode/
wp-config-sample.php
2. 打包與推送鏡像
PowerShell
# 編譯鏡像
docker build -t asia-east1-docker.pkg.dev/[PROJECT_ID]/wp-repo/[docker_name]:latest .
# 推送到 Artifact Registry
docker push asia-east1-docker.pkg.dev/[PROJECT_ID]/wp-repo/[docker_name]:latest
三、 資料庫遷移與設定
1. 匯入 SQL 腳本
將 .sql 檔案上傳至 Google Cloud Storage (GCS) 後執行匯入
注意 :請確保 SQL 檔案中不含 CREATE DATABASE 或 USE 語句,以免匯入失敗或指向錯誤的資料庫。
PowerShell
gcloud sql import sql [INSTANCE_NAME] gs://[BUCKET_NAME]/[docker_name].sql --database=[docker_name]_db
2. 設定 wp-config.php 智慧判斷
為了同時支援本地開發與雲端環境,建議在 wp-config.php 加入連線判斷邏輯
PHP
// 偵測是否在 Cloud Run 環境 (透過 Unix Socket 連線)
if (getenv('INSTANCE_CONNECTION_NAME')) {
define( 'DB_HOST', ':/cloudsql/' . getenv('INSTANCE_CONNECTION_NAME') );
} else {
define( 'DB_HOST', getenv('DB_HOST') ?: '127.0.0.1' );
}
// 負載平衡器 HTTPS 辨識
if (isset($_SERVER['HTTP_X_FORWARDED_PROTO']) && $_SERVER['HTTP_X_FORWARDED_PROTO'] === 'https') {
$_SERVER['HTTPS'] = 'on';
}
四、 部署至 Cloud Run
部署時需指定 Cloud SQL 連線名稱 ,這會自動建立加密隧道
PowerShell
gcloud run deploy [docker_name] `
--image asia-east1-docker.pkg.dev/[PROJECT_ID]/wp-repo/[docker_name]:latest `
--region asia-east1 `
--allow-unauthenticated `
--add-cloudsql-instances [PROJECT_ID]:asia-east1:[INSTANCE_NAME] `
--set-env-vars="INSTANCE_CONNECTION_NAME=[PROJECT_ID]:asia-east1:[INSTANCE_NAME],DB_NAME=[docker_name]_db,DB_USER=root,DB_PASSWORD=[PASSWORD]"
五、 設定負載平衡器 (GCLB) 與自訂網域
為了使用自有的網域(如 blog.rain.tips),建議使用 HTTPS 負載平衡器 。
建立 Serverless NEG :讓負載平衡器找到 Cloud Run 。設定前端 IP :保留一個靜態全域 IP。Google 管理憑證 :在前端設定中新增網域,Google 會自動處理 SSL 簽發與續期 。DNS 設定 :將您的網域 A 紀錄 指向負載平衡器的靜態 IP 。
六、 故障排除 (Troubleshooting)
Error establishing a database connection :
檢查 Cloud Run 服務帳戶是否擁有 「Cloud SQL Client」 角色 。
確認 DB_HOST 在雲端環境是否正確指向 :/cloudsql/... 。
503 Service Unavailable :
確認 Cloud Run 服務已設定為 「允許未經驗證的叫用」 。
檢查負載平衡器的憑證是否已變為綠色的 Active 狀態 。
IPv6 連線問題 :
若使用 Nginx 反向代理遇到 Network is unreachable,請強制 Nginx 優先使用 IPv4 或修改系統 /etc/hosts 。
參考資料
by Rain Chu 3 月 5, 2026 | MIS , Nvidia
在使用 nvidia spark 或 NVIDIA Jetson 類型的 AI 開發平台時,很多開發者會希望能夠遠端操作設備,而不是每次都連接螢幕、鍵盤與滑鼠。這時候 VNC(Virtual Network Computing) 就是一個非常方便的遠端桌面解決方案。
透過 vino VNC Server 與 RealVNC Viewer ,你可以在 Windows、macOS 或 Linux 上遠端連線到 NVIDIA Spark 的桌面環境,像是直接操作本機一樣。VNC 可以透過網路傳輸桌面畫面與輸入操作,因此非常適合 AI 開發、邊緣設備管理與遠端維護。
本文將介紹如何在 nvidia spark / Ubuntu 系統 中啟用 VNC Server(vino) ,並透過 RealVNC Viewer 進行遠端連線。
為什麼 NVIDIA Spark 建議使用 VNC
在 AI 或嵌入式開發場景中,遠端桌面有幾個重要用途:
遠端查看 GPU 程式的 GUI
遠端操作桌面應用程式
headless(無螢幕)設備管理
在不同電腦之間共享桌面
VNC 允許使用者透過網路存取 Linux 圖形桌面,而不需要實際連接顯示器。
NVIDIA Spark 啟用 VNC(vino)教學
以下步驟適用於 Ubuntu / GNOME 環境的 nvidia spark 。
1 安裝 VNC Server(vino)
首先在 NVIDIA Spark 中安裝 vino :
sudo apt update
vino 是 GNOME 桌面內建的 VNC Server,常用於 Ubuntu 遠端桌面。
2 啟用 VNC Server 自動啟動
建立 symbolic link,讓 vino 在登入後自動啟動:
cd /usr/lib/systemd/user/graphical-session.target.wants
這樣每次登入桌面時,VNC 服務就會自動啟動。
3 設定 VNC Server
關閉安全提示與加密:
gsettings set org.gnome.Vino prompt-enabled false
這些設定可以避免某些 VNC Viewer 無法連線的問題。
4 設定 VNC 密碼
設定遠端登入密碼:
gsettings set org.gnome.Vino authentication-methods "['vnc']"
請將 yourpassword 替換為自己的密碼。
5 重新啟動系統
sudo reboot
重新啟動後,VNC Server 設定就會生效。
使用 RealVNC Viewer 連線 NVIDIA Spark
在另一台電腦安裝 RealVNC Viewer 。
接著:
查詢 NVIDIA Spark IP
ifconfig
或
ip a
開啟 RealVNC Viewer
輸入 IP 地址
例如:
192.168.1.50
輸入剛剛設定的 VNC 密碼
即可成功遠端操作 NVIDIA Spark 桌面。
VNC 常見問題
1 VNC 無法連線
可能原因:
vino 沒有啟動
GNOME 沒有登入
防火牆阻擋
確認服務:
ps aux | grep vino
2 VNC 黑畫面
可能是:
可設定 自動登入(Auto Login) 解決。
VNC、RealVNC、vino 的差異
工具 功能 vino Linux GNOME VNC Server VNC 遠端桌面協定 RealVNC Viewer 常用 VNC 客戶端
通常搭配方式:
vino server + RealVNC viewer
結論
透過 VNC + vino + RealVNC ,可以快速讓 nvidia spark 具備遠端桌面能力,對於 AI 開發、遠端管理或 headless 系統來說非常方便。
只需要簡單幾個步驟:
安裝 vino
啟用 VNC server
設定密碼
使用 RealVNC 連線
就能輕鬆遠端控制 NVIDIA Spark。
相關資料
https://developer.nvidia.com/embedded/learn/tutorials/vnc-setup
by Rain Chu 8 月 8, 2025 | Agent , AI , Javascript , Python , RPA , 瀏覽器 , 程式開發
想用 AI 控制網頁自動化,但程式碼又要精準可靠,同時享受自然語言,高效又方便?那你絕不能錯過由 Browserbase 團隊推出的 Stagehand —— 這款專為 AI 時代設計的瀏覽器自動化框架,不僅支援 TypeScript 與 Python、可本地或雲端部署,還比 Browser‑Use 更快、更耐變動!
Stagehand 兼具控制力與智慧的 AI 瀏覽器自動化框架
Stagehand 是以 Playwright 為核心構建的 AI-native 自動化工具,它加入了 LLM 判斷能力,結合程式精準控制與自然語言指令,令自動化腳本更穩定、更智慧也更高效
自然語言 + 程式碼混合操作 :你可以用程式寫明確動作,也能用「act(‘點擊第一個 Stagehand 元件’)」這樣類人語法完成UI操作 。接口完整,支援察看、執行與資料萃取 :核心三大命令 act、observe、extract,讓操作更透明、更可控 容錯與自恢復能力 :UI 略有變動也不怕,Stagehand 的 observe + 快取策略讓腳本更具彈性完美整合 Playwright :所有 Playwright 腳本都能無縫升級 Stagehand,省心又高效
核心玩法!TypeScript/JavaScript 快速上手範例
// Use Playwright functions on the page object
const page = stagehand.page;
await page.goto("https://github.com/browserbase");
// Use act() to execute individual actions
await page.act("click on the stagehand repo");
// Use Computer Use agents for larger actions
const agent = stagehand.agent({
provider: "openai",
model: "computer-use-preview",
});
await agent.execute("Get to the latest PR");
// Use extract() to read data from the page
const { author, title } = await page.extract({
instruction: "extract the author and title of the PR",
schema: z.object({
author: z.string().describe("The username of the PR author"),
title: z.string().describe("The title of the PR"),
}),
}); 這段程式完整示範了初始化、導航、AI 驅動操作到資料萃取的流程,不僅省事,也大幅提升開發效率。
Stagehand 與 Browser-Use 比較
功能面 Stagehand(此文主角) Browser-Use 控制精準度 Token 級動作掌控 + 自然語言指令混合 攻擊角度偏自然語言,程式控制較弱 容錯能力 observe + 快取策略,對 DOM 變化更耐受缺少自恢復機制 雲端支援 原生整合 Browserbase,輕鬆雲端部署 需額外集成,無預設雲平台支援 語言支援 TypeScript / Python 主要依賴 Python AI 整合 天生結合 LLM,支援複雜任務拆解 依賴外部 LLM,不那麼一體化
只要先學四個指令,快速上手
指定去那一個網頁
goto():
# 初始化
page = stagehand.page
# 指定去那一個頁面
await page.goto("https://rain.tips/") 使用自然語言操作
act():
await page.act("點選確定按鈕"); 抓取數據資料
extract():
post = await page.extract("取得標題") 預覽功能
observe():
links = await page.observe("找到頁面中的所有連結") 實戰快速導覽
安裝
# 用 pip
pip install stagehand python-dotenv
# 安裝playwright
python -m playwright install
# 裝 chromium 瀏覽器
python -m playwright install chromium 建立 .env
export BROWSERBASE_API_KEY="your_browserbase_api_key"
export BROWSERBASE_PROJECT_ID="your_browserbase_project_id"
export MODEL_API_KEY="your_model_api_key" # OpenAI, Anthropic, etc. 建立程式碼 main.py
import asyncio
import os
from stagehand import Stagehand, StagehandConfig
from dotenv import load_dotenv
load_dotenv()
async def main():
config = StagehandConfig(
env="BROWSERBASE",
api_key=os.getenv("BROWSERBASE_API_KEY"),
project_id=os.getenv("BROWSERBASE_PROJECT_ID"),
model_name="gpt-4o",
model_api_key=os.getenv("MODEL_API_KEY")
)
stagehand = Stagehand(config)
try:
await stagehand.init()
page = stagehand.page
await page.goto("https://docs.stagehand.dev/")
await page.act("click the quickstart link")
result = await page.extract("extract the main heading of the page")
print(f"Extracted: {result}")
finally:
await stagehand.close()
if __name__ == "__main__":
asyncio.run(main()) 驗證與測試
若要用本地端的瀏覽器的話,可以改成下面的程式碼
import asyncio
import os
from dotenv import load_dotenv
from stagehand import StagehandConfig, Stagehand
load_dotenv()
async def main():
# 检查API密钥是否设置
api_key = os.getenv("OPENAI_API_KEY")
config = StagehandConfig(
env="LOCAL", # 本地运行
# AI模型配置 - 使用环境变量
model_name="gpt-4o-mini", # 使用更便宜的模型
model_api_key=api_key, # 从环境变量读取
# 本地运行配置
headless=False, # 显示浏览器窗口
verbose=3, # 详细日志
debug_dom=True, # DOM调试
)
# 使用配置创建Stagehand实例
stagehand = Stagehand(config)
# 初始化Stagehand(启动浏览器会话)
await stagehand.init()
# 获取页面对象,用于后续的页面操作
page = stagehand.page
await page.goto("https://rain.tips/")
# # 使用observe()取得文章的連結
blog_links = await page.observe("取得文章中的所有連結)
print(f"✅ Page link: {blog_links}")
await page.act(blog_links[0])
data_post_1 = await page.extract("取得文章的標題和內文")
print(f"✅ 文章資訊如下: {data_post_1}")
if __name__ == "__main__":
asyncio.run(main())
總結:為什麼 Stagehand 是下一代自動化框架?
語言直覺更自然,人類可理解 對 UI 變化具彈性、不易失效 結合 LLM,自動拆解任務,效率提升數倍 支援本地與雲端,開發與生產環境都得心應手
Stagehand 正重新定義瀏覽器自動化,不再只是死板指令,而是一場「程式控+AI 智能」的完美結合,無論對開發者或 AI 自動化愛好者,都是一大利器。快一起駕馭它,打造更強、更智慧的自動化流程!
參考資料
BrowserBase
GitHub Stagehand
Demo
開發說明文件
https://www.aivi.fyi/aiagents/introduce-stagehand
by Rain Chu 1 月 3, 2025 | MIS
Wireshark 是一款功能強大的網絡協議分析工具,可以幫助我們深入了解網絡流量,在日常使用中,我們有時需要檢查 HTTPS 流量,這些流量通常是加密的,通過配置 Wireshark,我們可以抓取並解碼 SSL/TLS 的加密資訊。
步驟 1:下載並安裝 Wireshark 首先,從 Wireshark 官方網站 下載適合您系統的安裝包,並完成安裝。安裝過程中,建議選擇安裝 WinPcap 或 Npcap,這是用於抓取網絡數據包的必要工具。
步驟 2:在 Windows 中設置用戶變量 要讓瀏覽器記錄 SSL/TLS 的密鑰,我們需要設置環境變量。
新增用戶變量 :
打開「系統屬性」>「高級系統設置」>「環境變量」。
在「用戶變量」區域中,點擊「新增」。
設置變量名稱與變量值 :
變量名 :SSLKEYLOGFILE變量值 :C:\logs
點擊「確定」保存變量。
步驟 3:使用 Chrome 訪問 HTTPS 網頁
打開 Google Chrome 瀏覽器。
瀏覽任意 HTTPS 網頁(例如 https://example.com)。
在剛才設置的 C:\logs 路徑下,會生成一個名為 sslkeylog.log 的文件。
這個設置的作用是讓支持 SSLKEYLOGFILE 的應用程序(例如 Chrome)記錄密鑰到指定文件中。
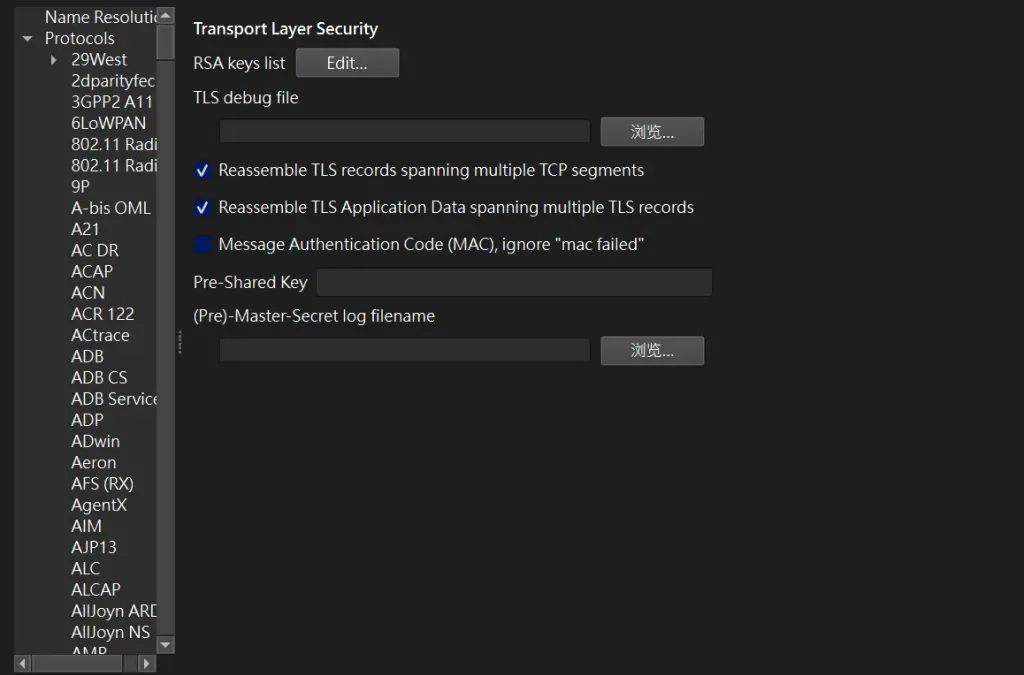
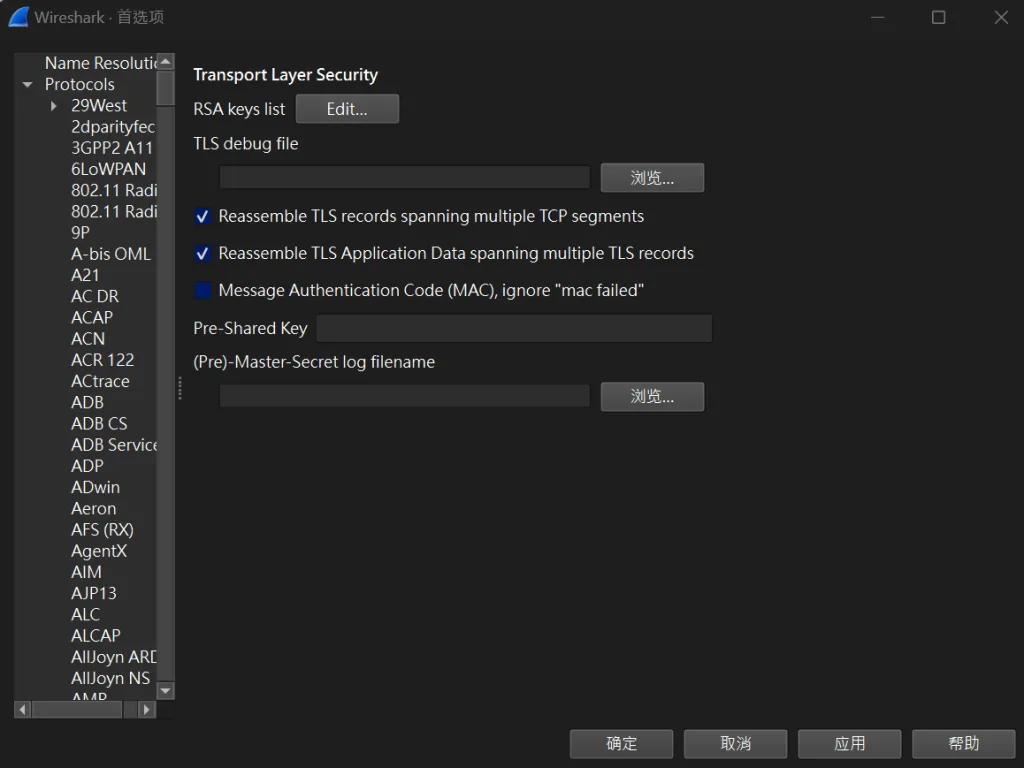
步驟 4:配置 Wireshark 解碼 SSL 流量 接下來,我們需要將生成的密鑰文件導入 Wireshark,以便解碼 HTTPS 流量。
打開 Wireshark。
點擊選單中的「編輯 」>「首選項 」。
在彈出的「首選項」窗口中:
展開左側的「Protocols 」。
找到並選擇「TLS 」協議。
在右側的「(Pre)-Master-Secret log filename 」欄位中,填入生成的 sslkeylog.log 文件的完整路徑,例如:
步驟 5:開始抓取 HTTPS 流量
在 Wireshark 中選擇網絡介面(例如 Wi-Fi 或有線網絡)。
點擊「開始捕獲 」按鈕(或快捷鍵 Ctrl+E)。
打開瀏覽器並訪問任意 HTTPS 網頁。
步驟 6:檢查解碼的內容
在抓取的數據包中,選擇任意 Client Hello 或 Server Hello 消息。
Wireshark 會根據 sslkeylog.log 自動解碼加密的數據流,您可以在「解碼」區域中看到未加密的數據內容。
by rainchu 11 月 14, 2024 | RPA , 管理 , 行銷
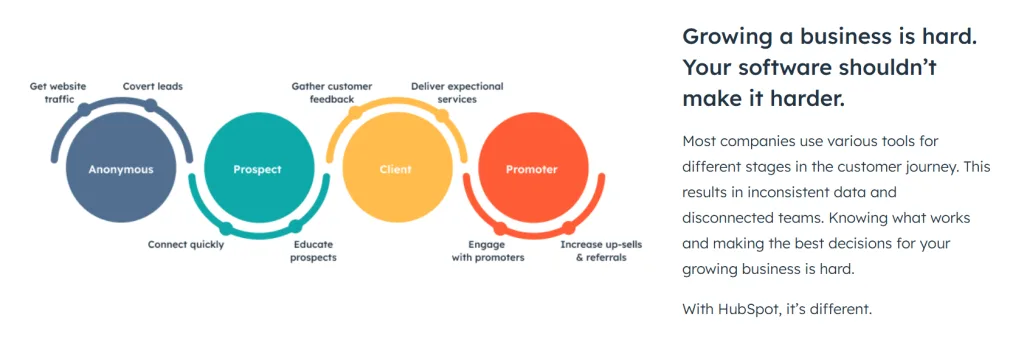
HubSpot 是一款功能強大的整合式行銷、銷售和客戶服務軟體,為企業提供了從行銷自動化到客戶關係管理 (CRM) 的多種解決方案。成立於 2006 年,HubSpot 以「吸引力行銷」(Inbound Marketing) 理念為核心,幫助企業透過內容行銷、社交媒體互動、以及顧客關係管理等工具來吸引、轉換和滿足客戶需求。以下是 HubSpot 的主要功能及優勢介紹:
1. 行銷自動化
HubSpot 的行銷工具涵蓋電子郵件行銷、社交媒體管理、SEO、廣告管理和內容創建。透過其強大的行銷自動化功能,企業可以針對不同的潛在客戶設計自動化工作流程,提供個性化的電子郵件、行銷信息和跟進活動,幫助提高行銷效率並增加潛在客戶的轉化率。
2. CRM (客戶關係管理)
HubSpot 的 CRM 是其核心功能之一,它能夠免費使用,且提供了強大的客戶資料管理和互動追蹤功能。用戶可以輕鬆管理客戶資料、跟蹤客戶行為,並記錄所有的溝通互動,讓業務團隊能夠更深入了解客戶需求,提供更好的服務。
3. 銷售工具
HubSpot 提供多種銷售支援工具,像是銷售管道管理、線索打分、預測分析和報表工具等,幫助業務團隊自動化重複性的任務,專注於建立與潛在客戶的關係。透過 HubSpot 的銷售功能,業務人員可以追蹤線索的進度、提醒後續行動,並利用個性化的銷售策略來提升銷售效率。
4. 客戶服務管理
HubSpot 的客戶服務工具包括客戶支援票務系統、聊天機器人、知識庫、客戶回饋和調查功能,讓企業可以提供一致且高效的客戶支援服務。企業可以追蹤每位客戶的服務歷史紀錄,確保所有團隊成員都能夠準確回應客戶的需求。
5. 數據分析和報表
HubSpot 的報表和分析工具能夠幫助企業衡量行銷、銷售和服務績效。企業可以輕鬆生成多種報表來評估行銷活動效果、銷售業績以及客戶滿意度,讓決策團隊能夠依據數據做出更有效的商業策略。
6. 與其他應用程式的整合
HubSpot 提供眾多第三方應用程式的整合,包括 Salesforce、Shopify、Slack、Google Workspace 等。透過這些整合,企業可以將所有業務流程集中在 HubSpot 中,減少切換應用的時間,並提高工作效率。
延伸閱讀
by Rain Chu 11 月 5, 2024 | MIS
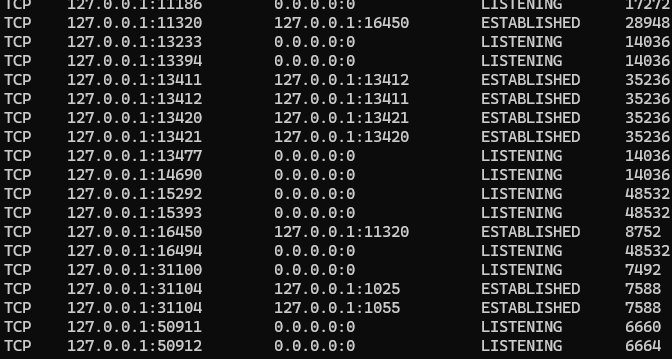
使用 docker 時候,常常遇到被占用的 port 要處理,這邊記錄下正確的處理方法
找到占用port的程式
netstat -ano | findstr 8080 會得到下面的輸出,最後面一個是 PID
查詢程式資訊
刪除占用的程式行程
舉例來說,我要刪除佔用了 port 50912 的程式,由上圖知道他的 PID 是 6664,那就輸入以下指令即可

近期留言