by Rain Chu 6 月 6, 2026 | AI , 繪圖
AI 圖像生成正式進入「設計級控制」時代
近兩年 AI 繪圖領域競爭激烈,從 Midjourney、Stable Diffusion、FLUX,到 Google Imagen,各家模型都在追求更好的畫質與更精準的提示詞理解能力。
真正困擾設計師與企業用戶的問題其實不是畫質,而是以下的問題:
文字總是生成錯誤
排版無法控制
Logo 與標題位置不準確
無法符合品牌色彩規範
每次生成結果都像在「抽卡」
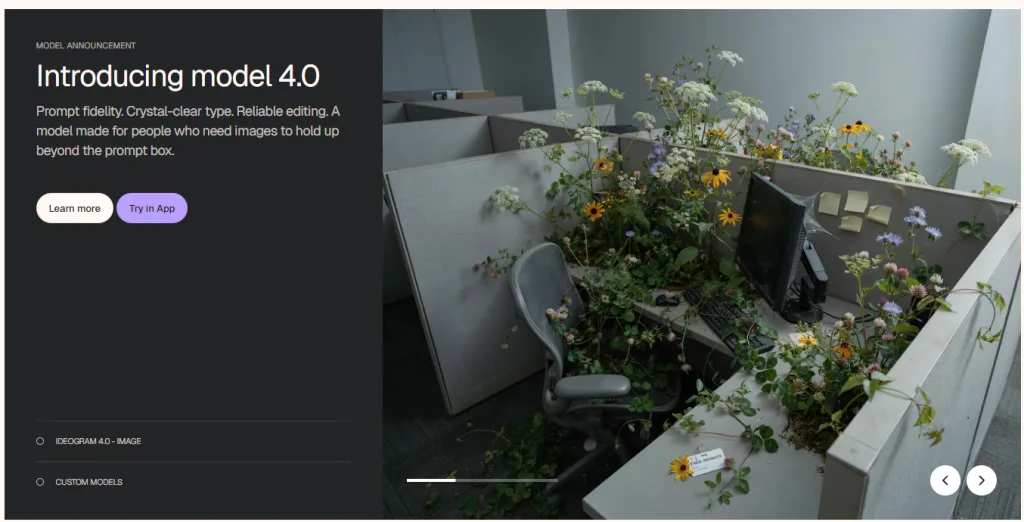
2026 年 6 月,Ideogram 正式推出最新開源模型:
Ideogram 4.0
這不僅是 Ideogram 首次公開權重(Open Weight)模型,更被許多開發者視為目前最接近商業設計工作流程的 AI 圖像生成系統。
什麼是 Ideogram 4.0?
Ideogram 4.0 是一款從零開始訓練的 AI 圖像生成模型,採用最新的:
Diffusion Transformer(DiT)架構
與傳統 Stable Diffusion 不同,Ideogram 4.0 使用:
34 層 Transformer
93 億參數(9.3B)
單流(Single Stream)設計
文字 Token 與影像 Token 共用同一套注意力機制
官方稱其為:
Single-Stream Diffusion Transformer(DiT)
這種架構讓模型能更深入理解文字與影像之間的關聯,提高提示詞遵循能力(Prompt Adherence)與版面控制能力。
核心架構解析
1. 文字編碼器(Text Encoder)
Ideogram 4.0 並未使用傳統的 CLIP 或 T5 「文字編碼器(Text Encoder)」。
而是採用了:
Qwen3-VL-8B-Instruct
作為文字理解引擎。
其特色包括:
視覺語言模型(Vision Language Model)
僅使用文字模式
提取 13 個中間層隱藏狀態
將多層特徵串接後輸入 DiT
這種設計能同時保留:
讓模型對複雜提示詞有更深層的理解能力。
2. DiT 主幹網路
Ideogram 4.0 採用:
34 Layers
Embedding Dimension:4608
18 Attention Heads
SwiGLU Feed Forward
總參數量達:
9.3 Billion Parameters
目前已是開源 AI 繪圖模型中最頂尖的規模之一。
3. VAE 解碼器
使用凍結(Frozen)的:
KL VAE
特性:
8× 空間壓縮
128 Latent Channels
負責將潛在空間(Latent Space)轉換為最終圖像。
4. Flow Matching 取樣器
不同於傳統 DDPM。
Ideogram 4.0 採用:
Euler Flow Matching
搭配:
Asymmetric CFG
特色:
提升生成效率
改善細節品質
更穩定的提示詞遵循能力
官方提供三種推理模式:
模式 Steps V4_TURBO 12 V4_DEFAULT 20 V4_QUALITY 48
品質模式會在最後階段降低引導強度,進一步提升真實感。
最大突破:JSON 結構化提示詞
這是 Ideogram 4.0 最具革命性的地方。
過去 AI 繪圖都依賴自然語言:
A beautiful girl standing beside a lake... Ideogram 4.0 則改為:
{ "background": "...", "objects": [...], "texts": [...], "style": {...}} 模型訓練時完全使用 JSON 描述,因此天生理解結構化資訊。
Bounding Box 精準版面控制
支援 Bounding Box:
{ "bbox": [100,100,400,400]} 採用:
可直接指定:
這是過去 Midjourney、Stable Diffusion 很難做到的功能。
色彩盤控制(Color Palette)
可直接指定品牌色:
{ "colour_palette": [ "#FF6600", "#FFFFFF", "#000000" ]} 限制:
非常適合:
多語言文字生成能力大幅提升
Ideogram 一直以來最強的能力就是:
Text Rendering
也就是圖片內文字生成。
例如:
以往 AI 經常出現亂碼。
但 Ideogram 4.0 已能大幅提升:
等多語系文字品質。
原生支援 2K 輸出
解析度支援:
最小:256 × 256
最大:2048 × 2048
且:
例如:
YouTube Banner
網站橫幅
電商主圖
手機桌布
皆可直接生成。
設計工作流功能全面升級
除了模型本身之外,Ideogram 平台也同步推出多項設計工具:
Prompt Edit
直接修改既有圖片中的特定區域。
Magic Fill
局部重繪。
Remix
基於現有圖片重新生成。
Extend / Reframe
擴展畫布與調整比例。
Upscale
提高解析度。
Transparent Background
直接輸出透明背景 PNG。
MCP 整合
可接入 AI Agent 工作流程。
Editable Text Layers
未來將支援真正可編輯的文字圖層功能。
Ideogram 4.0 與 Google Imagen 誰更強?
若比較:
Google Imagen
FLUX
Stable Diffusion
Ideogram 4.0
目前 Ideogram 最大優勢在於:
✅ 文字生成能力
✅ 排版控制能力
✅ JSON 結構化設計流程
✅ 開源權重
✅ 可自行部署
而 Google Imagen 仍在:
方面維持優勢。
若是企業設計工作流,Ideogram 4.0 已經是極具競爭力的選擇。
官方資源
官方網站
Ideogram 官方網站
模型介紹
Ideogram 4.0 Model Page
技術部落格
Ideogram 4.0 Technical Details
API 文件
Ideogram Developer API
GitHub
Ideogram 4 GitHub Repository
Hugging Face
Ideogram 4 Hugging Face Collection
Ideogram 4.0 不只是另一個 AI 繪圖模型。
它最大的突破在於:
把 AI 繪圖從「描述圖片」提升到「設計圖片」。
透過:
Diffusion Transformer(DiT)
Qwen3-VL 編碼器
JSON Prompt
Bounding Box 控制
色彩盤控制
可編輯文字圖層
Ideogram 4.0 正逐步接近 Photoshop、Illustrator 與 Figma 所代表的專業設計工作流程。
對於品牌設計、電商素材、廣告製作與 AI Agent 自動化內容生成來說,Ideogram 4.0 很可能會成為 2026 年最值得關注的開源 AI 圖像生成模型之一
by rainchu 12 月 15, 2025 | AI , 圖型處理 , 模型 , 繪圖
Nano Banana Pro 剛出,就馬上成為「圖像生成與視覺應用」領域的新標準,它不只是畫圖工具,而是一個高度可控、支援中文、能維持一致性的 AI 視覺引擎 。
以下整理 Google Nano Banana Pro 的 15 種超強應用場景 ,無論你是設計師、行銷企劃、教育工作者或產品經理,都能立即上手。
1️⃣ 簡報/企劃海報快速生成
只要輸入企劃主題與風格,Nano Banana 就能產出投影片主視覺、封面海報、提案插圖 ,大幅減少找素材與修圖時間。
2️⃣ 草圖秒變產品實景圖
手繪線稿、低擬真草圖,可直接轉為擬真產品照 ,特別適合工業設計、UI / UX、新創產品驗證。
3️⃣ 設計材質紋理
可精準生成木頭、金屬、皮革、布料、玻璃等高解析材質貼圖 ,支援不同光源與粗糙度設定。
4️⃣ 角色一致性
透過角色描述與參考設定,即使多次生成,也能維持臉型、服裝、風格高度一致 ,非常適合漫畫、品牌代言角色。
5️⃣ 品牌指南手冊
一次生成品牌色彩、字體風格、視覺範例 ,快速完成 Brand Book 視覺示意。
6️⃣ 生成各種尺寸
同一視覺可自動輸出 社群貼文、橫幅廣告、直式限動、網站 Banner 等多尺寸版本。
7️⃣ 食譜圖超清晰
針對食物細節表現極佳,油光、層次、質地自然,特別適合餐飲菜單、食譜部落格、外送平台 。
8️⃣ 多國語言菜單 Menu
結合 Gemini 的語言能力,可直接生成多國語言版本菜單圖片 ,且排版自然、不違和。
9️⃣ 景點/教材圖卡
可用於旅遊介紹、歷史教材、地理圖卡、兒童學習素材 ,風格可愛或寫實皆可。
🔟 風格轉換更精細
支援攝影風、插畫風、3D 風、日系、美式、復古等,且保留原圖構圖與細節 。
1️⃣1️⃣ 教學假桌面生成
快速生成「假作業系統畫面」、「教學用後台介面」,適合製作教學簡報與線上課程 。
1️⃣2️⃣ 腳本 → 連續劇照
輸入分鏡或劇本段落,即可生成連續一致的劇照畫面 ,對影視提案與動畫前期極有幫助。
1️⃣3️⃣ 中文超強
對繁體中文理解精準,無論是菜單、教材、標語、情境文字,都能自然呈現,不再需要英文轉譯 。
1️⃣4️⃣ 畫 3D 圖也可以
可生成擬 3D、等角視圖、產品爆炸圖概念,適合簡報與技術說明使用。
1️⃣5️⃣ 任意切換焦距
同一場景可切換廣角、標準、特寫、微距 ,視覺敘事能力大幅提升。
參考與官方資源
by rainchu 11 月 23, 2025 | AI , 繪圖
什麼是 AIX Studio?
AIX Studio 提供了一系列 AI 繪圖與視覺特效功能,讓使用者從文字提示、圖片輸入,甚至批量處理模式,快速生成具質感、具光影效果的視覺作品,並結合類似服務模式,它不僅針對創作者介面,也支援 API 整合,適合企業/開發者接入。
此外,從應用場景來看:
支援「電商場景圖片」:例如產品在光影下的立體感、背景反射、陰影鮮明。
室內設計視覺:場景光源處理、物件材質質感、自然光或人造光的投射。
人像後期與自媒體內容:人臉光影、高光處理、背景模糊與光線設計。
API 整合:可將生成流程嵌入自家 APP、網站或後台服務,自動產出多版本視覺素材。
多種光影特效與後期應用
這裡列出 AIX Studio 在光影與後期特效方面值得關注的功能:
光源模擬 :例如自然光、側光、背光、點光源等,讓畫面具備立體感與深度。陰影與反射處理 :物體在場景中的陰影投射、反光面板、水面反射或鏡面效果。材質質感增強 :金屬、玻璃、布料、木材等不同材質在光影下的變化。後期風格化特效 :如「電影膠片風格」、「電商清晰專業風」、「室內柔光」等。批量生成與版本控制 :可設定不同光影/風格參數,一鍵生成多版本,方便 A/B 測試或素材庫建立。API 調用 :對於開發者而言,可透過 API 傳送文字提示、圖片資料、光影參數,回收到生成圖像,便於整合至 APP/網站。
為什麼選擇 AIX Studio?
多場景適用 :從電商商品照、室內設計視覺、到人像後期、自媒體封面,一應俱全。光影特效為核心亮點 :不少 AI 繪圖工具偏重「風格化」或「插畫感」,但 AIX Studio 將光影處理、材質質感視為重點。開發者友善 API :如果你已有 APP 或網站需要圖片生產流程自動化或大量生成,API 支援是重要優勢。節省製作成本與時間 :過去可能需要專業攝影或後製師處理光線與材質,現在藉助 AI,可快速生成可用素材。
快速上手指南:三步驟生成質感圖像
步驟 1:明確構思場景與用途 步驟 2:在 AIX Studio 輸入提示/上傳圖片+調整光影參數
可選文字提示:如「luxury product on glass table, strong side light, velvet fabric backdrop, high contrast shadow」。
若已有素材,可上傳圖片並選擇「材質+光源模擬」參數。
點選生成後,系統處理後回傳圖像。
步驟 3:後製/整合與輸出
注意事項與實用 Tips
提示越具體,光影效果越精準 :描述中加入「光源類型、陰影強度、反射面材質、色溫」等詞彙。材質設定影響大 :例如「玻璃反射」與「布料柔光」處理方式不同,提示中應明確指出。確認 API 授權與用途 :若將生成圖像用於商用或整合至 APP 中,需確認 API 條款與版權可否。儲存提示與參數記錄 :若你生成多版本圖像,建議記錄提示詞、模型版本、光影參數,以便後續重現或修改。後製仍能提升質感 :雖然 AI 生成已具備光影特效,但你仍可手動微調色彩、加文字、疊圖效果以符合品牌風格。
參考資料
https://draw.aix.studio
by rainchu 11 月 23, 2025 | AI , 繪圖
什麼是 Pollo AI?
Pollo AI 是一款「一站式 AI 圖片+影片生成平台」,它整合了領先業界的文字-影像、影像-影片模型,甚至支援圖片轉影片、影片編輯、動畫生成等功能。根據官方介紹,它允許你從文字或圖像輸入,透過多款模型,產出高品質的視覺作品。
特色亮點:十個 AI 工具全合體
以下為 Pollo AI 的主要特色與亮點,讓你了解它為什麼值得一看:
整合多款頂尖模型 :平台支援多款影像與影片生成模型,如 Sora 2、Veo 3.1、Kling、Runway 等。 圖片到影片 :上傳靜態圖片、輸入提示文字,即可轉換為動態影片,並配備音效與背景音樂。 文字到影像/影片 :從文字提示產出圖片、或轉為影片,涵蓋從構思到視覺成品的流程。 特效與轉場豐富 :支援圖片‐影片風格化、動畫角色轉換、社群短影片格式等。 適用不同創作者 :無論你是社群內容創作者、品牌營銷人員、插畫師還是動畫愛好者,都能找到適合的功能。 省時高效 :相比傳統拍攝、後製流程,透過 AI 可大幅提升產出效率,縮短內容製作時間。
實測:影片生成流程解析
下面是一個簡化的實測流程,讓你看到 Pollo AI 從構思到生成影片的操作步驟:
構思影片主題 選擇模型與輸入提示 上傳素材或僅用文字 生成並下載 後製優化(視需求)
適用場景/創作建議
社群貼文影片 :想製作 Instagram 或 TikTok 用的短影音,可以用「圖片轉影片」模式快速生成。品牌影片/產品宣傳 :品牌想快速製作 Banner、預告片,使用文字+影片模型即可實踐。個人創作/插畫動畫 :插畫師可從靜態畫轉為動畫片段,或者從文字提示做視覺故事化。內容行銷/教育影片 :搭配影片編輯、文字提示功能,可快速製作教學、說明影片或簡報動畫。
注意事項與 Tips
提示越具體,效果越佳 :指明鏡頭類型、光線、構圖、角度、風格等可提高成品質量。選擇模型合適任務 :不同模型風格不同,比如 Veo 3.1 深於場景轉換、長片敘事;其他模型或更適合動態風格。檢查授權/商用條款 :若使用於商業用途,確認平台是否支援商用及是否需付費升級。儲存素材與提示文字 :建議紀錄使用哪個模型、提示內容,以便未來重複或修改。後製仍有價值 :雖然 AI 工具功能強大,但如需品牌風格統一、字幕、配音仍可由後製進一步加工。
參考資料
https://pollo.ai
by rainchu 11 月 23, 2025 | AI , 圖型處理 , 繪圖
所謂 AI 圖像生成,是指利用人工智慧模型(如「文本轉圖片」或「圖片轉圖片」)從文字提示、或現有影像作為輸入,產出全新視覺作品。這類工具背後常用「擴散模型」(diffusion models)或其他生成式架構。
快速上手指南:三步驟產出視覺作品
步驟 1:明確構思內容 步驟 2:輸入提示(Prompt)並生成 步驟 3:後製與整合
模型推薦:哪個最穩定、最強?
經檢視多項資料後,我們推薦使用 Analog Madness 模型。這裡說明為什麼選它:
Analog Madness 是一款靠近真實攝影質感的影像生成模型,据社群評論和模型頁面資料指出,其在「真實風格」、「類比攝影風格」方面表現優異。
它常被描述為「非常多用途(versatile)」、「提示越強效果越好」的模型。
在專門探討 AI 模型的討論中,有使用者提問:「Is Analog Madness the best 1.5 photorealistic model?」可見其在社群中名字較為常見。
使用建議 :
若你想要達成「真實感+類比攝影風格」的圖片,可選擇 Analog Madness 並搭配精細提示。
提示範例可加入「ultra realistic close up portrait, film grain, analog style, 4K」等描述。
注意:即便是最強模型,也仍需你提供具體而精準的提示詞;模型本身不是完全自動完美,仍須人為設計輔助。
LoRA 濾鏡玩法:讓 AI 直接「化妝」你的圖
除了選擇強模型之外,另一個提升圖片風格自由度與創意控制的關鍵是 LoRA(Low-Rank Adaptation)濾鏡 。以下為其玩法介紹:
什麼是 LoRA? 怎麼使用?
選擇一個支持 LoRA 的 UI 或工具(如 Stable Diffusion 前端)。
將你想加入的 LoRA 模組載入(如「beauty-makeup LoRA」、「film-grain LoRA」等)。
在提示(prompt)中明確加入你想的濾鏡風格,例如: prompt: 「A glamorous portrait of a woman, heavy makeup, glossy lips, dramatic eyeshadow, analog film style, beauty light」
效果與建議 :
利用 LoRA,你能讓 AI 圖像加上「化妝效果」、「風格化妝感」、「光影膠片質感」等,使圖片更具商業或時尚感。
建議提示中加入「makeup, dramatic eyeshadow, high-gloss skin, studio lighting」等描述詞,再搭配 LoRA,效果更佳。
若你生成系列圖片(例如插畫系列或社群貼文系列),可固定同一個 LoRA 濾鏡,以維持風格一致性。
注意事項 :
某些 LoRA 模組可能只用於私人、非商業用途,使用前請確認授權。
濾鏡效果強度過高可能導致圖片不自然,建議生成後進一步微調。
快速上手指南:三步驟產出視覺作品
步驟 1:明確構思內容 步驟 2:選模型+載入 LoRA +輸入提示 步驟 3:後製與整合
注意事項與實用 Tips
提示越具體,效果越好 :描述中加入「情緒、光線、構圖、色調」等詞彙。檢查版權與用途限制 :若將圖片用於商業用途,請確認工具條款。視覺風格一致性 :若產出系列圖像,建議統一提示中指定風格,以維持一致性。避免過度依賴 AI :AI 是輔助工具,創作者仍可加入人性化元素、構思與個人風格。輸出檔案備份 :建議保存原始生成圖片與提示文字,以便未來回溯或修改。
參考資料
https://aigallery.app
by rainchu 11 月 23, 2025 | Chat , 繪圖
ChatArt 是一款整合 AI 聊天、寫作、繪圖的工具平台。它支援用戶用對話方式輸入想法、選擇創作場景,平台便會協助產出文章、小說,甚至圖片。根據官網介紹,它提供小說產生器、圖生圖、文生圖功能,並且多平台支援(網頁/手機/平板)
為什麼用 AI 來寫小說、畫圖?
激發創意、打破瓶頸 節省時間、提高效率 視覺與文字一體化 免費/低成本起步
如何用 ChatArt 來寫小說+畫圖 — 步驟指南
以下為建議流程,協助您快速上手:
1. 明確構思主題
2. 開啟小說產生器
3. 產出畫圖
4. 潤飾與整合
5. 發佈與迭代
創意應用案例
短篇小說+插圖集 :用 ChatArt 快速創作一篇短篇(如 1000 字內)+ 3~5 張配圖,製作成自己的電子書。社群圖文貼文 :每日/每週用 AI 畫圖+配一段創意文字,在 Instagram 、 X 或 Facebook 刊出,快速累積風格與粉絲。故事連載+視覺系列 :將創作拆成「章節」+「每章畫圖」,展開系列連載,讓讀者期盼下一篇。寫作訓練工具 :若您是作家或插畫師,可用 AI 生成靈感,再由您精修,作為養成創意能力的練習。
注意事項/實用 Tips
雖然名稱說「免費」,但部分高階功能可能需付費或限制次數,建議先以「免費試用」為起點。
文字提示越具體,畫圖效果越精準。建議描述「色調、光影、角度、背景元素」等。
雖為 AI 產出,仍需您加入「人性化」元素:角色內心、轉折、情感描寫,畫圖也可修圖再發佈。
若將創作商業化,請確認平台的使用條款/商業授權情況。
創作完成後,建議備份作品(文字+圖片),確保資料安全。
參考資訊
https://www.chatartpro.com




近期留言