by Rain Chu 5 月 13, 2026 | AI , Ollama , 模型
最新的 Qwen 3.6,在 Ollama 上的表現,可以說是目前「本地 Coding 模型」中非常強勢的一個系列。
如果你正在使用:
NVIDIA Spark
RTX 顯卡
Ollama
OpenWebUI
Continue
Claude Code
OpenHands
Hermes Agent
Cursor 類工具
Apple
那麼 Qwen 3.6 幾乎一定值得研究。
這篇文章會完整解析:
Qwen 3.6 每個版本差異
27B 與 35B 的差異
MXFP8、NVFP4、BF16 是什麼
哪個最適合寫程式
NVIDIA Spark 最推薦的配置
Ollama 部署建議
多人 SaaS / AI Agent 最佳實務
什麼是 Qwen 3.6?
Qwen 是阿里巴巴推出的大型語言模型(LLM)系列。
最新的 Qwen 3.6,官方特別強調:
Agentic Coding
Repository-level Reasoning
長 Context 推理
Thinking Preservation
也就是說:
它不只是會寫程式,而是開始能理解「整個專案」。
根據官方與 Ollama 頁面資訊,Qwen 3.6 在以下方面有明顯提升:
前端工作流理解
多檔案推理
AI Agent Tool Calling
長上下文理解
歷史推理保留
Repository 級別程式分析
為什麼 Qwen 3.6 很適合 Ollama?
Qwen 3.6 最大特色之一:
就是對本地部署非常友善。
目前 Ollama 已提供大量版本:
27B
35B-A3B
Coding 版本
Vision 版本
MXFP8
NVFP4
BF16
MLX
而且幾乎都支援:
256K Context
長文本推理
本地 AI Agent
Coding Workflow
Qwen 3.6 各版本意思解析
qwen3.6:latest
這是官方最新預設版本。
特色:
適合:
但:
不是最強的 Coding 版本。
qwen3.6:27b
27B = 270億參數。
這是目前非常熱門的甜蜜點。
優點:
Coding 能力很強
推理速度快
VRAM 壓力較低
多人共享容易
非常適合:
Continue
Claude Code
VSCode AI
Agent Workflow
本地 Copilot
qwen3.6:35b
35B = 350億參數。
這類模型:
推理能力更強。
尤其在:
大型專案理解
架構設計
Refactor
多檔案分析
會比 27B 更好。
但缺點:
什麼是 Coding 版本?
例如:
qwen3.6:27b-coding-mxfp8
qwen3.6:35b-a3b-coding-nvfp4
這些是:
專門針對寫程式優化的模型。
相較一般聊天模型:
它們更擅長:
Python
TypeScript
Go
Rust
Docker
Shell
Kubernetes
Debug
Refactor
AI Agent Tool Calling
官方也特別提到:
Qwen 3.6 在 Agentic Coding 與 Repository-level reasoning 上有大幅提升。
MXFP8、NVFP4、BF16 是什麼?
很多人看到:
會很混亂。
其實這些都是:
「量化格式」。
MXFP8
例如:
qwen3.6:27b-coding-mxfp8
這是 NVIDIA 新世代 FP8 格式。
特色:
品質高
VRAM 使用合理
推理速度快
非常適合 NVIDIA GPU
目前很多人認為:
MXFP8 是本地 AI Coding 的最佳甜蜜點。
尤其適合:
NVIDIA Spark
RTX 4090
RTX 5090
多 Agent Workflow
NVFP4
例如:
qwen3.6:27b-coding-nvfp4
這是 NVIDIA 的 4-bit 浮點量化格式。
特色:
但:
推理品質會稍微下降。
比較適合:
SaaS 平台
多人 AI IDE
高併發 Agent
目前學術研究也開始針對 NVFP4 做最佳化。
BF16
例如:
qwen3.6:27b-coding-bf16
這幾乎是:
接近原始精度。
優點:
品質最高
reasoning 最穩
hallucination 較少
缺點:
適合:
MLX 是什麼?
MLX 是 Apple Silicon 專用。
例如:
什麼是 A3B?
例如:
qwen3.6:35b-a3b-coding-mxfp8
這代表:
MoE(Mixture of Experts)架構。
意思是:
模型總參數很大,但每次只啟用部分專家。
優點:
官方指出:
Qwen3.6-35B-A3B 僅啟動約 3B Active Parameters,但依然能超越部分大型 Dense 模型。
NVIDIA Spark 最推薦哪個?
如果你的環境是:
NVIDIA Spark
CUDA 13
128GB RAM
Ollama
OpenWebUI
Continue
Claude Code
OpenHands
那我目前最推薦:
🥇 最推薦:qwen3.6:27b-coding-mxfp8
推薦原因:
Coding 非常強
推理速度快
VRAM 不容易爆
Agent 很穩
長 Context 表現好
本地部署平衡最佳
這是目前真正的:
「Production Sweet Spot」。
🥈 高階推理推薦:qwen3.6:35b-a3b-coding-mxfp8
適合:
AI Agent
大型專案
架構設計
多 Repo 分析
優點:
reasoning 更強
repository 理解更強
複雜任務更穩
缺點:
🥉 多人 SaaS 推薦:qwen3.6:27b-coding-nvfp4
適合:
多人共享
SaaS
AI IDE
高併發 Agent
優點:
但:
品質會略低於 MXFP8。
我自己的實戰看法
如果你是:
「真正要拿來工作」。
我目前認為:
Qwen 3.6 已經開始接近:
「本地版 Claude Code」。
尤其:
27B Coding MXFP8。
真的已經非常強。
它最大的優勢不是單純寫程式。
而是:
能理解整個 Repo
能做 Agent 工作流
能做長 Context reasoning
能做 Tool Calling
能理解大型專案
這跟以前單純「補程式碼」的模型完全不同。
Ollama 部署建議
安裝模型
ollama pull qwen3.6:27b-coding-mxfp8 執行模型
ollama run qwen3.6:27b-coding-mxfp8 開放 API
export OLLAMA_HOST=0.0.0.0:11434 NVIDIA Spark 最佳化建議
建議環境變數:
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_NUM_PARALLEL=4"
Environment="OLLAMA_MAX_LOADED_MODELS=3"
Environment="OLLAMA_MAX_QUEUE=1024"
Environment="OLLAMA_KEEP_ALIVE=-1"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
Environment="OMP_NUM_THREADS=32" 適合搭配的工具
Qwen 3.6 很適合:
Continue
Claude Code
OpenHands
Hermes Agent
OpenWebUI
Cursor 類工具
Browser-use
AI Agent Workflow
結論
如果你現在想打造:
本地 AI Coding 環境
AI Agent 平台
多人 AI IDE
本地 Claude Code
Ollama SaaS
那麼:
Qwen 3.6 幾乎是目前最值得研究的一條路。
尤其:
qwen3.6:27b-coding-mxfp8
我認為:
這是目前 NVIDIA Spark 上:
最平衡、最實用、最值得長期使用的本地 Coding 模型之一。
參考資料
by Rain Chu 4 月 14, 2026 | AI , google , 模型
在 AI 模型快速演進的時代,由 Google 推出的 Gemma 系列模型 一直備受關注,但對許多進階開發者來說,官方版本的限制(安全策略、回應過濾)往往成為發揮模型潛力的瓶頸 ,有了越獄版本,模型就再也不會回答你說「這個問題我不能回答了」。
這篇文章將帶你深入了解——越獄版本 Gemma 4(Gemma-4-31B-JANG_4M-CRACK)是什麼? 它如何突破限制?是否值得使用? 在本地 AI 架構(如 Ollama)中的實戰價值
🧠 什麼是 Gemma 4 越獄版?
所謂「越獄版」或「Crack 版」,指的是:
👉 移除或弱化模型原本的安全限制(alignment / guardrails)
這個版本來自 Hugging Face 上的開源模型:Gemma-4-31B-JANG_4M-CRACK
並可透過:Ollama 直接部署本地推論
⚙️ 越獄版 vs 官方版差異
項目 官方 Gemma 4 越獄版 Gemma 4 安全限制 高(嚴格過濾) 低(大幅放寬) 回答自由度 中 非常高 敏感內容處理 拒答或模糊 直接回答 適合用途 商業應用 研究 / 測試 / 私有 AI 風險 低 高
💣 為什麼有人需要「越獄模型」?
對你這種在做 AI Agent / 本地 LLM 架構的人來說,關鍵原因只有一個:
👉「控制權」
1️⃣ 做 AI Agent(LangChain / AutoGen)
👉 尤其是:
🧪 越獄版的核心改動(技術面)
這類模型通常做了以下處理:
🔹 1. 去除 RLHF 對齊限制
🔹 2. 訓練資料調整(JANG_4M)
加入大量 unrestricted instruction data
強化「服從 prompt」能力
🔹 3. Prompt Injection 抗性降低
👉 反而變成「完全服從」
🚀 在 Ollama 中部署
你可以直接用:
ollama run SiliconBasedWorld/Gemma-4-31B-JANG_4M-CRACK ⚠️ 建議設定(for 128G)
export OLLAMA_NUM_PARALLEL=4
Hermes Agent 完整實測:自我進化 AI Agent 架構,全面取代 OpenClaw! – 雨
by Rain Chu 3 月 18, 2025 | AI , API
Groq
Groq API 的主要特色
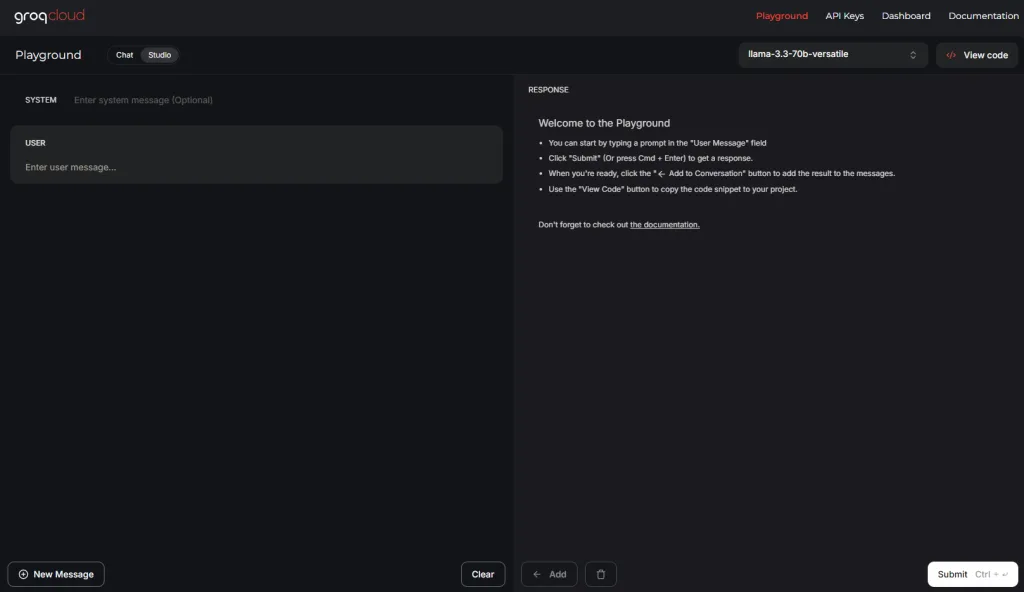
1. 提供 Playground 供快速測試
為了讓開發者能夠直觀地體驗和測試模型,Groq 提供了線上 Playground。使用者可以在此平台上直接輸入指令或問題,立即獲得模型的回應,無需進行繁瑣的設定或部署。
2. 詳細的 API 文件
Groq 提供了詳細且易於理解的 API 文件,涵蓋從基本使用到進階功能的各種說明,協助開發者快速上手並整合到自己的專案中。
3. 高速反應能力
得益於 Groq 的硬體架構,API 的反應速度極快,能夠即時處理大型語言模型的推理需求,提升使用者體驗。
如何開始使用 Groq API
註冊並獲取 API 金鑰 :
前往 Groq 官方網站 ,點擊「Login」或「Get API Key」,按照提示完成註冊並獲取 API 金鑰。
選擇開發環境並調用 API :
Python :使用 OpenAI 兼容的客戶端調用 Groq 提供的模型。
import openai
openai.api_key = 'YOUR_GROQ_API_KEY'
openai.api_base = 'https://api.groq.com/openai/v1'
response = openai.ChatCompletion.create(
model="groq/llama3-70b-8192",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "請介紹一下 Groq API 的特色。"}
]
)
print(response.choices[0].message['content'])
其他語言 :Groq 的 API 兼容 OpenAI 的接口,因此在其他編程語言中,只需將 API 基礎 URL 更改為 https://api.groq.com/openai/v1,並使用您的 Groq API 金鑰即可。
參考資料
by Rain Chu 3 月 17, 2025 | AI , Chat , Ollama , 模型
🚀 1. 本地端完美對接 Ollama AI 模型
OpenManus 最大的亮點在於能與目前最流行的 Ollama 本地端 AI 大模型平台進行完美整合。
Ollama 是一個輕量、高效的 AI 模型管理工具,讓你可以輕鬆在自己的電腦上運行各種強大的大模型(如 Llama3、Qwen、DeepSeek 系列模型等)。
OpenManus 透過 Ollama API 與這些模型無縫互動,你能輕易在本地體驗到媲美線上服務的智慧功能,並保護個人隱私。
💻 2. 跨平台支援 Windows、Mac、Linux
無論你使用哪個平台,OpenManus 都有完整的跨平台支援,讓你輕鬆安裝與運行:
Windows 用戶可透過 Conda 或 Docker 快速部署。
macOS 用戶可以使用 Homebrew 或直接透過終端機運行。
Linux 用戶則能自由選擇 Docker 或直接透過原生方式安裝。
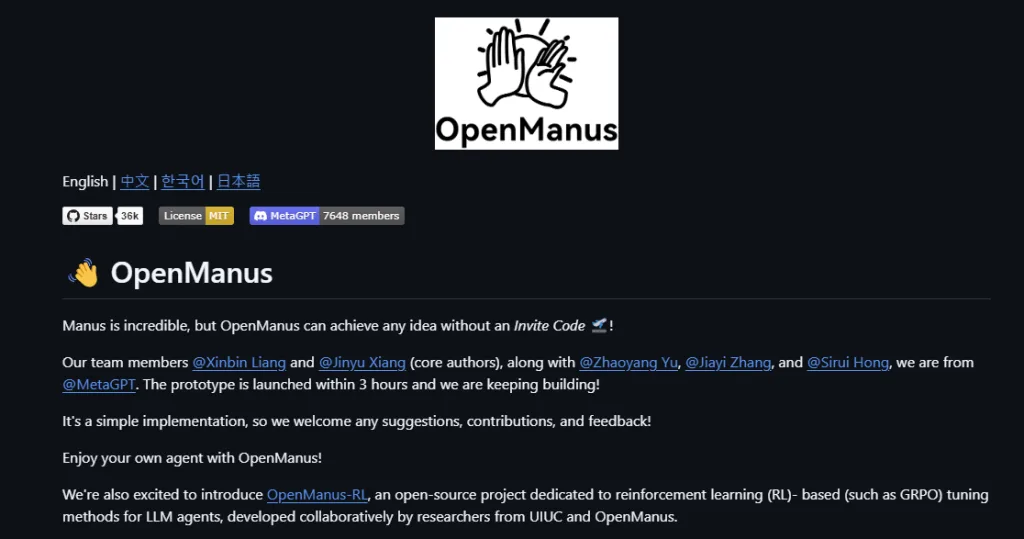
🎯 3. 無需邀請碼,即裝即用!
不同於原始封閉的 Manus 需要透過邀請碼才能使用,OpenManus 堅持完全開源與自由的精神。
如何快速部署 OpenManus?(以 Windows 為例)
只需幾個簡單步驟,即可享受本地端 AI 大模型:
建立 Conda 環境:
conda create -n openmanus python=3.12
conda activate openmanus Git OpenManus 專案:
git clone https://github.com/mannaandpoem/OpenManus.git
cd OpenManus 安裝所需依賴:
pip install -r requirements.txt 修改設定檔(config.toml):
cp config/config.example.toml config/config.toml config.toml的內容如下,可以參考後修改
# Global LLM configuration
#[llm]
# model = "claude-3-7-sonnet-20250219" # The LLM model to use
# base_url = "https://api.anthropic.com/v1/" # API endpoint URL
# api_key = "YOUR_API_KEY" # Your API key
# max_tokens = 8192 # Maximum number of tokens in the response
# temperature = 0.0 # Controls randomness
# [llm] #AZURE OPENAI:
# api_type= 'azure'
# model = "YOUR_MODEL_NAME" #"gpt-4o-mini"
# base_url = "{YOUR_AZURE_ENDPOINT.rstrip('/')}/openai/deployments/{AZURE_DEPOLYMENT_ID}"
# api_key = "AZURE API KEY"
# max_tokens = 8096
# temperature = 0.0
# api_version="AZURE API VERSION" #"2024-08-01-preview"
[llm] #OLLAMA:
api_type = 'ollama'
model = "llama3.2"
base_url = "http://localhost:11434/v1"
api_key = "ollama"
max_tokens = 4096
temperature = 0.0
# Optional configuration for specific LLM models
#[llm.vision]
#model = "claude-3-7-sonnet-20250219" # The vision model to use
#base_url = "https://api.anthropic.com/v1/" # API endpoint URL for vision model
#api_key = "YOUR_API_KEY" # Your API key for vision model
#max_tokens = 8192 # Maximum number of tokens in the response
#temperature = 0.0 # Controls randomness for vision model
[llm.vision] #OLLAMA VISION:
api_type = 'ollama'
model = "llama3.2-vision"
base_url = "http://localhost:11434/v1"
api_key = "ollama"
max_tokens = 4096
temperature = 0.0
# Optional configuration for specific browser configuration
# [browser]
# Whether to run browser in headless mode (default: false)
#headless = false
# Disable browser security features (default: true)
#disable_security = true
# Extra arguments to pass to the browser
#extra_chromium_args = []
# Path to a Chrome instance to use to connect to your normal browser
# e.g. '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome'
#chrome_instance_path = ""
# Connect to a browser instance via WebSocket
#wss_url = ""
# Connect to a browser instance via CDP
#cdp_url = ""
# Optional configuration, Proxy settings for the browser
# [browser.proxy]
# server = "http://proxy-server:port"
# username = "proxy-username"
# password = "proxy-password"
# Optional configuration, Search settings.
# [search]
# Search engine for agent to use. Default is "Google", can be set to "Baidu" or "DuckDuckGo".
# engine = "Google"
啟動 OpenManus 服務:
之後打開瀏覽器就可以了
測試 OpenManus :
可以輸入請他使用瀏覽器看某一個網站,並且執行SEO策略
打開 https://rain.tips/ 並且給予SEO的建議,並且把建議存放在桌面上.txt的文件 補充資料
Github
by Rain Chu 2 月 23, 2025 | AI , 程式開發
OpenRouter 是一個統一的大型語言模型(LLM)API 服務平台,可以讓使用者透過單一介面訪問多種大型語言模型。
主要特點:
多模型支援: OpenRouter 集成了多種預訓練模型,如 GPT-4、Gemini、Claude、DALL-E 等,按需求選擇適合的模型。易於集成: 提供統一的 API 介面,方便與現有系統整合,無需自行部署和維護模型。成本效益: 透過 API 調用,使用者無需購買昂貴的 GPU 伺服器,降低了硬體成本。
使用方法:
註冊帳號: 使用 Google 帳號即可快速註冊 OpenRouter。選擇模型: 在平台上瀏覽並選擇適合的模型,部分模型提供免費使用。調用 API: 使用統一的 API 介面,將選定的模型整合到您的應用中。
Cline 整合
OpenRouter 與 Cline 的整合為開發者提供了強大的 AI 編程體驗,Cline 是一款集成於 VSCode 的 AI 編程助手,支援多種大型語言模型(LLM),如 OpenAI、Anthropic、Mistral 等,透過 OpenRouter,Cline 能夠統一調用這些模型,簡化了不同模型之間的切換和管理,使用者只需在 Cline 的設定中選擇 OpenRouter 作為 API 提供者,並輸入相應的 API 金鑰,即可開始使用多種模型進行開發。這種整合不僅提升了開發效率,還降低了使用多模型的技術門檻。
DeepSeek R1
OpenRouter 現在也支援 DeepSeek R1 模型,DeepSeek R1 是一款高性能的開源 AI 推理模型,具有強大的數學、編程和自然語言推理能力。透過 OpenRouter,開發者可以在 Cline 中輕鬆調用 DeepSeek R1 模型,享受其強大的推理能力。這進一步豐富了開發者的工具選擇,讓他們能夠根據項目需求選擇最適合的模型。
近期留言