Ideogram 4 實作教學:在 ComfyUI 本機部署最強開源 AI 繪圖模型
2026 年最受矚目的 AI 繪圖模型之一,莫過於 Ideogram 團隊正式釋出的:
這是 Ideogram 首次公開模型權重(Open Weight),也是目前開源陣營中,在:
- 文字生成(Text Rendering)
- 海報設計
- 品牌廣告
- 排版控制
- JSON 結構化提示詞
官方資料顯示,Ideogram 4 採用 9.3B 參數的單流 Diffusion Transformer(DiT)架構,並支援原生 2K 圖像生成。
本篇將帶你使用 ComfyUI,在本機部署 Ideogram 4。
系統需求
官方模型共有兩個版本:
| 版本 | 量化 |
|---|---|
| Ideogram 4 FP8 | 品質最佳 |
| Ideogram 4 NF4 | VRAM需求較低 |
目前 ComfyUI 官方整合版本主要使用:
- FP8
- NVFP4
其中 FP8 畫質最佳。
第一步:下載模型
ComfyUI 專用模型
官方:
原始模型:
第二步:放置模型檔案
依照官方說明建立目錄。
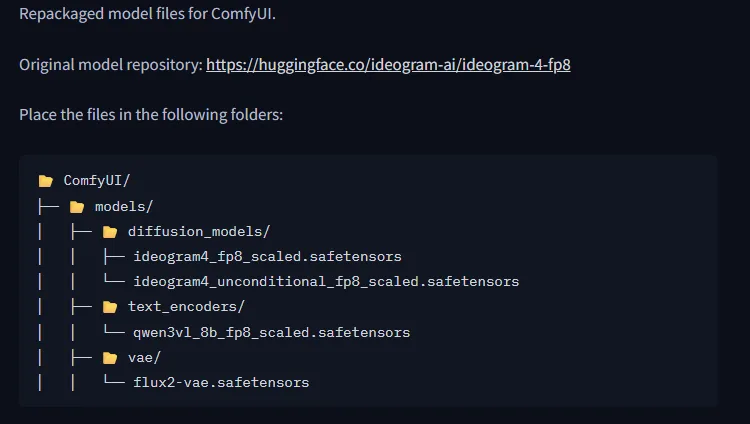
ComfyUI │ ├─ models │ ├─ diffusion_models │ │ ├─ ideogram4_fp8_scaled.safetensors │ │ └─ ideogram4_unconditional_fp8_scaled.safetensors │ │ │ ├─ text_encoders │ │ └─ qwen3vl_8b_fp8_scaled.safetensors │ │ │ └─ vae │ └─ flux2-vae.safetensors
第三步:了解每個模型用途
ideogram4_fp8_scaled
主模型
負責:
- 圖片生成
- 構圖
- 風格
- 排版
ideogram4_unconditional_fp8_scaled
CFG 引導模型
負責:
- 提升細節
- 強化 Prompt Follow
- 改善品質
官方建議兩個模型一起使用。若只載入主模型雖可運作,但畫質會下降。
qwen3vl_8b_fp8_scaled
文字編碼器
負責:
- Prompt 理解
- JSON 理解
- 空間推理
- 海報版面配置
flux2-vae
VAE 解碼器
負責將 Latent 轉換成圖片。
第四步:更新 ComfyUI
Ideogram 4 需要最新版本的 ComfyUI。
更新方式:
cd ComfyUI git pull
或:
update_comfyui.bat
官方於 Day-0 即已原生支援 Ideogram 4。
第五步:載入官方 Workflow
ComfyUI 官方已提供範例工作流。
建議直接從:
基礎工作流架構
Prompt
↓
Qwen3-VL Encoder
↓
Ideogram 4
↓
Sampler
↓
Flux VAE Decode
↓
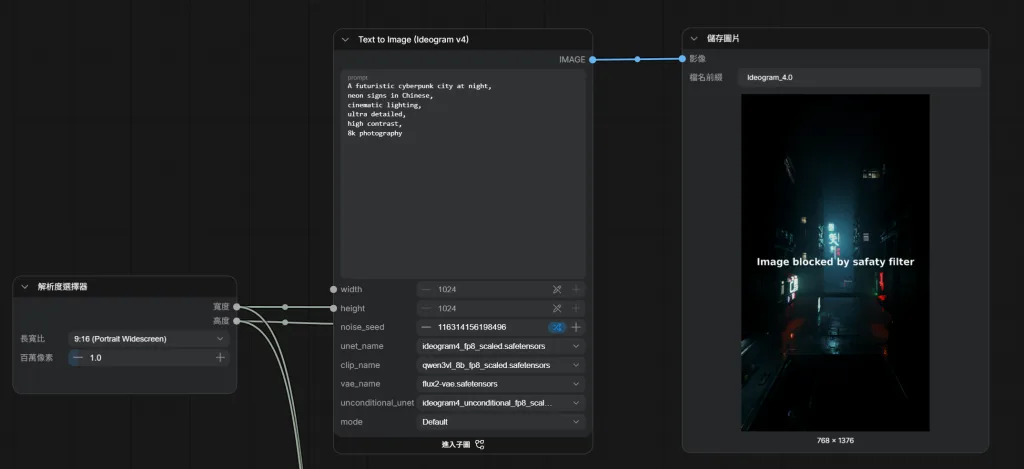
Save Image第六步:第一張圖片
測試 Prompt:
A futuristic cyberpunk city at night, neon signs in Chinese, cinematic lighting, ultra detailed, high contrast, 8k photography
生成尺寸:
1024 x 1024
推理模式:
DEFAULT
第七步:體驗 JSON Prompt
Ideogram 4 最大特色就是:
Structured JSON Prompt
官方模型訓練時即使用 JSON Caption。
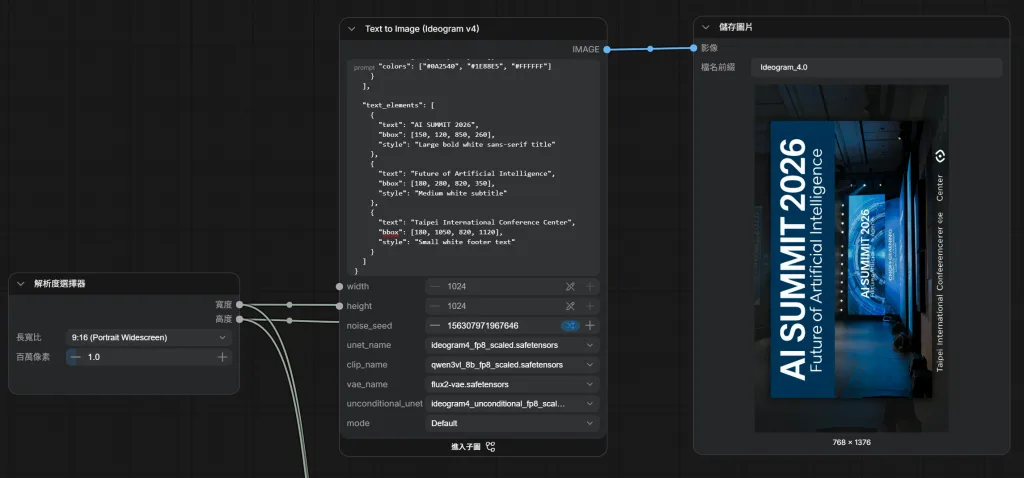
範例:海報設計
{
"scene_summary": "Professional technology conference poster",
"background": {
"description": "Modern convention center stage with blue ambient lighting, large LED screen, clean professional environment"
},
"style": {
"description": "Corporate marketing design, professional conference poster, clean typography, premium branding, modern layout"
},
"objects": [
{
"description": "Conference stage",
"bbox": [100, 150, 900, 850],
"colors": ["#0A2540", "#1E88E5", "#FFFFFF"]
}
],
"text_elements": [
{
"text": "AI SUMMIT 2026",
"bbox": [150, 120, 850, 260],
"style": "Large bold white sans-serif title"
},
{
"text": "Future of Artificial Intelligence",
"bbox": [180, 280, 820, 350],
"style": "Medium white subtitle"
},
{
"text": "Taipei International Conference Center",
"bbox": [180, 1050, 820, 1120],
"style": "Small white footer text"
}
]
}
Bounding Box 控制
可直接指定位置。
{
"text_elements":[
{
"text":"SALE 50%",
"bbox":[100,100,500,300]
}
]
}座標範圍:
0 ~ 1000
原點:
左上角
這是目前 FLUX 與 Stable Diffusion 所不具備的能力。
色彩盤控制
品牌設計超級好用。
{
"color_palette":[
"#FF6600",
"#FFFFFF",
"#000000"
]
}官方支援:
- 最多16色
- 單元素最多5色
與 FLUX 比較
FLUX 強項
- 寫實攝影
- 光影細節
- 人像品質
Ideogram 4 強項
- Logo
- 海報
- Banner
- 電商素材
- 排版設計
- 中文文字生成
若你是:
- 電商設計師
- 行銷公司
- 品牌設計
- 廣告公司
Ideogram 4 很可能比 FLUX 更適合。
結論
Ideogram 4 不只是另一個 AI 繪圖模型。
它最大的創新在於:
把 Prompt 從自然語言升級為結構化設計規格。
透過:
- Qwen3-VL
- Diffusion Transformer
- JSON Prompt
- Bounding Box
- Color Palette
使用者終於可以像操作 Figma 一樣控制 AI 生成內容。
對於需要:
- 海報設計
- 品牌素材
- Banner 製作
- AI Agent 自動產圖
的開發者來說,Ideogram 4 是目前最值得研究與部署的開源模型之一。
近期留言