by Rain Chu | 3 月 17, 2025 | AI, Chat, Tool
DeepSeek R1 模型已經在 NVIDIA 平台上線,這是一個擁有 6710 億參數的開放式專家混合模型(MoE),專為解決需要高級 AI 推理的問題而設計的,但就是官方API不穩定,只能到處尋找替代的解決方案。
DeepSeek R1 的主要特點
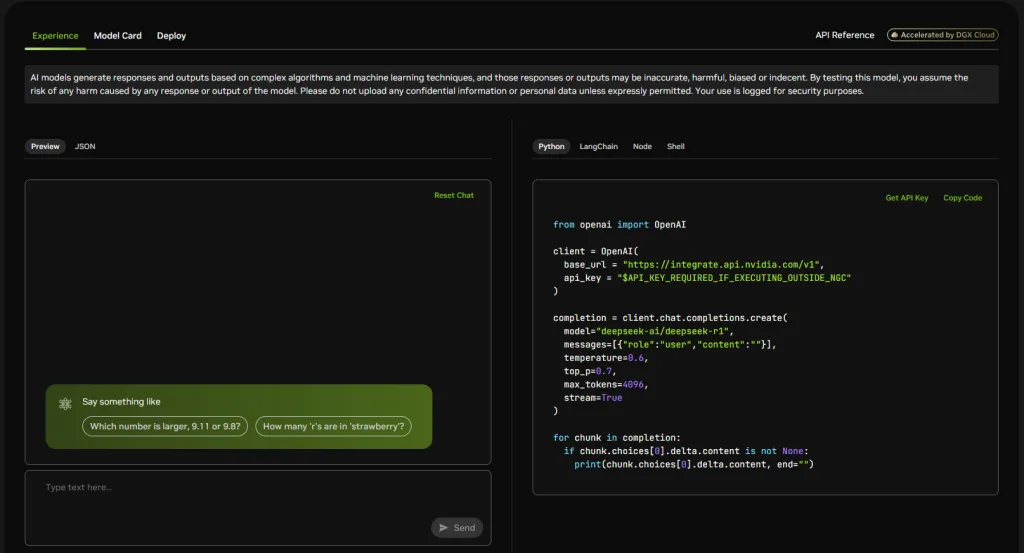
- API 友好性:DeepSeek R1 提供了多種 API 接口,支持 Python、LangChain、Node.js 和 Shell 等,方便開發者根據需求選擇合適的開發環境。
- 免費使用額度:NVIDIA 為個人和企業用戶提供了免費的使用額度。個人用戶可獲得 1000 點額度,企業用戶則可獲得 4000 點額度,讓更多人能夠體驗和使用該模型。
如何開始使用 DeepSeek R1
以下是使用 DeepSeek R1 的基本步驟:
- 註冊並獲取 API 密鑰:
- 前往 NVIDIA NIM 平台的 DeepSeek R1 頁面:
- 點擊右上角的「Login」或「Get API Key」,按照提示完成註冊並獲取 API 密鑰。
- 選擇開發環境並調用 API:
- Python:使用 OpenAI 兼容的客戶端調用 DeepSeek R1。 python複製編輯
- LangChain:可將 DeepSeek R1 集成到 LangChain 框架中,實現更複雜的語言處理任務。
- Node.js 和 Shell:NVIDIA 提供了相應的 SDK 和示例代碼,開發者可根據官方文檔進行集成。
用 python 來做示範
from openai import OpenAI
client = OpenAI(
base_url = "https://integrate.api.nvidia.com/v1",
api_key = "YOUR_API_KEY"
)
completion = client.chat.completions.create(
model="deepseek-ai/deepseek-r1",
messages=[{"role":"user","content":"你的問題內容"}],
temperature=0.6,
top_p=0.7,
max_tokens=4096,
stream=True
)
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
注意事項
- 使用額度:請留意您的免費使用額度,合理規劃 API 調用次數。
參考資料
https://build.nvidia.com/deepseek-ai/deepseek-r1
by rainchu | 9 月 10, 2024 | Docker, MIS
剛開始學習 docker的人,要記很多docker的指令,非常的麻煩以及複雜,身為RD,喜歡一切自己來,自己用CLI來控制,可以參考以下的指令
現有的 Docker 中去執行 shell command
1.找出容器的名稱或是ID
2.進入容器
docker exec -it [container_name_or_id] /bin/bash
3.直接執行shell命令,例如更新系統
apt update -y
apt upgrade -y
4.退出容器
延伸閱讀
docker 官網
by Rain Chu | 6 月 26, 2024 | Linux, MariaDB, Ubuntu, 資料庫
今天來實做一個備份任務,要在 Ubuntu 上設定每日凌晨 4:00 自動備份 MariaDB 中的所有資料庫,我們可以使用 cron 和一個自定義的 Shell 腳本來完成這個任務,以下是詳細步驟和代碼:
步驟 1:創建備份腳本
先創建一個備份 Shell Script,這個腳本將備份所有資料庫並分開儲存。
1.在 /usr/local/bin 目錄下創建一個新的 Shell 腳本:
sudo nano /usr/local/bin/backup_mariadb.sh
2. Script 的內容指令如下
#!/bin/bash
# 設定資料庫的用戶名和密碼
DB_USER="your_db_user"
DB_PASSWORD="your_db_password"
DB_HOST="10.0.0.1"
# 設定備份儲存目錄
BACKUP_DIR="/path/to/backup/dir"
mkdir -p $BACKUP_DIR
# 獲取當前日期和時間
CURRENT_DATE=$(date +%Y-%m-%d-%H-%M-%S)
# 獲取所有資料庫名稱
DATABASES=$(mysql -h$DB_HOST -u$DB_USER -p$DB_PASSWORD -e "SHOW DATABASES;" | tr -d "| " | grep -v Database)
# 備份每個資料庫
for DB in $DATABASES; do
if [[ "$DB" != "information_schema" && "$DB" != "performance_schema" && "$DB" != "mysql" && "$DB" != "sys" ]]; then
BACKUP_FILE="$BACKUP_DIR/$CURRENT_DATE-$DB.sql"
mysqldump -h$DB_HOST -u$DB_USER -p$DB_PASSWORD --databases $DB > $BACKUP_FILE
fi
done其中要修改的有
- DB_HOST : 要改成自己的
- your_db_user : 資料庫中有備份權限的使用者 ID
- your_db_password : 密碼
- BACKUP_DIR=”/path/to/backup/dir” : 要改成你要存放的路徑,像是 /var/backup_db/
3.將 .sh 變成可執行擋
sudo chmod +x /usr/local/bin/backup_mariadb.sh
步驟 2:設置 Cron 任務
1.打開 cron
2.加入設定內容,要注意的是實間是主機時間,通常主機是 UTC+0 的時區,要注意轉換,才會是正確的當地時間,可以參考這篇
0 4 * * * /usr/local/bin/backup_mariadb.sh
這樣就會在每天的早上四點去備份資料庫了
加入每一個SQL檔案都可以被壓縮的功能
程式碼區塊要改成下面這一個
# 備份每個資料庫並壓縮
for DB in $DATABASES; do
if [[ "$DB" != "information_schema" && "$DB" != "performance_schema" && "$DB" != "mysql" && "$DB" != "sys" ]]; then
BACKUP_FILE="$BACKUP_DIR/$CURRENT_DATE-$DB.sql"
ZIP_FILE="$BACKUP_DIR/$CURRENT_DATE-$DB.zip"
mysqldump -h$DB_HOST -u$DB_USER -p$DB_PASSWORD --databases $DB > $BACKUP_FILE
zip $ZIP_FILE $BACKUP_FILE
rm $BACKUP_FILE
fi
done刪除舊資料
可以利用下面的指令,放在程式碼的最後面
# 刪除兩天前的備份文件
find $BACKUP_DIR -type f -name "*.zip" -mtime +2 -exec rm {} \;需要改時間的話,只要修正 -mtime +2 ,把+2改成自己需要的時間
參考資料
https://help.ubuntu.com/community/CronHowto
近期留言