
by Rain Chu | 4 月 10, 2023 | AI, Stable Diffusion, 繪圖
Stable Diffusion Lora 超好用,已經不太需要說明,今天要來介紹一個可以讓 Lora 放開她的束縛,可以完全調整 Lora 在模型中的每一層的權重設定,為何要有分層設定,可以看看原作者的下面這張說明圖,分別在不同層插入 Lora 可以有不同的效果出現,也可以更精準的控制AI
LoRA 權重外掛
hako-mikan/sd-webui-lora-block-weight (github.com)
安裝方法,到擴充功能中,選擇從網址安裝,並且輸入 hako-mikan/sd-webui-lora-block-weight (github.com)
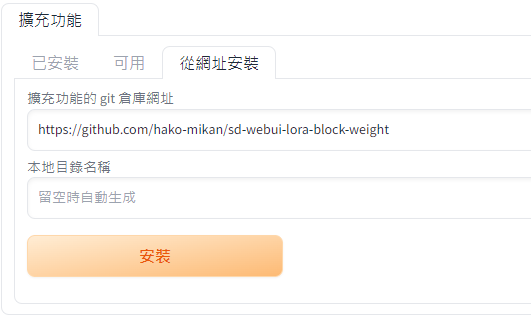
之後重啟系統即可看到多了 LoRA Block Weight 可以用
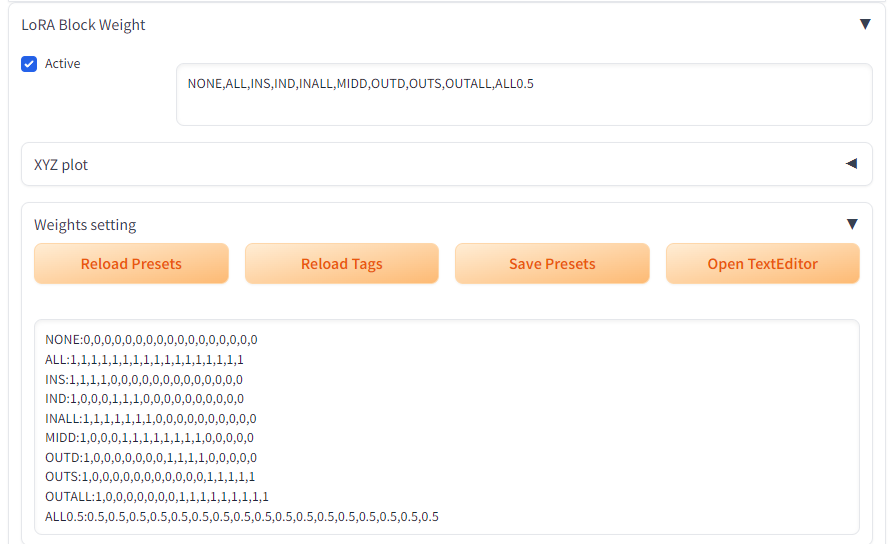
至於使用效果的話,我建議都試試看上面的設定,再去拿捏下手的感覺
LoRA 整合權重外掛的 UI
bbc-mc/sdweb-merge-block-weighted-gui: Merge models with separate rate for each 25 U-Net block (input, middle, output). Extension for Stable Diffusion UI by AUTOMATIC1111 (github.com)
LoRA擁有17個作用層

參考資料
by Rain Chu | 4 月 10, 2023 | AI, Stable Diffusion, 繪圖
不要再說AI畫出來的圖還沒達到專業水準了,現在日本一家新創公司,都用 Stable Diffusion 來設計它們自己的電動概念車,並且將完整的過程放在 Youtube 上,從畫設計稿,到建模並且列印出來,並且還製作了動畫

by Rain Chu | 4 月 8, 2023 | AI, Stable Diffusion, 繪圖
想要裝潢自己的房間,以前要學會CAD、3D、還要有美學基礎,和知道各式各樣的配件,才能完成室內設計的艱難任務,但現在可以用 StableDiffusion + ControlNet 或是 Lora 等方法,也可以用 https://interiorai.com/ 有訓練好且專門針對室內設計用的 AI 網站來創意發想。
一個好的室內設計軟體應該要能夠
- AI空間規劃:這款工具可以根據用戶提供的房間尺寸和設計需求,自動生成合適的家具佈局。它可以幫助室內設計師快速評估不同的空間規劃方案,並找出最佳的解決方案。
- AI颜色搭配:這款工具可以根據用戶提供的颜色樣本,自動生成和推薦搭配方案。它能幫助室內設計師在短時間內找到理想的配色方案,提高設計效率。
- AI材質生成:這款工具可以根據用戶提供的材質樣本,自動生成高質量的材質圖像。它可以為室內設計師提供大量的材質選擇,並支持快速地將材質應用到設計中。
- AI風格轉換:這款工具可以將一種風格的室內設計快速轉換為另一種風格。這可以幫助室內設計師為客戶提供多種風格的設計方案,以滿足不同的品味和需求。
而 interiorai 就可以快速的滿足上述條件
簡單且快速地創造提案
提供圖片檔,選擇場景,選擇創意,馬上就可以得到些提案,之後就可以精修設計圖
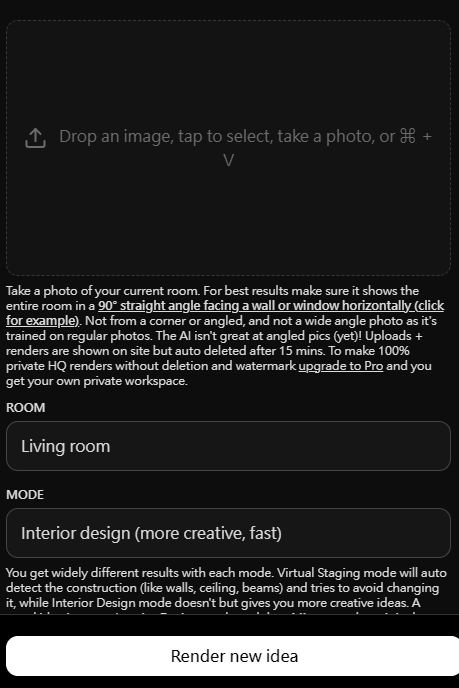
各種風格和功能可以進階調整

費用,專業版本每個月29美元,約900元

參考資料
AI也會畫室內設計
by Rain Chu | 4 月 2, 2023 | AI, Stable Diffusion, 繪圖
隨著科技的快速發展,人工智能(AI)已經深入滲透到我們日常生活的方方面面。在這個世代,手機已經成為我們生活中不可或缺的一部分。而現在,我們可以利用AI技術在手機上進行繪畫,使創作變得更加輕鬆、有趣和高效。在這篇文章中,我們將探討如何在手機上使用AI進行繪圖,以及如何充分利用這些工具來提高您的藝術技巧,讓你可以離開鍵盤和滑鼠的限制,用手點一點也可以AI繪畫。
直接用現成的APP
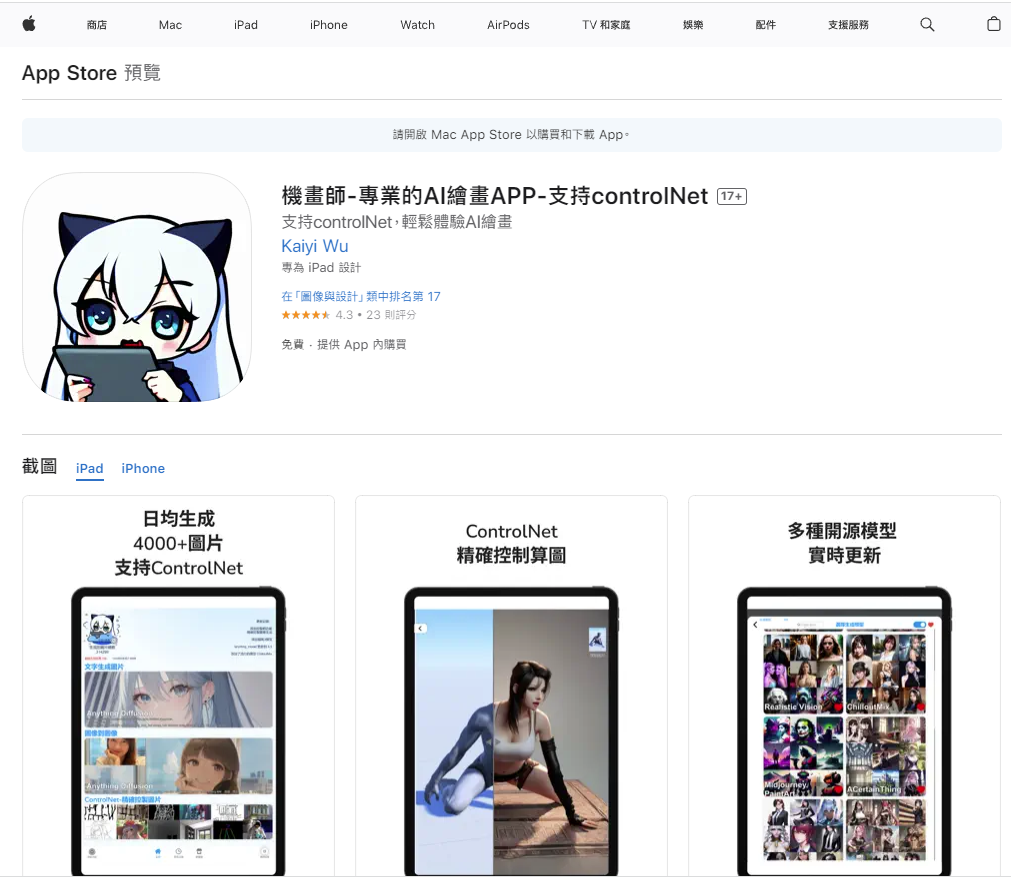
機畫師-專業的AI繪畫APP-支持controlNet
有團隊把 Stable Diffusion 的 Webui 做成 APP 給大家使用,需要付費,如果不想用電腦的可以試試看
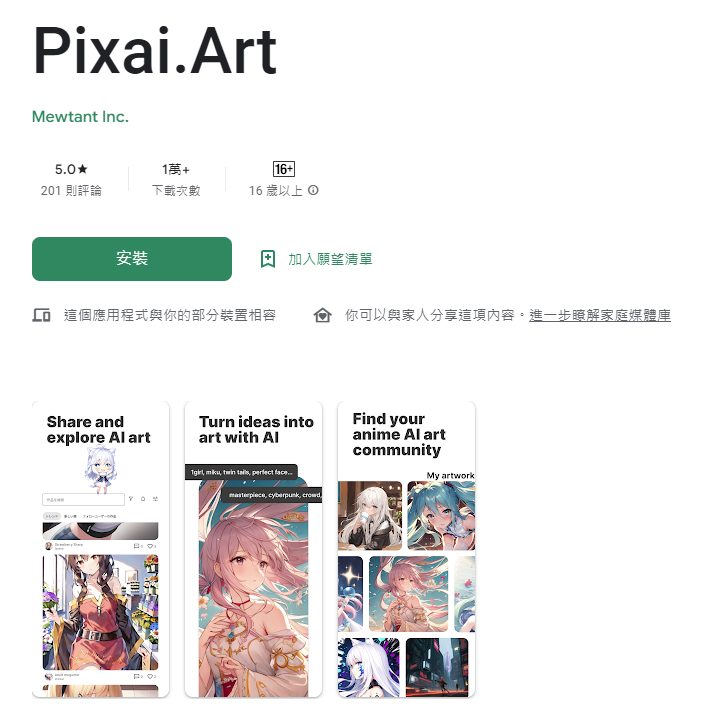
Pixai.Art
在 Android 上的 AI 繪圖軟體,底層也是採用 Stable Diffusion ,現在也支援 LORA 和 Control Net
Google Colab
用 Google Colab 雲端伺服器來幫忙運算,原則免費,但建議可以付點錢,享受更快更穩,不麻煩的服務
https://colab.research.google.com/github/camenduru/stable-diffusion-webui-colab/blob/main/stable/chillout_mix_webui_colab.ipynb
直接用上面的網址,然後都下一步,就可以建立起自己的 WebUi
Draw Things
https://drawthings.ai/
用 iPhone 上面的資(CPU、GPU),來做AI繪圖,可以離線使用,但手機會很燙,且很耗電
How to run Stable Diffusion on Termux on Android phone
https://ivonblog.com/en-us/posts/android-stable-diffusion/
神人教你如何在 Android 上面安裝自己的 Stable Diffusion Webui ,過程很難,且不是每一隻手機都可以,有興趣的在看看即可
參考資料
by Rain Chu | 4 月 2, 2023 | AI, Stable Diffusion, 繪圖
我相信很多人在 https://civitai.com/ 要下載 Stable Diffusion 模型的時候總是不知道要怎麼選擇,有的模型2-7GB,有的模型只有幾十MB,還有自己想要訓練自己的模型時候也不知道該用那個方法去選擇訓練的模型,今天在這邊解釋一下
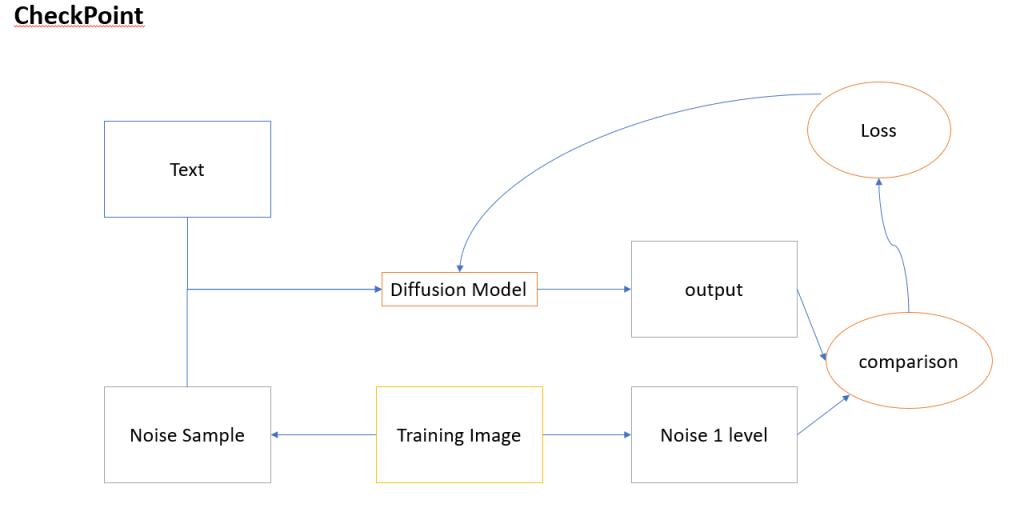
Checkpoint
完整的並且重頭到尾自己訓練一個模型出來,最能控制所有細節,但檔案最大,參數最多耗時耗力
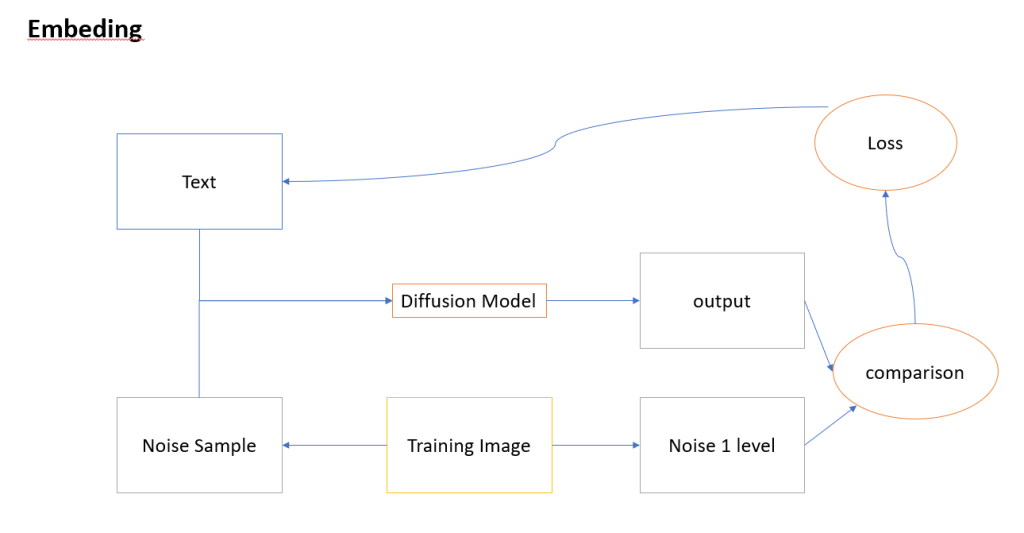
Embeding
需要選擇基礎模型,在基礎模型上,去調整訓練輸入用的文字,可以微調模型,讓模型更精準的識別你輸入的文字,而去產生更精準的圖片,最後訓練的結果通常都是幾KB或是幾MB,檔案都很小
Lora
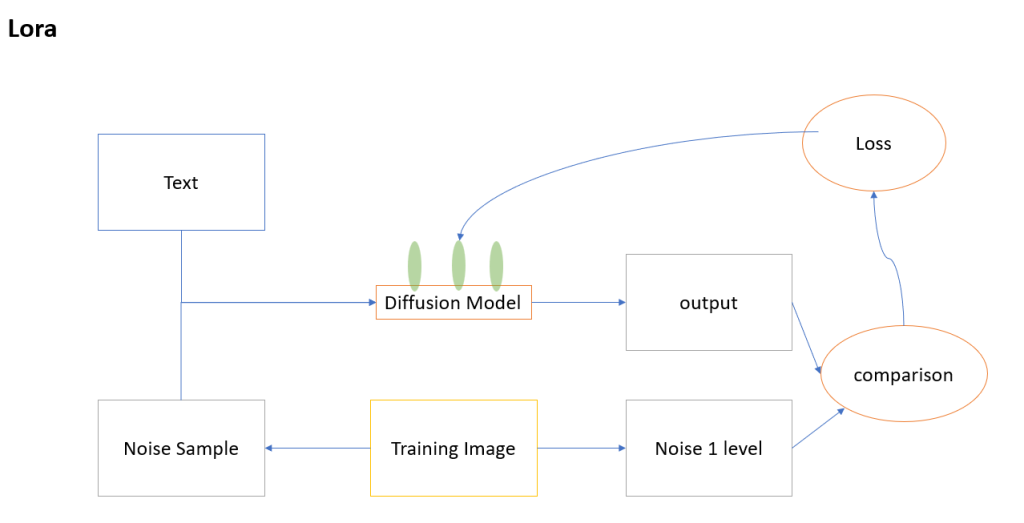
也需要選擇基礎模型,這時候的訓練,會是去疊加在原本模型中上面,可以想像你泡咖啡的時候,多了一個濾網,這個濾網有咖啡口味、抹茶口味,當以後你要用SD的時候,選擇了基礎模型,並且指定用那一個LORA模型,他就會在你們基本的咖啡上加入新的風味,且LORA模型還可以是多個輸入並且指定權重。
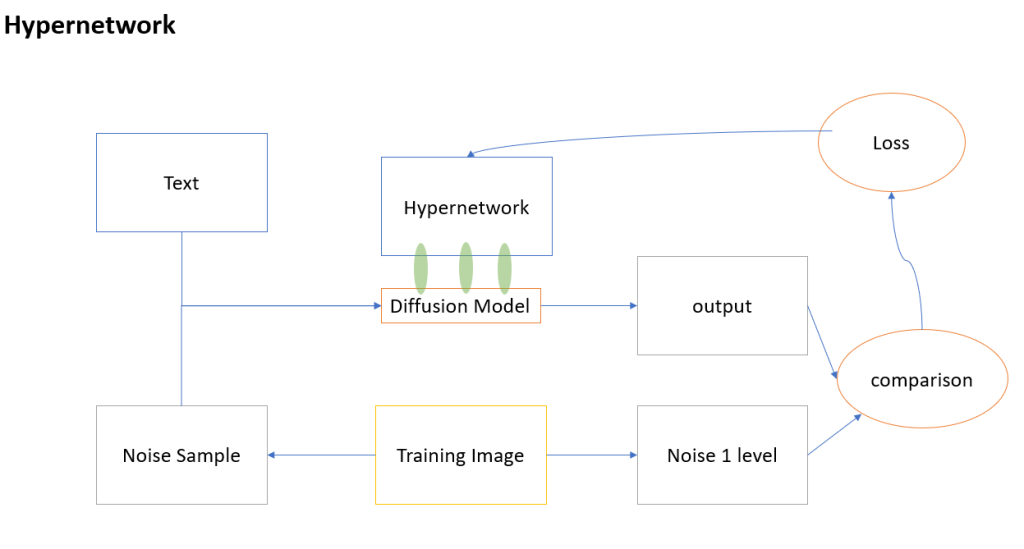
Hypernetwork
跟LORA模型類似,只是他會是在另外訓練一個新的模型,而不只是一個LORA濾網,現在已經比較不流行了,大多數的場景,用LORA即可,一般訓練出來的檔案大小跟LORA也差不多,細節是有更多可以設定,但效果沒差多少
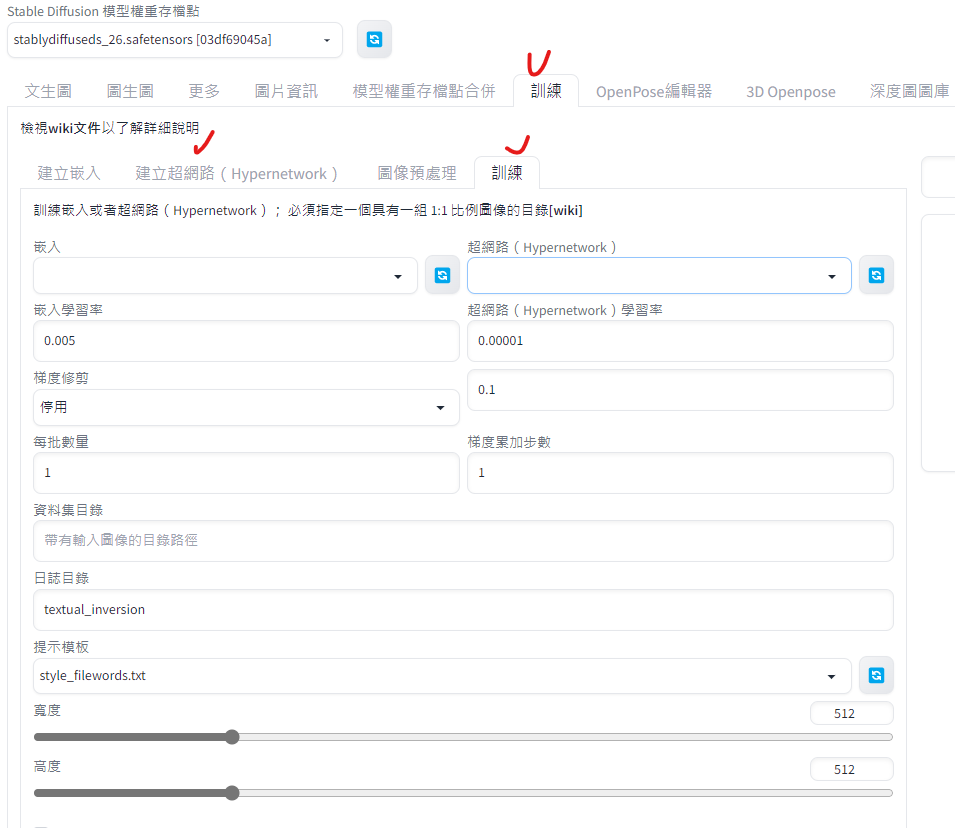
參考資料
by Rain Chu | 3 月 30, 2023 | AI, Stable Diffusion
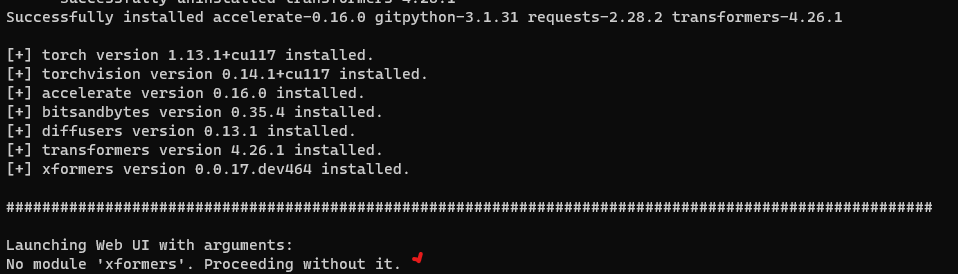
當你使用 Stable Diffusion 的 Webui 版本,預設啟動的時候會出現一行 No module ‘xformers’. Proceeding without it. 最有可能的情況是你已經安裝好 xformers ,但沒有啟動她,可以看看以下的解決方法
No module ‘xformers’. Proceeding without it.
Windows 使用者修改 webui-user.bat
請打開 webui-user.bat 並且找到 set COMMANDLINE_ARGS= ,在後面加入 –xformers 參數,讓他變成下面的樣子
set COMMANDLINE_ARGS=--xformers
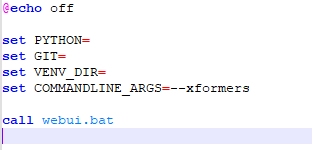
存檔後離開,並且重新執行 Webui 即可,但如果有錯誤,通常是執行環境以及CUDA的問題,那就先關閉,在找其他解法
補充說明
set COMMANDLINE_ARGS 後面可以接的參數如下,當你有記憶題不足的問題,可以嘗試其他的參數看看
–xformers
–medvram
–medvram –opt-split-attention –precision full –no-half
–medvram –opt-split-attention
–opt-split-attention
參考資料
https://github.com/AUTOMATIC1111/stable-diffusion-webui/discussions/5303
近期留言