by Rain Chu | 6 月 6, 2026 | AI, 圖型處理
2026 年最受矚目的 AI 繪圖模型之一,莫過於 Ideogram 團隊正式釋出的:
Ideogram 4
這是 Ideogram 首次公開模型權重(Open Weight),也是目前開源陣營中,在:
- 文字生成(Text Rendering)
- 海報設計
- 品牌廣告
- 排版控制
- JSON 結構化提示詞
官方資料顯示,Ideogram 4 採用 9.3B 參數的單流 Diffusion Transformer(DiT)架構,並支援原生 2K 圖像生成。
本篇將帶你使用 ComfyUI,在本機部署 Ideogram 4。
系統需求
官方模型共有兩個版本:
| 版本 | 量化 |
|---|
| Ideogram 4 FP8 | 品質最佳 |
| Ideogram 4 NF4 | VRAM需求較低 |
目前 ComfyUI 官方整合版本主要使用:
其中 FP8 畫質最佳。
第一步:下載模型
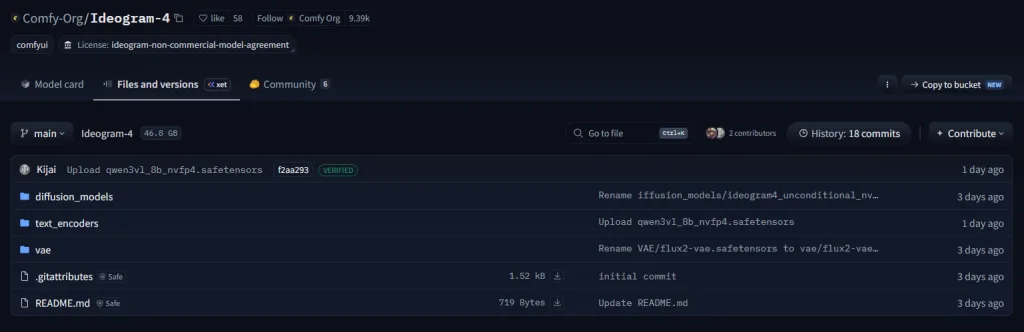
ComfyUI 專用模型
官方:
Comfy-Org Ideogram-4
原始模型:
Ideogram 4 FP8 官方模型
第二步:放置模型檔案
依照官方說明建立目錄。
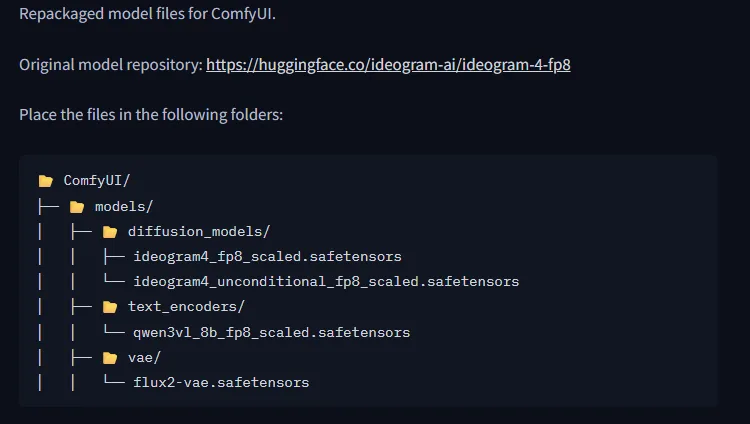
ComfyUI
│
├─ models
│ ├─ diffusion_models
│ │ ├─ ideogram4_fp8_scaled.safetensors
│ │ └─ ideogram4_unconditional_fp8_scaled.safetensors
│ │
│ ├─ text_encoders
│ │ └─ qwen3vl_8b_fp8_scaled.safetensors
│ │
│ └─ vae
│ └─ flux2-vae.safetensors
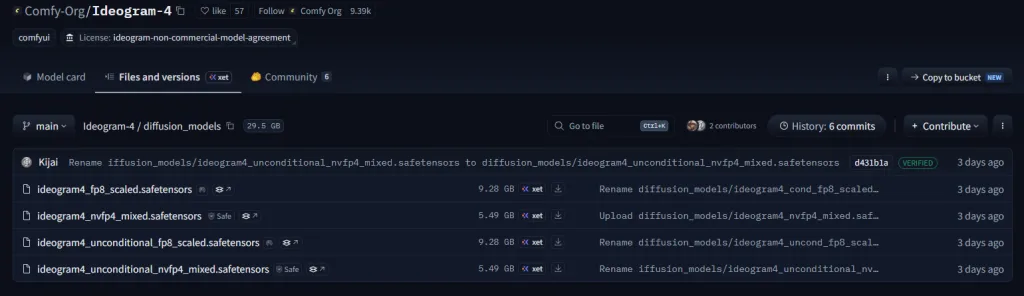
第三步:了解每個模型用途
ideogram4_fp8_scaled
主模型
負責:
ideogram4_unconditional_fp8_scaled
CFG 引導模型
負責:
- 提升細節
- 強化 Prompt Follow
- 改善品質
官方建議兩個模型一起使用。若只載入主模型雖可運作,但畫質會下降。
qwen3vl_8b_fp8_scaled
文字編碼器
負責:
- Prompt 理解
- JSON 理解
- 空間推理
- 海報版面配置
flux2-vae
VAE 解碼器
負責將 Latent 轉換成圖片。
第四步:更新 ComfyUI
Ideogram 4 需要最新版本的 ComfyUI。
更新方式:
或:
官方於 Day-0 即已原生支援 Ideogram 4。
第五步:載入官方 Workflow
ComfyUI 官方已提供範例工作流。
建議直接從:
Comfy Blog
下載 Workflow。
基礎工作流架構
Prompt
↓
Qwen3-VL Encoder
↓
Ideogram 4
↓
Sampler
↓
Flux VAE Decode
↓
Save Image
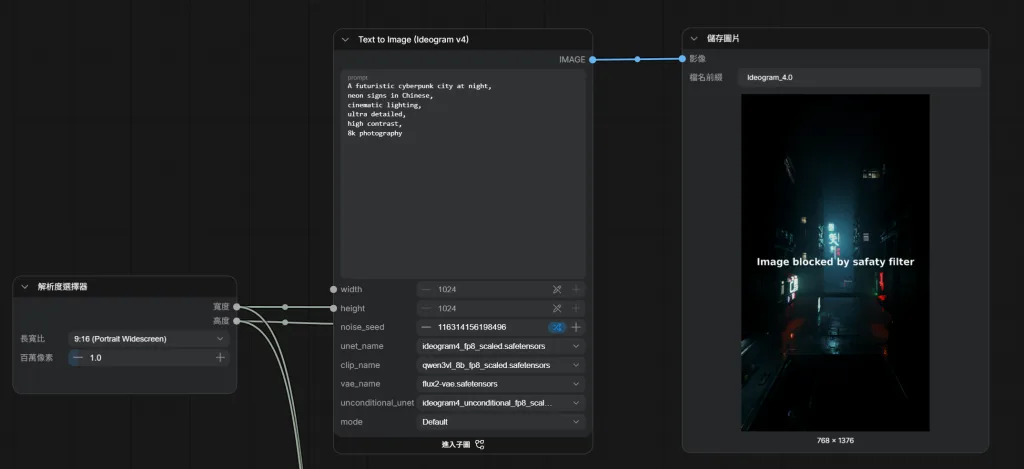
第六步:第一張圖片
測試 Prompt:
A futuristic cyberpunk city at night,
neon signs in Chinese,
cinematic lighting,
ultra detailed,
high contrast,
8k photography
生成尺寸:
推理模式:
第七步:體驗 JSON Prompt
Ideogram 4 最大特色就是:
Structured JSON Prompt
官方模型訓練時即使用 JSON Caption。
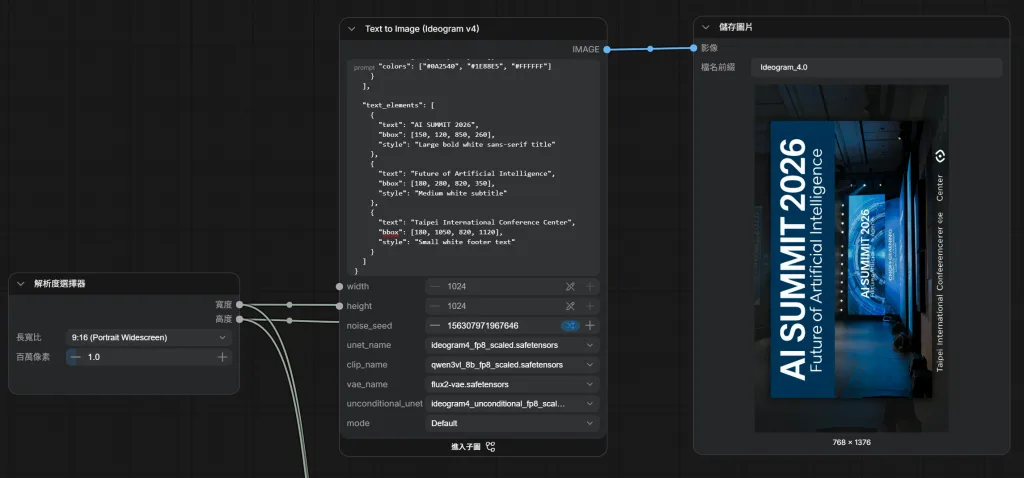
範例:海報設計
{
"scene_summary": "Professional technology conference poster",
"background": {
"description": "Modern convention center stage with blue ambient lighting, large LED screen, clean professional environment"
},
"style": {
"description": "Corporate marketing design, professional conference poster, clean typography, premium branding, modern layout"
},
"objects": [
{
"description": "Conference stage",
"bbox": [100, 150, 900, 850],
"colors": ["#0A2540", "#1E88E5", "#FFFFFF"]
}
],
"text_elements": [
{
"text": "AI SUMMIT 2026",
"bbox": [150, 120, 850, 260],
"style": "Large bold white sans-serif title"
},
{
"text": "Future of Artificial Intelligence",
"bbox": [180, 280, 820, 350],
"style": "Medium white subtitle"
},
{
"text": "Taipei International Conference Center",
"bbox": [180, 1050, 820, 1120],
"style": "Small white footer text"
}
]
}
Bounding Box 控制
可直接指定位置。
{
"text_elements":[
{
"text":"SALE 50%",
"bbox":[100,100,500,300]
}
]
}座標範圍:
原點:
這是目前 FLUX 與 Stable Diffusion 所不具備的能力。
色彩盤控制
品牌設計超級好用。
{
"color_palette":[
"#FF6600",
"#FFFFFF",
"#000000"
]
}官方支援:
與 FLUX 比較
FLUX 強項
Ideogram 4 強項
- Logo
- 海報
- Banner
- 電商素材
- 排版設計
- 中文文字生成
若你是:
Ideogram 4 很可能比 FLUX 更適合。
結論
Ideogram 4 不只是另一個 AI 繪圖模型。
它最大的創新在於:
把 Prompt 從自然語言升級為結構化設計規格。
透過:
- Qwen3-VL
- Diffusion Transformer
- JSON Prompt
- Bounding Box
- Color Palette
使用者終於可以像操作 Figma 一樣控制 AI 生成內容。
對於需要:
- 海報設計
- 品牌素材
- Banner 製作
- AI Agent 自動產圖
的開發者來說,Ideogram 4 是目前最值得研究與部署的開源模型之一。
by Rain Chu | 6 月 2, 2026 | AI, Ollama, 模型
想把 Ollama Client 安裝在 Windows 筆電上,但模型實際運行在另一台 AI 伺服器(例如 NVIDIA Spark、Linux GPU 主機)嗎?
本文教你如何透過 PowerShell 指定遠端 Ollama Server,讓本機直接使用遠端模型資源。
Ollama 遠端架構說明
一般情況下,Ollama 預設會連接本機:
但如果你的 AI 模型部署在另一台主機,例如:
則可以透過環境變數指定遠端伺服器。
Step 1:設定遠端 Ollama Host
開啟 PowerShell:
$Env:OLLAMA_HOST = "192.168.0.1:11434"
若使用 HTTP 格式也可以:
$Env:OLLAMA_HOST = "http://192.168.0.1:11434"
建議使用第二種寫法較完整。
Step 2:確認連線是否成功
執行:
若成功,將會看到遠端伺服器上的模型清單:
NAME ID SIZEclaude xxxxxx 45 GBkimi-k2.5:cloud xxxxxx 22 GBqwen3:32b xxxxxx 20 GBdeepseek-r1:70b xxxxxx 42 GB
若出現:
Error: connection refused
請確認:
- 遠端 Ollama 是否啟動
- 防火牆是否開放 11434 Port
- Ollama 是否監聽 0.0.0.0
Linux 可檢查:
sudo ss -tlnp | grep 11434
正常應看到:
Step 3:啟動 Claude
確認模型存在後:
系統將直接透過遠端 Ollama 執行 Claude。
Step 4:指定模型版本
例如使用 Kimi K2.5 Cloud 版本:
ollama launch claude --model kimi-k2.5:cloud
也可以切換成其他模型:
ollama launch claude --model qwen3:32b
ollama launch claude --model deepseek-r1:70b
ollama launch claude --model gemma3:27b
每次開機自動設定 OLLAMA_HOST
如果不想每次都輸入:
$Env:OLLAMA_HOST = "192.168.0.240:11434"
可永久寫入 Windows 使用者環境變數:
[System.Environment]::SetEnvironmentVariable( "OLLAMA_HOST", "http://192.168.0.240:11434", "User")
重新開啟 PowerShell 後生效。
驗證:
輸出:
http://192.168.0.240:11434
常見問題排除
無法連線
測試:
curl http://192.168.0.240:11434/api/tags
若有回傳 JSON 表示正常。
Linux Server 未開放外部連線
編輯 Ollama Service:
sudo systemctl edit ollama
加入:
[Service]Environment="OLLAMA_HOST=0.0.0.0:11434"
重新載入:
sudo systemctl daemon-reloadsudo systemctl restart ollama
查看目前設定
Windows:
Linux:
透過設定 OLLAMA_HOST,即可讓 Windows 電腦上的 Ollama Client 直接連接遠端 AI 伺服器,將模型運算交由高效能 GPU 主機處理,而本機僅作為操作介面。
這種架構特別適合:
- NVIDIA Spark AI 工作站
- 家用 GPU 伺服器
- 多人共用 Ollama Server
- 企業內部 AI 平台
- AI 開發與測試環境
只需一行指令:
$Env:OLLAMA_HOST = "192.168.0.240:11434"
即可讓你的 Windows PC 立即接管遠端 Ollama 的所有模型能力。
by Rain Chu | 5 月 13, 2026 | AI, Ollama, 模型
最新的 Qwen 3.6,在 Ollama 上的表現,可以說是目前「本地 Coding 模型」中非常強勢的一個系列。
如果你正在使用:
- NVIDIA Spark
- RTX 顯卡
- Ollama
- OpenWebUI
- Continue
- Claude Code
- OpenHands
- Hermes Agent
- Cursor 類工具
- Apple
那麼 Qwen 3.6 幾乎一定值得研究。
這篇文章會完整解析:
- Qwen 3.6 每個版本差異
- 27B 與 35B 的差異
- MXFP8、NVFP4、BF16 是什麼
- 哪個最適合寫程式
- NVIDIA Spark 最推薦的配置
- Ollama 部署建議
- 多人 SaaS / AI Agent 最佳實務
什麼是 Qwen 3.6?
Qwen 是阿里巴巴推出的大型語言模型(LLM)系列。
最新的 Qwen 3.6,官方特別強調:
- Agentic Coding
- Repository-level Reasoning
- 長 Context 推理
- Thinking Preservation
也就是說:
它不只是會寫程式,而是開始能理解「整個專案」。
根據官方與 Ollama 頁面資訊,Qwen 3.6 在以下方面有明顯提升:
- 前端工作流理解
- 多檔案推理
- AI Agent Tool Calling
- 長上下文理解
- 歷史推理保留
- Repository 級別程式分析
為什麼 Qwen 3.6 很適合 Ollama?
Qwen 3.6 最大特色之一:
就是對本地部署非常友善。
目前 Ollama 已提供大量版本:
- 27B
- 35B-A3B
- Coding 版本
- Vision 版本
- MXFP8
- NVFP4
- BF16
- MLX
而且幾乎都支援:
- 256K Context
- 長文本推理
- 本地 AI Agent
- Coding Workflow
Qwen 3.6 各版本意思解析
qwen3.6:latest
這是官方最新預設版本。
特色:
適合:
但:
不是最強的 Coding 版本。
qwen3.6:27b
27B = 270億參數。
這是目前非常熱門的甜蜜點。
優點:
- Coding 能力很強
- 推理速度快
- VRAM 壓力較低
- 多人共享容易
非常適合:
- Continue
- Claude Code
- VSCode AI
- Agent Workflow
- 本地 Copilot
qwen3.6:35b
35B = 350億參數。
這類模型:
推理能力更強。
尤其在:
- 大型專案理解
- 架構設計
- Refactor
- 多檔案分析
會比 27B 更好。
但缺點:
什麼是 Coding 版本?
例如:
- qwen3.6:27b-coding-mxfp8
- qwen3.6:35b-a3b-coding-nvfp4
這些是:
專門針對寫程式優化的模型。
相較一般聊天模型:
它們更擅長:
- Python
- TypeScript
- Go
- Rust
- Docker
- Shell
- Kubernetes
- Debug
- Refactor
- AI Agent Tool Calling
官方也特別提到:
Qwen 3.6 在 Agentic Coding 與 Repository-level reasoning 上有大幅提升。
MXFP8、NVFP4、BF16 是什麼?
很多人看到:
會很混亂。
其實這些都是:
「量化格式」。
MXFP8
例如:
qwen3.6:27b-coding-mxfp8
這是 NVIDIA 新世代 FP8 格式。
特色:
- 品質高
- VRAM 使用合理
- 推理速度快
- 非常適合 NVIDIA GPU
目前很多人認為:
MXFP8 是本地 AI Coding 的最佳甜蜜點。
尤其適合:
- NVIDIA Spark
- RTX 4090
- RTX 5090
- 多 Agent Workflow
NVFP4
例如:
qwen3.6:27b-coding-nvfp4
這是 NVIDIA 的 4-bit 浮點量化格式。
特色:
但:
推理品質會稍微下降。
比較適合:
- SaaS 平台
- 多人 AI IDE
- 高併發 Agent
目前學術研究也開始針對 NVFP4 做最佳化。
BF16
例如:
qwen3.6:27b-coding-bf16
這幾乎是:
接近原始精度。
優點:
- 品質最高
- reasoning 最穩
- hallucination 較少
缺點:
適合:
MLX 是什麼?
MLX 是 Apple Silicon 專用。
例如:
什麼是 A3B?
例如:
qwen3.6:35b-a3b-coding-mxfp8
這代表:
MoE(Mixture of Experts)架構。
意思是:
模型總參數很大,但每次只啟用部分專家。
優點:
官方指出:
Qwen3.6-35B-A3B 僅啟動約 3B Active Parameters,但依然能超越部分大型 Dense 模型。
NVIDIA Spark 最推薦哪個?
如果你的環境是:
- NVIDIA Spark
- CUDA 13
- 128GB RAM
- Ollama
- OpenWebUI
- Continue
- Claude Code
- OpenHands
那我目前最推薦:
🥇 最推薦:qwen3.6:27b-coding-mxfp8
推薦原因:
- Coding 非常強
- 推理速度快
- VRAM 不容易爆
- Agent 很穩
- 長 Context 表現好
- 本地部署平衡最佳
這是目前真正的:
「Production Sweet Spot」。
🥈 高階推理推薦:qwen3.6:35b-a3b-coding-mxfp8
適合:
- AI Agent
- 大型專案
- 架構設計
- 多 Repo 分析
優點:
- reasoning 更強
- repository 理解更強
- 複雜任務更穩
缺點:
🥉 多人 SaaS 推薦:qwen3.6:27b-coding-nvfp4
適合:
- 多人共享
- SaaS
- AI IDE
- 高併發 Agent
優點:
但:
品質會略低於 MXFP8。
我自己的實戰看法
如果你是:
「真正要拿來工作」。
我目前認為:
Qwen 3.6 已經開始接近:
「本地版 Claude Code」。
尤其:
27B Coding MXFP8。
真的已經非常強。
它最大的優勢不是單純寫程式。
而是:
- 能理解整個 Repo
- 能做 Agent 工作流
- 能做長 Context reasoning
- 能做 Tool Calling
- 能理解大型專案
這跟以前單純「補程式碼」的模型完全不同。
Ollama 部署建議
安裝模型
ollama pull qwen3.6:27b-coding-mxfp8
執行模型
ollama run qwen3.6:27b-coding-mxfp8
開放 API
export OLLAMA_HOST=0.0.0.0:11434
NVIDIA Spark 最佳化建議
建議環境變數:
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_NUM_PARALLEL=4"
Environment="OLLAMA_MAX_LOADED_MODELS=3"
Environment="OLLAMA_MAX_QUEUE=1024"
Environment="OLLAMA_KEEP_ALIVE=-1"
Environment="OLLAMA_FLASH_ATTENTION=1"
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
Environment="OMP_NUM_THREADS=32"
適合搭配的工具
Qwen 3.6 很適合:
- Continue
- Claude Code
- OpenHands
- Hermes Agent
- OpenWebUI
- Cursor 類工具
- Browser-use
- AI Agent Workflow
結論
如果你現在想打造:
- 本地 AI Coding 環境
- AI Agent 平台
- 多人 AI IDE
- 本地 Claude Code
- Ollama SaaS
那麼:
Qwen 3.6 幾乎是目前最值得研究的一條路。
尤其:
qwen3.6:27b-coding-mxfp8
我認為:
這是目前 NVIDIA Spark 上:
最平衡、最實用、最值得長期使用的本地 Coding 模型之一。
參考資料
by Rain Chu | 4 月 29, 2026 | AI, Ollama, 模型
🧱 直接給「滿血設定」
你現在 service 改成這個👇(最重要)
[Unit]
Description=Ollama Service
After=network-online.target[Service]
ExecStart=/usr/local/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3# ===== 核心 =====
Environment="OLLAMA_HOST=0.0.0.0:11434"
Environment="OLLAMA_KEEP_ALIVE=-1"# ===== GPU 強制 =====
Environment="OLLAMA_GPU_LAYERS=999"# ===== 記憶體優化 =====
Environment="OLLAMA_KV_CACHE_TYPE=q8_0"
Environment="OLLAMA_FLASH_ATTENTION=1"# ===== Spark專用 tuning =====
Environment="OLLAMA_NUM_PARALLEL=2"
Environment="OLLAMA_MAX_LOADED_MODELS=2"
Environment="OLLAMA_MAX_QUEUE=512"# ===== CPU 控制 =====
Environment="OMP_NUM_THREADS=20"# ===== PATH =====
Environment="PATH=/usr/local/cuda/bin:/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin"[Install]
WantedBy=multi-user.target
🔁 套用
sudo systemctl daemon-reexec
sudo systemctl daemon-reload
sudo systemctl restart ollama
🔍 一定要做驗證
systemctl show ollama | grep OLLAMA
👉 要看到全部變數
🧠 模型才是性能關鍵
🔥 Spark 正確用法
| 用途 | 模型 |
|---|
| 最快 | llama3:8b |
| 平衡 | llama3:13b |
| 大模型 | 30B(單一) |
✅ 先做這個測試(非常重要)
ollama run llama3
👉 再看:
nvidia-smi
🔥 讓 GPU 真的滿血(關鍵3件事)
① 模型「完全進 GPU」
👉 關鍵判斷:
ollama ps
看到:
100% GPU
👉 才算成功
② context 不要亂開
👉 Ollama 預設 4096
👉 你如果開到:
👉 = 直接 CPU fallback
👉 建議:
ollama run llama3 --num_ctx 4096
③ 不要多模型併發
Spark 特性:
👉 記憶體大,但 bandwidth 普通
👉 所以:
OLLAMA_NUM_PARALLEL=2
是最佳解
🧠 Spark 的本質
👉 DGX Spark:
- 128GB memory ✔
- 超大模型可跑 ✔
- ❌ 不是高吞吐 GPU
👉 正確定位:
🔥 大模型單機推理機
🧪 接下就會看到的改善
調完後:
| 指標 | 改善 |
|---|
| GPU Util | 0% → 80%+ |
| token/sec | ↑ 3~10倍 |
| latency | ↓ 50%以上 |
| CPU | ↓ |
🎯 注意事項
👉 ❗不要讓使用者直接打 Ollama
by Rain Chu | 3 月 5, 2026 | MIS, Nvidia
在使用 nvidia spark 或 NVIDIA Jetson 類型的 AI 開發平台時,很多開發者會希望能夠遠端操作設備,而不是每次都連接螢幕、鍵盤與滑鼠。這時候 VNC(Virtual Network Computing) 就是一個非常方便的遠端桌面解決方案。
透過 vino VNC Server 與 RealVNC Viewer,你可以在 Windows、macOS 或 Linux 上遠端連線到 NVIDIA Spark 的桌面環境,像是直接操作本機一樣。VNC 可以透過網路傳輸桌面畫面與輸入操作,因此非常適合 AI 開發、邊緣設備管理與遠端維護。
本文將介紹如何在 nvidia spark / Ubuntu 系統 中啟用 VNC Server(vino),並透過 RealVNC Viewer 進行遠端連線。
為什麼 NVIDIA Spark 建議使用 VNC
在 AI 或嵌入式開發場景中,遠端桌面有幾個重要用途:
- 遠端查看 GPU 程式的 GUI
- 遠端操作桌面應用程式
- headless(無螢幕)設備管理
- 在不同電腦之間共享桌面
VNC 允許使用者透過網路存取 Linux 圖形桌面,而不需要實際連接顯示器。
NVIDIA Spark 啟用 VNC(vino)教學
以下步驟適用於 Ubuntu / GNOME 環境的 nvidia spark。
1 安裝 VNC Server(vino)
首先在 NVIDIA Spark 中安裝 vino:
sudo apt update
sudo apt install vino
vino 是 GNOME 桌面內建的 VNC Server,常用於 Ubuntu 遠端桌面。
2 啟用 VNC Server 自動啟動
建立 symbolic link,讓 vino 在登入後自動啟動:
cd /usr/lib/systemd/user/graphical-session.target.wants
sudo ln -s ../vino-server.service ./
這樣每次登入桌面時,VNC 服務就會自動啟動。
3 設定 VNC Server
關閉安全提示與加密:
gsettings set org.gnome.Vino prompt-enabled false
gsettings set org.gnome.Vino require-encryption false
這些設定可以避免某些 VNC Viewer 無法連線的問題。
4 設定 VNC 密碼
設定遠端登入密碼:
gsettings set org.gnome.Vino authentication-methods "['vnc']"
gsettings set org.gnome.Vino vnc-password $(echo -n 'yourpassword' | base64)
請將 yourpassword 替換為自己的密碼。
5 重新啟動系統
sudo reboot
重新啟動後,VNC Server 設定就會生效。
使用 RealVNC Viewer 連線 NVIDIA Spark
在另一台電腦安裝 RealVNC Viewer。
接著:
- 查詢 NVIDIA Spark IP
ifconfig
或
ip a
- 開啟 RealVNC Viewer
- 輸入 IP 地址
例如:
192.168.1.50
- 輸入剛剛設定的 VNC 密碼
即可成功遠端操作 NVIDIA Spark 桌面。
VNC 常見問題
1 VNC 無法連線
可能原因:
- vino 沒有啟動
- GNOME 沒有登入
- 防火牆阻擋
確認服務:
ps aux | grep vino
2 VNC 黑畫面
可能是:
可設定 自動登入(Auto Login) 解決。
VNC、RealVNC、vino 的差異
| 工具 | 功能 |
|---|
| vino | Linux GNOME VNC Server |
| VNC | 遠端桌面協定 |
| RealVNC Viewer | 常用 VNC 客戶端 |
通常搭配方式:
vino server + RealVNC viewer
結論
透過 VNC + vino + RealVNC,可以快速讓 nvidia spark 具備遠端桌面能力,對於 AI 開發、遠端管理或 headless 系統來說非常方便。
只需要簡單幾個步驟:
- 安裝 vino
- 啟用 VNC server
- 設定密碼
- 使用 RealVNC 連線
就能輕鬆遠端控制 NVIDIA Spark。
相關資料
https://developer.nvidia.com/embedded/learn/tutorials/vnc-setup
近期留言