

如果你最近在看本地 AI 部署或企業工作站,很可能也被 RTX PRO 6000 Blackwell 的行情嚇到,這張卡原本是工作站專業卡,卻因為 96GB 大顯存、Blackwell 架構,以及能單卡容納 70B 量化模型的能力,被市場一路推成「算力理財產品」,它的矛盾也很明顯:不是最適合訓練的資料中心卡,卻成了企業做 AI 推理、RAG、知識庫問答與專業渲染時很難忽視的選項。
這篇文章會從規格、推理能力、價格結構與部署限制出發,幫你判斷 RTX PRO 6000 Blackwell 到底強在哪裡、為什麼漲價、適合哪些使用情境,以及工作站版、Max-Q 版、伺服器版和中國特供版應該怎麼選。
內容目錄
RTX PRO 6000 Blackwell 的核心定位
RTX PRO 6000 Blackwell 是 NVIDIA 在 2025 年 GTC 發布的專業工作站顯卡,定位不是遊戲,而是 AI 推理、3D 渲染、科學模擬、8K 內容製作與企業級工作負載,如果你已經在看 NVIDIA DGX Spark 這類本地 AI 硬體,它會是同一條部署思路下更高階的工作站選項。它與 RTX 5090 同屬 GB202 核心,但核心用途完全不同:RTX 5090 是消費級高階卡,RTX PRO 6000 則是拿來「幹活」的專業卡。
規格上,這張卡的重點包括:約 24,064 個 CUDA 核心、96GB GDDR7 顯存、512-bit 位寬、約 1,792GB/s 頻寬、ECC 顯存,以及最高約 4,000 TOPS 的 AI 算力。真正讓 AI 圈關注的,是 96GB 顯存搭配低精度推理時,可以讓 70B 量化大模型不用複雜多卡部署就塞進單卡。
對本地 AI 部署來說,能用單卡容納 70B 量化模型,往往比單純追求峰值算力更實際。
它能不能平替 H200?
如果拿 RTX PRO 6000 與 H200 相比,答案要務實一點:在主流 70B 模型 4-bit 推理場景下,RTX PRO 6000 的性能大約可達 H200 的 75% 到 80%。差距主要來自顯存頻寬與多卡互連能力。H200 是資料中心級方案,單卡價格也高很多;RTX PRO 6000 則更像工作站裡的 AI 推理加速器。
換句話說,如果你要從零訓練千億參數模型,RTX PRO 6000 不是最佳選擇;但如果你的需求是把 70B 模型部署到本地,用於程式碼生成、知識庫問答、RAG 或企業內部推理服務,它的成本結構會比 H200 方案更容易讓人接受。這類需求通常也會搭配 Ollama 遠端連線或內部 API 服務,讓團隊不必每個人都直接碰工作站。
最大的限制:沒有 NVLink
RTX PRO 6000 的一個關鍵限制,是不支援 H200 那種高速 NVLink 互連,如果兩張 PRO 6000 進行多卡推理,資料交換主要依靠 PCIe 5.0 x16,理論頻寬約 128GB/s,實務上還會受軟體堆疊影響;而 H200 的 NVLink 卡間頻寬可到約 900GB/s,這會直接影響需要頻繁交換 KV cache 或進行大規模模型並行的工作負載。
所以部署策略很清楚:單卡能搞定,就盡量不要上雙卡。RTX PRO 6000 的優勢在於單卡大顯存與本地推理,而不是多卡無損通信或大規模訓練。
為什麼價格一路上漲?
漲價原因可以歸納成三點。
第一,96GB GDDR7 顯存本身成本高。
第二,Blackwell 架構產能優先供給資料中心,工作站卡供應被壓縮。
第三,AI 本地部署需求太強,企業、科研機構、設計公司都在搶現貨。
這張卡發布初期的官方定價約 8,000 美元,但國內現貨價已經衝破 42 萬台幣,這種價格波動讓它不只是一張顯卡,更像企業算力採購裡的稀缺資源。
ECC、FP4 與 96GB 顯存的真正價值
對一般玩家來說,ECC 顯存可能只是「比較穩」。但在金融風控、醫療影像、科學計算或企業模型推理場景,一個 bit 翻轉就可能造成結果偏差,RTX PRO 6000 的 96GB GDDR7 全部支援 ECC,這也是它和遊戲卡之間很大的分水嶺。
另一個關鍵點是 FP4 原生支援。當模型採用 4-bit 量化時,顯卡是否原生支援低精度計算,會影響實際推理效率,這也是 RTX PRO 6000 在 70B 模型本地部署上特別有吸引力的原因。如果你主要在比較本地模型格式與量化選項,也可以先從 Ollama + Qwen 模型選擇這類實務問題回頭推硬體需求。
版本怎麼選?
RTX PRO 6000 Blackwell 可以分成幾個主要版本來看:工作站版、Max-Q 版、伺服器版,以及中國特供版 RTX PRO 6000D。選擇邏輯不是誰規格最高就買誰,而是看你要放在什麼機器裡、用幾張卡、散熱與供電條件是否撐得住。
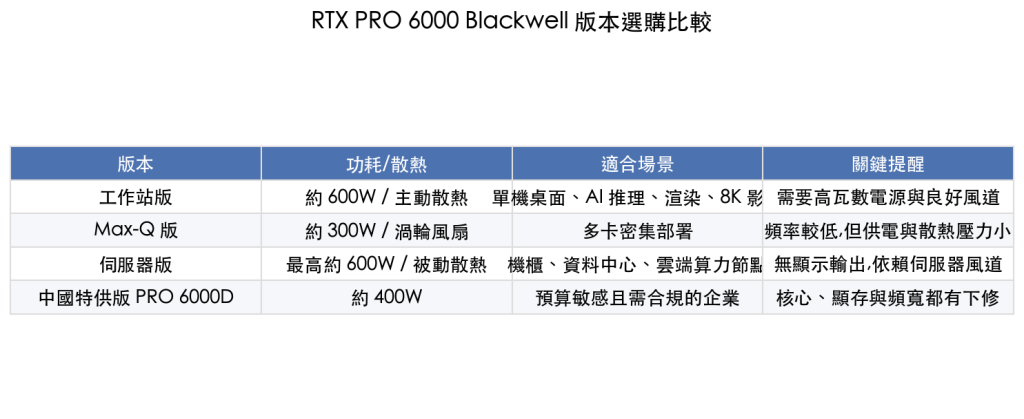
| 版本 | 適合對象 | 注意事項 |
|---|---|---|
| 工作站版 | 單機桌面、AI 推理、渲染、8K 內容製作 | 約 600W 功耗,需要高瓦數電源與良好風道 |
| Max-Q 版 | 多卡密集部署 | 功耗較低,較適合多卡機箱 |
| 伺服器版 | 機櫃、資料中心、雲端算力節點 | 被動散熱、無顯示輸出,依賴伺服器風道 |
| 中國特供版 PRO 6000D | 預算敏感且需合規的企業 | 核心、顯存與頻寬下修,但價格較低 |
工作站該怎麼配?
600W 等級的顯卡不是隨便塞進一般機箱就能穩定運作,電源至少要抓 1200W,更穩妥是 1500W 以上;若考慮峰值功耗或未來擴充,2000W 白金電源會更安心,主板則建議支援 PCIe 5.0 x16,並選擇 PCIe 通道充足的工作站平台,例如 Threadripper Pro 或 Xeon W 等級平台。
散熱方面,工作站版雖然有主動散熱,但機箱風道仍然非常重要。
多卡部署更建議考慮水冷或 Max-Q 版本。CPU 不能太弱,因為推理工作仍需要 CPU 處理資料預處理、API 調度與周邊工作。記憶體建議 128GB 起跳,若有 RAG、向量資料庫或多模型服務,256GB 會更寬裕。
現在該不該買?
我的判斷會比較直接:如果你是個人開發者或小團隊,有 AI 推理、RAG 或微調需求,且預算足夠,可以考慮入手;如果不急,可以等產能釋放後價格回落,但不要期待回到早期官方定價,若是做大模型訓練,也應該看 H100/H200 這類資料中心方案。
總結來說,RTX PRO 6000 Blackwell 的價值不在於「全能」,而在於它把 96GB 大顯存、ECC、FP4、Blackwell 架構和工作站可部署性放在同一張卡上。它不完美,沒有 NVLink、訓練能力有限、價格也高;但在本地 AI 推理、企業工作站、專業渲染和 4K 內容製作場景裡,確實是一張很有競爭力的卡。
FAQ
RTX PRO 6000 Blackwell 適合訓練大模型嗎?
不太適合大規模訓練。它更適合本地 AI 推理、RAG、知識庫問答、專業渲染與工作站應用。若要做大規模多卡訓練,應優先考慮 H100/H200 等資料中心方案。
RTX PRO 6000 能平替 H200 嗎?
不能完全平替。在 70B 4-bit 推理場景下,它大約可達 H200 約 75% 到 80% 的性能,但 H200 在顯存頻寬與 NVLink 多卡互連上仍有明顯優勢。
RTX PRO 6000 為什麼適合 70B 模型?
關鍵在 96GB 顯存與低精度推理支援。70B 量化模型可以在單卡容納,降低多卡部署複雜度,也避免多卡通信帶來的延遲。
近期留言