by Rain Chu 3 月 18, 2025 | AI , 影片製作
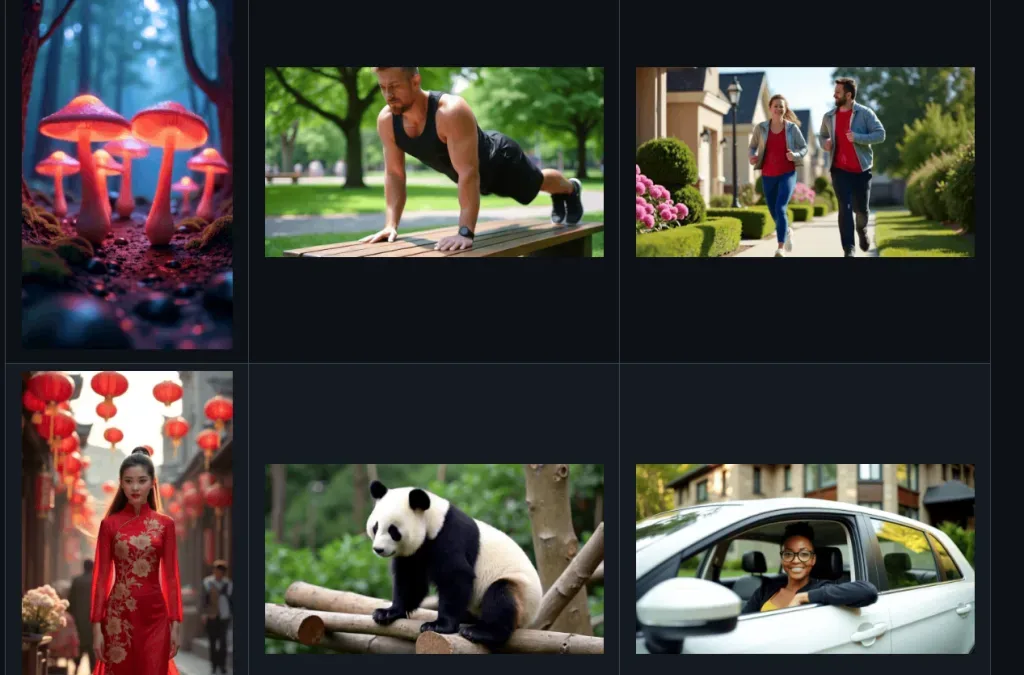
Open-Sora 這個 GitHub 專案,提供類似於 OpenAI 的 Sora 的影片生成模型,讓更多人能夠高效地製作高品質影片,無需再等待 Sora 的推出。
Open-Sora 的主要特色
1. 11B 參數模型
Open-Sora 採用了擁有 110 億參數的大型模型架構,這使其在影片生成的質量和細節上達到業界領先水平。與其他需要大量資源的模型相比,Open-Sora 以較低的成本實現了高品質的影片生成。
2. 基於 PyTorch 和 xFormers
該專案基於 PyTorch 框架開發,並結合了 xFormers 技術,這使得模型在計算效率和資源利用上有顯著提升。開發者可以利用這些技術,進行更高效的模型訓練和推理。
3. 支援本地運行
Open-Sora 支援在本地環境中運行,使用者可以在自己的設備上部署和運行模型,這不僅提高了資料的私密性,還減少了對外部伺服器的依賴。這對於需要處理敏感資料的使用者尤為重要。
如何開始使用 Open-Sora
獲取程式碼 :前往 Open-Sora 的 GitHub 儲存庫,克隆或下載最新的程式碼。安裝依賴項 :確保您的環境中已安裝 PyTorch,並根據專案需求安裝其他必要的 Python 套件。配置環境 :根據官方文件,配置您的運行環境,包括設定模型參數和路徑。運行模型 :按照指導,運行模型並生成影片。您可以根據需要調整輸入參數,以獲得不同的影片效果。
by Rain Chu 3 月 13, 2025 | AI , Chat , Ollama , 模型
超大型語言模型(LLM)成為科技界矚目的焦點,以前這類模型通常需要極高的硬體門檻,要很多的 GPU 才能達成(需要好幾百萬),難以在本地設備上流暢運行。然而,現在配備 512GB 超大記憶體 的 Mac Studio,約33萬台幣,就能輕鬆駕馭滿血版 DeepSeek R1,讓個人或企業用戶都能輕鬆享受超大型語言模型帶來的豐富應用價值!
為何 512GB 就足夠跑 DeepSeek R1?
DeepSeek R1 是一款擁有超過 6710 億參數 的超級大型語言模型,理論上需超過 400GB 以上記憶體空間才能順暢載入。然而,DeepSeek R1 採用了特殊的 Mixture of Experts (MoE) 架構,儘管整體模型規模龐大,但實際上單次推理只會激活約 370 億參數,大幅減少記憶體的實際使用需求,讓 512GB 記憶體的 Mac Studio 就能輕鬆駕馭。
關鍵技巧:調整 VRAM 配置,釋放更大的 GPU 資源
Mac Studio 使用的是統一記憶體架構(Unified Memory),系統自動分配 GPU 使用的 VRAM 空間。預設情況下,VRAM是有限制的,不足以負荷 DeepSeek R1 這樣龐大的語言模型,但使用者可以透過調整系統參數,自由設定 GPU 的 VRAM 配置,以達到最大效能:
以下是關鍵指令:
sudo sysctl iogpu.wired_limit_mb=448000 透過這項設定,系統的 GPU VRAM 即可輕鬆擴展到 448GB ,滿足 DeepSeek R1 等超大型模型的嚴苛需求,真正發揮 512GB 記憶體 Mac Studio 的硬體潛力。
⚠️ 貼心提醒:
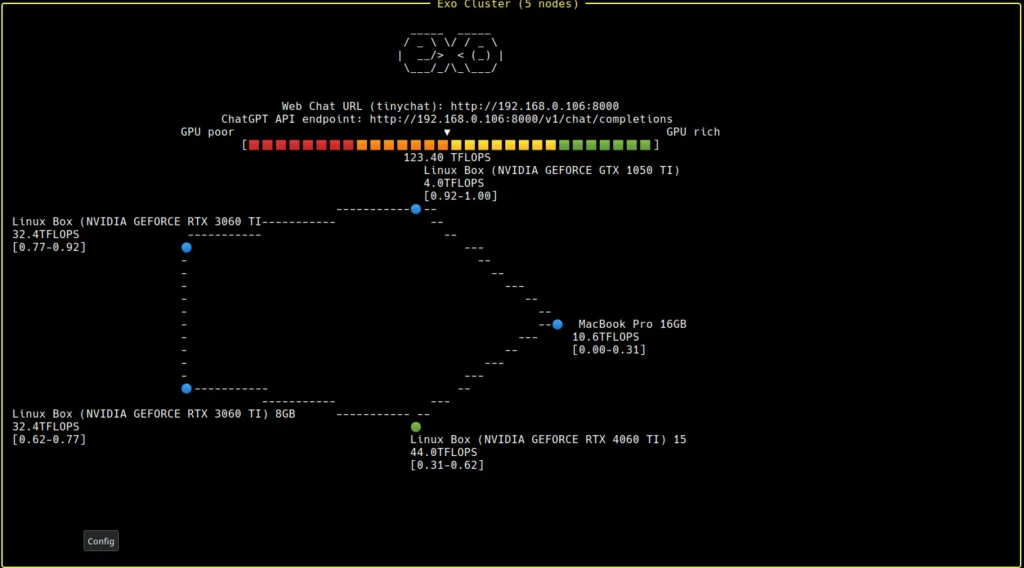
EXO 工具:連接多台 Mac,建立強大的分散式計算環境
如果你需要更強大的算力,還可以透過開源的 EXO 專案 ,將多台 Mac 電腦串聯起來,組成超強大的本地計算集群,以協同運行 DeepSeek R1 這類超大型語言模型。
透過 EXO,你可以:
將多台 Mac Studio 連結成計算網絡。
有效分散模型推理負載,提升整體效能。
進一步降低單機的運算負擔,確保持續穩定運作。
這個方法尤其適合專業研究團隊、企業內部部署,甚至是有進階 AI 運算需求的開發者。
參考資料
https://zenn.dev/robustonian/articles/apple_silicon_vram
by Rain Chu 5 月 13, 2024 | AI , Chat , Linux , NodeJS , React , Ubuntu , ViteJS , 程式
AnythingLLM是一款全功能的應用程序,支持使用商業或開源的大語言模型(LLM)和向量數據庫建構私有ChatGPT。用戶可以在本地或遠端運行該系統,並利用已有文檔進行智能對話。此應用將文檔分類至稱為工作區的容器中,確保不同工作區間的資料隔離,保持清晰的上下文管理。
特點:多用戶支持、權限管理、內置智能代理(可執行網頁瀏覽、代碼運行等功能)、可嵌入到網站的聊天窗口、多種文檔格式支持、向量數據庫的簡易管理界面、聊天和查詢兩種對話模式、引用文檔內容的展示,以及完善的API支持客戶端定制整合。此外,該系統支持100%雲端部署,Docker部署,且在處理超大文檔時效率高,成本低。
VIDEO
注意,以下要用 linux 平台安裝,windows 用戶可以用 WSL,推薦用 Ubuntu OS
在自己的 home 目錄下,到 GitHub 中下載原始碼
git clone https://github.com/Mintplex-Labs/anything-llm.git 利用 yarn 作設定資源
cd anything-llm
yarn setup 把環境變數建立起來,後端主機是 NodeJS express
cp server/.env.example server/.env
nano server/.env 密文需要最少12位的字元,檔案的存放路徑也記得改成自己的
JWT_SECRET="my-random-string-for-seeding"
STORAGE_DIR="/your/absolute/path/to/server/storage" 前端的環境變數,先把/api打開即可
# VITE_API_BASE='http://localhost:3001/api' # Use this URL when developing locally
# VITE_API_BASE="https://$CODESPACE_NAME-3001.$GITHUB_CODESPACES_PORT_FORWARDING_DOMAIN/api" # for Github Codespaces
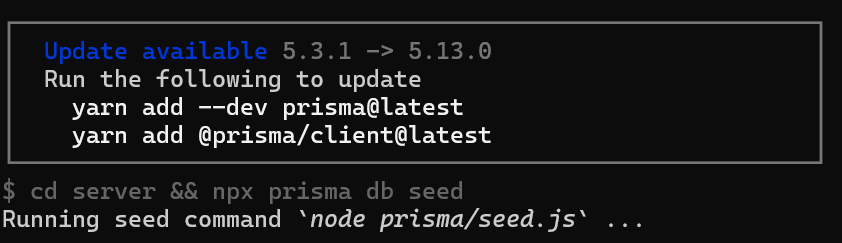
VITE_API_BASE='/api' # Use this URL deploying on non-localhost address OR in docker. 如果你在設定的時候,遇到更新請求,可以跟我著我下面的方法作
把 prisma 更新好
yarn add --dev prisma@latest
yarn add @prisma/client@latest 前端的程式碼
先編譯前端程式碼,前端是由 viteJS + React
cd frontend && yarn build 將編譯好的資料放到 server 的目錄下
cp -R frontend/dist/* server/public/ 選項,如果需要用到本地端的 LLM 模型,就把 llama-cpp 下載下來
cd server && npx --no node-llama-cpp download 把資料庫建立好
cd server && npx prisma generate --schema=./prisma/schema.prisma
cd server && npx prisma migrate deploy --schema=./prisma/schema.prisma Server端是用來處理 api 以及進行向量資料庫的管理以及跟 LLM 交互
Collector 是一個 NodeJS express server,用來作UI處理和解析文檔
cd server && NODE_ENV=production node index.js &
cd collector && NODE_ENV=production node index.js & 更新的指令碼
現在 anything llm 更新速度超快,把這一段指令碼複製起來,方便未來作更新的動作
#!/bin/bash
cd $HOME/anything-llm &&\
git checkout . &&\
git pull origin master &&\
echo "HEAD pulled to commit $(git log -1 --pretty=format:"%h" | tail -n 1)"
echo "Freezing current ENVs"
curl -I "http://localhost:3001/api/env-dump" | head -n 1|cut -d$' ' -f2
echo "Rebuilding Frontend"
cd $HOME/anything-llm/frontend && yarn && yarn build && cd $HOME/anything-llm
echo "Copying to Sever Public"
rm -rf server/public
cp -r frontend/dist server/public
echo "Killing node processes"
pkill node
echo "Installing collector dependencies"
cd $HOME/anything-llm/collector && yarn
echo "Installing server dependencies & running migrations"
cd $HOME/anything-llm/server && yarn
cd $HOME/anything-llm/server && npx prisma migrate deploy --schema=./prisma/schema.prisma
cd $HOME/anything-llm/server && npx prisma generate
echo "Booting up services."
truncate -s 0 /logs/server.log # Or any other log file location.
truncate -s 0 /logs/collector.log
cd $HOME/anything-llm/server
(NODE_ENV=production node index.js) &> /logs/server.log &
cd $HOME/anything-llm/collector
(NODE_ENV=production node index.js) &> /logs/collector.log &
近期留言