AI 不再失憶!Rowboat 如何用知識圖譜打造真正會記住你的 AI 助理
覺得 AI 助理總是問一次忘一次?這次不一樣 Rowboat 深度解析
你應該也遇過這種情況:
👉 跟 AI 聊了一堆專案細節
👉 隔天再問,它完全忘光
這不是你錯,是目前大多數 AI 的「設計限制」。
但現在,有一個專案正在顛覆這件事 —— Rowboat
它的目標不是做一個聊天機器人,而是:
✅ 一個「有長期記憶」的 AI 數位同事
✅ 一個能理解你工作脈絡的 AI Agent
✅ 一個真正能幫你處理工作的系統
🚀 Rowboat 是什麼?
Rowboat 是一個 Local-First 的 AI Agent 系統,核心概念很簡單但非常關鍵:
👉 AI 不應該只靠 prompt,而應該有「記憶系統」
它的架構結合了:
- 本地資料存儲
- 知識圖譜(Knowledge Graph)
- Markdown-based 知識庫
- AI 任務自動化
👉 簡單講:它讓 AI 變成「真的記得事情的人」
🎥 Rowboat 實際運作
這支影片展示了 Rowboat 如何:
- 自動整理資訊
- 建立關聯
- 持續累積記憶
- 協助日常工作
🏗️ 核心特色一:Local-First 架構(真正的資料主權)
🔐 為什麼 Local-First 很重要?
傳統 AI:
- 資料在雲端
- 無法控制
- 有隱私風險
Rowboat:
👉 所有資料存在你的電腦裡
這帶來幾個關鍵優勢:
✅ 完全資料掌控
- 不怕資料外洩
- 不依賴第三方平台
✅ 可離線運作(搭配本地模型)
- 可整合 Ollama
- 建立完全私有 AI 系統
✅ 適合企業 / 敏感資料
- 客戶資料
- 專案文件
- 財務資料
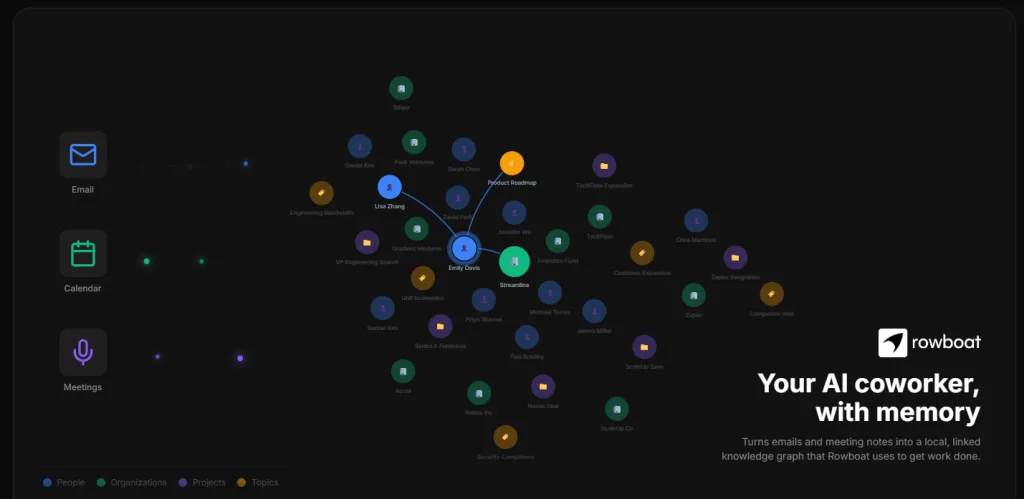
🧩 核心特色二:知識圖譜(AI 長期記憶的核心)
Rowboat 最大的突破在這裡:
👉 它不是存資料,而是建立「關係」
📊 傳統 AI vs Rowboat
| 類型 | 記憶方式 |
|---|---|
| ChatGPT | 單次對話 |
| RAG | 文件檢索 |
| Rowboat | 🧠 知識圖譜 |
🧠 知識圖譜能做什麼?
Rowboat 會自動:
- 連結 Email ↔ 人物
- 連結會議 ↔ 專案
- 連結任務 ↔ 文件
- 建立「上下文關係」
例如:
Rain → GCP 專案 → Cloud Run 架構 → WordPress
👉 AI 會「理解脈絡」,不是只找資料
📝 核心特色三:Obsidian 相容(Markdown = 最強知識格式)
Rowboat 選擇一個非常聰明的設計:
👉 用 Markdown 當資料格式
並且相容 Obsidian
💡 為什麼這很重要?
✅ 永遠不被綁架
- 純文字
- 可版本控管(Git)
✅ 可讀可改
- 不需要 UI 也能操作
- 可自動化處理
✅ AI 友善
- 非結構 → 可結構化
- 易於 embedding / parsing
👉 這點比很多 SaaS 工具高級非常多
🤖 核心特色四:數位分身(真正能工作的 AI)
Rowboat 的最終目標:
👉 建立一個「數位分身 AI」
🧪 實際應用場景
🧑💼 1. 會議助理
- 自動整理會議紀錄
- 建立關聯人物
- 產生 follow-up 任務
📂 2. 專案理解
- AI 能回答:
- 這個專案歷史?
- 有哪些決策?
- 誰負責?
📧 3. Email 分析
- 自動分類
- 關聯專案
- 建立知識節點
🧠 4. 個人知識庫
- 技術筆記
- 架構設計(像你 GCP)
- 問題排查紀錄
👉 AI 不只是回答問題,而是「幫你做事」
🆚 Rowboat vs 一般 AI Agent
| 功能 | 一般 Agent | Rowboat |
|---|---|---|
| 記憶 | ❌ 短期 | ✅ 長期 |
| 資料位置 | 雲端 | 本地 |
| 結構 | 無 | 知識圖譜 |
| 控制權 | 低 | 高 |
| 可擴展 | 中 | 高 |
💡Rowboat 的實戰評價
如果你是:
- DevOps / 架構師
- 多專案管理者
- WordPress / GCP 維運
- AI Agent 開發者
👉 Rowboat 很可能是你下一步的「核心系統」
因為它解決一個關鍵問題:
❗ AI 沒有記憶,就永遠只是工具
✅ AI 有記憶,才會變成「同事」
🚀 結論:Rowboat 是 AI 的「第二階段」
第一階段:
👉 ChatGPT(會回答)
第二階段:
👉 Rowboat(會記住 + 會做事)
未來:
👉 每個人都會有一個「數位分身 AI」
而 Rowboat,正在把這件事變成現實。
近期留言