by Rain Chu | 3 月 13, 2025 | AI, Chat, Ollama, 模型
超大型語言模型(LLM)成為科技界矚目的焦點,以前這類模型通常需要極高的硬體門檻,要很多的 GPU 才能達成(需要好幾百萬),難以在本地設備上流暢運行。然而,現在配備 512GB 超大記憶體的 Mac Studio,約33萬台幣,就能輕鬆駕馭滿血版 DeepSeek R1,讓個人或企業用戶都能輕鬆享受超大型語言模型帶來的豐富應用價值!
為何 512GB 就足夠跑 DeepSeek R1?
DeepSeek R1 是一款擁有超過 6710 億參數的超級大型語言模型,理論上需超過 400GB 以上記憶體空間才能順暢載入。然而,DeepSeek R1 採用了特殊的 Mixture of Experts (MoE) 架構,儘管整體模型規模龐大,但實際上單次推理只會激活約 370 億參數,大幅減少記憶體的實際使用需求,讓 512GB 記憶體的 Mac Studio 就能輕鬆駕馭。
關鍵技巧:調整 VRAM 配置,釋放更大的 GPU 資源
Mac Studio 使用的是統一記憶體架構(Unified Memory),系統自動分配 GPU 使用的 VRAM 空間。預設情況下,VRAM是有限制的,不足以負荷 DeepSeek R1 這樣龐大的語言模型,但使用者可以透過調整系統參數,自由設定 GPU 的 VRAM 配置,以達到最大效能:
以下是關鍵指令:
sudo sysctl iogpu.wired_limit_mb=448000
透過這項設定,系統的 GPU VRAM 即可輕鬆擴展到 448GB,滿足 DeepSeek R1 等超大型模型的嚴苛需求,真正發揮 512GB 記憶體 Mac Studio 的硬體潛力。
⚠️ 貼心提醒:
調整 VRAM 前,建議備份重要資料。修改設定可能影響系統穩定性,請謹慎操作。
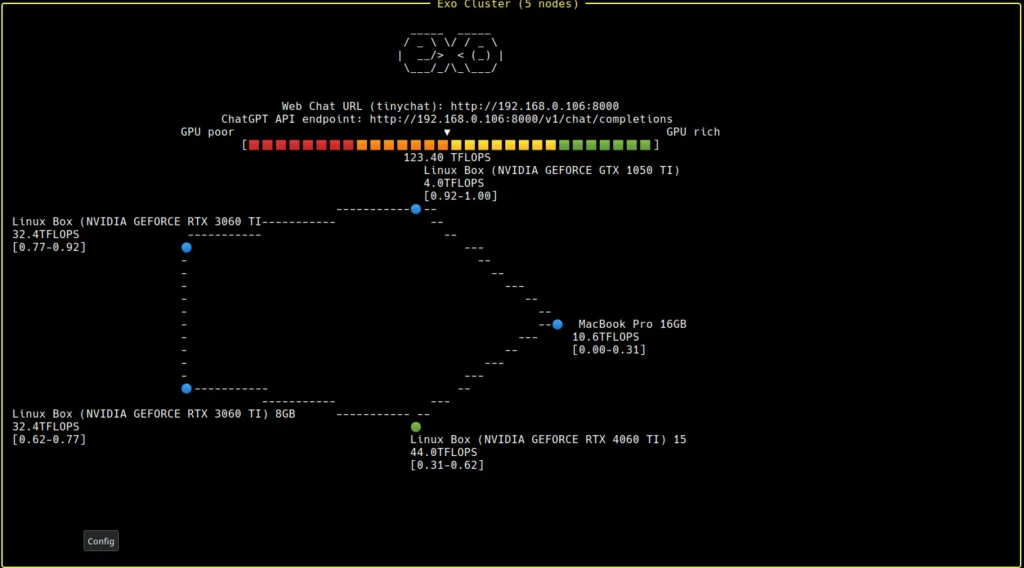
EXO 工具:連接多台 Mac,建立強大的分散式計算環境
如果你需要更強大的算力,還可以透過開源的 EXO 專案,將多台 Mac 電腦串聯起來,組成超強大的本地計算集群,以協同運行 DeepSeek R1 這類超大型語言模型。
透過 EXO,你可以:
- 將多台 Mac Studio 連結成計算網絡。
- 有效分散模型推理負載,提升整體效能。
- 進一步降低單機的運算負擔,確保持續穩定運作。
這個方法尤其適合專業研究團隊、企業內部部署,甚至是有進階 AI 運算需求的開發者。
參考資料
https://zenn.dev/robustonian/articles/apple_silicon_vram
by Rain Chu | 3 月 10, 2025 | AI, 影片製作
探索阿里巴巴開源的 AI 影片製作模型:Wan 2.1
阿里巴巴近期推出的開源影片生成模型——Wan 2.1,為創作者提供了一個強大且高效的工具。該模型不僅完全開源,還具備極快的生成速度,並融入了豐富的東方元素,如哪吒等,為影片創作帶來了新的可能性。
Wan 2.1 的主要特色
完全開源,兼容性強
Wan 2.1 採用 Apache 2.0 協議開源,這意味著開發者可以自由地使用、修改和分發該模型,甚至用於商業用途。此外,Wan 2.1 支援 ComfyUI 等圖形介面,方便用戶進行可視化操作,降低了技術門檻。
高效的影片生成速度
得益於先進的架構設計,Wan 2.1 在影片生成速度上表現優異。即使在消費級 GPU 上,如 RTX 3070 顯卡,使用 1.3B 參數模型即可流暢運行,生成 480P 分辨率的影片,更何況現在已經來到了RTX 5090,這將讓個人也能夠在本地設備上高效地進行影片創作。
豐富的東方元素融入
Wan 2.1 在影片生成中融入了大量的東方元素,特別是中國傳統文化中的角色和場景。例如,模型能夠生成包含哪吒等經典角色的影片,這為喜愛東方文化的創作者提供了更多的創作靈感和素材。
如何離線使用 Wan 2.1 進行影片創作
- 環境準備:首先,確保您的電腦具備足夠的硬體資源,建議使用至少 12GB 顯存的顯卡。
- 下載模型:從官方 GitHub 倉庫或 HuggingFace 平台下載 Wan 2.1 的模型檔案。
- 安裝依賴:根據官方指引,安裝所需的 Python 套件和其他依賴項。
- 運行 ComfyUI:啟動 ComfyUI,載入 Wan 2.1 模型,並按照介面提示輸入文本或上傳圖片,以生成對應的影片內容。
- 下載 ComfyUI 工作流 : JSON
參考資料
https://www.freedidi.com/18705.html
by Rain Chu | 3 月 10, 2025 | AI, 圖型處理, 影片製作
探索 Magnific 的圖片風格遷移功能
風格遷移(Style Transfer)是現在AI圖學中的一項創新技術,讓我們能夠將一張圖片的風格應用到另一張圖片上,創造出獨特且富有創意的視覺效果。Magnific 作為一款先進的 AI 圖像處理工具,近期推出了風格遷移功能,為用戶提供了更多元的創作可能性。
什麼是風格遷移?
風格遷移是一種基於卷積神經網絡(CNN)的技術,通過優化目標圖像,使其在內容上接近原始圖像,在風格上接近參考圖像,從而實現風格的遷移。這意味著,我們可以將一幅畫的藝術風格應用到一張照片上,或是將某種設計風格融入到現有的圖像中,創造出全新的視覺效果。
Magnific 的風格遷移功能特色
Magnific 的風格遷移功能在保留原圖結構的同時,成功地將參考圖的風格融入其中。這使得生成的圖像既保持了原始內容的清晰度,又展現了新的風格特徵。
主要參數解讀
- Style Strength(風格強度):控制風格遷移的程度。建議初次使用時設置在 95% 左右,以最大程度地遷移參考圖的風格。
- Structure Strength(結構強度):決定保留原圖結構的程度。建議設置在 85% 以上,最好是 100%,以確保輸入圖像的線條和輪廓得以保留。
- Portrait(肖像模式):處理肖像時,務必啟用此選項。
- Portrait Style(肖像風格):可根據個人喜好選擇「標準」、「流行」或「超流行」。
- Enhance(增強):若希望面部特徵更為明顯,可啟用此選項,但可能會導致相似度略有下降。
- Fixed Generation(固定生成):啟用後,使用相同的設置(如提示詞、風格強度等)生成的圖像將始終相同。此功能主要用於模型微調和測試。
- Engine(引擎):建議選擇 Balanced(平衡)模式,效果均衡美觀,細節豐富。Real(真實)和 Super Real(超真實)適合生成寫實風格。
- Flavor(風味):若希望生成的圖片風格更接近參考圖,可選擇 Faithful。若希望色彩更豐富、藝術感更強,可選擇 GenZ 或 Psychedelia。
如何使用 Magnific 的風格遷移功能
- 上傳圖像:在 Magnific 的界面中,分別上傳要編輯的圖像和風格參考圖。
- 設置參數:切換到風格遷移功能,填寫提示詞,並根據需要設置上述參數。
- 生成圖像:點擊「Generate」按鈕,等待片刻,Magnific 即會生成一張融合了兩張圖片特徵的新圖像。
- 放大與修復:最後,可使用 Upscale 功能放大圖像並修復一些細節,特別是面部細節。
Magnific 與 Midjourney 的比較
Magnific 的風格遷移功能與 Midjourney 的風格參考功能在算法上有所不同,導致了二者的差異。Midjourney 主要使用擴散模型(Diffusion Model),通過噪聲逐步擴散和去噪的過程來生成圖像。然而,這種方法對原始圖片的結構保留得並不好,生成的圖像往往在構圖和形狀上與原圖差異較大。而 Magnific 使用的是風格遷移技術,通過優化目標圖像,使其在內容上接近原始圖像,在風格上接近參考圖像,從而實現風格的遷移。在這個過程中,原始圖像的結構信息可以得到較好的保留。
Magnific 的風格遷移功能為用戶提供了一個強大且靈活的工具,能夠在保持原圖結構的同時,實現風格的創意轉換。無論是設計師、攝影師,還是普通用戶,都可以利用這項功能。
by Rain Chu | 2 月 25, 2025 | AI, 圖型處理, 繪圖
可以不要再用 photoshop 來摳圖了,Aiarty Image Matting 以其強大的 AI 摳圖技術脫穎而出,能夠精準識別前景與背景,並處理各種複雜場景,如毛髮、透明物體、婚紗和玻璃等細節,最新版本支援多款 AI 模型,其中 AlphaStandard V2 在半透明物件的摳圖方面表現尤為出色,確保細節保留並與背景完美融合。
主要功能介紹
1. 多款 AI 摳圖模型
Aiarty Image Matting 提供四種 AI 模型,以應對不同類型的圖像:
- AlphaStandard V2:適用於婚紗、玻璃、水滴等半透明物件,保留細緻邊緣與透明效果。
- AlphaEdge V2:針對邊緣處理優化,使摳圖效果更清晰細緻。
- EdgeClear V2:適合處理 電商產品圖,如服飾、鞋子、包包、電子產品等。該模型可有效增強邊緣清晰度,使產品與背景分離更加自然,並去除雜訊,確保產品輪廓銳利。這對於電商平台(如 Amazon、Shopee、蝦皮、京東)上的商品展示至關重要。
- SolidMat V2:專為堅固物件(如書籍、家具、衣物)設計,提供最佳輪廓識別。
2. 支援導出蒙版功能
Aiarty Image Matting 允許使用者導出 Alpha 蒙版(Mask),這項功能對於影像合成、特效處理和影像編輯極為重要。蒙版導出後,可在 Photoshop、Premiere Pro 或其他影像處理軟體中進一步編輯,方便用戶調整前景與背景的融合效果。
3. 高效批量處理
該工具支援一次處理多達 3000 張圖片,適合需要大量摳圖的設計師與影像後製團隊,大幅提升工作效率。
4. 多樣化背景處理
摳圖後的影像可選擇:
- 保留透明背景(.PNG)
- 替換純色背景
- 替換自定義背景(如模糊效果或其他圖片)

by Rain Chu | 2 月 23, 2025 | Agent, AI, Chat, Prompt
硅基流動(SiliconFlow)是一家致力於加速通用人工智慧(AGI)普惠化的公司,主要可以讓生成式人工智慧惠及開發者和終端使用者使用,最近,硅基流動與華為雲合作,推出了基於昇騰雲的 DeepSeek R1 和 V3 推理服務,為使用者提供高效、穩定的 AI 模型推理體驗。
DeepSeek R1 與硅基流動的合作
DeepSeek R1 是一款由強化學習驅動的推理模型,旨在解決模型生成內容的重複性和可讀性問題。在強化學習之前,DeepSeek R1 引入了冷啟動數據,進一步優化推理效能。然而,近期由於 DeepSeek 官方伺服器頻繁出現繁忙狀態,許多使用者在使用時受到限制。
為了解決這一問題,硅基流動與華為雲合作,將 DeepSeek R1 部署在基於昇騰的計算平台上,提供更 穩定、高速 的 DeepSeek R1 API 服務,讓使用者可以在更低的成本下獲得優質的 AI 推理服務。
如何使用 DeepSeek R1 API
使用者可以透過 註冊硅基流動平台,取得 API 金鑰,並將 DeepSeek R1 模型整合到各種應用之中。硅基流動提供了詳細的 技術文件與教學,幫助開發者快速上手,充分發揮 DeepSeek R1 的強大功能。
硅基流動透過與華為雲的合作,成功解決了 DeepSeek R1 在使用過程中的伺服器繁忙問題,為開發者和終端使用者提供了一個 高效、穩定的 AI 模型推理平台。這不僅展現了 硅基流動的技術優勢,也體現了其在推動 AGI 普惠化 方面的努力。
API使用
by Rain Chu | 2 月 23, 2025 | AI, Chat, 模型, 程式開發
Cherry Studio 是一款功能強大的桌面客戶端,可以為使用者提供多模型對話、知識庫管理、AI 繪圖、翻譯等全方位的 AI 助手服務,其高度自訂的設計、強大的擴充能力和友善的使用者體驗,使其成為專業使用者和 AI 愛好者的理想選擇。
核心功能與特色
- 多模型對話支援:Cherry Studio 集成了多種大型語言模型(LLM)服務商,如 OpenAI、Gemini、Anthropic、Azure 等,使用者可以在同一平台上調用不同模型,滿足多樣化需求。
- 豐富的 AI 助手與對話功能:
- 預配置助手:內建超過 300 個行業專用助手,涵蓋翻譯、程式設計、寫作等領域,使用者也可自訂助手。
- 多模型同時對話:支援同一問題通過多個模型同時生成回覆,方便使用者比較不同模型的表現。
- 對話管理:自動分組管理對話記錄,支援對話匯出為多種格式(如 Markdown、PDF 等),便於儲存與分享。
- 文件與資料處理:
- 多格式支援:支援匯入 PDF、DOCX、PPTX、XLSX、TXT、MD 等多種檔案格式,方便使用者建構和查詢專屬知識庫。
- 資料來源多樣性:支援本機檔案、網址、網站地圖甚至手動輸入內容作為知識庫來源。
- 知識庫匯出:處理後的知識庫可匯出並分享給他人使用。
- 實用工具整合:
- AI 繪圖:提供專用繪圖面板,使用者可通過自然語言描述生成高品質圖像。
- 翻譯功能:支援專用翻譯面板、對話翻譯、提示詞翻譯等多種翻譯場景。
- 全域搜尋:快速定位歷史記錄和知識庫內容,提升工作效率。
- 使用者體驗提升:
- 跨平台支援:相容 Windows、macOS 和 Linux 系統,滿足不同使用者的需求。
- 即裝即用:無需複雜的環境配置,下載後即可使用。
- 介面自訂:支援自訂 CSS、對話佈局、頭像和側邊欄選單,打造個性化的使用體驗。
適用場景
- 知識管理與查詢:通過本機知識庫功能,快速建構和查詢專屬知識庫,適用於研究、教育等領域。
- 多模型對話與創作:支援多模型同時對話,幫助使用者快速獲取資訊或生成內容。
- 翻譯與辦公自動化:內建翻譯助手和檔案處理功能,適合需要跨語言交流或文件處理的使用者。
- AI 繪圖與設計:通過自然語言描述生成圖像,滿足創意設計需求。
公開原始碼
近期留言