Flux API – black-forest-labs(黑森林實驗室中的最強文生圖)
這是由黑森林實驗室所提供的 Flux API,, 原生有提供 Python, Node.js, Http 的範例,價格也很彈性,產圖的效果很好,可以不用自己組建自己的主機,就可以享有 FLUX 的繪圖能力,可以快速且容易的整合進 Dify 工作流程中
參考資料
https://replicate.com/black-forest-labs
這是由黑森林實驗室所提供的 Flux API,, 原生有提供 Python, Node.js, Http 的範例,價格也很彈性,產圖的效果很好,可以不用自己組建自己的主機,就可以享有 FLUX 的繪圖能力,可以快速且容易的整合進 Dify 工作流程中
https://replicate.com/black-forest-labs
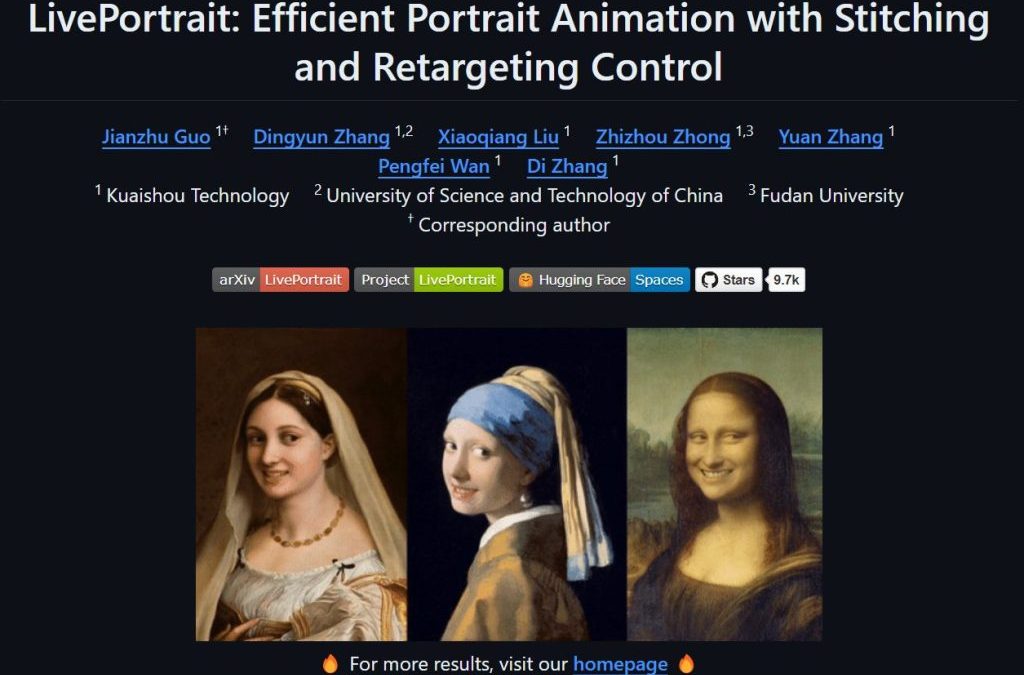
LivePortrait 是一個先進且有趣的影像生成技術,它不僅讓靜態肖像圖片動起來,變得栩栩如生,還能讓用戶在不同的角色之間進行變換,甚至能做到將一位大叔轉變成美女,美女變會跳舞的效果。這項技術目前在GitHub上獲得了10K顆星的高度關注,顯示了它在開源社群中的受歡迎程度。
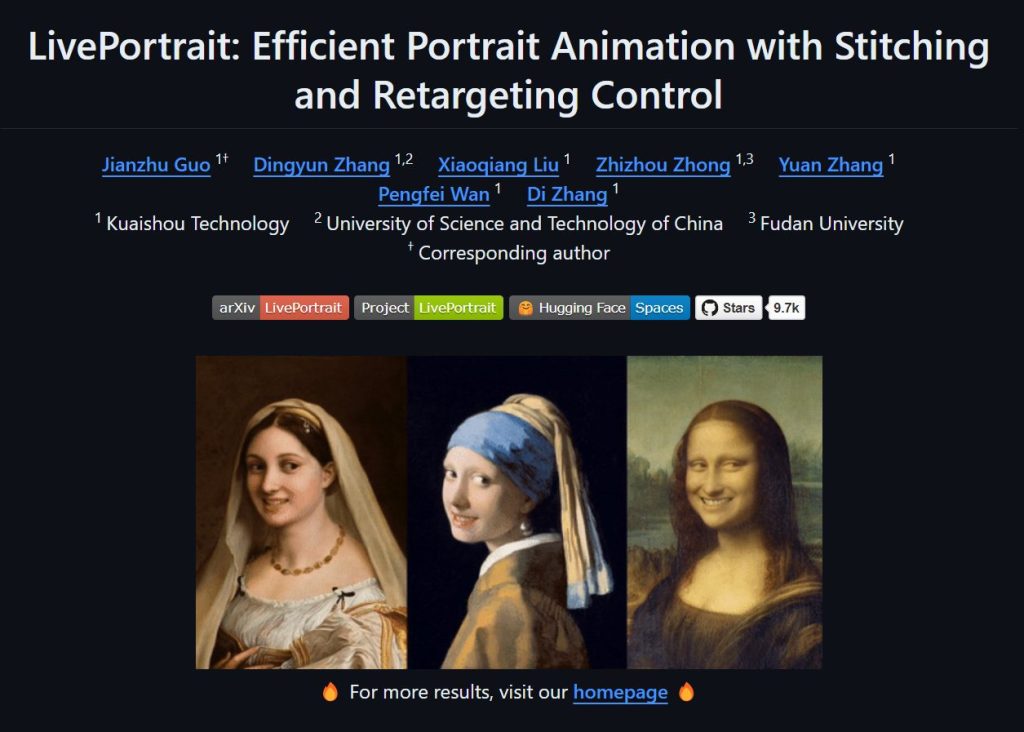
LivePortrait 是一個能夠讓靜態人像圖片進行動畫化的技術。該技術的核心是將人臉動作從一個人像轉移到另一個人像上,從而實現讓靜態圖片「動起來」的效果。與傳統的動畫技術相比,LivePortrait 的計算效率更高,並且生成的影像更加自然、流暢。
LivePortrait 的應用場景非常廣泛,從娛樂到專業用途都有所涉及。舉例來說,它可以用於製作逼真的動畫表情,為虛擬角色賦予生命,或者在影像特效中實現面部交換等功能。其高度的可定製性也讓它成為許多創意工作者的工具首選。
原始項目網址 https://github.com/KwaiVGI/LivePortrait
git clone https://github.com/KwaiVGI/LivePortrait cd LivePortrait # create env using conda conda create -n LivePortrait python=3.9 conda activate LivePortrait # 安裝相關依賴 pip install -r requirements.txt
# !pip install -U "huggingface_hub[cli]" huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
如果不能存取 Huggingface
# !pip install -U "huggingface_hub[cli]" export HF_ENDPOINT=https://hf-mirror.com huggingface-cli download KwaiVGI/LivePortrait --local-dir pretrained_weights --exclude "*.git*" "README.md" "docs"
# For Linux and Windows users python inference.py # For macOS users with Apple Silicon (Intel is not tested). NOTE: this maybe 20x slower than RTX 4090 PYTORCH_ENABLE_MPS_FALLBACK=1 python inference.py
# source input is an image python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4 # source input is a video ✨ python inference.py -s assets/examples/source/s13.mp4 -d assets/examples/driving/d0.mp4 # more options to see python inference.py -h

先安裝寵物模式
cd src/utils/dependencies/XPose/models/UniPose/ops python setup.py build install cd - # equal to cd ../../../../../../../
要使用的時候只需要下
python inference_animals.py -s assets/examples/source/s39.jpg -d assets/examples/driving/wink.pkl --driving_multiplier 1.75 --no_flag_stitching
https://huggingface.co/spaces/KwaiVGI/LivePortrait

Fusion Lab 又有新款力作,Hallo AI 可以讓用戶僅需提供一張照片和一段語音,就能讓照片中的人物進行說話、唱歌甚至進行動作,為數字內容創作帶來了革命性的突破。

盡量採用 Linux 平台,我這邊測試成功的有 Ubuntu 20 WSL 版本,就可以簡單三個步驟,部過前提要記得先安裝好 WSL CUDA 支援
conda create -n hallo python=3.10 conda activate hallo
pip install -r requirements.txt pip install .
apt-get install ffmpeg
python scripts/inference.py --source_image examples/reference_images/1.jpg --driving_audio examples/driving_audios/1.wav

Rope以其令人矚目的功能,站在了這場技術革新的前沿。這款AI工具不僅能夠輕鬆去除臉部遮擋,更整合了多種高清化算法,讓處理速度快如閃電。然而,在介紹如何安裝和使用Rope之前,我們必須提醒每一位用戶:這項強大的技術應當用於正當的創造和學術研究,千萬別拿去做壞事。現在,讓我們詳細了解如何在您的本地設備上安裝並運行Rope。

在開始使用Rope之前,需要先安裝一些必要的軟體:
安裝了必要的軟體後,便可以開始安裝Rope:
透過這些步驟,您可以在本地機器上成功安裝和配置Rope,並開始進行高效的臉部轉換。隨著AI技術的快速發展,Rope提供了一個既方便又強大的工具,使創意和創新更加無限。
請先確認安裝 Rope 已經成功,接著,遵循以下步驟來執行Rope的批量換臉功能:
cd命令切換到存放Rope應用程式的目錄。call venv\Scripts\activate.bat指令來激活Rope的Python虛擬環境。python run.py --execution-provider cuda指令,開始執行批量換臉處理。Rope提供多個可選參數來滿足用戶的特定需求:
face_enhancer選項,可以對換臉後的面部進行增強處理,使其更加清晰細緻。--video-quality選項並指定一個0到50的數值(數值越小,輸出質量越高)。--max-memory選項設定最大內存限制。--execution-threads來指定執行線程數,以達到最佳運行效能。Rope又一款强大的一键换脸AI!可消除脸部遮挡,多种高清化算法,飞一般的处理速度!本地安装与参数使用详解。 – YouTube
解除roop检测深度换脸 – YouTubehttps://www.youtube.com/watch?v=YH4hB3wmRcQ
roop新奇用法:一键直播换脸、批量换图 – YouTube

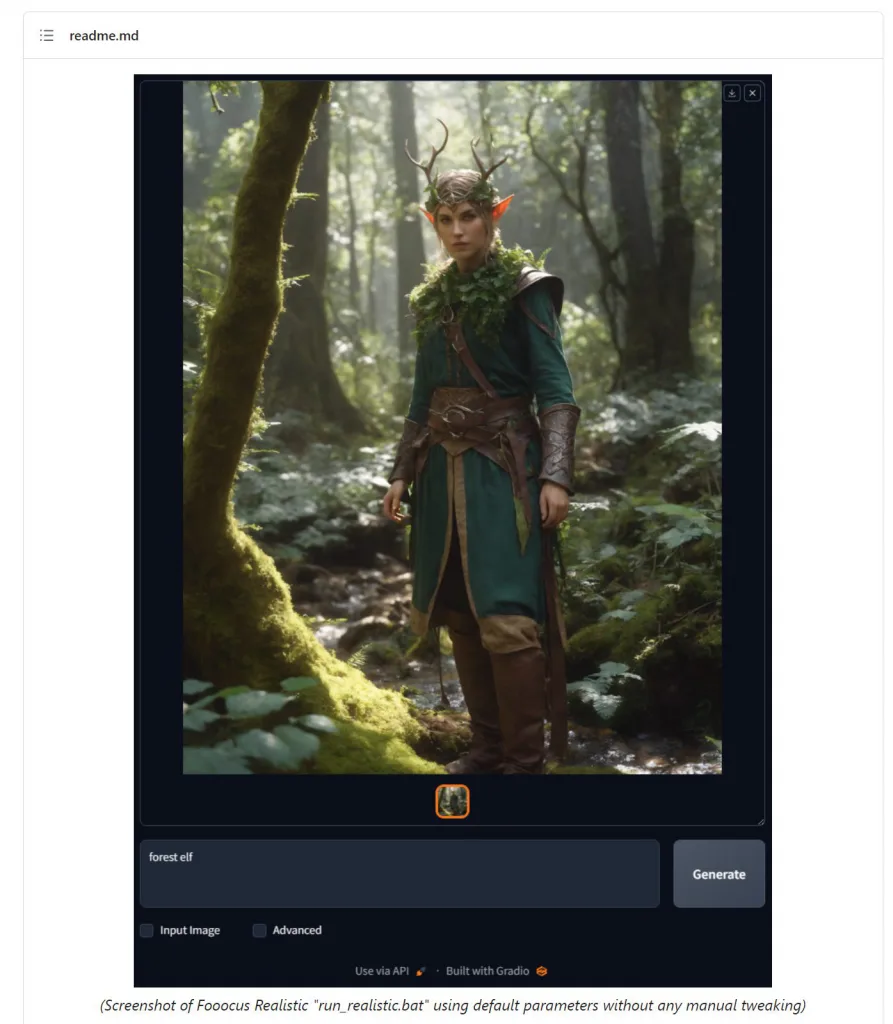
不論你是否具備繪畫基礎,Fooocus的力量都能幫助你創建出大師級的作品。本文將深入解析Fooocus的核心技術及其使用體驗。
Fooocus的使用界面簡潔明了,即使是零基礎的用戶,也能在短時間內上手。其推薦的配置要求為4GB Nvidia GPU記憶體及8GB系統記憶體,但即便是中低端筆記本,如配備16GB RAM及6GB VRAM的Nvidia 3060,都能達到令人滿意的效果。
Fooocus不僅為專業的AI繪畫工具,其安裝和使用過程也十分簡單。以下將針對Windows平台進行Fooocus的安裝與使用教學。
https://github.com/lllyasviel/Fooocus/releases/download/release/Fooocus_win64_2-1-60.7z
解壓縮後放在Fooocus_win64_2-1-60目錄下
sd_xl_base_1.0_0.9vae.safetensors
sd_xl_refiner_1.0_0.9vae.safetensors
模型檔需要放在 Fooocus\models\checkpoints\ 目錄下
控制模型要放在 Fooocus\models\inpaint\ 目錄下
執行解壓縮目錄下的 run.bat
Fooocus_win64_2-1-60\run.bat
這時候會做好模型下載以及基本設定,並且在本地端起一個 http://127.0.0.1:7860/ 伺服器
接下來用瀏覽器開啟該網址即可,超簡單
https://github.com/lllyasviel/Fooocus
近期留言