AI Agent 實戰:用 Chrome 自動操作 + OpenCLI 控制瀏覽器與 Cursor 開發環境
🧠 什麼是 OpenCLI?
OpenCLI 是一個結合 CLI(命令列)+AI Agent+瀏覽器控制能力 的工具。
它讓你可以:
- 用 AI 操作你的瀏覽器(真的操作你的 Chrome)
- 控制本地開發工具(例如 Cursor)
- 串接自訂 Plugin(抓資料、爬網站、整合 API)
👉 簡單來說,它是「本地版 AI Agent 作業系統」
🧠 核心組件說明
1️⃣ Runtime(最重要)
OpenCLI 本體負責:
- 任務調度
- 指令解析
- Plugin 呼叫
- 狀態管理
👉 類似:
- LangChain Agent Executor
- 或 AutoGPT 的 runtime
2️⃣ Plugin Adapter(YAML)
👉 這是 OpenCLI 最強的地方之一
你可以:
- 把網站轉成 CLI
- 定義資料抓取規則
- 建立 AI 工具鏈
📌 重點:
👉 不是寫程式,而是寫 YAML
3️⃣ Browser Bridge(關鍵黑科技)
OpenCLI 不是用 Selenium
👉 而是:
- Playwright MCP bridge
- Chrome DevTools Protocol(CDP)
👉 直接控制「你正在用的瀏覽器」
4️⃣ Channel / Gateway
負責:
- AI ↔ 工具 溝通
- 多工具整合
- 跨平台控制
⚡ 核心特色
1️⃣ 直接使用你的 Chrome(含登入狀態)
OpenCLI 最大的優勢之一:
👉 直接控制你正在使用的 Chrome
這代表:
- ✅ 可以使用已登入的帳號(Google、FB、銀行等)
- ✅ 可以存取 cookies / session
- ✅ 不需要重新登入
背後技術是:
👉 Chrome DevTools Protocol(CDP) ( opencli chrome外掛)
這比 Selenium 強的地方在於:
- 更快
- 更貼近真實使用者
- 可操作現有視窗
2️⃣ 控制 Cursor 寫程式(AI 自動開發)
Cursor 是目前非常強的 AI 編輯器,而 OpenCLI 可以直接操控它 👇
🛠️ 設定方式
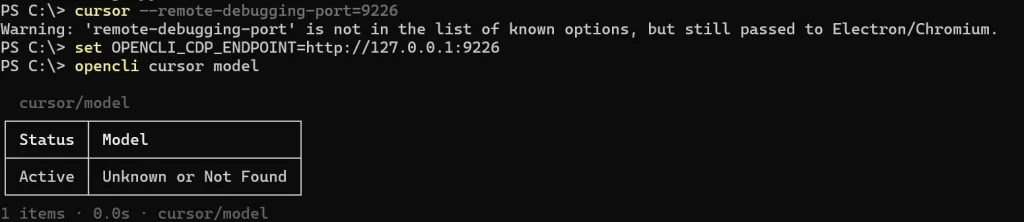
Step 1:啟動 Cursor Debug 模式
cursor --remote-debugging-port=9226
⚠️ 注意:
- 視窗 不能關閉
- 這會開啟 CDP 讓 OpenCLI 控制
Step 2:設定環境變數
mac or linux
export OPENCLI_CDP_ENDPOINT="http://127.0.0.1:9226"
windows 版本
set OPENCLI_CDP_ENDPOINT=http://127.0.0.1:9226
Step 3:測試是否成功
opencli cursor model
Step 4:讓 AI 寫程式
opencli cursor send "新增一個 readme.txt"
👉 OpenCLI 會直接:
- 操控 Cursor
- 建立檔案
- 寫入內容
🔥 實際應用場景
- 自動生成專案 README
- 批次修改程式碼
- 自動補齊文件
- AI Refactor 專案
👉 等於你有一個「真的會操作 IDE 的 AI 工程師」
3️⃣ 自訂 Plugin Adapter(YAML 抓網站)
OpenCLI 支援自訂 Plugin,透過 YAML 定義資料來源 👇
🧩 範例概念
name: fetch_news
description: 抓取新聞網站資料request:
url: https://example.com/news
method: GETparse:
type: html
selectors:
title: h1.title
content: div.article
👉 你可以做到:
- 抓網站資料
- 做 ETL pipeline
- 整合 API
- 建立 AI 工具鏈
📦 安裝 OpenCLI
官方資源:
- GitHub:GitHub 上的 opencli repo
- npm 套件:
@jackwener/opencli
npm install -g @jackwener/opencli
安裝 OpenCLI Chorm extension
https://github.com/jackwener/opencli/releases
解壓縮後放到 chrome 的擴充套件中
檢查安裝狀態
opencli doctor
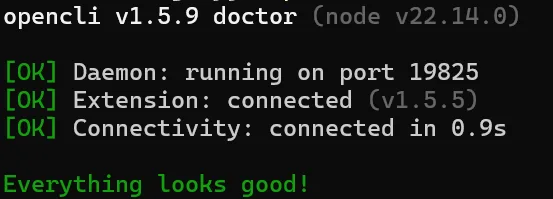
看到上面的資訊就代表成功
可以測試用自己的帳號去查 B 站的最熱門影片了
opencli bilibili hot –limit 5

⚡ 三大核心能力
🔥 1. 把任何網站變 CLI
👉 這是 OpenCLI 最核心功能
例如:
opencli hackernews top
opencli twitter mentions
opencli gmail read
背後:
- YAML 定義
- AI 自動操作頁面
🔥 2. 直接用你 Chrome(含登入)
👉 這點非常關鍵(你前面有用到)
OpenCLI:
- 不模擬登入
- 不存 cookie
- 不重建 session
👉 直接用你 Chrome 裡的登入狀態
🔥 這代表什麼?
你可以:
- 操作 Gmail
- 操作 FB / IG
- 操作內部系統(SSO)
👉 完全不像傳統爬蟲
🔥 3. 控制本地工具(Cursor / VSCode)
👉 這才是 AI Agent 真正關鍵
OpenCLI 可以:
- 控制 Cursor
- 控制 CLI
- 操作本機檔案
👉 等於:
AI 可以「真的幫你寫程式」
🧪 真實應用場景
📌 1. 自動收集資訊
👉 每天做:
- 抓新聞
- 抓 Reddit
- 抓競品資料
📌 2. 自動寫程式
👉 例如:
opencli cursor send "建立 flask API"
📌 3. 自動操作後台
👉 例如:
- WordPress 發文
- Cloud Console 操作
- CRM 系統
📌 4. 自動化工作流
👉 一句話:
👉「抓資料 → 分析 → 寫報告 → 存檔」
📱 延伸:手機 + Termux + OpenCLI
Termux + Android 手機也可以跑:
👉 搭配:
- OpenClaw
- OpenCLI
可以做到:
- 行動 AI Agent
- 手機自動操作
- 遠端開發
⚠️ 注意事項
🔒 安全性
因為它可以:
- 操控你的 Chrome
- 使用你的登入狀態
👉 建議:
- 不要開放外網
- 使用本機環境
- 控制權限
⚙️ 穩定性
- CDP port 被占用會失敗
- Cursor 視窗關閉會斷線
- Plugin YAML 要寫正確
🎯 總結
OpenCLI 的本質不是工具,而是:👉 AI 的「手」
👉 AI 操作你電腦的入口
它讓你可以:
- 🧠 用 AI 控制瀏覽器
- 💻 用 AI 操作 IDE(Cursor)
- 🔗 串接任何資料來源(Plugin)
🧠 AI 能力分層
| 層級 | 能力 |
|---|---|
| LLM | 思考 |
| LangChain | 決策 |
| OpenCLI | 行動 |
👉 沒有 OpenCLI:
👉 AI 只能「講」
👉 有 OpenCLI:
👉 AI 才能「做」
近期留言