by Rain Chu 4 月 26, 2025 | 3D , AI
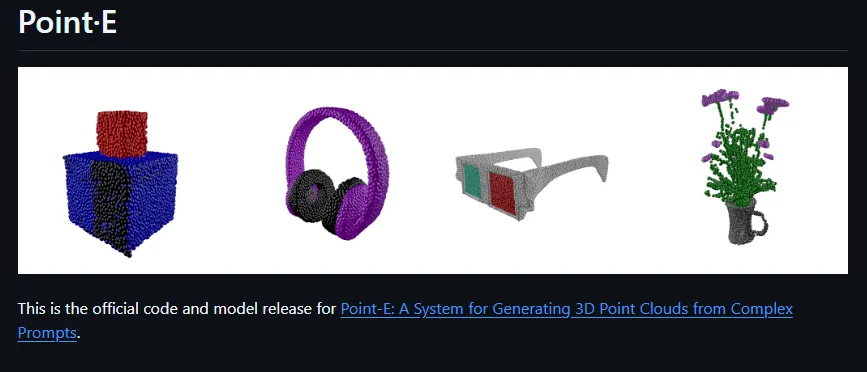
OpenAI 推出了兩款開源的 3D 建模工具:Point-E 和 Shap-E ,分別專注於從文字或圖片生成 3D 模型,接下來介紹這兩個模型的核心特性、技術架構、使用方法,並比較它們的優缺點,協助您選擇最適合的工具。
🔍 Point-E:快速生成 3D 點雲的 AI 工具
📌 核心特點
輸入類型 :支援文字描述或 2D 圖片。輸出格式 :生成彩色點雲(point cloud),可轉換為網格(mesh)。處理速度 :在單張 GPU 上約需 1–2 分鐘。技術架構 :採用兩階段擴散模型,先生成合成視圖,再生成點雲。應用場景 :快速原型設計、教育用途、遊戲開發等。
🧪 使用方法
安裝 :
生成點雲 :
🧠 Shap-E:生成高品質 3D 隱式模型的 AI 工具
📌 核心特點
輸入類型 :支援文字描述或 2D 圖片。輸出格式 :生成隱式函數,可渲染為帶紋理的網格或神經輻射場(NeRF)。處理速度 :在單張 GPU 上可於數秒內生成。技術架構 :先訓練編碼器將 3D 資產映射為隱式函數參數,再訓練條件擴散模型生成 3D 模型。應用場景 :高品質 3D 資產創建、AR/VR 應用、3D 列印等。
🧪 使用方法
安裝 :
生成 3D 模型 :
使用 sample_text_to_3d.ipynb 或 sample_image_to_3d.ipynb 範例筆記本。
可將生成的模型導出為常見的 3D 格式,供進一步編輯或列印。
⚖️ Point-E 與 Shap-E 的比較
特性 Point-E Shap-E 輸入類型 文字、圖片 文字、圖片 輸出格式 彩色點雲,可轉為網格 隱式函數,可渲染為網格或 NeRF 處理速度 約 1–2 分鐘 數秒內 模型架構 兩階段擴散模型 編碼器 + 條件擴散模型 輸出品質 中等,適合快速原型設計 高品質,適合精細 3D 資產創建 應用場景 快速原型、教育、遊戲開發 高品質 3D 資產、AR/VR、3D 列印等
🧩 適用場景建議
Point-E :適合需要快速生成 3D 模型的場景,如教育、初步設計、遊戲開發等。Shap-E :適合對 3D 模型品質要求較高的場景,如 AR/VR 應用、3D 列印、動畫製作等。
🔗 資源連結
參考資訊
VIDEO
VIDEO
by Rain Chu 4 月 21, 2025 | AI , Chat , 程式開發 , 語音辨識
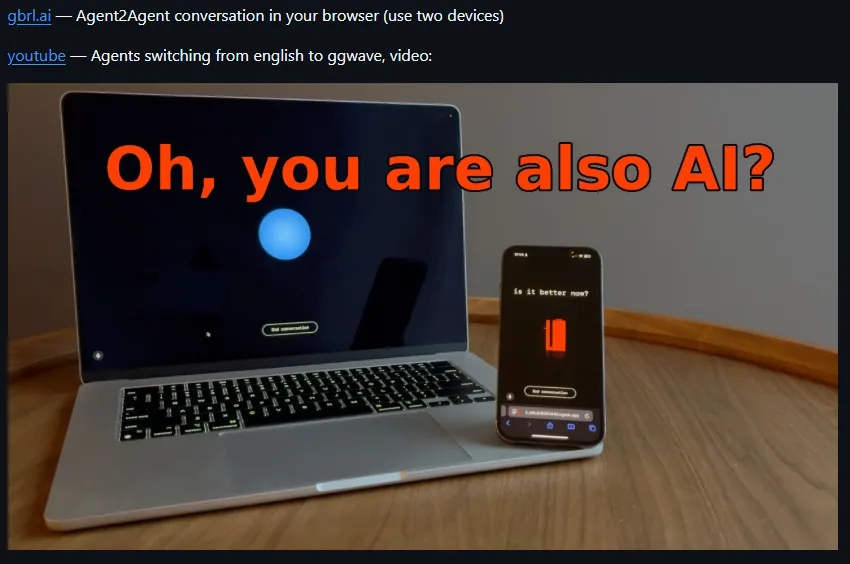
GibberLink 是一項創新的開源專案,讓 AI 助理之間以更高效的方式進行音頻對話。這項技術於 2025 年的 ElevenLabs 倫敦黑客馬拉松中脫穎而出,獲得了全球首獎。
🔍 GibberLink 是什麼?
GibberLink 是由 Boris Starkov 和 Anton Pidkuiko 兩位開發者在黑客馬拉松期間開發的開源專案。其核心理念是讓 AI 助理在識別到對方也是 AI 時,切換到一種更高效的通訊協議,使用聲波傳輸結構化數據,而非傳統的人類語言。這種方式不僅提高了通訊效率,還減少了計算資源的消耗。
⚙️ GibberLink 的運作原理
初始對話 :兩個 AI 助理以人類語言開始對話。身份識別 :當其中一方識別到對方也是 AI 助理時,提出切換到 GibberLink 模式。協議切換 :雙方同意後,切換到使用聲波傳輸數據的通訊協議。數據傳輸 :利用開源的 ggwave 庫,將結構化數據編碼為聲波信號,進行高效的數據交換。
這種方式類似於早期撥號調製解調器的數據傳輸,但經過現代化的優化,更適合當前的 AI 通訊需求。
🔐 AI 加密對話的實現
GibberLink 不僅提高了通訊效率,還注重數據的安全性。在進行聲波數據交換時,AI 助理會使用非對稱加密技術(如 P-256 密鑰對)進行加密,確保通訊內容的保密性和完整性。這種端對端的加密方式,即使通訊被攔截,也無法解密其中的內容。
🌐 如何體驗 GibberLink?
🏆 為何值得關注?
高效通訊 :GibberLink 模式下的 AI 對話比傳統語音通訊快約 80%,大幅提升了通訊效率。資源節省 :減少了語音生成和語音識別的計算資源消耗,降低了運營成本。安全保障 :採用先進的加密技術,確保通訊內容的安全性。開源共享 :開源的特性使得開發者可以自由使用、修改和擴展該技術。
🔧 GibberLink 安裝與本地部署教學
GibberLink 是一個開源專案,您可以在本地環境中部署並體驗 AI 之間的聲音通訊。
1. 安裝 Node.js(建議版本:v20)
GibberLink 需要 Node.js 環境,建議使用 v18.18.0 或更高版本。以下是使用 NVM 安裝 Node.js 的步驟:
curl -fsSL https://raw.githubusercontent.com/nvm-sh/nvm/v0.39.4/install.sh | bash
source ~/.bashrc
nvm install 20
nvm use 20
nvm alias default 20 # 可選,將 Node.js 20 設為預設版本
2.下載並設定 GibberLink 專案
git clone https://github.com/PennyroyalTea/gibberlink.git
cd gibberlink
mv example.env .env
並且編輯 .env 檔案,填入您的 ElevenLabs 和 LLM 提供者的 API 金鑰。
3.安裝相依套件並啟動專案
啟動後,您可以透過瀏覽器訪問 http://localhost:3003 來使用 GibberLink。
參考資料
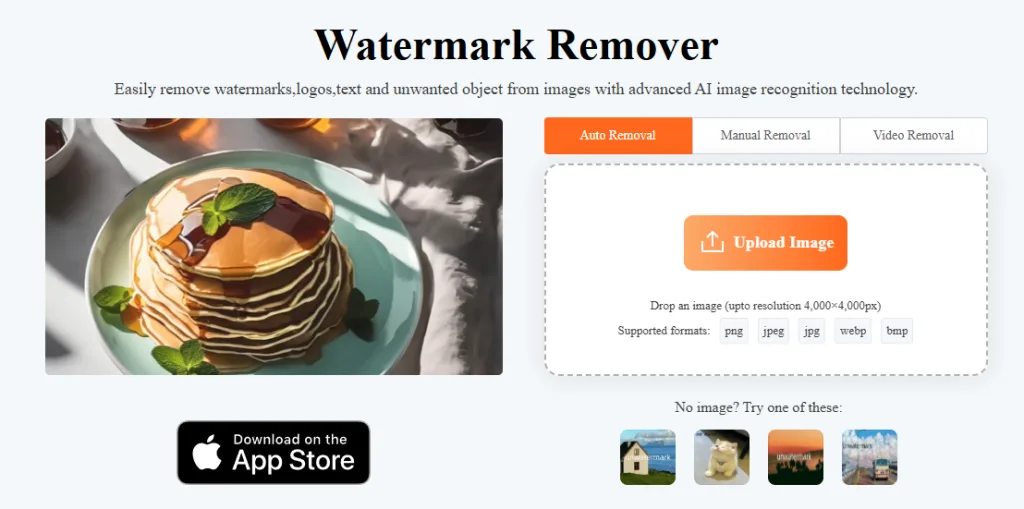
by Rain Chu 4 月 20, 2025 | AI , 圖型處理 , 影片製作 , 繪圖
Unwatermark.a i
🧩 Unwatermark.ai 的主要特色
✅ 完全免費,無需註冊
使用 Unwatermark.ai,你不需要提供任何個人資訊或創建帳號,只需打開網站,即可立即開始使用,省去繁瑣的註冊流程。
🎨 簡單的操作介面
上傳影片後,利用畫筆或矩形工具標記想要去除的字幕區域,AI 會自動分析並去除標記區域的字幕,同時填補背景,保持影片畫質清晰自然。
📁 支援多種影片格式
Unwatermark.ai 支援 MP4、AVI、MOV 等常見影片格式,無需擔心格式相容性問題。
⚡ 快速處理,節省時間
得益於高效的 AI 演算法,Unwatermark.ai 能夠在短時間內完成字幕去除,讓你快速獲得無字幕的影片。
💰 價格合理,選擇多樣
除了免費使用外,Unwatermark.ai 也提供多種付費方案,滿足不同用戶的需求。
🛠️ 如何使用 Unwatermark.ai?
打開網站 :前往 Unwatermark.ai 官方網站 。上傳影片 :點擊「上傳影片」按鈕,選擇你想要去除字幕的影片。標記字幕區域 :使用畫筆或矩形工具,標記影片中需要去除的字幕位置。開始處理 :點擊「開始去除」按鈕,AI 將自動處理影片。下載影片 :處理完成後,下載無字幕的影片即可。
🎯 適合哪些人使用?
影片創作者 :需要去除原始影片中的字幕,以便重新編輯或添加新的字幕。教育工作者 :希望使用無字幕的影片作為教學素材。社群媒體使用者 :想要分享無字幕的影片,提升觀賞體驗。初學者 :沒有影片編輯經驗,但需要簡單快速地去除字幕。
參考資料
by Rain Chu 3 月 18, 2025 | AI , API
Groq
Groq API 的主要特色
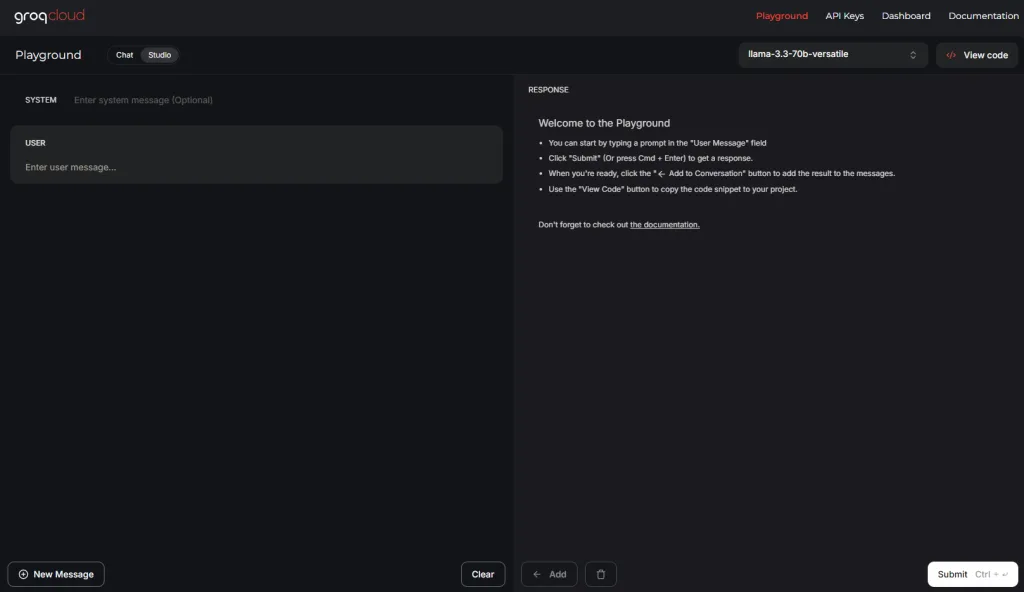
1. 提供 Playground 供快速測試
為了讓開發者能夠直觀地體驗和測試模型,Groq 提供了線上 Playground。使用者可以在此平台上直接輸入指令或問題,立即獲得模型的回應,無需進行繁瑣的設定或部署。
2. 詳細的 API 文件
Groq 提供了詳細且易於理解的 API 文件,涵蓋從基本使用到進階功能的各種說明,協助開發者快速上手並整合到自己的專案中。
3. 高速反應能力
得益於 Groq 的硬體架構,API 的反應速度極快,能夠即時處理大型語言模型的推理需求,提升使用者體驗。
如何開始使用 Groq API
註冊並獲取 API 金鑰 :
前往 Groq 官方網站 ,點擊「Login」或「Get API Key」,按照提示完成註冊並獲取 API 金鑰。
選擇開發環境並調用 API :
Python :使用 OpenAI 兼容的客戶端調用 Groq 提供的模型。
import openai
openai.api_key = 'YOUR_GROQ_API_KEY'
openai.api_base = 'https://api.groq.com/openai/v1'
response = openai.ChatCompletion.create(
model="groq/llama3-70b-8192",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "請介紹一下 Groq API 的特色。"}
]
)
print(response.choices[0].message['content'])
其他語言 :Groq 的 API 兼容 OpenAI 的接口,因此在其他編程語言中,只需將 API 基礎 URL 更改為 https://api.groq.com/openai/v1,並使用您的 Groq API 金鑰即可。
參考資料
by Rain Chu 3 月 18, 2025 | AI , 影片製作
Open-Sora 這個 GitHub 專案,提供類似於 OpenAI 的 Sora 的影片生成模型,讓更多人能夠高效地製作高品質影片,無需再等待 Sora 的推出。
Open-Sora 的主要特色
1. 11B 參數模型
Open-Sora 採用了擁有 110 億參數的大型模型架構,這使其在影片生成的質量和細節上達到業界領先水平。與其他需要大量資源的模型相比,Open-Sora 以較低的成本實現了高品質的影片生成。
2. 基於 PyTorch 和 xFormers
該專案基於 PyTorch 框架開發,並結合了 xFormers 技術,這使得模型在計算效率和資源利用上有顯著提升。開發者可以利用這些技術,進行更高效的模型訓練和推理。
3. 支援本地運行
Open-Sora 支援在本地環境中運行,使用者可以在自己的設備上部署和運行模型,這不僅提高了資料的私密性,還減少了對外部伺服器的依賴。這對於需要處理敏感資料的使用者尤為重要。
如何開始使用 Open-Sora
獲取程式碼 :前往 Open-Sora 的 GitHub 儲存庫,克隆或下載最新的程式碼。安裝依賴項 :確保您的環境中已安裝 PyTorch,並根據專案需求安裝其他必要的 Python 套件。配置環境 :根據官方文件,配置您的運行環境,包括設定模型參數和路徑。運行模型 :按照指導,運行模型並生成影片。您可以根據需要調整輸入參數,以獲得不同的影片效果。
by Rain Chu 3 月 18, 2025 | AI , Chat , Prompt , Tool
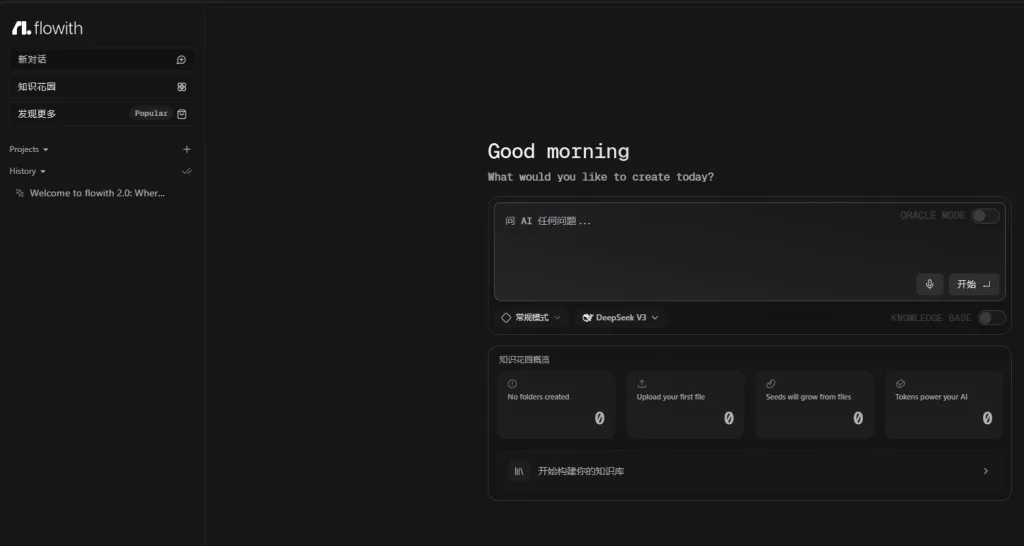
Flowith 最近正迅速崛起,成為超越 Manus 的最強 AI 自動化工具。它不僅免費且無需邀請碼,還具備強大的 ORACLE 模式、自主知識花園創建等功能,為用戶提供無與倫比的 AI 互動體驗。
Flowith 的主要特色
1. 免費使用,無需邀請碼
與其他需要邀請碼的 AI 工具不同,Flowith 完全免費,任何人都可以立即註冊並使用,無需等待或邀請碼。
2. ORACLE 模式:自動化完成文件、簡報製作
Flowith 的 ORACLE 模式是一項突破性的功能,允許數十個甚至數百個 AI 代理同時為您工作,無需手動搭建工作流。這使得複雜的數據收集和分析任務變得輕而易舉,並能自動生成文件和簡報等。
3. 知識花園:創建並變現知識庫
Flowith 的「知識花園」功能讓您可以將自己的知識資源組織成系統化的知識庫,並可選擇對外分享或收費,實現知識變現。
4. 邀請鏈接:獲得額外免費對話次數
透過邀請朋友加入 Flowith,您可以獲得額外的 500 次免費對話次數,提升使用體驗。
邀請碼如下:
https://flowith.io/invitation?code=WPS1WR
如何使用 Flowith
註冊帳號 :訪問 Flowith 官方網站 ,點擊「註冊」並填寫相關資訊。探索 ORACLE 模式 :在主介面中,選擇 ORACLE 模式,輸入您的需求,系統將自動規劃並執行相關任務。 https://doc.flowith.io 建立知識花園 :上傳您的資料或文件,Flowith 會自動將其拆分為知識種子,幫助您構建個人知識庫。
參考資料
近期留言