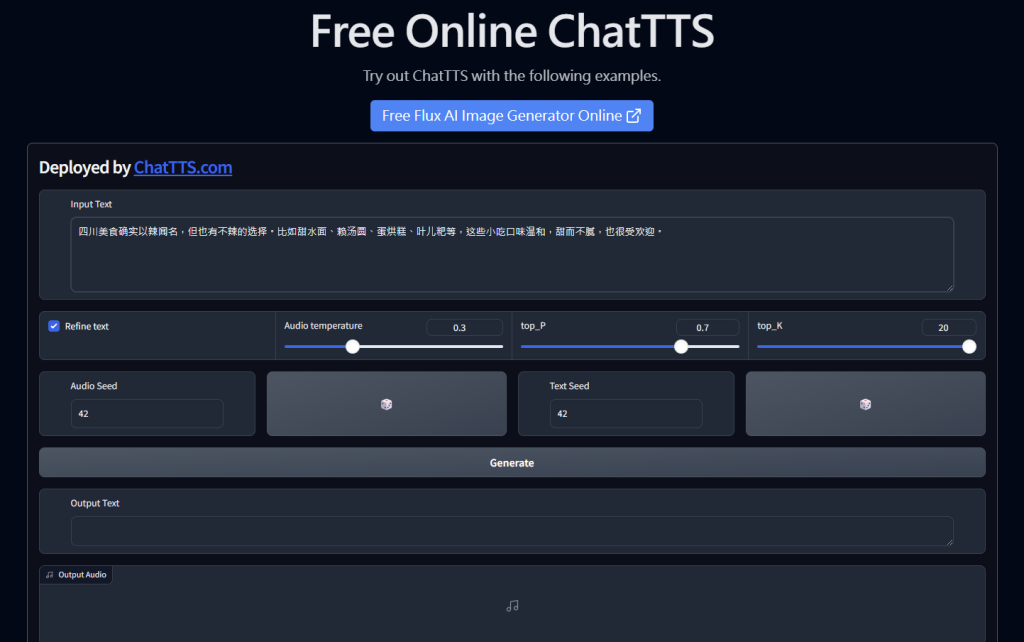
ChatTTS-完整使用指南
免費且超強大的 AI TTS,文字轉語音模型+工具,有許多語氣的控制,也可以很精準的寫程式控制效果,是RD眼中好用的Local端開源的TTS
特色說明
1.大規模的數據:10萬小時的訓練資料,現在開源的是4小時的版本
2.專用設計:專門對於對話情境、視頻介紹的情境所設計的模型
3.開源特性:可以很簡單的整合到你的WEB中
4.支持語氣:oral, laugh, break
安裝前準備
python 3.10
CUDA
GIT
gradio
安裝說明
github 複製
git clone https://github.com/2noise/ChatTTS cd ChatTTS
安裝依賴
pip install --upgrade -r requirements.txt
執行 webui
python examples/web/webui.py
利用 CLI
python examples/cmd/run.py "Your text 1." "Your text 2."
要整合在 python 程式碼中,可以安裝 PyPI
pip install ChatTTS pip install git+https://github.com/2noise/ChatTTS pip install -e .
整合程式碼
###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
"""
In some versions of torchaudio, the first line works but in other versions, so does the second line.
"""
try:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
except:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]), 24000)V3版本
音色庫
https://www.modelscope.cn/studios/ttwwwaa/chattts_speaker
注意事項
1.是否要使用CUDA,需要的話,記得安裝依賴
2.要用CUDA,怎選擇 Linux 平台,相容性比較好
3.Python最好用3.10版本,並且用conda
直接使用
參考資源
Lobe Chat UI-有plugin,多模態的AI CHAT UI – 雨 (rain.tips)
AI Tools – AI工具大全(總整理) – 雨 (rain.tips)

近期留言