by Rain Chu | 5 月 13, 2026 | AI, Ollama, 模型
最新的 Qwen 3.6,在 Ollama 上的表現,可以說是目前「本地 Coding 模型」中非常強勢的一個系列。
如果你正在使用:
- NVIDIA Spark
- RTX 顯卡
- Ollama
- OpenWebUI
- Continue
- Claude Code
- OpenHands
- Hermes Agent
- Cursor 類工具
- Apple
那麼 Qwen 3.6 幾乎一定值得研究。
這篇文章會完整解析:
- Qwen 3.6 每個版本差異
- 27B 與 35B 的差異
- MXFP8、NVFP4、BF16 是什麼
- 哪個最適合寫程式
- NVIDIA Spark 最推薦的配置
- Ollama 部署建議
- 多人 SaaS / AI Agent 最佳實務
什麼是 Qwen 3.6?
Qwen 是阿里巴巴推出的大型語言模型(LLM)系列。
最新的 Qwen 3.6,官方特別強調:
- Agentic Coding
- Repository-level Reasoning
- 長 Context 推理
- Thinking Preservation
也就是說:
它不只是會寫程式,而是開始能理解「整個專案」。
根據官方與 Ollama 頁面資訊,Qwen 3.6 在以下方面有明顯提升:
- 前端工作流理解
- 多檔案推理
- AI Agent Tool Calling
- 長上下文理解
- 歷史推理保留
- Repository 級別程式分析
為什麼 Qwen 3.6 很適合 Ollama?
Qwen 3.6 最大特色之一:
就是對本地部署非常友善。
目前 Ollama 已提供大量版本:
- 27B
- 35B-A3B
- Coding 版本
- Vision 版本
- MXFP8
- NVFP4
- BF16
- MLX
而且幾乎都支援:
- 256K Context
- 長文本推理
- 本地 AI Agent
- Coding Workflow
Qwen 3.6 各版本意思解析
qwen3.6:latest
這是官方最新預設版本。
特色:
適合:
但:
不是最強的 Coding 版本。
qwen3.6:27b
27B = 270億參數。
這是目前非常熱門的甜蜜點。
優點:
- Coding 能力很強
- 推理速度快
- VRAM 壓力較低
- 多人共享容易
非常適合:
- Continue
- Claude Code
- VSCode AI
- Agent Workflow
- 本地 Copilot
qwen3.6:35b
35B = 350億參數。
這類模型:
推理能力更強。
尤其在:
- 大型專案理解
- 架構設計
- Refactor
- 多檔案分析
會比 27B 更好。
但缺點:
什麼是 Coding 版本?
例如:
- qwen3.6:27b-coding-mxfp8
- qwen3.6:35b-a3b-coding-nvfp4
這些是:
專門針對寫程式優化的模型。
相較一般聊天模型:
它們更擅長:
- Python
- TypeScript
- Go
- Rust
- Docker
- Shell
- Kubernetes
- Debug
- Refactor
- AI Agent Tool Calling
官方也特別提到:
Qwen 3.6 在 Agentic Coding 與 Repository-level reasoning 上有大幅提升。
MXFP8、NVFP4、BF16 是什麼?
很多人看到:
會很混亂。
其實這些都是:
「量化格式」。
MXFP8
例如:
qwen3.6:27b-coding-mxfp8
這是 NVIDIA 新世代 FP8 格式。
特色:
- 品質高
- VRAM 使用合理
- 推理速度快
- 非常適合 NVIDIA GPU
目前很多人認為:
MXFP8 是本地 AI Coding 的最佳甜蜜點。
尤其適合:
- NVIDIA Spark
- RTX 4090
- RTX 5090
- 多 Agent Workflow
NVFP4
例如:
qwen3.6:27b-coding-nvfp4
這是 NVIDIA 的 4-bit 浮點量化格式。
特色:
但:
推理品質會稍微下降。
比較適合:
- SaaS 平台
- 多人 AI IDE
- 高併發 Agent
目前學術研究也開始針對 NVFP4 做最佳化。
BF16
例如:
qwen3.6:27b-coding-bf16
這幾乎是:
接近原始精度。
優點:
- 品質最高
- reasoning 最穩
- hallucination 較少
缺點:
適合:
MLX 是什麼?
MLX 是 Apple Silicon 專用。
例如:
什麼是 A3B?
例如:
qwen3.6:35b-a3b-coding-mxfp8
這代表:
MoE(Mixture of Experts)架構。
意思是:
模型總參數很大,但每次只啟用部分專家。
優點:
官方指出:
Qwen3.6-35B-A3B 僅啟動約 3B Active Parameters,但依然能超越部分大型 Dense 模型。
NVIDIA Spark 最推薦哪個?
如果你的環境是:
- NVIDIA Spark
- CUDA 13
- 128GB RAM
- Ollama
- OpenWebUI
- Continue
- Claude Code
- OpenHands
那我目前最推薦:
🥇 最推薦:qwen3.6:27b-coding-mxfp8
推薦原因:
- Coding 非常強
- 推理速度快
- VRAM 不容易爆
- Agent 很穩
- 長 Context 表現好
- 本地部署平衡最佳
這是目前真正的:
「Production Sweet Spot」。
🥈 高階推理推薦:qwen3.6:35b-a3b-coding-mxfp8
適合:
- AI Agent
- 大型專案
- 架構設計
- 多 Repo 分析
優點:
- reasoning 更強
- repository 理解更強
- 複雜任務更穩
缺點:
🥉 多人 SaaS 推薦:qwen3.6:27b-coding-nvfp4
適合:
- 多人共享
- SaaS
- AI IDE
- 高併發 Agent
優點:
但:
品質會略低於 MXFP8。
我自己的實戰看法
如果你是:
「真正要拿來工作」。
我目前認為:
Qwen 3.6 已經開始接近:
「本地版 Claude Code」。
尤其:
27B Coding MXFP8。
真的已經非常強。
它最大的優勢不是單純寫程式。
而是:
- 能理解整個 Repo
- 能做 Agent 工作流
- 能做長 Context reasoning
- 能做 Tool Calling
- 能理解大型專案
這跟以前單純「補程式碼」的模型完全不同。
Ollama 部署建議
安裝模型
ollama pull qwen3.6:27b-coding-mxfp8
執行模型
ollama run qwen3.6:27b-coding-mxfp8
開放 API
export OLLAMA_HOST=0.0.0.0:11434
NVIDIA Spark 最佳化建議
建議環境變數:
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_NUM_PARALLEL=4"
Environment="OLLAMA_MAX_LOADED_MODELS=3"
Environment="OLLAMA_MAX_QUEUE=1024"
Environment="OLLAMA_KEEP_ALIVE=-1"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
Environment="OMP_NUM_THREADS=32"
適合搭配的工具
Qwen 3.6 很適合:
- Continue
- Claude Code
- OpenHands
- Hermes Agent
- OpenWebUI
- Cursor 類工具
- Browser-use
- AI Agent Workflow
結論
如果你現在想打造:
- 本地 AI Coding 環境
- AI Agent 平台
- 多人 AI IDE
- 本地 Claude Code
- Ollama SaaS
那麼:
Qwen 3.6 幾乎是目前最值得研究的一條路。
尤其:
qwen3.6:27b-coding-mxfp8
我認為:
這是目前 NVIDIA Spark 上:
最平衡、最實用、最值得長期使用的本地 Coding 模型之一。
參考資料
by Rain Chu | 4 月 29, 2026 | AI, Ollama, 模型
🧱 直接給「滿血設定」
你現在 service 改成這個👇(最重要)
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3# ===== 核心 =====
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_KEEP_ALIVE=-1"# ===== GPU 強制 =====
Environment="OLLAMA_GPU_LAYERS=999"# ===== 記憶體優化 =====
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
Environment="OLLAMA_FLASH_ATTENTION=1"# ===== Spark專用 tuning =====
Environment="OLLAMA_NUM_PARALLEL=2"
Environment="OLLAMA_MAX_LOADED_MODELS=2"
Environment="OLLAMA_MAX_QUEUE=512"# ===== CPU 控制 =====
Environment="OMP_NUM_THREADS=20"# ===== PATH =====
Environment="PATH=/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"[Install]
WantedBy=multi-user.target
🔁 套用
sudo systemctl daemon-reexec
sudo systemctl daemon-reload
sudo systemctl restart ollama
🔍 一定要做驗證
systemctl show ollama | grep OLLAMA
👉 要看到全部變數
🧠 模型才是性能關鍵
🔥 Spark 正確用法
| 用途 | 模型 |
|---|
| 最快 | llama3:8b |
| 平衡 | llama3:13b |
| 大模型 | 30B(單一) |
✅ 先做這個測試(非常重要)
ollama run llama3
👉 再看:
nvidia-smi
🔥 讓 GPU 真的滿血(關鍵3件事)
① 模型「完全進 GPU」
👉 關鍵判斷:
ollama ps
看到:
100% GPU
👉 才算成功
② context 不要亂開
👉 Ollama 預設 4096
👉 你如果開到:
👉 = 直接 CPU fallback
👉 建議:
ollama run llama3 --num_ctx 4096
③ 不要多模型併發
Spark 特性:
👉 記憶體大,但 bandwidth 普通
👉 所以:
OLLAMA_NUM_PARALLEL=2
是最佳解
🧠 Spark 的本質
👉 DGX Spark:
- 128GB memory ✔
- 超大模型可跑 ✔
- ❌ 不是高吞吐 GPU
👉 正確定位:
🔥 大模型單機推理機
🧪 接下就會看到的改善
調完後:
| 指標 | 改善 |
|---|
| GPU Util | 0% → 80%+ |
| token/sec | ↑ 3~10倍 |
| latency | ↓ 50%以上 |
| CPU | ↓ |
🎯 注意事項
👉 ❗不要讓使用者直接打 Ollama
by Rain Chu | 4 月 24, 2026 | Agent, AI, Microsoft, Tool
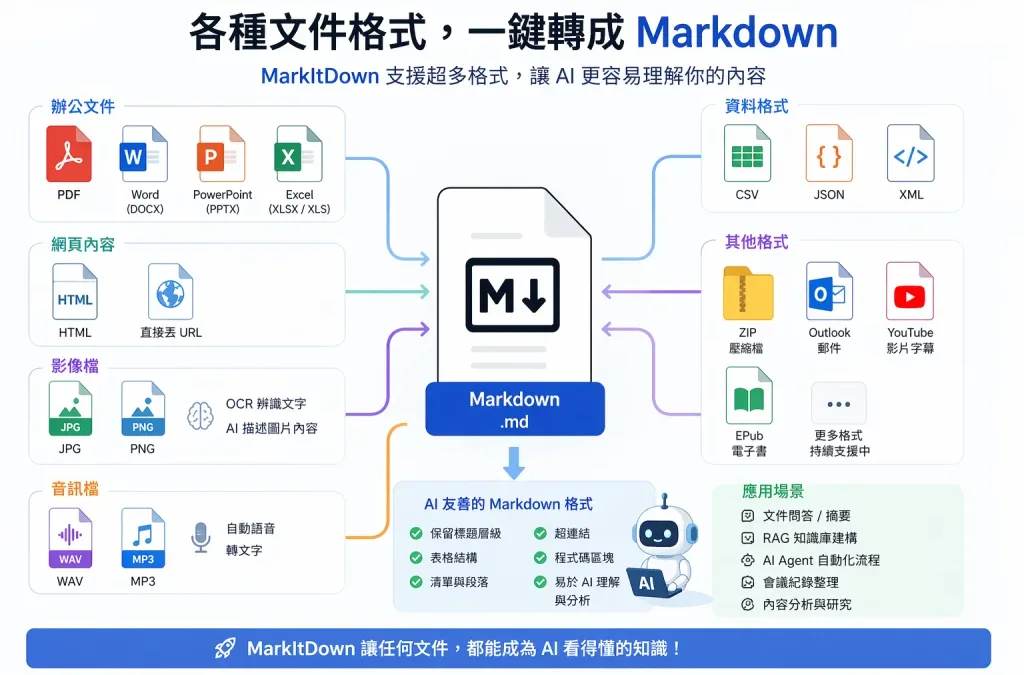
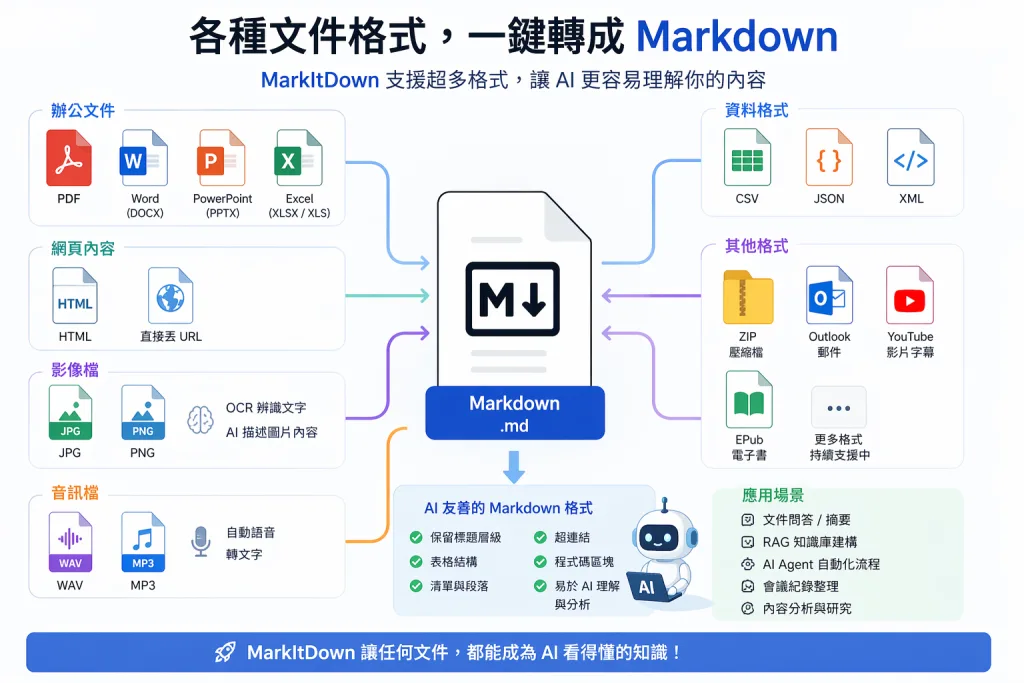
在 AI 時代,「讓 AI 看懂文件」變成一個非常關鍵的能力,但現實世界的資料格式五花八門,從 PDF、Word 到 PPT、甚至影片與音訊,這些內容對 AI 來說其實並不好直接處理。
這時候,MarkItDown 就成為一把真正的「文件瑞士刀」。
由 Microsoft 開源推出,MarkItDown 能將各種格式的檔案,一鍵轉換成乾淨、結構化、AI 友善的 Markdown,讓 ChatGPT、Claude 或各種 AI Agent 能輕鬆理解與分析。
你只要把 https://github.com/microsoft/markitdown 網址貼給 agent ,請他安裝就可以了
🚀 為什麼 MarkItDown 這麼強?
MarkItDown 最大的優勢只有一句話:
👉 幾乎什麼格式都能轉,而且還轉得漂亮
📂 支援格式(強到誇張)
🧾 辦公文件
- PDF
- Word(DOCX)
- PowerPoint(PPTX)
- Excel(XLSX / XLS)
🌐 網頁內容
🖼️ 影像檔
- JPG / PNG
- 支援 OCR 文字辨識
- 可搭配 AI 產生圖片描述
🎧 音訊檔
- WAV / MP3
- 自動語音轉文字(Speech-to-Text)
📊 資料格式
📦 其他進階格式
- ZIP(自動解壓並轉換)
- Outlook 郵件
- YouTube(自動擷取字幕)
- EPub 電子書
✨ 不只是轉檔,而是「結構理解」
很多轉檔工具的問題是:
👉 轉出來變成一坨純文字(完全不能用)
但 MarkItDown 不一樣,它會:
- 保留標題層級(# ## ###)
- 還原表格結構
- 保留清單與段落
- 維持超連結
👉 轉出來就是 AI 可以直接理解的 Markdown 結構
這對以下應用非常關鍵:
- RAG(檢索增強生成)
- AI 文件摘要
- Agent 自動閱讀文件
⚡ 安裝與使用(超簡單)
安裝
pip install "markitdown[all]"
👉 如果只需要特定格式:
pip install "markitdown[pdf,docx,pptx]"
CLI 使用
markitdown 報告.pdf -o 報告.md
Python 使用
from markitdown import MarkItDownmd = MarkItDown()
result = md.convert("文件.docx")print(result.markdown)
👉 幾行程式碼就搞定
🤖 搭配 AI:威力直接翻倍
MarkItDown 真正強的地方,是它「原生為 AI 設計」。
🧠 AI 圖片理解
- 可串接 OpenAI 視覺模型
- 自動產生圖片描述
- 讓 AI 看懂圖片內容
🔍 OCR 文字辨識
- 整合 Azure Document Intelligence
- 可讀取掃描 PDF / 圖片文字
🔌 MCP(Model Context Protocol)整合
- 可直接接入 Claude Desktop
- 或各種 AI Agent 系統
👉 這點對在做 AI Agent / LangChain / 自動化流程 特別重要
🧩 外掛系統
📌 實際應用場景
1️⃣ 餵 AI 吃文件(超省 Token)
👉 先轉 Markdown,再丟 AI
效果:
- Token 減少最多可達 80%
- AI 理解更準確
2️⃣ 建構企業知識庫(RAG)
流程:
文件 → MarkItDown → Markdown → Embedding → Vector DB
👉 完整 AI 知識庫 pipeline
3️⃣ AI Agent 文件閱讀能力
在你的 Agent 流程中加入:
文件 → MarkItDown → LLM 分析
👉 Agent 直接具備「讀文件能力」
4️⃣ 會議紀錄自動化
錄音 → 轉文字 → Markdown → AI整理
👉 自動產出結構化會議紀錄
⚠️ 不是萬能
MarkItDown 雖然強,但有幾個限制:
- 複雜圖表(Chart / Graph)解析較弱
- 高度排版文件可能失真
- 不適合做「高保真排版還原」
👉 如果你要的是「完美排版還原」
建議用:
👉 Pandoc
👉 如果你要的是「讓 AI 看懂」
👉 MarkItDown 完勝
🧠 結論:AI 時代的文件標準工具
MarkItDown 解決了一個非常關鍵但常被忽略的問題:
👉 AI 看不懂文件格式
它的價值在於:
- ✅ 超廣格式支援
- ✅ 保留結構(不是純文字)
- ✅ 原生為 AI 設計
- ✅ 可整合 Agent / RAG / 自動化流程
- ✅ 免費開源
👉 如果你正在做:
- AI Agent
- 文件分析
- 自動化流程
- 知識庫建構
MarkItDown 是 AI Agent 必裝工具。
by Rain Chu | 4 月 24, 2026 | AI, 影片製作
🎬 前言:影音生成進入新紀元
在 AI 生成技術快速進化的浪潮中,影音生成(Video Generation)一直是最具挑戰的領域之一,近期阿里巴巴推出全新開源模型 Happy Horse 1.0,不僅一舉登上視訊生成排行榜首,更以「原生音視訊同步」技術引發業界關注。
這不只是一次模型更新,而是一場技術架構的全面升級。
🧠 技術突破:原生音視訊同步與統一架構
過去的影音生成模型,多數採用「先產畫面、再加聲音」的分離式流程,導致以下問題:
- 聲音與畫面不同步
- 情緒與語境不一致
- 動作與語音對不上(例如嘴型錯誤)
而 Happy Horse 1.0 的最大突破在於:
✅ 原生音視訊同步(Native Audio-Visual Generation)
模型在同一個架構中,同步生成:
👉 這代表:
- 嘴型、語氣、動作可以完全對齊
- 情境更自然、沉浸感更強
✅ 統一生成架構(Unified Architecture)
傳統模型:
Text → Image → Video → Audio
Happy Horse:
Text → Audio + Video(同步生成)
👉 好處:
🌍 開源策略:直接撼動產業格局
這次阿里的另一個關鍵策略是——全面開源。
在目前市場上,多數高品質影音模型(如某些閉源模型)仍然:
而 Happy Horse 1.0:
🔓 開源帶來的優勢
- 可自行部署(企業私有化)
- 可進行 fine-tune
- 可整合到自家 SaaS / Agent 系統
- 大幅降低成本
👉 對你這種正在做:
- AI Agent
- SaaS 平台(像 OpenClaw / Hermes)
- 影音生成服務
這其實是「直接可商用的關鍵拼圖」。
🧪 實測對比:各有所長,但方向已定
從目前社群與測試結果來看,Happy Horse 1.0 與其他主流模型相比:
🎥 優勢
- 音畫同步表現極佳(領先)
- 人物口型與語音一致性高
- 長影片穩定性提升
⚖️ 相對限制
- 某些細節畫質仍有進步空間
- 複雜場景(多人物)仍需優化
- 訓練與硬體需求較高
👉 結論不是「全面碾壓」,而是:
在「影音同步」這個核心維度上,已經領先一個世代。
🧩 對開發者的實際影響(重點)
如果你是開發者或創業者,這代表什麼?
💡 你現在可以做:
- AI 影片生成 SaaS(類似 Runway / Pika)
- AI 虛擬人(帶語音與表情同步)
- 自動短影音生成(TikTok / 房仲 / 行銷)
- AI 教學影片生成
👉 Happy Horse 可以直接變成:
Agent → 呼叫影音生成 API → 自動產影片
甚至可以做到:
- 「用一句話生成完整短影音廣告」
- 「AI 自動生成房仲介紹影片」
🏗️ 未來趨勢:影音生成將取代文字生成?
目前 AI 發展路線:
- 文字生成(GPT)
- 圖像生成(Stable Diffusion)
- 影音生成(下一戰場)
而 Happy Horse 代表:
🔥「影音生成正式進入可商用時代」
未來很可能出現:
- AI 直接生成 YouTube 影片
- 無人製作的短影音工廠
- AI 自動做內容變現
📦 官方資源

by Rain Chu | 4 月 24, 2026 | Agent, AI
在過去,AI 只是工具
現在,AI 正在變成你的「員工」
而未來,你的團隊中——
真正工作的,可能不再是人類
🧠 什麼是 Multica?

Multica 是一個開源的 Managed Agents(智能體管理)平台,核心概念非常直接:
把 AI 編碼 Agent,變成真正的「隊友」
不像傳統 AI 工具需要你手動下 prompt、盯著結果,
Multica 讓 AI:
- 自己接任務
- 自己執行工作
- 自己回報進度
- 自己累積能力
👉 就像你真的聘請了一個工程師。
根據官方說明,它的目標是打造「人類 + AI 的混合團隊」基礎設施。
💥 核心理念:AI 不再是工具,而是「員工」
傳統 AI:
Multica 的 AI:
👉 這是從「工具」到「組織角色」的巨大轉變。
⚙️ Multica 的核心功能
1️⃣ Agent 即隊友
你可以像在 Jira 或 Linear 一樣:
- 指派任務給 AI
- AI 會自動認領
- 在看板上更新進度
- 主動回報問題
👉 AI 成為專案管理的一等公民
2️⃣ 全自動任務執行
AI 會:
- 排隊 → 接任務 → 執行 → 完成 / 失敗
- 全程自動運作
- 即時回報進度(WebSocket)
👉 不需要再「盯著 AI 跑」
3️⃣ 技能累積(最關鍵)
每一次任務:
➡️ 都會變成「可重用技能」
例如:
- 部署流程
- DB migration
- Code review
👉 團隊能力會「越用越強」
4️⃣ 多 Agent 協作
你可以同時:
- 跑 10 個 AI 任務
- 多個 Agent 協同工作
- 平行處理專案
👉 等於一個 AI 工程團隊
5️⃣ 統一運行與算力管理
- 本地 + 雲端 runtime
- 自動偵測 CLI 工具
- 統一控制台管理
👉 不用自己拼基礎設施
🧩 為什麼這件事重要?
現在 AI 最大的問題是:
- 每個人用自己的 Agent
- 知識無法共享
- 工作流程碎片化
Multica 解決的是:
👉 AI 協作的「組織問題」
它讓:
👉 這就是「AI 組織化」的開始
🏢 這其實是「AI HR 系統」
如果用一句話形容:
Multica = AI 員工管理系統
它提供:
- 任務分配(像 HR)
- 進度追蹤(像 PM)
- 能力累積(像培訓系統)
👉 AI 不只是會做事,還會「成長」
🔮 未來趨勢:公司將變成「人類 + AI 混合組織」
你可以想像未來公司長這樣:
| 類型 | 角色 |
|---|
| 人類 | 決策 / 創意 / 策略 |
| AI Agent | 開發 / 測試 / 自動化 / 文書 |
甚至:
- 一個人帶 10 個 AI 工程師
- 一個團隊管理 100 個 Agent
👉 生產力直接提升 10 倍(甚至更多)
⚔️ Multica vs 傳統 AI 工具
| 比較 | 傳統 AI | Multica |
|---|
| 使用方式 | Prompt | 任務分配 |
| 工作模式 | 單次互動 | 長時間運行 |
| 協作 | 無 | 多 Agent |
| 記憶 | 無 | 技能累積 |
| 管理 | 人盯 | 自動化 |
👉 本質差異:
工具 → 組織系統
🧠 結論:你該開始思考的事
這不是未來,而是現在正在發生的事。
by Rain Chu | 4 月 18, 2026 | AI, 語音合成
🧠 什麼是 VoxCPM?
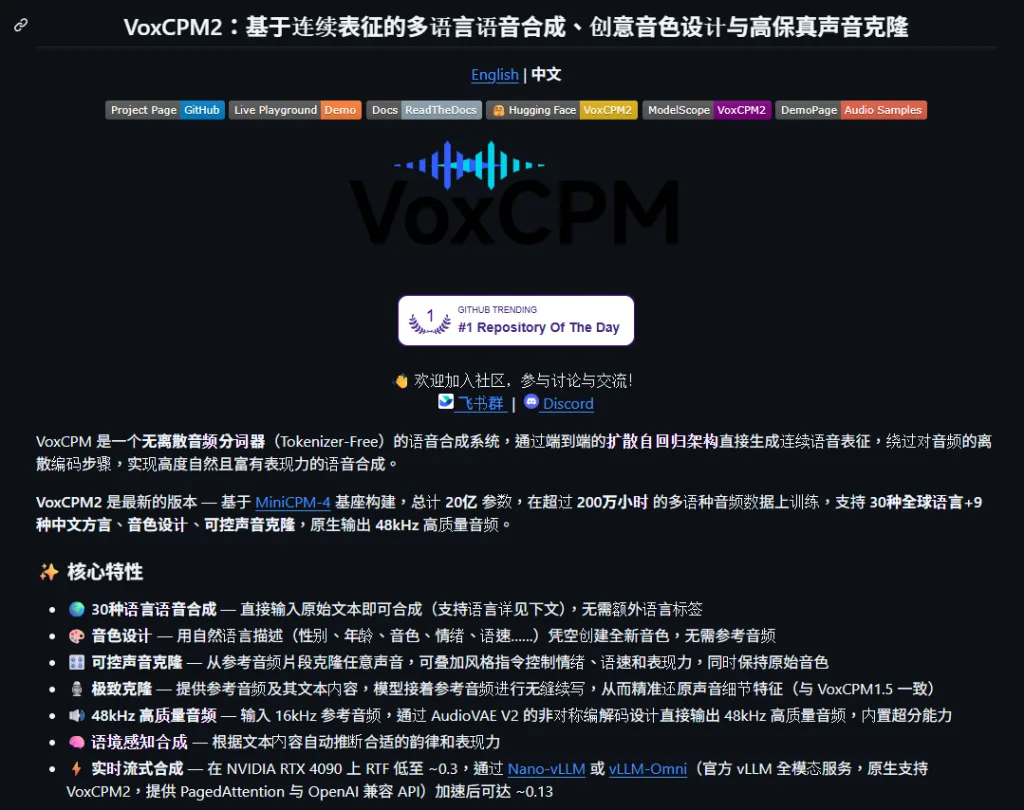
VoxCPM 是由 OpenBMB 推出的新一代語音生成模型,主打:
👉 超低樣本聲音克隆(只需5秒)
👉 完全本地運行(無需雲端)
👉 多語言+多方言支持(30+)
簡單講一句話:
👉 它就是「語音界的 Stable Diffusion」
🚀 核心特色
🎙️ 1️⃣ 極致聲音複製(5秒搞定)
只需要一段短短語音(約5秒):
👉 幾乎達到「真人等級」
🎚️ 2️⃣ 專業播音員等級輸出
生成語音具備:
- 清晰度高(接近錄音室品質)
- 節奏自然
- 可長文本生成(Podcast / 有聲書)
👉 可直接商用(需注意授權)
🌏 3️⃣ 多語言+方言(重點)
支援:
- 中文(普通話)
- 台語(閩南語)
- 廣東話
- 四川話
- 英文 / 日文 / 韓文 等
👉 這點直接屌打很多 TTS 工具
🔒 4️⃣ 完全本地運行
不像:
- ElevenLabs(雲端)
- PlayHT(雲端)
VoxCPM:
✅ 無需上傳聲音
✅ 不怕資料外洩
✅ 無 API 費用
⚙️ 安裝教學(本地部署)
📦 硬體需求(建議)
- GPU:RTX 3060 以上(最佳)
- RAM:16GB+
- OS:Ubuntu / Windows(WSL)
🧩 Step 1:下載專案
官方 Repo👇
👉 VoxCPM GitHub repository
🧩 Step 2:安裝環境
🧩 Step 3:下載模型
依照 repo 指示下載:
🧩 Step 4:執行推理
🧩 Step 5:使用WEBUI
# WebUI
python lora_ft_webui.py # http://localhost:7860
🧠 進階玩法(你可以做什麼)
💰 商業應用
- AI 配音 SaaS
- 有聲書生成平台
- YouTube 自動旁白
🧪 高階玩法
- 聲音角色庫(多人 voice profile)
- Telegram 語音 Bot
- 客製客服語音
⚠️ 注意事項(很重要)
⚙️ 技術限制
🆚 VoxCPM vs 其他 TTS
| 工具 | 本地 | 聲音克隆 | 方言 | 成本 |
|---|
| VoxCPM | ✅ | ✅ | ✅ | 免費 |
| ElevenLabs | ❌ | ✅ | 普通 | $$$ |
| PlayHT | ❌ | ✅ | 普通 | $$$ |
👉 結論:
本地部署 = VoxCPM 完勝
參考資料
官方網站
移除背景聲音工具(UVR5)
近期留言