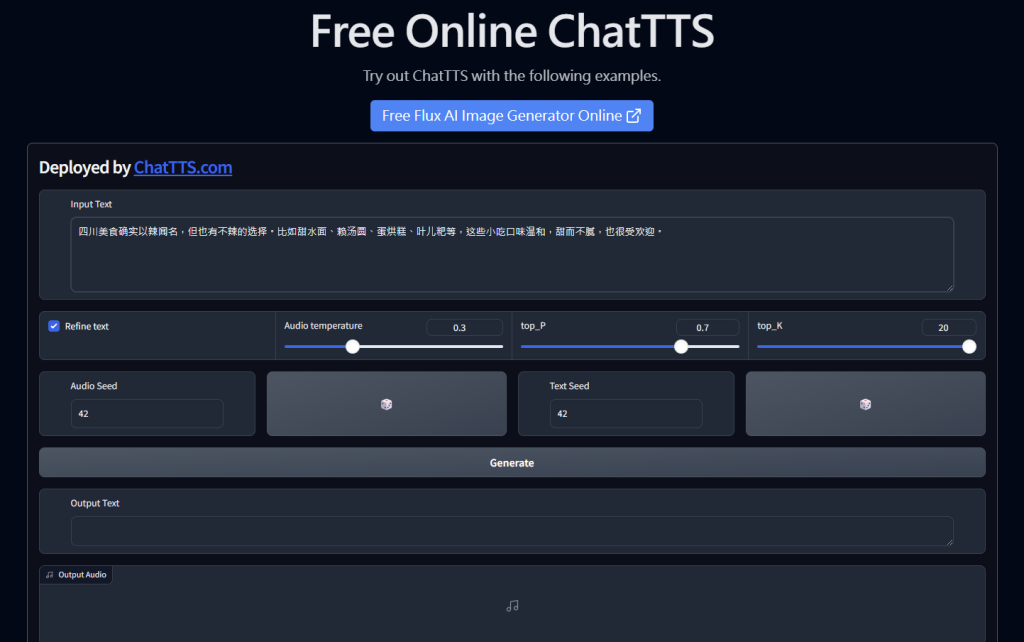
###################################
# Sample a speaker from Gaussian.
rand_spk = chat.sample_random_speaker()
print(rand_spk) # save it for later timbre recovery
params_infer_code = ChatTTS.Chat.InferCodeParams(
spk_emb = rand_spk, # add sampled speaker
temperature = .3, # using custom temperature
top_P = 0.7, # top P decode
top_K = 20, # top K decode
)
###################################
# For sentence level manual control.
# use oral_(0-9), laugh_(0-2), break_(0-7)
# to generate special token in text to synthesize.
params_refine_text = ChatTTS.Chat.RefineTextParams(
prompt='[oral_2][laugh_0][break_6]',
)
wavs = chat.infer(
texts,
params_refine_text=params_refine_text,
params_infer_code=params_infer_code,
)
###################################
# For word level manual control.
text = 'What is [uv_break]your favorite english food?[laugh][lbreak]'
wavs = chat.infer(text, skip_refine_text=True, params_refine_text=params_refine_text, params_infer_code=params_infer_code)
"""
In some versions of torchaudio, the first line works but in other versions, so does the second line.
"""
try:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]).unsqueeze(0), 24000)
except:
torchaudio.save("word_level_output.wav", torch.from_numpy(wavs[0]), 24000)
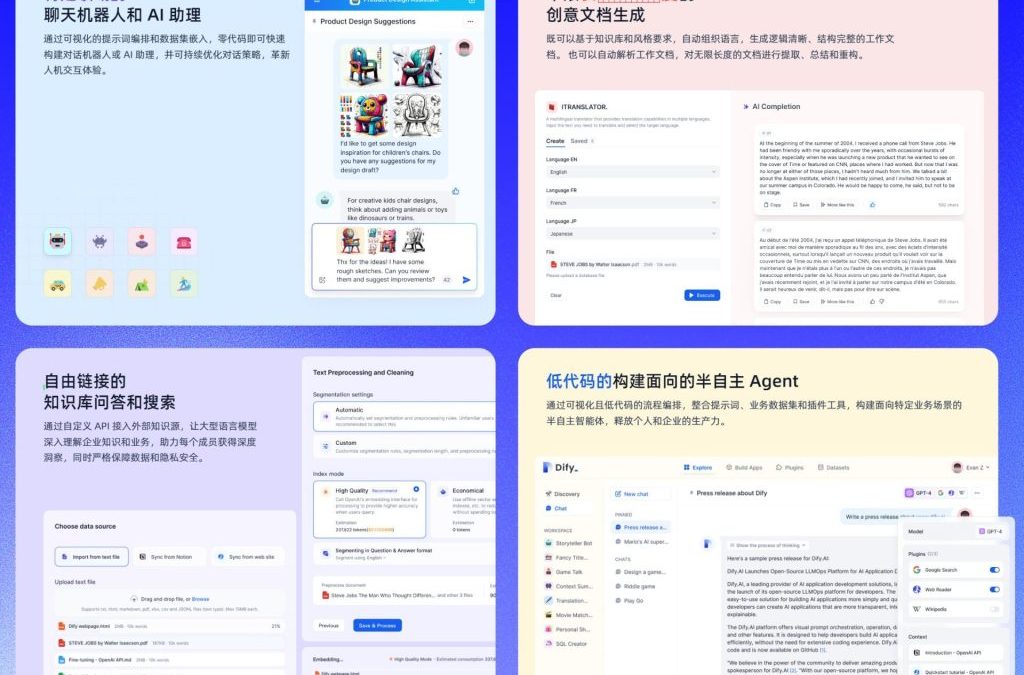
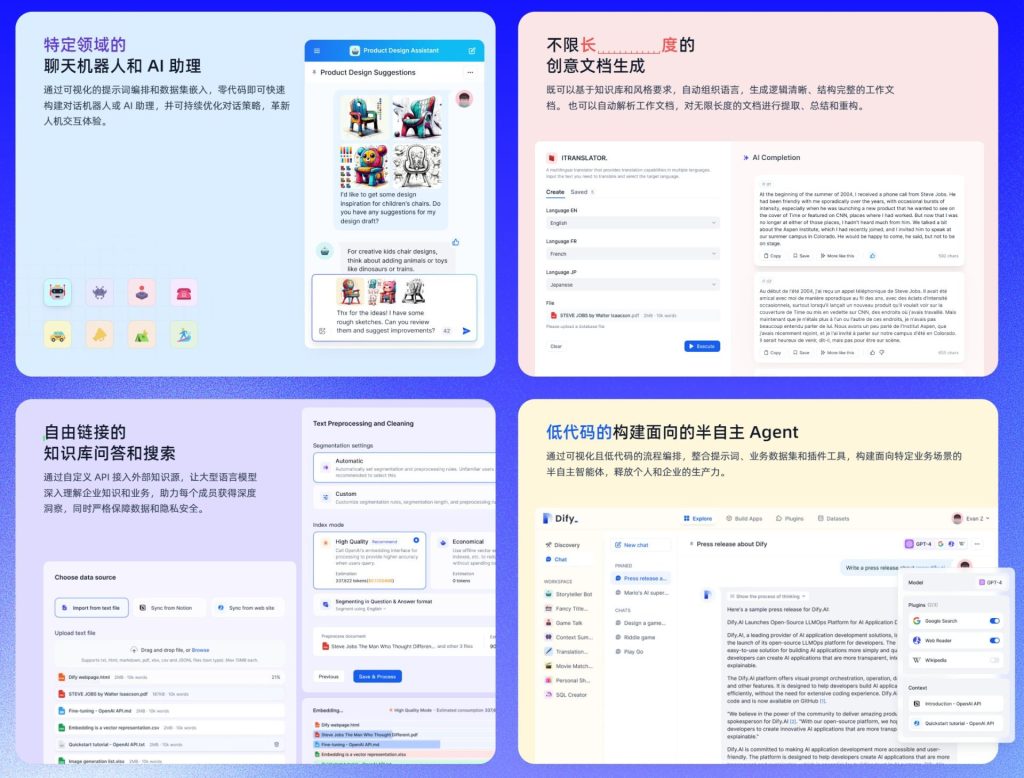
Dify AI 是一個開放靈活的生成式 AI 應用開發框架,提供了一個全方面的解決方案,讓開發者能夠輕鬆構建和運營生成式 AI的 原生應用。平台的核心技術包括 AI 工作流程編排、RAG 檢索、模型管理等功能。Dify AI 支持從 Agent 建立到工作流程編排的完整開發過程,讓使用者可以專注於創造應用的核心價值,此外,它提供的工具包括 Prompt IDE、Enterprise LLMOps 和 BaaS 等解決方案,可以大幅度的提升開發效率並優化應用性能,可以先去Dify的GitHUB看看。
特色介紹
公司內部私有化的知識庫和AI助理:
Dify AI 允許企業將內部知識庫整合到平台中,並創建專屬的AI助理,來高效地管理和利用企業知識。
公司內部可以控管的紀錄:
企業可以通過Dify AI平台對所有操作和數據進行詳細記錄和管控,確保數據安全和合規性。
AI工作流自動化:
Dify AI 提供連結公司內部資訊系統的能力,幫助企業自動化處理各種業務流程,提升運營效率。
零代碼創建 AI Agent:
平台支持用戶在無需編寫代碼的情況下,創建和部署個性化的 AI Agent,滿足各類業務需求。
支持多種大語言模型:
Dify AI 支持全球各種主流的大語言模型(LLM),為企業提供靈活的選擇,以滿足不同場景的應用需求。
開發以及運營的支持
利用 Docker 安裝
先把專案抓下來
git clone https://github.com/langgenius/dify.git
然後可以用下面的指令安裝
cd docker
cp .env.example .env
docker compose up -d
# For Linux and Windows users
python inference.py
# For macOS users with Apple Silicon (Intel is not tested). NOTE: this maybe 20x slower than RTX 4090
PYTORCH_ENABLE_MPS_FALLBACK=1 python inference.py
指令碼
# source input is an image
python inference.py -s assets/examples/source/s9.jpg -d assets/examples/driving/d0.mp4
# source input is a video ✨
python inference.py -s assets/examples/source/s13.mp4 -d assets/examples/driving/d0.mp4
# more options to see
python inference.py -h
超酷的寵物模式
先安裝寵物模式
cd src/utils/dependencies/XPose/models/UniPose/ops
python setup.py build install
cd - # equal to cd ../../../../../../../


近期留言